
👋에필로그
KT에서 주관하는 AICE(AI Certificate for Everyone) 자격증 취득을 위해 준비하며 정리한 내용입니다.
*AICE에서 제공되는 소개자료를 기반으로 작성되었습니다.
💡AICE💡
AICE는 AI Certificate for Everyone의 약자로 KT가 개발하고 한국 경제가 함께 주관하는 인공지능 활용능력을 평가하는 시험이다.
🏷️AICE의 핵심
AICE 자격증의 핵심은 인공지능을 제대로 다룰 수 있는지를 검증하는 것입니다.
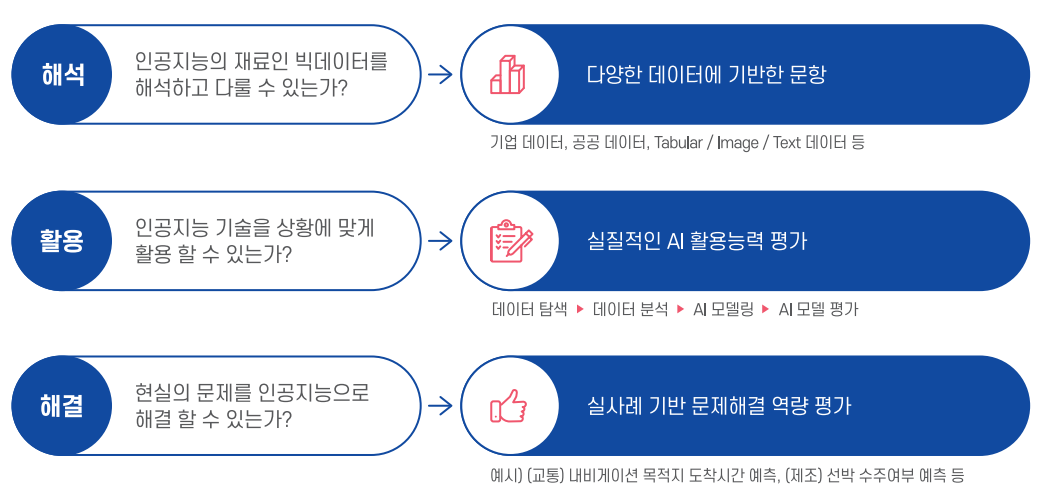
🏷️AICE의 종류
초등학생부터 성인, 비전공자부터 전공자까지 필요한 AI역량에 따라 5개의 수준으로 나뉘어 구성되어 있습니다.
(이 중에서 ASSOCIATE 자격증 취득에 도전합니다.
90분 동안 총 14문항을 풀며 80점 커트라인을 통과해야 취득할 수 있다.)


🏷️AICE ASSOCIATE 출제범위
AICE ASSOCIATE의 출제범위는 비즈니스 혁신 역량에 해당하는 데이터 분석 및 모델링까지 입니다.
- 탐색적 데이터 분석
- 데이터 전처리
- 머신러닝/딥러닝 모델링
- 모델 성능평가

💾AICE ASSOCIATE 총정리💾
*공부하면서 필요하다고 느낀 내용 위주로 정리하였습니다.
🚫주의사항🚫
🔘 주어진 답안 코드 작성란에 코드를 작성해야 합니다.
"# 여기에 답안코드를 작성하세요"라고 적혀있으니까 주의해서 봐야합니다.
🔘 주어진 코드 작성란을 제거할 경우 채점하지 않습니다.
🔘 만일의 사태에 대비해임시저장버튼을 수시로 눌러 저장해하는 습관을 가집시다.
🔘 제출 시에는최종 제출 및 종료버튼을 눌러야 제출됩니다.
🔘 주어진 문제에 맞게 코드를 작성해야 하기 때문에 문제에 제시된 가이드를 잘 읽고 코드를 작성해야 합니다.
🔘 변수명, 데이터프레임명을 잘 확인하고 맞게 작성해야 합니다.
🔘 문제를 유출할 수 없습니다.
1) 탐색적 데이터 분석
라이브러리 로드
분석에 필요한 다양한 라이브러리를 로드할 수 있어야 합니다.
라이브러리 로드 시 주어진 alias 조건에 맞게 로드해야 합니다.
없는 라이브러리는 !pip install로 설치하면 됩니다.
scikit-learnimport sklearn
pandasimport pandas as pd
numpyimport numpy as np
matplotlibimport matplotlib.pyplot as plt
seaborn
* seaborn은 설치가 필요합니다.!pip install seaborn import seaborn as sns
데이터 로드 및 확인
데이터 로드
주어진 변수명에 맞게 pandas 패키지를 활용해 데이터 프레임을 로드합니다.
pd.read_csv('{path}')df = pd.read_csv('파일 경로')
데이터 확인
행, 열, 데이터 프레임 정보, 통계 정보 등을 확인합니다.
.head()
앞행 n개 확인 (default: 5)df.head(n)
.tail()
뒷행 n개 확인 (default: 5)df.tail(n)
.columns
데이터 프레임 열 이름 확인df.columns
.shape
데이터 프레임 행, 열 개수 확인df.shape
.info()
열 정보, Null 개수, 열 타입, 사이즈 등의 데이터 프레임 정보 확인df.info()
.describe()
계산 가능한 값(수치형 변수)에 대한 통계 정보 확인df.describe()
.isnull()
Null인 데이터 확인
- 단순히
isnull()만 사용하기도 하지만sum()과 함께 사용되어 행이나 열별로의 Null 개수를 세기 위해 주로 사용합니다.df.isnull().sum()
.value_counts()
범주형 변수에 대해 각 범주별 빈도수 확인
normalize = True를 주면 정규화된 값으로 범주별 비율을 확인할 수 있습니다.df[열 이름].value_counts(normalize = False/True)
.select_dtypes()
원하는 데이터 타입에 해당하는 열만 데이터 프레임 형태로 확인
type:int,float,str등의 원하는 데이터 타입의 열만 추출.columns를 활용해 열 이름만 추출할 수 있다.df.select_dtypes(type)
2) 데이터 전처리
데이터 프레임 제거 및 변환
데이터 프레임 제거
.drop()
선택 열 제거
- 리스트 형태로 여러 개의 열을 한 번에 제거할 수 있습니다.
axis: 행(=0)과 열(=1)을 주어 원하는 방향으로 제거할 수 있습니다.inplace = True: 변수를 할당하지 않고 바로 적용할 수 있습니다.df.drop(axis=0/1, inplace = False/True)
데이터 프레임 변환
.replace()
값 변경
원하는 값으로 변경하기 위해 사용하며 결측값 대체나 범주형 변수를 라벨링할 때 사용합니다.
to_replace: 주로{'바꾸고자 하는 값': '바뀌는 값'}의 딕셔너리 형태로 주어집니다.inplace = True: 변수를 할당하지 않고 바로 적용할 수 있습니다.df.replace({'바꾸고자 하는 값': '바뀌는 값'}, inplace = False/True)
.fillna()
결측값 대체
inplace = True: 변수를 할당하지 않고 바로 적용할 수 있습니다.df['열이름'].fillna('바뀌는 값', inplace = False/True)
.astype()
데이터 프레임 열 타입 변환
astype은 바꾸고자 하는 열에 할당해주어야 변환 값이 적용된다.
type:int,float,str등으로 원하는 타입으로 변환df['열이름'] = df['열이름'].astype(type)
그룹 집계
.groupby()
그룹별 집계 함수
집계 함수에 맞게 그룹별로 원하는 열을 집계할 수 있다.
by: 그룹의 기준이 되는 열로 여러 열을 기준으로도 할 수 있다.as_index = bool: 그룹 기준 열을 인덱스화 할지 여부를 선택할 수 있다.- 집계함수:
sum(합),mean(평균),count(개수) 등의 집계함수df.groupby(by=['그룹기준 열'])['집계 대상 열'].집계함수()
정규화/표준화 (스케일링)
정규화/표준화는 각 변수 간의 측정단위 및 범위가 달라 값을 특정 값 사이로 변화해 비교가 가능할 수 있도록 하는 과정이다. 특히 거리를 기준으로 하는 모델에서는 꼭 필요한 과정이다.
정규화/표준화에는 다양한 방식이 있지만 ASSOCIATE에는 주로 Min Max Scale이 나온다고 한다.
Min Max Scale은 sklearn의 MinMaxScaler를 사용하여 적용한다.
MinMaxScaler
MinMaxScaler를 사용하기 위해서는 로드하는 과정이 필요하다.
fit: 기준이 되는 데이터를 기반으로 스케일러 값을 맞춘다.transform: 기준 값을 기반으로 스케일링을 적용한다.# import from sklearn.preprocessing import MinMaxScaler # 객체 생성 mms = MinMaxScaler() # 스케일링 적용 X_train = mms.fit_transform(X_train) X_test = mms.transform(X_test)
인코딩
인코딩은 문자열이나 범주형으로 된 변수를 수치화 하는 과정으로 문자열이 모델링 과정에서 해석되지 않기 때문에 필요한 과정이다.
라벨 인코딩 Label Encoding
LabelEncoder
LabelEncoder를 사용하기 위해서는 로드하는 과정이 필요하다.
fit: 기준이 되는 데이터를 기반으로 인코더 값을 맞춘다.transform: 기준 값을 기반으로 인코딩을 적용한다.# import from sklearn.preprocessing import LabelEncoder # 객체 생성 le = LabelEncoder() # 인코딩 적용 df['범주형 열'] = le.fit_transform(df['범주형 열'])
원-핫 인코딩 One-Hot Encoding
.get_dummies()
원-핫 인코딩은pandas내의 메소드로 적용한다.
columns: 원-핫 인코딩을 적용할 열 리스트drop_first=True: 첫번째 범주는 제외하고 원-핫 인코딩 적용.df = pd.get_dummies(df, columns=['범주형 열'], drop_first=True)
3) 모델링 및 성능 평가
데이터 분할
적합한 모델을 생성하기 위해서는 과적합(과대적합/과소적합)을 피하기 위해 검증하는 과정이 필요하다. 이를 위해서 데이터를 학습을 위한 학습용 데이터와 검증을 위한 검증용 데이터로 분할한다.
데이터 분할에는 sklearn의 train_test_split을 사용한다.
train_test_split()
train_test_split를 사용하기 위해서는 로드하는 과정이 필요하다.
- X_train, X_test, y_train, y_test 순으로 분할한 데이터 값을 반환한다.
train_size/test_size: 학습용/검증용 데이터를 분할할 기준이 된다. (주로 8:2나 7:3으로 분할한다.)stratify: 타겟 변수의 불균형이 심할 때 범주를 균형있게 분할 해준다.random_state: 랜덤 시드를 줌으로써 매번 같은 결과가 나올 수 있도록 설정한다.# import from sklearn.model_selection import train_test_split # 데이터 분할 X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=.8, stratify=y, random_state=2023)
모델 학습
fit()
- 생성된 모델을 학습용 데이터를 기반으로 학습한다.
# 모델 학습 model.fit(X_train, y_train)
모델 검증
score()
- 생성된 모델의 성능을 평가한다.
분류 모델은 정확도로, 회귀 모델은 결정계수로 검증한다.# 모델 검증 model.score(X_test, y_test)
모델 예측
predict()
- 생성된 모델로 데이터의 예측값을 계산한다.
# 모델 예측 model.predict(X_test)
모델 검증
모델 검증에 사용되는 지표도 모델에 따라 달라진다.
- 회귀 모델:
MSE,RMSE,MAE, ...- 분류 모델:
Accuracy,Precision,Recall,F1 Score, ...
모델 평가 지표는 sklearn의 함수들을 사용하여 계산할 수 있다.
평가 지표를 계산할 때, (Actual, Predicsion)으로 입력값을 주는 것이 좋다
# import
from sklearn.metrics import * # 모든 함수 로드
# 분류 모델 평가 지표
from sklearn.metrics import accuracy_score # 정확도
from sklearn.metrics import precision_score # 정밀도
from sklearn.metrics import recall_score # 재현율
from sklearn.metrics import f1_score # f1 score
from sklearn.metrics import confusion_matrix # 혼동행렬
from sklearn.metrics import accuracy_score # 모든 지표 한번에
# 회귀 모델 평가 지표
from sklearn.metrics import r2_score # R2 결정계수
from sklearn.metrics import mean_squared_error # MSE
from sklearn.metrics import mean_absolute_error # MAE+) Confusion Matrix Heatmap으로 시각화 하기
y_pred = model.predict(X_test) # 모델 예측값 저장
cf_matrix = confusion_matrix(y_test, y_pred)
print(cf_matrix) # 혼동 행렬
# 히트맵으로 시각화
sns.heatmap(cf_matrix, # 혼동 행렬
annot=True, # 주석
fmt='d') # 주석 포맷
plt.show()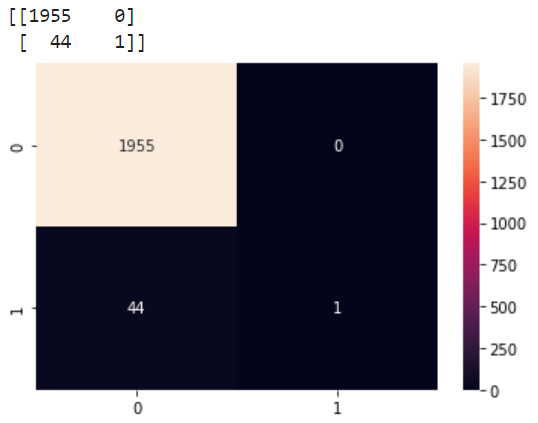
3-1) 머신러닝 모델링
타겟 변수 y가 수치형이냐 범주형이냐에 따라 분류/회귀 문제가 달라진다. 해당 부분을 꼭 확인해서 맞는 모델을 사용해야 한다.
Logistic Regression (로지스틱 회귀, 분류)
LogisticRegression
Logistic Regression을 사용하기 위해서는 로드하는 과정이 필요하다.
C: 규제 강도max_iter: 반복 횟수# import from sklearn.linear_model import LogisticRegression # 모델 생성 lg = LogisticRegression(C=1.0, max_iter=1000) # 모델 학습 lg.fit(X_train, y_train) # 모델 평가 lg.score(X_test, y_test)
Decision Tree (의사결정 나무, 분류/회귀)
DecisionTreeClassifier / DecisionTreeRegressor
Decision Tree를 사용하기 위해서는 로드하는 과정이 필요하다.
max_depth: 트리 깊이random_state: 랜덤 시드# import from sklearn.tree import DecisionTreeClassifier # 분류 from sklearn.tree import DecisionTreeRegressor # 회귀 # 모델 생성 dt = DecisionTreeClassifier(max_depth=5, random_state=2023) # 모델 학습 dt.fit(X_train, y_train) # 모델 평가 dt.score(X_test, y_test)
Random Forest (랜덤 포레스트, 분류/회귀)
RandomForestClassifier / RandomForestRegressor
Random Forest를 사용하기 위해서는 로드하는 과정이 필요하다.
n_estimators: 사용하는 트리 개수random_state: 랜덤 시드# import from sklearn.ensemble import RandomForestClassifier # 분류 from sklearn.ensemble import RandomForestRegressor # 회귀 # 모델 생성 rf = RandomForestClassifier(n_estimators=100, random_state=2023) # 모델 학습 rf.fit(X_train, y_train) # 모델 평가 rf.score(X_test, y_test)
XGBoost (분류/회귀)
XGBClassifier / XGBRegressor
XGBoost를 사용하기 위해서는 설치 및 로드하는 과정이 필요하다.
n_estimators: 사용하는 트리 개수# install !pip install xgboost # import from xgboost import XGBClassifier # 분류 from xgboost import XGBRegressor # 회귀 # 모델 생성 xgb = XGBClassifier(n_estimators=100) # 모델 학습 xgb.fit(X_train, y_train) # 모델 평가 xgb.score(X_test, y_test)
Light GBM (분류/회귀)
LGBMClassifier / LGBMRegressor
Light GBM을 사용하기 위해서는 설치 및 로드하는 과정이 필요하다.
n_estimators: 사용하는 트리 개수# install !pip install lightgbm # import from lightgbm import LGBMClassifier # 분류 from lightgbm import LGBMegressor # 회귀 # 모델 생성 lgbm = LGBMClassifier(n_estimators=100) # 모델 학습 lgbm.fit(X_train, y_train) # 모델 평가 lgbm.score(X_test, y_test)
3-2) 딥러닝 모델링
딥러닝은 tensorflow를 활용하여 모델링한다.
가이드에 맞게 모델을 생성하는 것이 중요하다.
# import
import tensorflow as tf
from tensorflow import keras모델 생성
주로 Sequential한 방법으로 레이어를 쌓는 문제가 나온다고 한다.
example
# 첫번째 레이어 - unit: 128, activation: relu, input_shape: (26,)
# 두번째 레이어 - unit: 64, activation: relu
# 세번째 레이어 - unit: 32, activation: relu
# 각 히든 레이어 사이에는 0.3비율의 Dropout 적용
# 아웃풋 레이어 - activation: sigmoid# import from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Dense, Dropout # 모델 생성 model = Sequential() # 모델 구조 model.add(Dense(128, input_shape=(26,), activation='relu')) model.add(Dropout(.3)) model.add(Dense(64, activation='relu')) model.add(Dropout(.3)) model.add(Dense(32, activation='relu')) model.add(Dropout(.3)) # output layer의 unit 수는 타겟 변수의 범주 개수와 동일하다. model.add(Dense(1, activation='sigmoid')) # 모델 요약 model.summary()
모델 학습
compile
딥러닝은 머신러닝과 달리 모델링 과정에서 컴파일이 필요하다.
optimizer: 모델링을 최적화하는 방법. 주로Adam을 사용한다.loss: 손실함수 - 타겟변수에 맞는 손실함수를 사용해야 한다.
- 회귀:
mse- 이진분류:
binary_crossentropy- 다중분류:
sparse_categorical_crossentropy,categorical_crossentropymetrics: 모니터링 지표로, 사용자 정의 함수를 사용할 수 있다.
- 회귀:
mse,rmse- 분류:
accuracy# 모델 컴파일 model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
EarlyStopping
모델의 과대적합을 방지하기 위해 학습이 개선되지 않는다면 학습을 종료시킨다.
monitor: 학습되는지 확인하는 기준mode: 모델 최적화의 기준 - 최대화/최소화patience: 모델 성능이 개선되지 않을때 지켜보는 횟수# import from tensorflow.keras.callbacks import EarlyStopping es = EarlyStopping(monitor='val_loss', mode='min')
ModelCheckpoint
모델을 학습하는 과정에서 일정한 간격으로 모델의 가중치를 저장하며 최적 모델을 선택한다.
filepath: 모델 저장 경로monitor: 모니터링하는 지표mode: 모델 최적화의 기준 - 최대화/최소화verbose: 정보 표시 정도(0, 1, 2)save_best_only=True: 가장 좋은 성능의 모델만 저장# import from tensorflow.keras.callbacks import ModelCheckpoint mc = ModelCheckpoint('my_checkpoibnt.ckpt', monitor='val_loss', mode='min', save_best_only=True)
fit
모델을 학습한다.
validation_data: 검증용 데이터.
종속변수와 타겟변수의 쌍으로 입력해야 한다.epochs: 학습 반복 횟수batch_size: 학습 시 한 번에 학습하는 데이터 사이즈callbacks: EarlyStopping, ModelCheckpoint와 같은 학습 과정에서 호출되는 함수history = model.fit(X_train, y_train, validation_data = (X_test, y_test), epochs=epochs, batch_size=batch_size, callbacks=[es, mc])
모델 검증
history
모델 학습 과정에서 모델 학습 결과를 저장함으로써 학습 과정의 변화를 확인할 수 있다.
history는 딕셔너리 형태로 저장되어 key값으로 접근할 수 있다.
loss: 학습 loss.val_loss: 검증 loss.accuracy: 학습 accuracy.val_accuracy: 검증 accuracy.# 시각화 예시 plt.plot(history.history['loss'], label='Train Loss') plt.plot(history.history['val_loss'], label='Validation Loss') plt.xlabel('Epochs') # X축 라벨 plt.ylabel('Loss') # Y축 라벨 plt.legend() # 범례 표시 - label값 plt.show()
👋프롤로그
시험이 일주일 남은 시점에서 정리한 내용이라 작성자 기준에서 알아두면 좋을 것 같은 내용 위주로 작성을 하였기 때문에 시험에 얼마나 도움이 될 지는 모르겠다.
그래도 정리하면서 시험 범위를 흐름에 따라 공부할 수 있어서 좋았던 것 같다. 모두에게 도움이 되기를 바라며 작성하였다.
자격 시험을 준비 중이라면 과정을 쭉 익힌다음에 AICE 홈페이지에서 제공해주는 샘플문항을 풀어보면 시험 대비가 될 것 같다.
+) 시험이 끝난 후 소감과 함께 내용을 보충하도록 하겠습니다. 다들 파이팅😄

21개의 댓글

특정타입 열들을 LabelEncoder 하는법
모든 오브젝트(문자열) 열을 선택
object_columns = titanic.select_dtypes(include=['object','category'])
모든 오브젝트(문자열) 열을 Label Encoding
for column in object_columns:
titanic[column] = label_encoder.fit_transform(titanic[column])

내비게이션
테이블에 대한 정보는 들어가서 샘플 문항에서 직접 확인 바랍니다.
sckitlearn 패키지 import
import sklearn as sk
pandas 패키지 import
import pandas as pd
json파일 읽어오기
df = pd.read_json('A0007IT.json')
Address1(주소1)에 대해 countplot그래프로 만들기
Seaborn을 활용
Address1(주소1)에 대해서 분포를 보여주는 countplot그래프
지역명이 없는 '-'에 해당되는 row(행)을 삭제
import seaborn as sns
sns.countplot(data=df, x='Address1')
plt.show()
df = df[df['Address1'] != '-']
5.실주행시간과 평균시속의 분포 확인
ime_Driving(실주행시간)과 Speed_Per_Hour(평균시속)을 jointplot 그래프 그리기
Seaborn을 활용
X축에는 Time_Driving(실주행시간)을 표시하고 Y축에는 Speed_Per_Hour(평균시속)을 표시
sns.jointplot(data=df, x='Time_Driving',y='Speed_Per_Hour')
plt.show()
jointplot 그래프에서 발견한 이상치 1개를 삭제
대상 데이터프레임: df
jointplot 그래프를 보고 시속 300 이상되는 이상치를 찾아 해당 행(Row)을 삭제하세요.
전처리 반영 후에 새로운 데이터프레임 변수명 df_temp에 저장하세요.
df_temp = df[df['Speed_Per_Hour'] < 300]
가이드에 따른 결측치 제거
대상 데이터프레임: df_temp
결측치를 확인하는 코드를 작성
결측치가 있는 행(raw)를 삭제
전처리 반영된 결과를 새로운 데이터프레임 변수명 df_na에 저장
df_temp.isna().sum()
df_na = df_temp.dropna(axis=0)
불필요한 변수 삭제
대상 데이터프레임: df_na
'Time_Departure', 'Time_Arrival' 2개 컬럼을 삭제
전처리 반영된 결과를 새로운 데이터프레임 변수명 df_del에 저장
df_del = df_na.drop(['Time_Departure','Time_Arrival'], axis=1)
조건에 해당하는 컬럼 원핫인코딩
대상 데이터프레임: df_del
원-핫 인코딩 대상: object 타입의 전체 컬럼
활용 함수: pandas의 get_dummies
해당 전처리가 반영된 결과를 데이터프레임 변수 df_preset에 저장
cols = df_del.select_dtypes('object').columns
df_preset = pd.get_dummies(data=df_del, columns=cols)
훈련, 검증 데이터셋 분리
대상 데이터프레임: df_preset
훈련 데이터셋 label: y_train, 훈련 데이터셋 Feature: X_train
검증 데이터셋 label: y_valid, 검증 데이터셋 Feature: X_valid
훈련 데이터셋과 검증데이터셋 비율은 80:20
random_state: 42
Scikit-learn의 train_test_split 함수를 활용하세요.
from sklearn.model_selection import train_test_split
x = df_preset.drop('Time_Driving', axis=1)
y = df_preset['Time_Driving']
X_train, X_valid, y_train, y_valid = train_test_split(x,y, test_size=0.2, random_state=42)
Decision tree로 머신러닝 모델 만들고 학습하기
트리의 최대 깊이: 5로 설정
노드를 분할하기 위한 최소한의 샘플 데이터수(min_samples_split): 3로 설정
random_state: 120로 설정
from sklearn.tree import DecisionTreeRegressor
dt = DecisionTreeRegressor(max_depth=5, min_samples_split=3, random_state=120)
dt.fit(X_train, y_train)
위 Decision tree 모델 성능 평가하기
예측 결과의 mae(Mean Absolute Error)를 구하기
성능 평가는 검증 데이터셋을 활용
11번 문제에서 만든 의사결정나무(decision tree) 모델로 y값을 예측(predict)하* 여 y_pred에 저장
검증 정답(y_valid)과 예측값(y_pred)의 mae(Mean Absolute Error)를 구하고 dt_mae 변수에 저장
from sklearn.metrics import mean_absolute_error
y_pred = dt.predict(X_valid)
dt_mae = mean_absolute_error(y_valid, y_pred)
Time_Driving(실주행시간)을 예측하는 딥러닝 모델을 만들기
Tensoflow framework를 사용하여 딥러닝 모델 구현
히든레이어(hidden layer) 2개이상으로 모델을 구성
dropout 비율 0.2로 Dropout 레이어 1개를 추가
손실함수는 MSE(Mean Squared Error)를 사용
하이퍼파라미터 epochs: 30, batch_size: 16으로 설정
각 에포크마다 loss와 metrics 평가하기 위한 데이터로 X_valid, y_valid 사용
학습정보는 history 변수에 저장
model = Sequential()
model.add(Dense(128, input_shape=(X_train.shape[1],), activation='relu'))
model.add(Dropout(0.2))
model.add(Dense(64, activation='relu'))
model.add(Dense(1))
model.compile(optimizer='adam', loss='mse', metrics='mse')
history = model.fit(X_train, y_train, epochs=30, batch_size=16, validation_data=(X_valid, y_valid))
위 딥러닝 모델 성능 평가
Matplotlib 라이브러리 활용해서 학습 mse와 검증 mse를 그래프로 표시
1개의 그래프에 학습 mse과 검증 mse 2가지를 모두 표시
위 2가지 각각의 범례를 'mse', 'val_mse'로 표시
그래프의 타이틀은 'Model MSE'로 표시
X축에는 'Epochs'라고 표시하고 Y축에는 'MSE'라고 표시
plt.plot(history.history['mse'])
plt.plot(history.history['val_mse'])
plt.legend(['mse','val_mse'])
plt.title('Model MSE')
plt.xlabel('Epochs')
plt.ylabel('Mse')
[비디오 선호조사 관련
8.원-핫인코딩은 범주형 변수를 1과 0의 이진형벡터로 변환하기 위해 사용하는 원-핫인코
딩으로 아래 조건에 해당하는 컬럼데이터를 변환하세요.
• 대상데이터프레임: medialabel
• 원-핫 인코딩 대상컬럼: ‘sex_cd’ : 성별코드, ‘age_cd: 연령코드
• 활용함수: Pandas의 get_dummies
• drop first옵션을 통해 가변수(dummy variable) 1개 삭제
• 해당 전처리가 반영된 media_label를 데이터프레임변수 media_preset에 저장해 주세요
#어기에 답안코드를 작성하세요
media_preset = pd.get_dummies(data=media, columns=[‘sex_cd’, ‘age_cd’].drop
9. 훈련과 검증 각각에 사용할 데이터셋을 분리하려고 합니다.
‘favor_genre’ (선로장르) 컬럼을 Label(y), 나머지컬럼을 Feature(x)로 할당한 후 훈련 데이터셋과 분리하세요
ㅇ 대상 데이터셋 media_preset
ㅇ 훈련데이터셋: label y_train, 훈련데이터셋 Feature: X_train
ㅇ 검증 데이터셋 label : y_valid, 검증 데이터셋 Feature: X_valid
ㅇ 훈련 데이터셋과 검증데이터셋 비율은 70:30
ㅇ random_state: 22
ㅇ Scikit-learn의 train_split 함수를 활용하세요
ㅇ 데이터 분리시 y데이터를 원래 데이터의 분포와 유사하게 추출되도록 옵션을 적용하세요
#여기에 답안코드를 작성하세요
from sklearn model_selection import train_test_split
y=media[‘favor_genre’]
X=media.drop([‘favor_gnre’], axix=1)
X_train, X_valid, y_train, y_valid=train_test_split(X,y, test_size=0.3, random_state=22, st~~
10. 각 데이터들이 AI모델링 학습에 동일한 중요도로 반영되도록 하기 위해 데이터정규화
를 하려고 합니다
MinMaxScalar를 사용하여 아래 조건에 따라 데이터변수를 정규분포화, 표준화 하세요
ㅇ Scikit-learn의 MinMaxScalar를 사용하세요.
ㅇ 훈련데이터셋의 Feature는 정규분포화(fit_transform)를 하세요
ㅇ 검증데이터셋의 Feature는 표준화(transform)를 하세요
11. 엑스트라 트리는 분류, 회귀분석 등에 사용되는 앙상블 학습방법입니다.
아래 하이퍼 파라미터 설정값을 적용하여 ExtraTrees모델로 학습을 진행하세요.
• 결정트리의 개수는 70으로 설정하세요
• 트리의 최대길이는 10으로 설정하세요
• 최대 Feature개수는 10으로 설정하세요
• 노드를 분할하기 위한 최소한의 샘플 데이터 수는 3으로 설정하세요
• Random_state는 3030으로 설정하세요
• 엑스트라 트리모델을 etc변수에 저장해 주세요
• Fit를 활용해 모델을 학습해 주세요. 학습시 훈련데이터 셋을 활용해 주세요
#여기에 답안코드를 작성하세요
from sklearn ensemble import ExtraTreeClassifier
from sklearn metrics import accuracy_score
rf=ExtraTreesClassifier(n_estimators=70, max_features=10, max_depth=10, random_state=3030)
rf fit(X_train, y_train)
rf score(X_train, y_train)
Result: 0.910791~~~
• ** 사전 코드실행
• From sklearn ensemble import ExtraTreesClassifier, ExtraTreesRegressor
• From sklearn metrics import classification_report, confusion_matrix
12. 위 모델의 성능을 평가하려고 합니다.
• Y값을 예측하여 confusion matri를 구하고, heatmap그래프로 시각화하세요
• 또한, scikit-learn의 classification repor기능을 사용하여 성능을 출력하세요
• 성능은 ㄱㅁ증데이터 셋을 활용하세요
• 11번 문제에서 만든 모델로 y값을 예측(predict)하여 y_pred값에 저장하세요
• confusion_matrix를 구하고 heatmap그래프로 시각화하세요. 이때 aneetation을 포함시키세요
• Scikit-learn의 classification repor기능을 사용하여 클래스별 presision recll f1-score를 출력하고
from sklearn_matrics import confusion_matrix, classification_report
prediction = fr.predict(X_valid)
y_pred=prediction
conf_max=confusion_matrix(y_true=y_valid, y_pred=y_pred)
sns.heatmap(conf_mat, annot=True)
plt.show
13. 고객의 미디어 선호장르를 분류하는 딥러닝 모델을 만들려고 합니다 아래 토폴로지 그
림과 가이드에 따라 모델링하고 학습을 진행하세요
• Tensoflow tramework를 사용하고 아래 토폴로지에 맞는 딥러닝 모델을 만드세요
• EarlyStopping 콜백으로 정해진 epoch동안 모니터링 지표가 향상되지 않을 때 훈련을 중지하도록 설정하세요(모니터링 지표 val_loss)
• ModeCheckpoint콜백으로 validation performance가 좋은 모델을 tf_ai_best_model.h5파일로 저장하세요 (모니터링 지표 vald_loss)
• (모니터링 지표 )
• EarlyStopping 객체는 earlystp변수에, Modelchkpkpt 활용해 주세요
• 하이퍼파라미터 epchs 50, batch_size 16, droppoul 비율 0.3으로 설정해 주세요
• 학습정보는 history변수에 저장해 주세요

항공사 만족
Class(비행등급) 이 Economy인 고객의 평균 Flight Distance(비행거리)는?
df.groupby('Class')['Flight Distance'].mean()
( 조건 : 평균 mean, 합 sum, 최댓값 max, 최솟값 min )satisfaction 컬럼의 분포를 확인하는 histogram 그래프를 만드세요.
plt.hist(df['satisfaction'])
plt.title('satisfaction')
plt.xlabel('satisfaction')
plt.ylabel('customer')Class(비행등급) 와 Flight Distance(비행거리)를 활용하여 barplot그래프를 만드세요
sns.boxplot(x='Class', y='Flight Distance', data=df[['Class', 'Flight Distance']])결측치가 있을 경우 float와 int 타입은 0으로, object 타입은 최빈값으로 바꾸세요
df_na = df.copy()
df_na['Arrival Delay in Minutes'].fillna(0, inplace=True)
print(df_na.isnull().sum())모든 범주형 데이터를 Scikit-learn의 label Encoder를 활용하여 수치형 데이터로 바꾸세요
ㅇ LabelEncoder 라이브러리 호출
from sklearn.preprocessing import LabelEncoder
ㅇ LabelEncoder 객체 생성
label_encoder = LabelEncoder()
ㅇ df_pre = df_na.copy()
ㅇ 모든 오브젝트(문자열) 열을 선택
object_columns = df_pre.select_dtypes(include=['object'])
ㅇ 모든 오브젝트(문자열) 열을 Label Encoding
for column in object_columns:
df_pre[column] = label_encoder.fit_transform(df_pre[column])훈련과 검증 각각에 사용할 데이터셋을 분리하려고 합니다.
(조건) 예측해야되는 변수는 y에 나머지 변수는 X로 할당한 후 데이터를 분리하세요
X = df_pre.drop(['satisfaction'], axis = 1)
y = df_pre['satisfaction']
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 2024)
X_train.shape, X_test.shape, y_train.shape, y_test.shape
딥러닝 모델
- Tensorflow Framework를 활용하여 딥러닝 모델을 만드세요
- 히든레이어는 3개이상으로 모델을 구성하고 각각 과적합을 방지하는 dropout을 설정하세요
- earlysopping 콜백으로 정해진 epoch 동안 모니터링 지표가 향상되지 않을 때 훈련을 중지하도록 설정하세요
- ModelCheckpoint 콜백으로 validation performance가 좋은 모델을 best_model.h5 파일로 저장하세요
- 기본 조건 : epochs = 100, early_stop patience = 5, 나머지는 자유 import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout
model = Sequential()
model.add(Dense(32, activation='relu', input_shape=(X_train.shape[1],))) # 입력층
model.add(Dropout(0.2))
model.add(Dense(64, activation='relu')) # 입력층
model.add(Dropout(0.2))
model.add(Dense(64, activation='relu')) # 입력층
model.add(Dropout(0.2))
model.add(Dense(1, activation = 'linear'))
model.compile(loss= 'mse', optimizer = 'adam', metrics=['mse'])
from keras.callbacks import EarlyStopping, ModelCheckpoint
ㅇ 얼리 스탑 콜백 생성
early_stopping = EarlyStopping(monitor='val_loss', patience=3, restore_best_weights=True, verbose=1)
ㅇ 모델 체크포인트 콜백 생성
checkpoint = ModelCheckpoint(filepath='best_model.h5', monitor='val_accuracy', save_best_only=True)
ㅇ 모델 학습 시 얼리 스탑과 모델 체크포인트 콜백 추가
history = model.fit(X_train, y_train, epochs=50, batch_size=32, validation_data=(X_test, y_test), callbacks=[early_stopping, checkpoint])
가장 좋았던 모델을 이용해 예측하려고 합니다.
- 해당 모델을 불러와 테스트 데이터(x_test)를 예측하세요
- 예측 후 데이터는 y_pred로 저장하세요.
from keras.models import load_model
ㅇ 모델 불러오기
loaded_model = load_model('best_model.h5')
ㅇ 예측
y_pred = loaded_model.predict(x_test)
ㅇ 예측 결과 출력
print(y_pred)
스케일링 시 특정 컬럼의 데이터 A, B 로 주어질 경우에는
x_train[['A','B'] =scaler.fit_transform(x_train[['A','B']])
x_test[['A','B'] =scaler.transform(x_test[['A','B']])
특정'A'컬럼 값의 'a','b','c'로 구성된 'COL2'데이터 프레임 만들기 와 그룹화
COL2= COL1[COL1['A'].isin(['a', 'b', 'c' ])]
COL2.groupby('A').mean()
'숫자형 데이터 상관관계' 히트맵 예
corr=bhp_null.select_dtypes('number').corr()
sns.heatmap(corr,annot=True)
범주형 -최빈값, 연속형-평균값
DATA['A'].fillna(DATA['A'].mode()[0], inplace=True)
DATA['B'].fillna(DATA['B'].mean(),inplace=True)

- scikit-learn를 별칭(alias) sk로 임포트
import sklearn as sk- 판다스 임포트
import pandas as pd- merge
df_a = pd.read_json('A000IT7.json')
df_b = pd.read_csv('signal.csv')
df = pd.merge(df_a, df_b, how='inner', on='RID')- address1에 대해서 분포를 보여주는 countplot 그래프 시각화, Address1변수에 지역명이 없는 '-'에 해당되는 행 삭제
import seaborn as sns
sns.countplot(data=df, x='Address1')
plt.show()
df = df[df['Address1'] != '-']- Time_Driving과 Speed_Per_Hour을 jointplot 그래프 시각화
sns.jointplot(data=df, x='Time_Driving', y='Speed_Per_Hour')
plt.show()- 이상치, 불필요한 컬럼 삭제 후 재할당
df_temp = df[df['Speed_Per_Hour'] < 300]
df_temp = df_temp.drop(['RID'], axis=1)- 결측치 확인 및 삭제
df_temp.isna().sum()
df_na = df_temp.dropna(axis=0)- 불필요한 컬럼 삭제 후 재할당
df_del = df_na.drop(['Time_Departure', 'Time_Arrival'], axis=1)- 원 핫 인코딩
cols = df_del.select_dtypes('object').columns
df_preset = pd.get_dummies(data=df_del, columns=cols)- 데이터셋 분리 후 스케일링
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import RobustScaler
X = df_preset.drop(columns=['Time_Driving'], axis=1)
y = df_preset['Time_Driving']
X_train, X_valid, y_train, y_valid = train_test_split(X, y, test_size=0.2, random_state=42)
scaler = RobustScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_valid)- dt, rf 모델 생성 후 학습진행
from sklearn.tree import DecisionTreeRegressor
from sklearn.ensemble import RandomForestRegressor
dt = DecisionTreeRegressor(max_depth=5, min_samples_split=3, random_state=120)
rf = RandomForestRegressor(max_depth=5, min_samples_split=3, random_state=120)
dt.fit(X_train, y_train)
rf.fit(X_train, y_train)- mae 성능평가
from sklearn.metrics import mean_absolute_error
y_pred_dt= dt.predict(X_test)
y_pred_rf= rf.predict(X_test)
dt_mae = mean_absolute_error(y_valid, y_pred_dt)
print("Decision Tree MAE:", dt_mae)
rf_mae = mean_absolute_error(y_valid, y_pred_rf)
print("Random Forest MAE:", rf_mae)- 딥러닝 모델 생성
model = Sequential()
model.add(Dense(128, input_shape=(X_train.shape[1],), activation='relu'))
model.add(Dropout(0.2))
model.add(Dense(64, activation='relu'))
model.add(Dense(1))
model.compile(
optimizer='adam',
loss='mse',
metrics='mse'
)
history = model.fit(
X_train, y_train,
validation_data=(X_valid, y_valid),
epochs=30,
batch_size=16,
verbose=1
)- 학습 mse, 검증 mse 그래프로 표시
plt.plot(history.history['mse'], label='mse')
plt.plot(history.history['val_mse'], label='val_mse')
plt.title('Model MSE')
plt.xlabel('Epochs')
plt.ylabel('MSE')
plt.legend()
plt.show()
결측값 처리에 대해 내용 중 추가
df['age'].median() : 중앙값
df['age'].mode()[0] : 최빈 값
df.interpolate() : 컴퓨터가 알아서 결측치 바꾸기(보간법)
.fillna의 method='bfill' : 바로 뒤 데이터 값 / # method='ffill' : 바로 앞 데이터 값
.dropna : 결측치 있는 데이터 지우기
df = df.dropna(subset=['sex_type'])