
파이썬 자료구조(List)
자료구조란?
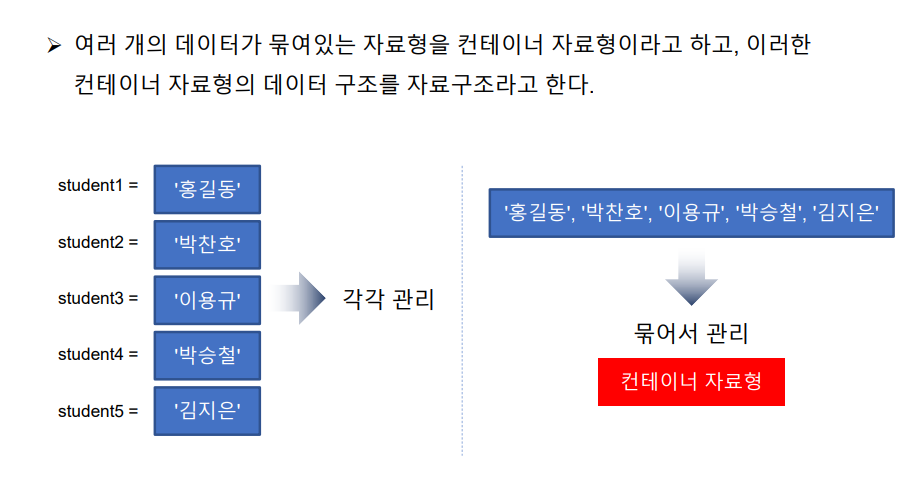
대표적인 컨테이너자료형(자료구조)
1. 리스트(List)
students = ['홍길동','박찬호','이용규','박승철','김지은']
#type을 출력하면
print(type(students)) #list2. 튜플(Tuple)
jobs = ('의사','속기사')
*한번 정해진 데이터는 변경할 수 없다.
#type을 출력하면
print(type(jobs)) #tuple3. 딕셔너리(Dic)
socores = {'kor':88 , 'eng':91 , 'mat':95 }
*'key' 와 value 값으로 이뤄짐
#type을 출력하면
print(type(socores)) #dic4. 셋트(set)
allsales = {100 , 150 , 90 , 100}
*중복된 데이터 허용X (하나의 데이터로 판독)
*마지막 200은 중복데이터라 출력되지 않음
#type을 출력하면
print(type(allsales)) #set하나하나 자세히 알아보자 !
[리스트]
1. 리스트 기본지식
[]를 이용해서 선언하고, 데이터 구분은','를 이용한다.
- 데이터 하나하나는 아이템(요소)라고한다.
- 숫자, 문자열, 논리형등 모든 기본데이터를 같이 저장할 수 있다.
- 리스트에 또다른 리스트를 넣을 수 있다.
students = ['홍길동','박찬호','이용규','박승철','김지은']
print('students : {}'.format(students))
#출력값 ['홍길동','박찬호','이용규','박승철','김지은']
list = ['홍길동',3.14,70,['박승철','김지은']]
print('list : {}'.format(list))
#출력값 list : ['홍길동', 3.14, 70, ['박승철', '김지은']]2. 리스트 아이템조회
A.인덱스를 이용한 아이템 조회
인덱스란
아이템에 자동으로 부여되는 번호표
e.g.
students = ['홍길동','박찬호','이용규','박승철','김지은']
앞에부터 0,1,2,3,4 인덱스 부여 됨
students = ['홍길동','박찬호','이용규','박승철','김지은']
print('students[0] : {}'.format(students[0])) #students[0] : 홍길동
print('students[1] : {}'.format(students[1])) #students[1] : 박찬호
print('students[2] : {}'.format(students[2])) #students[2] : 이용규
print('students[3] : {}'.format(students[3])) #students[3] : 박승철
print('students[4] : {}'.format(students[4])) #students[4] : 김지은
# 단, 범위 밖의 인덱스 번호를 출력할 시 error
print('students[5] : {}'.format(students[5])) #error
# 개별출력의type은 list가 아닌 요소의 type으로 출력
list = ['홍길동',3.14,70,['박승철','김지은']]
print(type(list[0])) #<class 'str'>
print(type(list[1])) #<class 'float'>
print(type(list[2])) #<class 'int'>
print(type(list[3])) #<class 'list'>B. for문을 활용한 아이템조회
#----for문활용 1----
students = ['홍길동','박찬호','이용규','박승철','김지은']
for i in range(5) : #0부터 4까지
print('student[{}] : {}'.format(i,students[i]))
#출력값
#student[0] : 홍길동
#student[1] : 박찬호
#student[2] : 이용규
#student[3] : 박승철
#student[4] : 김지은
#----for문 활용2-----
my_favorite_sports = ['수영','배구','야구','조깅']
for i in my_favorite_sports :
print(i)
#출력값
#수영
#배구
#야구
#조깅✔️ for문 리스트길이 활용
리스트의 길이란, 리스트에 저장된 아이템 개수를 뜻한다.
len(문자열) = 문자 개수(공백포함)
e.g. len('hello python') #12
len(리스트) = 리스트 아이템 개수
#range값에 len을 넣어서 활용 할 수 있음.
for i in range(len(students)) :
print(students[i])위 내용을 활용하여 for문을 이용한 두가지 조회를 복습해보면,
my_favorite_sports = ['수영','배구','야구','조깅']
#방법1
for i in range(len(my_favorite_sports)) : #4번반복=> range(0부터 3까지 4번)
print(my_favorite_sports[i])
#방법2
for i in my_favorite_sports :
print(i)✔️ 내부 리스트 조회
studens = [[1,19],[2,20],[3,22],[4,18],[5,21]]
#변수[아이템 인덱스번호][아이템 내부리스트의 인덱스번호]
for i in range(len(studens)):
print('{}반 학생 수 : {}'.format(studens[i][0],studens[i][1]))
#각각의 변수에 아이템 내부리스트 할당
for class_no, cnt in studens :
print('{}반 학생 수 : {}'.format(class_no,cnt))#실습문제 : 반별 학급수와 전체학생수 평균학생수출력
studens = [[1,18],[2,19],[3,23],[4,21],[5,20],[6,22],[7,17]]
sum_student = 0
for class_no, cnt in studens :
print('{}반 학생 수 : {}'.format(class_no,cnt))
sum_student += cnt
avg_student = sum_student / len(studens)
print('전체 학생 수 : {}명'.format(sum_student))
print('평균 학생 수 : {}명'.format(avg_student))C. while문을 활용한 아이템조회
while문을 이용해서 조회할 수 있다.
#방법1
n = 0
while n < len(cars) :
print(cars[n])
n += 1
#방법2
n = 0
flag = True
while flag :
print(cars[n])
n += 1
if n == len(cars) :
flag = False
#방법3
n = 0
while True :
print(cars[n])
n += 1
if n == len(cars) :
break##실습 학급별 학생 수와 전체 학생 수 그리고 평균 학생수를 출력해보자
#방법1
students_cnt = [[1,18],[2,19],[3,23],[4,21],[5,20],[6,22],[7,17] ]
sum_cnt = 0
avg_cnt = 0
n = 0
while True :
print('{}학급 학생수 : {}'.format(students_cnt[n][0],students_cnt[n][1]))
sum_cnt += students_cnt[n][1]
n += 1
if n == len(students_cnt) :
break
avg_cnt = sum_cnt / len(students_cnt)
print('전체 학생 수 : {}명'.format(sum_cnt))
print('평균 학생 수 : {}명'.format(avg_cnt))#방법2
n = 0
while True :
class_no = students_cnt[n][0]
cnt = students_cnt[n][1]
sum_cnt += cnt
print('{}학급 학생수 : {}'.format(class_no,cnt))
n += 1
if n == len(students_cnt) :
break
avg_cnt = sum_cnt / len(students_cnt)
print('전체 학생 수 : {}명'.format(sum_cnt))
print('평균 학생 수 : {}명'.format(avg_cnt))
#학급 학생 수가 가장 작은학급과 많은 학급을 출력해보자
students_cnt = [[1,18],[2,19],[3,23],[4,21],[5,20],[6,22],[7,17] ]
max_class = 0
max_cnt = 0
min_class = 0
min_cnt = 0
n = 0
while n < len(students_cnt) :
if min_cnt == 0 or students_cnt[n][1] < min_cnt :
min_class = students_cnt[n][0]
min_cnt = students_cnt[n][1]
if students_cnt[n][1] > max_cnt :
max_class = students_cnt[n][0]
max_cnt = students_cnt[n][1]
n += 1
print('학생수가 가장 적은 학급 : {}학급 ({}명)'.format(min_class,min_cnt))
print('학생수가 가장 많은 학급 : {}학급 ({}명)'.format(max_class,max_cnt))
D. enumerate 함수
인덱스와 아이템을 한번에 조회하자
sports = ['농구','축구','수구','마라톤','테니스']
#기존방법
for i in range(len(sports)) :
print('{} : {}'.format(i,sports[i]))
#enumerate함수 사용
for idx, value in enumerate(sports) :
print('{} : {}'.format(idx,value))
#출력값은 두가지 모두
#0 : 농구
#1 : 축구
#2 : 수구
#3 : 마라톤
#4 : 테니스문자열도 가능하다.
str = 'hello python'
for idx, value in enumerate(str) :
print('{} : {}'.format(idx, value))
#출력값
0 : h
1 : e
2 : l
3 : l
4 : o
5 :
6 : p
7 : y
8 : t
9 : h
10 : o
11 : n
#실습
#가장 좋아하는 스포츠가 몇번째에 있는지 출력하는 프로그램을 만들어보자
sports = ['농구','축구','수구','마라톤','테니스']
input_n = input('가장 좋아하는 스포츠입력 : ')
best = 0
for idx, value in enumerate(sports) :
if value == input_n :
best = idx+1
print('{}는 {}번째에 있습니다.'.format(input_n,best))
print('-'*60)#실습
#사용자가 입력한 문자열에서 공백의 개수를 출력해보자
message = input('메세지 입력 : ')
cnt = 0
for idx, value in enumerate(message) :
if value == ' ' :
cnt += 1
print('공백갯수 : {}개'.format(cnt))
3.리스트에 아이템 추가
A. append()
마지막 인덱스에 아이템 추가
cars = ['그랜저','소나타','말리부','카니발','쏘렌토']
print('cars : {}'.format(cars))
print('cars length : {}'.format(len(cars)))
print('last index : {}'.format(len(cars)-1))
#cars : ['그랜저', '소나타', '말리부', '카니발', '쏘렌토']
#cars length : 5
#last index : 4
cars.append('마세라티')
print('cars : {}'.format(cars))
print('cars length : {}'.format(len(cars)))
print('last index : {}'.format(len(cars)-1))
#cars : ['그랜저', '소나타', '말리부', '카니발', '쏘렌토', '마세라티']
#cars length : 6
#last index : 5실습 새로태어난 동생을 리스트에 추가해보자
family = [['아빠',40],['엄마',38],['나',9]]
family.append(['동생',1])
print(family)
#[['아빠', 40], ['엄마', 38], ['나', 9], ['동생', 1]]
for name, age in family :
print('{} : {}'.format(name,age))
#아빠 : 40
#엄마 : 38
#나 : 9
#동생 : 1B. insert()
리스트에 특정위치에 아이템 추가
insert ( 인덱스번호 , 추가아이템 )
words = ['I','a','girl']
words.insert(1,'am')
for word in words :
print('{} '.format(word), end='')
#I am a girl실습 사용자가 입력한 정수를 추가하되 오름차순정렬이 유지되게하라
numbers = [1,3,6,11,45,54,62,74,85]
input_num = int(input('숫자 입력 : '))
inset_index = 0
for idx,number in enumerate(numbers) :
print(idx,number)
if inset_index == 0 and number >= input_num :
inset_index = idx
numbers.insert(inset_index,input_num)
print(numbers)4. 리스트에 아이템 삭제
A. pop()
인덱스를 활용한 삭제
pop()은 마지막 인덱스 삭제
pop(3)은 3번째 인덱스 삭제
#기존 리스트
cars = ['그랜저','소나타','말리부','카니발','쏘렌토','재규어','람보르기니']
print('car list : {}'.format(cars))
print('car len : {}'.format(len(cars)))
print('car cnt : {}'.format(len(cars)-1))
#car list : ['그랜저', '소나타', '말리부', '카니발', '쏘렌토', '재규어', '람보르기니']
#car len : 7
#car cnt : 6
#마지막 삭제
cars.pop()
print('car list : {}'.format(cars))
print('car len : {}'.format(len(cars)))
print('car cnt : {}'.format(len(cars)-1))
#car list : ['그랜저', '소나타', '말리부', '카니발', '쏘렌토', '재규어']
#car len : 6
#car cnt : 5
cars = ['그랜저','소나타','말리부','카니발','쏘렌토','재규어','람보르기니']
#3번(카니발) 삭제
cars.pop(1) #3번(카니발) 삭제
print('car list : {}'.format(cars))
print('car len : {}'.format(len(cars)))
print('car cnt : {}'.format(len(cars)-1))
#car list : ['그랜저', '말리부', '카니발', '쏘렌토', '재규어', '람보르기니']
#car len : 6
#car cnt : 5#실습 점수표에서 최저, 최고점수를 삭제해보자
scores = [9.5,8.9,9.2,9.8,8.8,9.0]
max_score = 0
max_play = 0
min_score = 0
min_play = 0
for play,score in enumerate(scores) :
if max_score < score :
max_score = score
max_play = play
print('최대점수 : {} / 인덱스 : {}'.format(max_score,max_play))
scores.pop(max_play)
for play,score in enumerate(scores) :
if min_score == 0 or min_score > score :
min_score = score
min_play = play
print('최저점수 : {} / 인덱스 : {}'.format(min_score,min_play))
scores.pop(min_play)
print('삭제된후 : {}.format(scores))
#최대점수 : 9.8 / 인덱스 : 3
#최저점수 : 8.8 / 인덱스 : 3
#[삭제된후 : 9.5, 8.9, 9.2, 9.0]
B. remove()
특정 아이템 삭제
cars = ['그랜저','소나타','말리부','카니발','쏘렌토','재규어','람보르기니']
cars.remove('람보르기니')
print(cars)
#['그랜저','소나타','말리부','카니발','쏘렌토','재규어']
단 remove는 한개의 아이템만 삭제 가능하다.
만약, 삭제하려는 데이터가 2개이상이라면 반복문을 사용하자
#문제점
cars = ['그랜저','소나타','말리부','람보르기니','카니발','쏘렌토','재규어','람보르기니']
cars.remove('람보르기니') #앞에 있는 람보르기니만 삭제됨
print(cars)
# ['그랜저','소나타','말리부','카니발','쏘렌토','재규어','람보르기니']
# for문으로 해결
for car in cars :
if car == '람보르기니' :
cars.remove('람보르기니')
print(cars)
#while문으로 해결
print('람보르기니' in cars ) #cars에 람보르기니가 있으면 True(출력) 없으면 False(출력X)
while '람보르기니' in cars :
cars.remove('람보르기니')
print(cars)
#실습 사용자가 입력한 일정을 삭제하는 프로그램
to_do_list = ['마케팅회의','회의록정리','점심약속','월간업무보고','치과방문','마트장보기']
print(to_do_list)
remove_item = input('삭제 일정 입력 : ')
while remove_item in to_do_list :
to_do_list.remove(remove_item)
print(to_do_list)c. del
idx 번호를 활용한 특정아이템 삭제
students = ['홍길동','박찬호','강호동','박승철','김지은','강호동']
del students[1] #idx 1 박찬호삭제
print(students)
#['홍길동','강호동','박승철','김지은','강호동']#여러개도가능
students = ['홍길동','박찬호','강호동','박승철','김지은','강호동']
del students[1:4] #idx 1 박찬호부터 4김지은 앞까지 삭제
print(students)
#['홍길동', '김지은', '강호동']5. 리스트연결
A. extend
리스트에 다른 리스트를 확장
e.g. list_a.extend(list_b) = list_a에 list_b 추가
group_a = ['홍길동','박찬호','이용규']
group_b = ['강호동','박승철','김지은']
group_a.extend(group_b)
print('group_a : {}'.format(group_a)) #확장
print('group_b : {}'.format(group_b))
#group_a : ['홍길동', '박찬호', '이용규', '강호동', '박승철', '김지은']
#group_b : ['강호동', '박승철', '김지은']B. 덧셈연산자
리스트에 다른 리스트를 연결
e.g. list_a + list_b = list_c
group_a = ['홍길동','박찬호','이용규']
group_b = ['강호동','박승철','김지은']
group_c = group_a + group_b
print('group_a : {}'.format(group_a))
print('group_b : {}'.format(group_b))
print('group_c : {}'.format(group_c))
#group_a : ['홍길동', '박찬호', '이용규']
#group_b : ['강호동', '박승철', '김지은']
#group_c : ['홍길동', '박찬호', '이용규', '강호동', '박승철', '김지은']#실습 번호 리스트를 하나로 합쳐라
#단, 중복되는 숫자는 하나만
my_favorite = [1,3,5,6,7]
friend_favorite = [2,3,5,8,10]
add_list = my_favorite + friend_favorite
result = []
for numbers in add_list :
if numbers not in result :
result.append(numbers)
print('result : {}'.format(result))6. 리스트정렬
sort() : 오름차순정렬
sort ( reverse=False ) : 오름차순정렬
sort ( reverse=True ) : 내림차순정렬
students = ['홍길동','박찬호','이용규','강호동','박승철','김지은']
print(students)
#['홍길동', '박찬호', '이용규', '강호동', '박승철', '김지은']
students.sort()
print(students)
#['강호동', '김지은', '박승철', '박찬호', '이용규', '홍길동']
students.sort(reverse=False)
print(students)
#['강호동', '김지은', '박승철', '박찬호', '이용규', '홍길동']
students.sort(reverse=True)
print(students)
#['홍길동', '이용규', '박찬호', '박승철', '김지은', '강호동']실습 최저 및 최고 점수를 삭제한 후 총점과 평균을 출력하자
score = [9.5,8.9,9.2,9.8,8.8,9.0]
#오름차순
score.sort()
print('오름차순 : {}'.format(score))
#최고점수 삭제
max = score.pop(0)
print('최고점수 : {}'.format(max))
min = score.pop(len(score)-1)
print('최저점수 : {}'.format(min))
print('최고 최저 삭제한 최종점수 : {}'.format(score))
sum_score = 0
for num in score :
sum_score += num
avg_score = sum_score / len(score)
print('총점 : %.2f'%sum_score )
print('평균 : %.2f'%avg_score )7. 리스트 순서 뒤집기
reserve()
students = ['홍길동','박찬호','이용규','강호동','박승철','김지은']
students.reverse()
print(students)
#['김지은', '박승철', '강호동', '이용규', '박찬호', '홍길동']8. 슬라이싱
원하는 아이템만 뽑아내자
[n:m] = n <= value < m
value 추출
A. 리스트 슬라이싱
students = ['홍길동','박찬호','이용규','강호동','박승철','김지은']
print(students[2:4]) #index 2번부터 index4번앞까지
print(students[2:]) #index 2번부터 끝까지
print(students[:4]) #처음부터 index 4번 앞까지
print(students[2:-2]) #index 2번부터 뒤에서 2번째 앞까지
print(students[-5:4]) #뒤에서 5번째부터 index 4번 앞까지
print(students[-5:-2]) #뒤에서 5번째부터 뒤에서 2번째 앞까지
#출력값
#['홍길동', '박찬호', '이용규', '강호동', '박승철', '김지은']
#['이용규', '강호동']
#['이용규', '강호동', '박승철', '김지은']
#['홍길동', '박찬호', '이용규', '강호동']
#['이용규', '강호동']
#['박찬호', '이용규', '강호동']
#['박찬호', '이용규', '강호동']➕문자열 슬라이싱
str = 'hello python'
print(str) #hello python
print(str[2:8]) #llo py
print(str[2:]) #llo python
print(str[:5]) #hello
print(str[2:-2]) #llo pyth
print(str[-5:10]) #yth
print(str[-5:-2]) #yth
B. 슬라이싱 단계설정
numbers = [2,50,0.12,1,9,7,17,35,100,3.14]
print(numbers[2:-2]) #index 2번자리부터 끝에서 2번째 앞까지
print(numbers[2:-2:2]) #index 2번자리부터 끝에서 2번째 앞까지 2씩 건너뛰면서
print(numbers[:-2:2]) #처음부터 끝에서 2번째 앞까지 2씩 건너뛰면서
print(numbers[::2]) #처음부터 끝까지 2씩 건너뛰면서C. 아이템변경
#아이템변경 (개수가 부족하면 개수만큼 날라감)
students = ['홍길동','박찬호','이용규','강호동','박승철','김지은']
students[1:4] = ['park chanho','lee younggye','gang hodong']
# index 1번부터 4번앞까지 []로 변경
print(students)
#['홍길동', 'park chanho', 'lee younggye', 'gang hodong', '박승철', '김지은']단 아이템의 개수가 다를경우 삭제된다.
students = ['홍길동','박찬호','이용규','강호동','박승철','김지은']
students[1:4] = ['park chanho','lee younggye'] #강호동 날라감
print(students)
#['홍길동', 'park chanho', 'lee younggye', '박승철', '김지은']
#강호동 날라감D. slice함수
students[1:4] = students[slice(1,4)]
students = ['홍길동','박찬호','이용규','강호동','박승철','김지은']
print(students[2:4])
print(students[slice(2,4)])
#['이용규', '강호동']
#['이용규', '강호동']9. 이외 추가기능
A. count()
특정 아이템 개수 알아내기
students = ['홍길동','박찬호','강호동','박승철','김지은','강호동']
cnt = students.count('강호동')
print('강호동의 개수 : {}'.format(cnt))
#강호동의 개수 : 2실습 하루동안 헌혈을 진행한 후 혈액형 별 개수를 파악하는 프로그램을 만들어보자
import random
types = ['A','B','O','AB']
today_data = []
for i in range(100):
type = types[random.randrange(len(types))]
today_data.append(type)
for type in types :
print('{}형\t: {}개'.format(type,today_data.count(type)))B. index(item)
students = ['홍길동','박찬호','강호동','박승철','김지은','강호동']
print(students.index('강호동'))
#2 (가장앞쪽 하나만 출력)
print(students.index('강호동',3,7))
#7 (index 3부터 7까지 중 강호동 index번호)C. 곱셈연산
곱셈연산을 사용하면 아이템이 반복된다.
students = ['홍길동','박찬호','강호동']
print('students : {}'.format(students))
#students : ['홍길동', '박찬호', '강호동']
students_mul = students * 2
print('students_mul : {}'.format(students_mul))
#students_mul : ['홍길동', '박찬호', '강호동', '홍길동', '박찬호', '강호동']Zero Base 데이터분석 스쿨
Daily Study Note
