언제쯤 GPT 없이 문제를 풀 수 있을것인가..😅
문제 소개 및 데이터 준비 단계
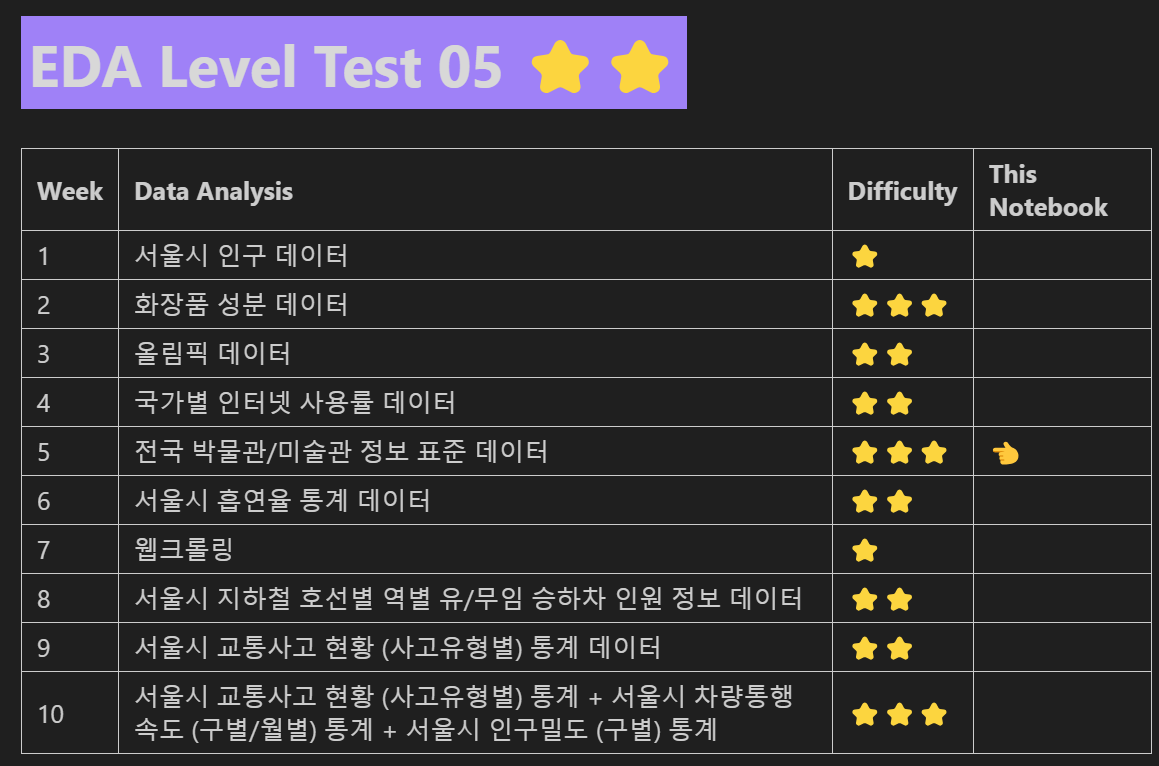
Target Data(Json): 전국박물관미술관정보표준데이터
- Source: 공공데이터포털
- DownLoad: 전국박물관미술관정보표준데이터.json
참고사항
- 공공데이터포털에서 해당 데이터는 다양한 Format(xls, xml, json, rdf, csv)으로 제공합니다.
- 다양한 Data Format 사용을 하고자 해당 Test에서는 일부러 json format의 데이터를 사용할 예정입니다.
- json 상세 설명: https://www.json.org/json-ko.html
- 문제에 hint가 있을 경우, 해당 hint를 이용하지 않으셔도 무방합니다.
import json
# 채점을 위한 코드입니다. 반드시 실행해주세요.
from grading import *
with open('./datas/전국박물관미술관정보표준데이터.json', 'r', encoding='utf-8') as f:
json_data = json.load(f)1단계: Json Data로 DataFrame으로 만들기
문제 1-1) Json Data로 Pandas DataFrame 만들기 (10점)
- 위에서 읽은 json_data는 아래와 같이 구성되어있습니다. 이를 참고하여 pandas dataframe으로 불러오세요.
- json_data
- json_data['fields']: List. 각 variable은 하나의 Column(열)을 의미하며, {id: Column(열)명}의 형식으로 구성 되어있습니다.
- json_data['records']: List. 각 variable은 하나의 Row(행)을 의미하며, {Column(열)명: data}의 형식으로 구성 되어있습니다.
- 조건1: 위의 내용을 참고하여 'json_data'를 이용하여 Pandas DataFrame을 만드세요
- 조건2: json data의 Index와 Column(열)의 순서(order)는 변경하지 마세요.
- 앞에서부터 순차적으로 차례로 읽어 그대로 DataFrame으로 만드세요.
- 조건3: 'df_target' 변수에 결과 DataFrame을 할당하세요.
- hint: pandas의 read_json method로는 읽어지지 않습니다.
- 공공데이터포털에서 json data를 만드는 형식이 read_json과 matching되지 않아 Error가 발생합니다.
📌 답안
import pandas as pd
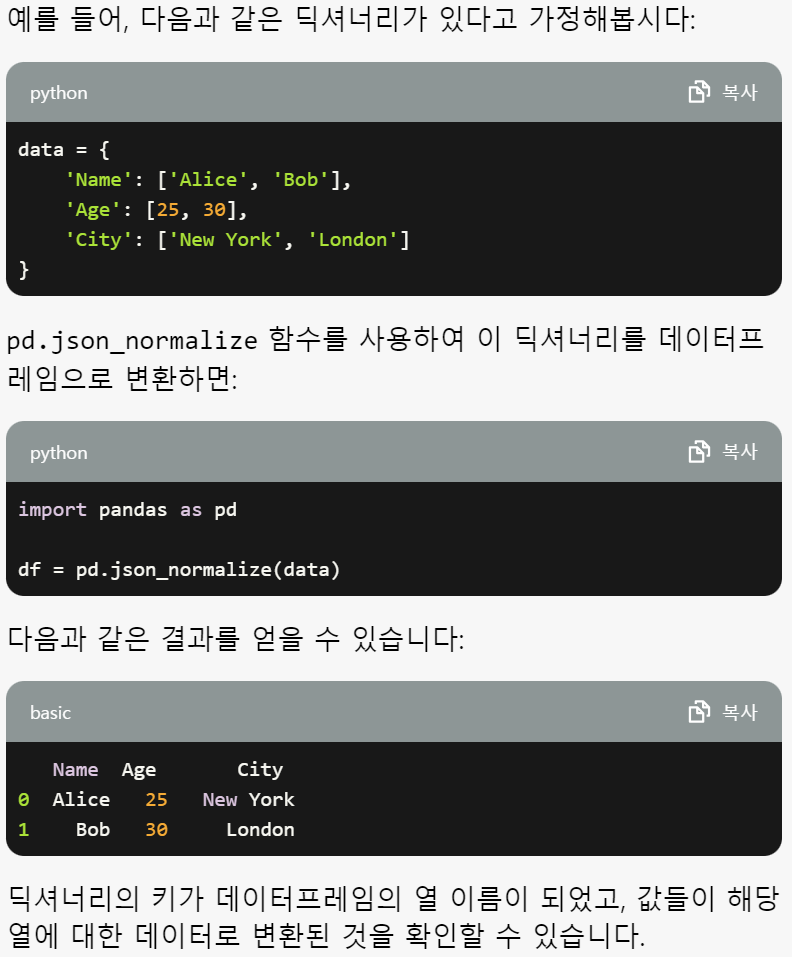
df_target = pd.json_normalize(json_data["records"])pd.json_normalize
- pd.json_normalize 함수는 JSON 데이터를 정규화하여 DataFrame을 반환한다.
- 위에서 읽어온 json 파일의 records key에 해당하는 value가 컬럼, 데이터 형태의 딕셔너리로 담겨있기 때문에
해당 데이터를 바로 넣어 데이터 프레임을 만들 수 있었다.- 참고링크 : https://gibles-deepmind.tistory.com/entry/PYTHON-JSON-%ED%8C%8C%EC%9D%BC-DataFrame-%EB%B3%80%ED%99%98jsonnormalize
(사실상 더 복잡한 기능이 있는것 같지만, 일단은 여기까지만 이해하는것으로.. )
2단계: DataFrame 전처리 01 - 기초
문제 2-1) 기초 전처리 01 (5점)
- 1단계의 DataFrame(df_target)을 아래의 조건에 맞게 변경하세요.
- 해당 json_data의 null값은 ""로 구성되어 df_target.info() 또는 df_target.isna() 등을 이용하여 null값을 확인할 경우 null값이 없다고 나오게 됩니다. 이에 이 Data를 제대로 확인하기 위해서 "" 대신에 Null값을 넣으려 합니다.
- 조건1: ""(또는 '')는 띄어쓰기 없이 쌍따옴표(혹은 따옴표)로만 구성됩니다.
- 조건2: ""(또는 '')를 null값(None)으로 바꾸세요.
- 조건3: Index 또는 순서(order)는 변경하지 마세요.
- 조건4: 'df_target' 변수에 결과 DataFrame을 할당하세요.
📌 답안
df_target.replace(to_replace='', value=None, inplace=True)데이터프레임 특정 데이터 변경방법
df.place(to_replace = {원본데이터값}, values={변경할데이터값}, inplace = {원본데이터수정여부})특정 열의 모든 값을 변경
df['Column_Name'] = 변경할데이터값특정 위치의 데이터 값을 변경
df.at[row_index, 'Column_Name'] = 변경할데이터값특정 조건을 만족하는 데이터 값을 변경
df.loc[condition, 'Column_Name'] = 변경할데이터값
문제 2-2) 기초 전처리 02 (5점)
- 2-1의 DataFrame(df_target)을 아래의 조건에 맞게 변경하세요.
- json Data를 Pandas DataFrame으로 만들면서 수치형 데이터들이 string으로 인식되었습니다. 이를 변경하려고 합니다.
- 조건1: 아래 type_int_col의 Column(열) Data를 정수(int)형 Data로 변경하세요.
- 조건2: 아래 type_float_col의 Column(열) Data를 실수(float)형 Data로 변경하세요.
- 조건3: 변경할 Data에 Null값이 있다면, 0으로 채우세요.
- 조건4: Index 또는 순서(order)는 변경하지 마세요.
- 조건5: 'df_target' 변수에 결과 DataFrame을 할당하세요.
type_int_col = ['어른관람료', '청소년관람료', '어린이관람료']
type_float_col = ['위도', '경도']
📌 답안
# 조건1, 2
df_target[type_int_col] = df_target[type_int_col].astype(int)
df_target[type_float_col] = df_target[type_float_col].astype(float)
#조건3
df_target[type_int_col] = df_target[type_int_col].fillna(0)
df_target[type_float_col] = df_target[type_float_col].fillna(0)데이터프레임 None값 특정 데이터로 변경
df.fillna({바꿀데이터값})
문제 2-3) 기초 전처리 03 (5점)
- 2-2의 DataFrame(df_target)을 아래의 조건에 맞게 변경하세요.
- 분석과 상관 없는 Column(열)의 Data들을 삭제하여 Data의 가독성을 높이고자 합니다.
- 조건1: 아래 drop_col의 Column(열) Data를 삭제하세요.
- 조건2: Index 또는 순서(order)는 변경하지 마세요.
- 조건3: 'df_target' 변수에 결과 DataFrame을 할당하세요.
drop_cols = ['소재지지번주소', '위도', '경도', '운영기관전화번호','운영기관명', '운영홈페이지', '편의시설정보', '휴관정보',
'관람료기타정보', '박물관미술관소개', '교통안내정보', '관리기관전화번호', '관리기관명', '제공기관코드', '제공기관명']
📌 답안
df_target.drop(labels=drop_cols, axis=1, inplace=True)특정컬럼삭제
df.drop(labels = {삭제할컬럼})
문제 2-4) 기초 전처리 04 (5점)
- 2-3의 DataFrame(df_target)을 아래의 조건에 맞게 변경하세요.
- 어른, 청소년, 어린이 관람료가 이상한 경우, 해당 row(행) data 자체가 이상하다고 판단하여 삭제하고자 합니다.
- 조건1: 관람료와 관련된 Column(열)은 위에서 정의한 type_int_col 입니다.
- 조건2: 관람료가 10원 단위로 나누어 떨어지지 않는 경우 이상치로 판단합니다. 해당 row(행)를 삭제하세요.
- 조건3: 관람료가 100000원(십만원) 이상인 경우 이상치로 판단합니다. 해당 row(행)를 삭제하세요.
- 조건4: Index 또는 순서(order)는 변경하지 마세요.
- 조건5: 'df_target' 변수에 결과 DataFrame을 할당하세요.
📌 답안
# 삭제할 행 index 추출
idx = df_target[(df_target[type_int_col] % 10 != 0).any(axis=1) | (df_target[type_int_col] >= 100000).any(axis=1)].index
# drop
df_target.drop(idx,inplace=True)
- any : 하나라도 만족하면 삭제
- all : 모두 만족해야 삭제
- 옵선 : axis=0 | 열 / axis=1 | 행
- 특정 인덱스 삭제
- drop(idx)
3단계: DataFrame 전처리 02 - 심화
문제 3-1) 심화 전처리 01 (10점)
- 2단계의 DataFrame(df_target)을 아래의 조건에 맞게 변경하세요.
- 휴관중이거나 중복된 박물관/미술관의 data를 삭제하고자 합니다.
- 아래의 조건 이외에도 중복되는 data들이 있으나, 해당 Test에서는 아래 조건에 따른 중복 data만 삭제하여 진행합니다.
- 조건1: 시설명 Column(열) data에 '휴관'이라는 글자가 들어있으면 해당 row(행)은 삭제합니다.
- 조건2: 시설명 Column(열) data가 중복되는 경우 해당 row(행)의 '데이터기준일자'가 최신인 data를 남기고 최신이 아닌 row(행)은 삭제합니다.
- 만약, 시설명 Column(행)의 data가 중복되면서 가장 최신인 data가 두 개 이상인 경우, Index가 가장 낮은(예시: 495, 674 중 495) Index를 남기고, 높은 Index(예시: 495, 674 중 674)의 row(행) data를 삭제하세요.(낮은 인덱스가 더 최근 데이터라고 가정)
- 예시: 아래 예시의 경우 데이터기준일자가 최신인 0번 index의 row(행)은 남기고 1338번 index의 row(행)은 삭제합니다.
- 조건3: 시설명 Column(열) data의 중복 여부는 시설명 Column(열) data의 띄어쓰기를 삭제한 값이 일치할 경우 중복된 박물관/미술관으로 판단합니다.
- 예시: 아래 예시의 경우 시설명 Column(열) data의 띄어쓰기를 삭제할 경우 시설명 Column(열) data가 동일합니다. 이에 데이터기준일자가 최신인 6번 index의 row(행)은 남기고 1909번 index의 row(행)은 삭제합니다.
- 조건4: Index 또는 순서(order)는 변경하지 마세요.
- 문제를 풀기위해 순서를 변경하였다면, 다시 Index 순서로 정렬하세요
- 조건5: 'df_target' 변수에 결과 DataFrame을 할당하세요.
- hint1: '데이터기준일자' Column(열)의 Data는 현재 string입니다. 대소비교가 가능한지 확인해보세요.
- hint2: 조건2 관련하여, '시설명'과 '데이터기준일자'가 같은 data들이 존재합니다. Index를 확인하세요.
- '데이터기준일자' 기준으로 정렬시 주의하세요.
- 휴관중이거나 중복된 박물관/미술관의 data를 삭제하고자 합니다.
# 혹시모를 깊은본사
df_target_temp = df_target.copy()
# 조건3 띄어쓰기 삭제
df_target_temp['시설명'] = df_target_temp['시설명'].str.replace(' ','')
# 시설명 오름차순, 데이터기준일자 내림차순 정렬
df_target_temp = df_target_temp.sort_values(['시설명','데이터기준일자'], ascending=[True,False])
# 시설명 기준으로 중복제거 (마지막행 유지 : 데이터기준일자 최신)
df_target_temp = df_target_temp.drop_duplicates('시설명', keep='first')
# 인덱스 원래로 정렬
df_target_temp = df_target_temp.sort_index()
- 중복데이터 삭제
- (첫 번째로 등장한 데이터 유지, 기본값=keep='first')
df_dropped = df.drop_duplicates()- (마지막으로 등장한 데이터 유지)
df_dropped = df.drop_duplicates(keep='last')- 모든 중복된 데이터 제거
df_dropped = df.drop_duplicates(keep=False)
문제 3-2) 심화 전처리 02 (10점)
- 3-1의 DataFrame(df_target)을 아래의 조건에 맞게 변경하세요.
- 평일과 공휴일에 박물관/미술관이 하루 중 몇시간이나 열려있는지를 알려주는 '관람가능시간'을 구하려고 합니다.
- 조건1: 평일의 관람가능시간은 '평일관람시작시각'부터 '평일관람종료시각'까지 입니다. '평일관람가능시간' Column(열)을 만들어 평일의 관람가능시간을 입력하세요.
- 조건2: 공휴일의 관람가능시간은 '공휴일관람시작시각'부터 '공휴일관람종료시각'까지 입니다. '공휴일관람가능시간' Column(열)을 만들어 공휴일의 관람가능시간을 입력하세요.
- 조건3: '평일관람가능시간'과 '공휴일관람가능시간'은 시간(hour) 단위 실수(float)로 표기합니다.
- 관람가능시간이 8시간 30분인경우 8.5로 표기합니다.
- 관람가능시간이 23시간을 초과하는 경우 24시간으로 표기합니다.
- 평일 또는 공휴일의 관람시작시각과 관람종료시각이 모두 00:00(또는 0:00)인 경우 휴일로 판단하며, 관람가능시간은 0으로 입력합니다.
- 관람가능시간이 6시간 40분과 같이 무환소수(6.6666666666666......6666666667)로 표기될 경우 소숫점 셋째 자리에서 반올림하여 소숫점 둘째 자리까지 표기합니다.
- 조건4: Index 또는 순서(order)는 변경하지 마세요.
- 조건5: 'df_target' 변수에 결과 DataFrame을 할당하세요.
- hint: 각 관람시작시각/관람종료시각의 Data Type은 string 입니다.
📌 답안
weekday = []
holiday = []
from datetime import datetime
for idx, row in df_target_temp.iterrows():
weekday_start_timedate = datetime.strptime(row.평일관람시작시각,"%H:%M")
weekday_end_timedate = datetime.strptime(row.평일관람종료시각,"%H:%M")
weekday_time_diff = weekday_end_timedate - weekday_start_timedate
weekday_hours_diff = round(weekday_time_diff.total_seconds() / 3600 ,2)
if weekday_hours_diff > 23 :
weekday_hours_diff = 24.00
if weekday_hours_diff == 0 :
weekday_hours_diff = 0.00
weekday.append(weekday_hours_diff)
holiday_start_timedate = datetime.strptime(row.공휴일관람시작시각,"%H:%M")
holiday_end_timedate = datetime.strptime(row.공휴일관람종료시각,"%H:%M")
holiday_time_diff = holiday_end_timedate - holiday_start_timedate
holiday_hours_diff = round(holiday_time_diff.total_seconds() / 3600 ,2)
if holiday_hours_diff > 23 :
holiday_hours_diff = 24.00
if holiday_hours_diff == 0 :
holiday_hours_diff = 0.00
holiday.append(holiday_hours_diff)
df_target_temp['평일관람가능시간'] = weekday
df_target_temp['공휴일관람가능시간'] = holiday
datetime.strptime
현재 시간컬럼들이 문자열이기 때문에 datetime.strptime 모듈로 시 분 으로 변경한 뒤, 그 차를 구하고 시간단위로 표현해줬다.
round로 소수점 둘째자리까지 반올림 시키고 리스트에 담아
컬럼할당 !
문제 3-3) 심화 전처리 03 (10점)
- 3-2의 DataFrame(df_target)을 아래의 조건에 맞게 변경하세요.
- '소재지도로명주소' Column(열)의 Data를 가공하여 광역자치단체-기초자치단체(행정시)-상세 주소로 구분하려고 합니다.
- 조건1: '소재재도로명주소' Column(열) data의 첫번째 단어는 언제나 광역자치단체명을 의미합니다. '광역' Column(열)을 만들어 해당 row(행) data의 광역자치단체명을 입력하세요.
- '세종특별시'는 현재 '세종특별자차시'로 명칭이 변경되었습니다. 이를 반영해주세요.
- 조건2: '소재재도로명주소' Column(열) data의 두번째 단어는 대부분 기초자치단체명을 의미합니다. '기초' Column(열)을 만들어 해당 row(행) data의 기초자치단체명을 입력하세요.
- '제주특별자치도'의 경우 기초자치단체가 없으나, 행정시('제주시', '서귀포시')가 '소재재도로명주소' Column(열) data의 두번째 단어에 위치합니다. 행정시를 '기초' Column(열)에 입력하세요.
- '세종특별자치시'의 경우 기초자치단체가 없습니다. '세종특별자치시'의 경우 '기초' Column(열)에는 Null값(None)을 입력해주세요.
- 조건3: '소재재도로명주소' Column(열) data에서 광역/기초자치단체(행정시포함)에 포함되지 않은 데이터는 '상세' Column(열)을 만들어 입력하세요.
- 조건4: '소재지도로명주소', '광역', '기초', '상세 Column(행)의 data는 해당 data의 앞-뒤로 띄어쓰기 등 공백이 없어야 합니다.
- 조건5: Index 또는 순서(order)는 변경하지 마세요.
- 조건6: 'df_target' 변수에 결과 DataFrame을 할당하세요.
📌 답안
df_target = df_target_temp.copy()
split1 = []
split2 = []
split3 = []
for idx, row in df_target.iterrows() :
address = row['소재지도로명주소'].split()
if address[0] == '세종특별시' or address[0] == '세종특별자치시' :
temp1 = '세종특별자치시'
temp2 = None
temp3 = " ".join(address[1:]).strip()
else :
temp1 = address[0].strip()
temp2 = address[1].strip()
temp3 = " ".join(address[2:]).strip()
split1.append(temp1)
split2.append(temp2)
split3.append(temp3)
df_target['광역'] = split1
df_target['기초'] = split2
df_target['상세'] = split3
df_target.소재지도로명주소 = df_target.소재지도로명주소.str.strip()🧷 3-3 메소드 모음
contain(): 특정문자가 포함되어있는지 확인contain('{포함하는지 찾을 문자열}')strip(): 앞뒤 특정문자 자르기contain('{자를 문자열 또는 공백(의 경우 생략)}')join(): 문자열합치기'{합칠기준(ex공백)}'.join(리스트)endswith(): 특정문자로 끝나는지 확인endswith('{찾을문자열}')startswith(): 특정문자로 시작하는지 확인startswith('{찾을문자열}')
4단계: 원하는 정보 얻기
문제 4-1) 원하는 정보 얻기 01 (10점)
- 3단계의 DataFrame(df_target)을 이용하여 아래의 조건에 맞는 정보를 구하세요.
- 광역자치단체별 박물관/미술관의 총 수를 확인하고자 합니다.
- 조건1: df_target의 '광역' Column(열)에 있는 광역자치단체 data를 이용하여 광역자치단체별 박물관/미술관의 총 수를 나타내주세요.
- 조건2: 결과 DataFrame의 Index는 광역자치단체입니다. 광역자치단체의 우선순위는 아래 province_dict의 value(값)으로 제공합니다. Index의 순서를 광역자치단체의 우선순위에 따라 나열해주세요.
- 출처: 행정안전부
- 조건3: 결과 DataFrame의 박물관/미술관의 총 수를 나타내는 Column(열)의 이름은 '박물관미술관수' 입니다.
- 예시: Index/Column
- 조건4: 'df_result' 변수에 결과 DataFrame을 할당하세요.
province_dict = {
'서울특별시': 0,
'부산광역시': 1,
'대구광역시': 2,
'인천광역시': 3,
'광주광역시': 4,
'대전광역시': 5,
'울산광역시': 6,
'세종특별자치시': 7,
'경기도': 8,
'강원도': 9,
'충청북도': 10,
'충청남도': 11,
'전라북도': 12,
'전라남도': 13,
'경상북도': 14,
'경상남도': 15,
'제주특별자치도': 16
}
📌 답안
df_target_temp[['광역','시설명' ]].groupby(['광역']).count().rename(columns={'시설명':'박물관미술관수'}).sort_values(by='광역', key = lambda x: x.map(province_dict))특정 기준을 기반으로 정렬
sort_valeus의 key 옵션사용
문제 4-2) 원하는 정보 얻기 02 (10점)
- 3단계의 DataFrame(df_target)을 이용하여 아래의 조건에 맞는 정보를 구하세요.
- 광역자치단체-기초자치단체(행정시)의 박물관/미술관의 총 수가 8개인 광역-기초자치단체(행정시)를 확인하고자 합니다.
- 조건1: df_target의 '광역'과 '기초' Column(열)에 있는 광역자치단체/기초자치단체(행정시) data를 이용하여 광역자치단체-기초자치단체(행정시)별 박물관/미술관의 총 수가 8개인 곳을 찾아주세요.
- 조건2: 결과 DataFrame의 '광역' Column(열)에 광역자치단체를, '기초' Column(열)에 기초자치단체(행정시)를 입력해주세요.
- 조건3: '광역' Column(열)은 4-1문제와 같이 광역자치단체의 우선순위에 따라 나열해주세요.
- 4-1의 province_dict 참고
- 조건4: 같은 광역자치단체가 있다면, '기초' Column(열)의 data는 가나다 순의 역순으로 나열해주세요.
- 조건5: 결과 DataFrame의 박물관/미술관의 총 수를 나타내는 Column(열)의 이름은 '박물관미술관수' 입니다.
- 예시: 박물관미술관수가 9개인 광역-기초자치단체(행정시)
- 조건6: Index는 숫자(정수) 오름차순으로 설정해주세요.
- 조건7: 'df_result' 변수에 결과 DataFrame을 할당하세요.
📌 답안
df = df_target.groupby(['광역','기초'],dropna=False).size().to_frame(name='박물관미술관수')
df = df[df['박물관미술관수'] == 8]
df = df.sort_values(by=['기초'], ascending=False).sort_values(by=['광역'], key = lambda x : x.map(province_dict))
df_result = df.reset_index()문제 4-3) 원하는 정보 얻기 03 (10점) 💢🥲🤨📌
- 3단계의 DataFrame(df_target)을 이용하여 아래의 조건에 맞는 정보를 구하세요.
- 광역자치단체-박물관미술관구분(사립, 국립, 공립, 대학)의 평균 관람료 차이를 알아보고자 합니다.
- 조건1: df_target의 '광역'과 '박물관미술관구분' Column(열)에 있는 광역자치단체/박물관미술관구분 data를 이용하여 광역자치단체-박물관미술관구분별 평균 어른관람료-평균 어린이관람료 간 차이가 가장 크고 작은 곳을 찾아주세요.
- 단, 어른관람료 또는 어린이관람료가 둘 중 하나라도 0원(무료)인 박물관/미술관의 경우 평균 계산에서 제외해주세요.
- 조건3: 결과 DataFrame의 '광역' Index에 광역자치단체를, '박물관미술관구분' Index에 박물관미술관구분를 입력해주세요.
- 조건4: '광역' Index은 4-1문제와 같이 광역자치단체의 우선순위에 따라 나열해주세요.
- 4-1의 province_dict 참고
- 조건5: 결과 DataFrame의 '어른관람료' Column(열)은 광역자치단체-박물관미술관구분별 평균 어른 관람료를, '어린이관람료' Column(열)은 광역자치단체-박물관미술관구분별 평균 어린이 관람료를, '관람료차이' Column(열)은 광역자치단체-박물관미술관구분별 평균 어른 관람료 - 평균 어린이 관람료(차액)을 입력해주세요.
- 어른/어린이 관람료 및 관람료차이는 평균값에서 소숫점 첫째 자리에서 반올림한 정수 값을 입력해주세요.
- 예시: 2978.5원 -> 2980.0원(소숫점 첫째 자리에서 반올림) -> 2980원(정수 값)
- 예시: 청소년관람료-어린이관람료 차이가 가장 크고 작은 광역자치단체-박물관미술관구분
- 어른/어린이 관람료 및 관람료차이는 평균값에서 소숫점 첫째 자리에서 반올림한 정수 값을 입력해주세요.
- 조건6: 'df_result' 변수에 결과 DataFrame을 할당하세요.
📌 답안
df = df[(df['어른관람료'] != 0) & (df['어린이관람료'] != 0)]
df = df.pivot_table(index=['광역','박물관미술관구분'], values=['어른관람료', '어린이관람료'], aggfunc='mean').round(-1).astype(int)
df['관람료차이'] = df['어른관람료'] - df['어린이관람료']
df.sort_index(level=0, key=lambda x:x.map(province_dict), inplace=True)오답..
문제 4-4) 원하는 정보 얻기 04 (10점)💢🥲🤨📌
- 3단계의 DataFrame(df_target)을 이용하여 아래의 조건에 맞는 정보를 구하세요.
- 가족(어른2, 청소년1, 어린이1)이 공휴일에 제주특별자치도 제주시에 있는 미술관을 관람하려 합니다. 총 관람료가 2만원 이하, 공휴일 4시간 이상 관람 가능한 미술관 list를 보여주세요.
- 조건1: 가족(어른 2명, 청소년 1명, 어린이 1명)의 총 관람료가 2만원 이하여야 합니다.
- 조건2: 제주특별자치도의 제주시에 있는 미술관을 가려고 합니다.
- 미술관: 이 Test에서는 df_target의 시설명 Column(열)에 있는 data 중 <'미술관' 또는 '갤러리' 또는 '아트'> 라는 글자들이 포함되어 있는 곳을 '미술관'이라고 정의합니다.
- 조건3: 공휴일에 가고자 합니다. 공휴일에 4시간 이상 관람 가능한 미술관이어야 합니다.
- 조건4: 미술관 List의 Frame은 df_target과 동일합니다.
- 예시: 서울특별시 송파구에서 가족(어른2, 청소년1, 어린이1)이 총 관람료 2만원 이내로 공휴일에 4시간 이상 관람할 수 있는 박물관 List
- 조건5: 'df_result' 변수에 결과 DataFrame을 할당하세요.
📌 답안
4-3 못풀어서 패스..
Zero Base 데이터분석 스쿨
Daily Study Note

Study Log