
SQL보다는 크롤링 때문에 시간이 오래걸렸다.
파이썬 라이브러리 언제쯤 적응이 될런지..🥲
문제 1.
AWS RDS (MySQL) 에 프로젝트 관련 Database 를 생성하고, 접근 가능한 사용자 계정을 생성하세요.
- Database Name : oneday
- User Name / Password : oneday / 1234
#-----AWS연결-----
import mysql.connector
remote = mysql.connector.connect(
host = "database-1.cpc8kqyoiq1s.ap-southeast-2.rds.amazonaws.com" ,
port = 3306,
user = "admin",
password = "{pw}"
)
#-----DATABASE생성-----
sql = "CREATE DATABASE oneday"
cursor = remote.cursor()
cursor.execute(sql)
#-----oneday user 생성-----
sql = "CREATE USER 'oneday'@'%' identified by '1234'"
cursor = remote.cursor()
cursor.execute(sql)
#-----oneday user 권한부여-----
sql = "GRANT ALL ON oneday.* TO 'oneday'@'%'"
cursor = remote.cursor()
cursor.execute(sql)
#-----DATABASE 생성확인-----
sql = "SHOW CREATE DATABASE oneday"
cursor = remote.cursor(buffered=True)
cursor.execute(sql)
result = cursor.fetchall()
# print(result)
for i in result :
print(i)
#-----oneday 유저권한확인-----
sql = "SHOW GRANTS FOR 'oneday'@'%'"
cursor = remote.cursor(buffered=True)
cursor.execute(sql)
result = cursor.fetchall()
# print(result)
for i in result :
print(i)
문제 2.
스타벅스 이디야 데이터를 저장할 테이블을 다음의 구조로 생성하세요
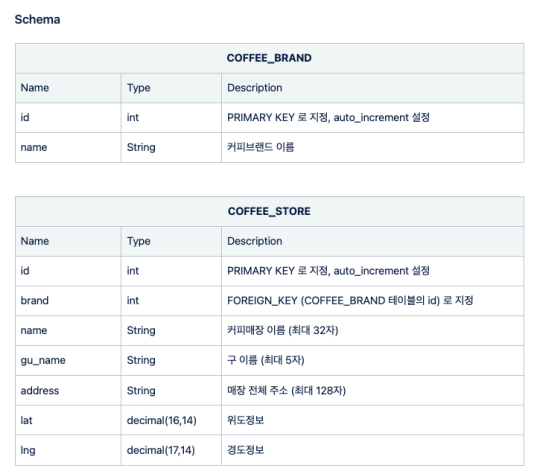
#-----oneday 데이터베이스 사용-----
sql = "use oneday"
cursor = remote.cursor(buffered=True)
cursor.execute(sql)
#-----coffee_brand 테이블 생성-----
sql = "CREATE TABLE coffee_brand (id INT NOT NULL AUTO_INCREMENT , name VARCHAR(32), PRIMARY KEY (id))"
cursor = remote.cursor(buffered=True)
cursor.execute(sql)
#-----coffee_store 테이블 생성-----
sql = "CREATE TABLE coffee_store (id INT NOT NULL AUTO_INCREMENT, brand INT, name VARCHAR(32), gu_name VARCHAR(5), address VARCHAR(128), lat DECIMAL(16,14), lng DECIMAL(17,14), PRIMARY KEY (id), CONSTRAINT FK_coffee FOREIGN KEY (brand) REFERENCES coffee_brand (id) )"
cursor = remote.cursor(buffered=True)
cursor.execute(sql)
#-----coffee_brand 테이블 정보확인-----
sql = "desc coffee_brand"
cursor = remote.cursor(buffered=True)
cursor.execute(sql)
result = cursor.fetchall()
for i in result :
print(i)
#-----coffee_store 테이블 정보확인-----
sql = "desc coffee_store"
cursor = remote.cursor(buffered=True)
cursor.execute(sql)
result = cursor.fetchall()
for i in result :
print(i)
문제 3.
Python 코드로 COFFEE_BRAND 데이터를 다음과 같이 입력하고 확인하세요
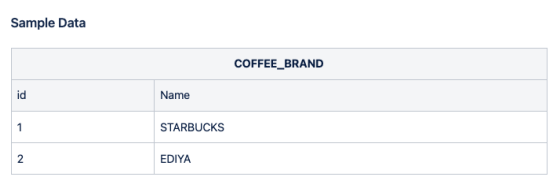
#-----coffee_brand 데이터 입력-----
sql = "INSERT INTO coffee_brand VALUES (1, 'STARBUCKS')"
cursor = remote.cursor(buffered=True)
cursor.execute(sql)
sql = "INSERT INTO coffee_brand VALUES (2, 'EDIYA')"
cursor = remote.cursor(buffered=True)
cursor.execute(sql)
#-----coffee_brand 데이터 조회-----
sql = "SELECT * FROM coffee_brand"
cursor = remote.cursor(buffered=True)
cursor.execute(sql)
result = cursor.fetchall()
for i in result :
print(i)
문제 4.
스타벅스 페이지에 접근하는 코드에서 팝업창이 없는 경우, 팝업창을 닫는 코드에서 에러가 발생합니다. 예외처리 해서 에러
메시지를 출력하고 실행이 중단되지 않도록 수정해주세요.
# 페이지 접근
from selenium import webdriver
try:
url = "https://www.starbucks.co.kr/store/store_map.do"
driver = webdriver.Chrome("../driver/chromedriver.exe")
driver.get(url)
driver.find_element_by_css_selector('/holyday_notice_close a').click
except :
print("팝업창이 없습니다.")
문제 5. 💢 💢
Python 코드로 스타벅스 페이지에서 데이터를 가져올때, COFFEE_STORE 테이블에 바로 입력하도록 수정하세요.
- 데이터 세트: 매장 이름, 매장이 위치한 구 이름, 매장 주소, 위도, 경도
- 필요한 데이터를 한세트씩 가져와서 COFFEE_STORE 테이블에 각각INSERT 하도록 합니다.
- 입력된 데이터의 총 갯수를 쿼리하여 결과를 확인합니다.
- 입력된 데이터 상위 10개를 쿼리하여 결과를 확인합니다.
from tqdm import tqdm_notebook
for i in tqdm_notebook(raw) :
name = i.get("data-name")
address = i.find(class_ = "result_details").contents[0]
gu_name = address.split()[1]
lat = i.get("data-lat")
lng = i.get("data-long")
sql = f"INSERT INTO coffee_store (brand, name, gu_name, address, lat, lng) VALUES ('1','{name}','{gu_name}','{address}','{lat}','{lng}')"
cursor = remote.cursor(buffered=True)
cursor.execute(sql)
print(name,gu_name,address,lat,lng)
remote.commit()📌 테스트코드 및 페이지코드 접근할 때 사용한 코드리뷰는 생략했습니다.
문제 6. 💢 💢
Python 코드로 이디야 페이지에서 데이터를 가져올때, COFFEE_STORE 테이블에 바로 입력하도록 수정하세요.
- 데이터 세트 : 매장 이름, 매장이 위치한 구 이름, 매장 주소, 위도, 경도
- 이디야 페이지에서 검색에 사용할 구 이름은 COFFEE_STORE 에서 중복을 제거하는 쿼리를 사용하여 가져와서 {‘서울 ‘ + 구이
름} 형식으로 변환하여 사용하도록 합니다. - 필요한 데이터를 한 세트씩 가져와서 COFFEE_STORE 테이블에 각각 INSERT 하도록 합니다.
- (주의) COFFEE_STORE 테이블에 입력할 구 이름은 {‘서울 ‘} 이 제거된 구 이름입니다.
- 입력된 데이터의 총 갯수를 쿼리하여 결과를 확인합니다.
- 입력된 데이터 상위 10개를 쿼리하여 결과를 확인합니다.
sql = "SELECT DISTINCT gu_name FROM coffee_store"
cursor = remote.cursor(buffered=True)
cursor.execute(sql)
result = cursor.fetchall()
for i in tqdm_notebook(result) :
# print(i[0])
key = '서울 ' + i[0]
# print(key)
driver.find_element(By.CSS_SELECTOR,"#keyword").send_keys(key)
driver.find_element(By.CSS_SELECTOR,"#keyword_div > form > button").click()
soup = BeautifulSoup(driver.page_source,"html.parser")
raw = soup.select("#placesList > li > a")
for i in raw:
try :
name = i.text.split("점 ")[0]
address = i.text.split("점 ")[1]
gu_name = i.text.split("점 ")[1].split()[1]
if len(gmaps.geocode(f"이디야 {name}점", language = "ko")) != 0 :
lat = gmaps.geocode(f"이디야 {name}점", language = "ko")[0].get("geometry")["location"]["lat"]
lng = gmaps.geocode(f"이디야 {name}점", language = "ko")[0].get("geometry")["location"]["lng"]
else :
lat = ""
lng = ""
time.sleep(0.05)
sql = f"INSERT INTO coffee_store (brand, name, gu_name, address, lat, lng) VALUES ('2','{name}','{gu_name}','{address}','{lat}','{lng}')"
cursor = remote.cursor(buffered=True)
cursor.execute(sql)
print(name,gu_name,address,lat,lng)
remote.commit()
except :
driver.find_element(By.CSS_SELECTOR,"#keyword").clear()
pass
driver.find_element(By.CSS_SELECTOR,"#keyword").clear()
# except :
# driver.find_element(By.CSS_SELECTOR,"#keyword").clear()
# pass📌 테스트코드 및 페이지코드 접근할 때 사용한 코드리뷰는 생략했습니다.
문제 7.
Python 코드에서 다음의 데이터를 쿼리를 사용하여 조회하세요.
- 스타벅스 매장 주요 분포 지역 (매장수가 많은 상위 5개 구이름, 매장 개수 출력)
- 이디야 매장 주요 분포 지역 (매장수가 많은 상위 5개 구이름, 매장 개수 출력)
- 구별 브랜드 각각의 매장 개수 조회 (구이름, 브랜드이름, 매장 개수 출력)
- 구별 브랜드 각각의 매장 개수 조회 (구이름, 스타벅스 매장 개수, 이디야 매장 개수 출력
# 스타벅스 매장 주요 분포 지역 (매장수가 많은 상위 5개 구이름, 매장 개수 출력)
sql = "SELECT gu_name, COUNT(id) as '스타벅스 매장 수' FROM coffee_store WHERE brand = 1 GROUP BY gu_name ORDER BY COUNT(id) DESC LIMIT 5 "
cursor = remote.cursor(buffered=True)
cursor.execute(sql)
result = cursor.fetchall()
for i in result:
print(i)# 이디야 매장 주요 분포 지역 (매장수가 많은 상위 5개 구이름, 매장 개수 출력)
sql = "SELECT gu_name, COUNT(id) as '이디야 매장 수' FROM coffee_store WHERE brand = 2 GROUP BY gu_name ORDER BY COUNT(id) DESC LIMIT 5 "
cursor = remote.cursor(buffered=True)
cursor.execute(sql)
result = cursor.fetchall()
for i in result:
print(i)# 구별 브랜드 각각의 매장 개수 조회 (구이름, 브랜드이름, 매장 개수 출력)
sql = "SELECT s.gu_name, b.name, count(s.id) as '매장 수' FROM coffee_store s LEFT OUTER JOIN coffee_brand b ON s.brand = b.id GROUP BY s.gu_name, b.name ORDER BY s.gu_name"
cursor = remote.cursor(buffered=True)
cursor.execute(sql)
result = cursor.fetchall()
for i in result:
print(i)# 구별 브랜드 각각의 매장 개수 조회 (구이름, 스타벅스 매장 개수, 이디야 매장 개수 출력)
sql = "WITH starbucks AS (SELECT gu_name, count(id) as c FROM coffee_store WHERE brand = 1 GROUP BY gu_name),ediya AS (SELECT gu_name, count(id) as c FROM coffee_store WHERE brand = 2 GROUP BY gu_name) SELECT s.gu_name, s.c as '스타벅스 매장 수', e.c as '이디야 매장수' FROM starbucks s, ediya e WHERE s.gu_name = e.gu_name"
cursor = remote.cursor(buffered=True)
cursor.execute(sql)
result = cursor.fetchall()
for i in result:
print(i)
문제 8.
시각화 프로젝트를 위하여 다음의 규칙으로 쿼리하여 CSV 파일로 저장합니다. (Python 코드로 작업)
- 전체 데이터를 가져오는데, 각 스타벅스 매장별로 이디야 전체 매장정보가 매칭되어 있어야 합니다. (정렬 : s_id, e_id 순)
- 다음의 형식으로 저장되어야 합니다. (브랜드 이름, 칼럼 명 주의)
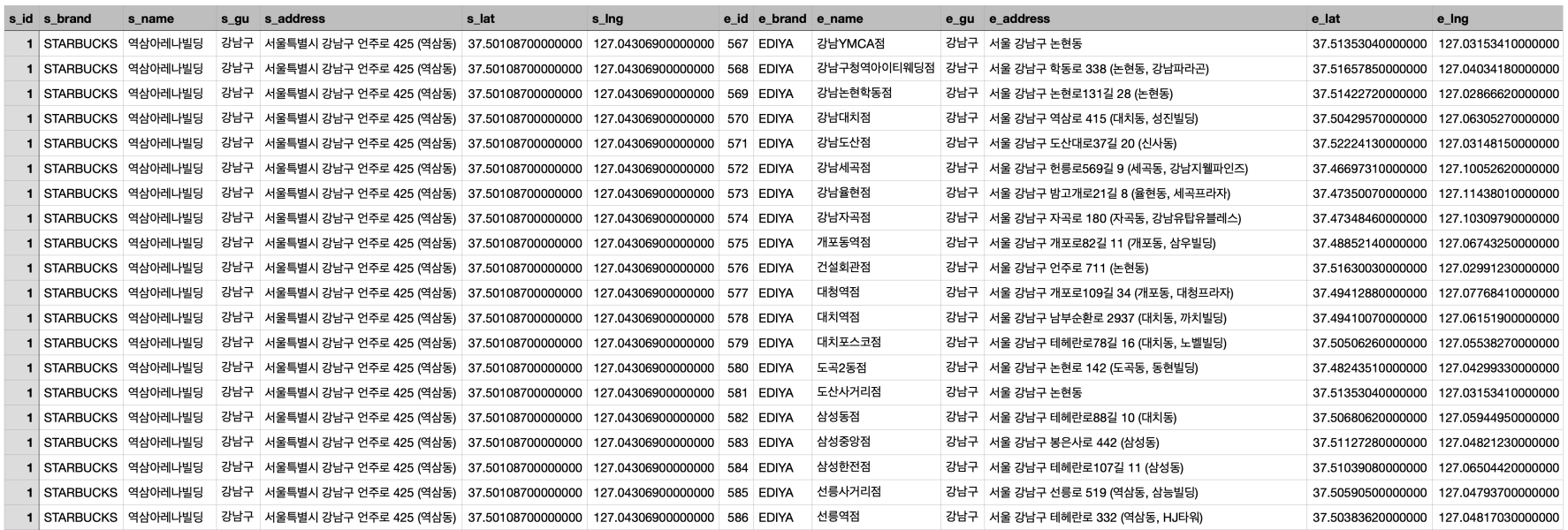
sql = ("SELECT * FROM (SELECT s.id AS s_id, b.name AS s_brand, s.name AS s_name, s.gu_name AS s_gu, s.address AS s_address, s.lat AS s_lat, s.lng AS s_lng FROM coffee_store s LEFT OUTER JOIN coffee_brand b on s.brand = b.id WHERE s.brand = 1) AS sta, (SELECT s.id AS e_id, b.name AS e_brand,s.name AS e_name, s.gu_name AS e_gu, s.address AS e_address, s.lat AS e_lat, s.lng AS e_lng FROM coffee_store s LEFT OUTER JOIN coffee_brand b on s.brand = b.id WHERE s.brand = 2) AS edi ORDER BY sta.s_id, edi.e_id")
cursor = remote.cursor(buffered=True)
cursor.execute(sql)
result = cursor.fetchall()
import pandas as pd
df = pd.DataFrame(result)
df.columns = ['s_id', 's_brand', 's_name', 's_gu', 's_address', 's_lat', 's_lng',
'e_id', 'e_brand', 'e_name', 'e_gu', 'e_address', 'e_lat', 'e_lng']
df.to_csv('./starbucks_ediya.csv', index = False, encoding = "euc-kr")8번문제의 답은 cross join이 더 적합하다 !


Zero Base 데이터분석 스쿨
Daily Study Note

Study Log