
알고리즘_~값
1. 최댓값
자료구조에서 가장 큰 값을 찾는다.
#max 모듈
class Max_Algorithm :
def __init__(self,list):
self.list = list
self.max = 0
def get_max_num(self):
# self.max = self.list[0]
for n in self.list :
if self.max < n :
self.max = n
return self.max#실행파일
import random
nums = random.sample(range(1,21),10)
import max
max_nums = max.Max_Algorithm(nums).get_max_num()
print(f'nums : {nums}')
print(f'max : {max_nums}')📁python 실습
리스트에서 아스키코드가 가장 큰 값을 찾는 알고리즘을 만들어보자.
#max 모듈
class Max_ascii :
def __init__(self,list):
self.list = list
self.max = 0
def get_max_char(self):
self.max = self.list[0]
for n in self.list :
if ord(self.max) < ord(n) :
self.max = n
return self.max#실행파일
chars = ['c','x','Q','A','e','P','p']
print(f'chars : {chars}')
import max
max_char = max.Max_ascii(chars).get_max_char()
print(f'max char : {max_char}')🫥 정렬에 비하면 굉장히 쉬운 코드로 최댓값 알고리즘을 구현할 수 있다!
❗ 참고할점은
최댓값 return 클래스에 숫자 list를 넣을 때와
문자 list를 넣을 때가 조금 다른데,
숫자리스트의 경우 get_max에서self.max = self.list[0]를 굳이 초기화하지 않아도된다.
(초기설정값 0으로 int 비교가 가능하므로)
다만, 문자의 경우 아스키코드로 변경해야하기때문에
self.max값을 list의 idx 0으로 초기화를 먼저한 후에
비교하여 초기화해주어야한다.
2. 최솟값
자료구조에서 가장 작은 값을 찾는다.
#min 모듈
class Min_Algorithm:
def __init__(self, list):
self.list = list
self.min = 0
def get_min(self):
self.min = self.list[0]
for n in self.list:
if self.min > n:
self.min = n
return self.min
#실행파일
import random
nums = random.sample(range(-20,21),10)
print(f'nums : {nums}')
import min
min_num = min.Min_Algorithm(nums).get_min()
print(f'min_num : {min_num}')📁python 실습
#min 모듈
class Min_ascii :
def __init__(self,list):
self.list = list
self.min = 0
def get_min_ascii(self):
self.min = self.list[0]
for str in self.list :
if ord(self.min) > ord(str) :
self.min = str
return self.min
#실행파일
chars = ['c','x','Q','A','e','P','p']
print(f'chars : {chars}')
import min
min_str = min.Min_ascii(chars).get_min_ascii()
print(f'min char : {min_str}')3. 최빈값
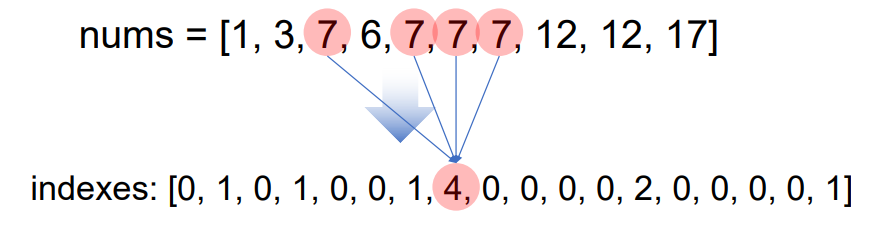
빈도수가 가장 높은 값
nums의 최대값 (17)+1 만큼의 idx 가진 indexes list를 하나 만들고, nums의 data를 스캔하면서 indexes의 idx data 자리에 +1 해준다
-> nums의 1은 indexes의 1번 idx에 +1 / 7은 indexes indexes 7번 idx에 +1
-> indexes의 가장 큰값의 idx번호가 nums의 최빈값
즉, indexes의 최대값 = 최빈값의 빈도
indexes의 최대값 idx번호 = 최빈값
#입력된 리스트의 최대값과 최대값 idx 번호를 출력하는 클래스 생성
class Max_Algorithm :
def __init__(self,list):
self.list = list
self.max = 0
self.max_idx = 0
def set_max_idx(self):
self.max = self.list[0]
self.max_idx = 0
for i, n in enumerate(self.list) :
if self.max < n :
self.max = n
self.max_idx = i
def get_max_num(self):
return self.max
def get_max_idx(self):
return self.max_idx
nums = [1,3,7,6,7,7,7,12,12,17]
print(f'nums : {nums}')
#nums : [1, 3, 7, 6, 7, 7, 7, 12, 12, 17]
print(f'nums length : {len(nums)}')
#nums length : 10
max_alo = Max_Algorithm(nums)
max_alo.set_max_idx()
max_num = max_alo.get_max_num()
#nums의 최대값 추출
max_idx = max_alo.get_max_idx()
#nums의 최대값의 idx 번호 추출
indexes = [0 for i in range(max_num+1)]
#최대값+1의 indexes 리스트 생성
print(f'indexes : {indexes}')
#indexes : [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
print(f'indexes length : {len(indexes)}')
#indexes length : 18
#indexes에 nums를 스캔하면서 해당idx 자리에 +1
for n in nums :
indexes[n] += 1
print(f'indexes : {indexes}')
#indexes : [0, 1, 0, 1, 0, 0, 1, 4, 0, 0, 0, 0, 2, 0, 0, 0, 0, 1]
#indexes를 다시 최대값과 해당 자리 idx번호를 추출하는 클래스에 할당
max_alo = Max_Algorithm(indexes)
max_alo.set_max_idx()
#indexes 최대값 추출(nums의 최빈값의 빈도추출)
max_num = max_alo.get_max_num()
#indexes 최대값 idx자리 추출(nums의 최빈값 추출)
max_idx = max_alo.get_max_idx()
print(f'max num : {max_num}') #max num : 4
print(f'max idx : {max_idx}') #max idx : 7
print(f'즉, {max_idx}의 빈도수가 {max_num}로 가장 높다')
#즉, 7의 빈도수가 4로 가장 높다📁python 실습
최빈값 알고리즘을 이용해서 학생 100명의 점수분포를 시각화하라
import random
scores = []
#71~100범위 중 5점단위 scores 생성
for i in range(100) :
score = random.randint(71,101)
if score != 100 :
score = score - (score % 5 )
scores.append(score)
print(f'scores : {scores}')
indexes = [0 for i in range(101)]
for idx in scores :
indexes[idx] += 1
print(f'indexes : {indexes}')
n=0
for score, cnt in enumerate(indexes) :
if cnt != 0 :
n += 1
print(f'{n}. {score}의 빈도수 : {cnt}\t',end='')
print('+'*cnt)이렇게 list의 최대값을 알 경우
최대값과 최대값 idx를 추출하는 class 없이도
빈도 확인이 가능하다.
4. 근삿값
가장 가까운 값을 찾자(특정값(참값)에 가까운 값)
import random
nums = random.sample(range(0,51),20)
print(f'nums : {nums}')
search_num = int(input('찾을 값 입력 : '))
print(f'search_num : {search_num}')
near_num = 0
div = 0
nums_max = 50
for i in nums :
abs_num = abs(i - search_num)
if abs_num < nums_max :
nums_max = abs_num
div = nums_max
near_num = i
print(f'near_num : {near_num}')
print(f'차이 : {div}')위 처럼 nums의 최대값을 변수에 초기화 시켜놓고,
nums의 data와 찾을 수의 차의 절댓값을 추출
절댓값이 최댓값보다 작을경우 near_num에 해당 data를 할당
근삿값과 찾고자 하는 값의 차이는 abs_num이나
for문이 계속 반복되면서 abs_num이 변경되므로,
따로 변수에 할당해주었다.
📁python 실습
❗ 강의 풀이와 달라서 오류가 있을 수 있음
근삿값 알고리즘을 이용해서 시험점수를 입력하면 학점이 출력되는 프로그램을 만들어보자
평균점수에 따른 학점 기준 점수는 다음과 같다.
- 95점에 근삿값 : A
- 85점에 근삿값 : B
- 75점에 근삿값 : C
- 65점에 근삿값 : D
- 55점에 근삿값 : F
class Scores :
def __init__(self,*s):
self.scores = list(s)
self.grade = {'A':95 ,'B':85,'C':75,'D':65,'F':55}
def total(self):
result = 0
for score in self.scores :
result += score
return result
def avg(self):
result = self.total() / len(self.scores)
return result
def max_algorithm(self):
max_score = 0
for score in self.grade.values():
if max_score < score :
max_score = score
return max_score
def grade_alphabet(self):
max_score = self.max_algorithm()
for grade, score in self.grade.items() :
abs_score = abs(self.avg() - score)
if abs_score < max_score :
max_score = abs_score
div = max_score
near_grade = grade
return near_grade
kor = int(input('input kor score : '))
eng = int(input('input eng score : '))
mat = int(input('input mat score : '))
sci = int(input('input sci score : '))
his = int(input('input his score : '))
score = Scores(kor,eng,mat,sci,his)
total_score = score.total()
avg_score = score.avg()
grade = score.grade_alphabet()
print(f'total_score : {total_score}')
print(f'avg_score : {avg_score}')
print(f'grade : {grade}')
Scores 클래스에서 튜플을 받는다.
점수를 입력할 경우 해당 튜플(점수들)을 list로 변환해
합계와 평균을 내는 total 메소드와 avg 메소드를 만들어 주었다.
점수별 등급을 딕셔너리에 담아주고
max_algorithm을 만들어 해당 딕셔너리의 최대값을 추출하는 메소드를
grade_alphabet 메소드에서 실행시켜 변수에 담아준 뒤
등급별 점수의 절댓값과 비교하여 근삿값을 알아낸다음
등급을 반환시켰다.
5. 평균
여러수나 양의 중간값을 갖는 수
1. 리스트 전체의 평균
import random
nums = random.sample(range(0,101),10)
print(f'nums : {nums}')
total = 0
for num in nums :
total += num
avg = total / len(nums)
print(f'nums의 평균 : {avg}')2. 50이상 90이하 수들의 평균
import random
nums = random.sample(range(0,101),10)
print(f'nums : {nums}')
total = 0
cnt = 0
for num in nums :
if num >= 50 and num <= 90 :
total += num
cnt += 1
avg = round(total / cnt,2)
print(f'nums의 50이상 90이하 수들의 평균 : {avg}')3. 정수들의 평균
nums = [90, 3, 93.5, 29, 86, 50.8, 44, 68, 10.9, 21]
print(f'nums : {nums}')
total = 0
cnt = 0
for num in nums :
if num - int(num) == 0 :
total += num
cnt += 1
avg = round(total / cnt,2)
print(f'nums의 정수들의 평균 : {avg}')이런 방식으로 여러 조건을 걸어 평균을 구할 수 있다.
📁python 실습
다음은 어떤 체조선수의 점수이다.
평균을 구하고 순위를 정하는 알고리즘을 만들어보자.
scores = [8.9,7.6,8.2,9.1,8.8,9.1,7.9,9.4,7.2,8.7]
현재순위 = {1:9.12,2:8.95,3:8.12,4:7.90,5:7.88}
❗ 강의 풀이와 달라서 오류가 있을 수 있음
class Score :
def __init__(self,scores):
self.scores = scores
self.rank = {1:9.12,2:8.95,3:8.12,4:7.90,5:7.88}
#총점 구하는 메소드
def total(self):
total = 0
for score in self.scores :
total += score
return total
#평균 구하는 메소드
def avg(self):
avg = self.total()/len(self.scores)
return avg
#현재 rank 출력
def now_rank(self):
print('현재 전체 순위')
for rank, score in self.rank.items() :
print(f'{rank}위 -> {score}')
#tatal rank 출력
def total_rank(self):
avg = self.avg()
target_idx = 0
#평균점수가 들어갈 idx 추출
for rank, score in self.rank.items() :
if avg >score :
target_idx = rank
break
#기존 점수 밀어내기
#평균이 들어갈예정이니 len()의 크기가 +1 되어야함
for i in range(len(self.rank)+1,target_idx-1,-1):
self.rank[i] = self.rank[i-1]
#평균점수 집어넣기
self.rank[target_idx] = self.avg()
#토탈 랭킹 출력
print('토탈 전체 순위')
for rank, score in self.rank.items():
print(f'{rank}위 -> {score}')
scores = [8.9,7.6,8.2,9.1,8.8,8.1,7.9,9.4,7.2,8.7]
현재순위 = {1:9.12,2:8.95,3:8.12,4:7.90,5:7.88}
alo = Score(scores)
alo.now_rank()
alo.total_rank()제로베이스 데이터취업스쿨
Daily Study Note
