1. 배열과 인덱스
- 배열과 같이 여러 데이터(자료)를 구조화해서 다루는 것을 자료 구조하고 함
- 자바는 배열 뿐만 아니라, 컬렉션 프레임워크라는 이름으로 다양한 자료구조를 제공함
- 컬렉션 프레임워크와 자료 구조를 설명하기 전에 먼저 자료 구조의 가장 기본이 되는 배열의 특징을 알아보는 강의 세션
package collection.array;
import java.util.Arrays;
public class ArrayMain1 {
public static void main(String[] args) {
int[] arr = new int[5];
//index 입력: O(1)
System.out.println("==index 입력: O(1)==");
arr[0] = 1;
arr[1] = 2;
arr[2] = 3;
System.out.println(Arrays.toString(arr));
//index 변경: O(1)
System.out.println("==index 변경: O(1)==");
arr[2] = 10;
System.out.println(Arrays.toString(arr));
//index 조회: O(1)
System.out.println("==index 조회: O(1)==");
System.out.println("arr[2] = " + arr[2]);
//검색: O(n)
System.out.println("==배열 검색: O(n)==");
System.out.println(Arrays.toString(arr));
int value = 10;
for (int i = 0; i < arr.length; i++) {
System.out.println("arr[" + i + "]:" + arr[i]);
if (arr[i] == value) {
System.out.println(value + " 찾음");
break;
}
}
}
}실행 결과
==index 입력: O(1)==
[1, 2, 3, 0, 0]
==index 변경: O(1)==
[1, 2, 10, 0, 0]
==index 조회: O(1)==
arr[2] = 10
==배열 검색: O(n)==
[1, 2, 10, 0, 0]
arr[0]:1
arr[1]:2
arr[2]:10
10 찾음메모리 그림
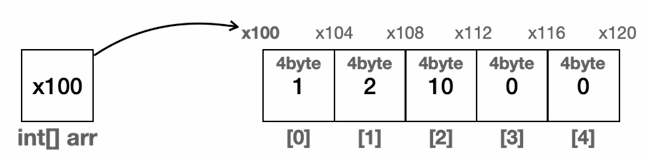
배열의 특징
- 배열에서 자료를 찾을 때 인덱스(index)를 사용하면 매우 빠르게 자료를 찾을 수 있음
- 인덱스를 통한 입력, 변경, 조회의 경우 한 번의 계산으로 자료의 위치를 찾을 수 있음
배열 index 사용 예시
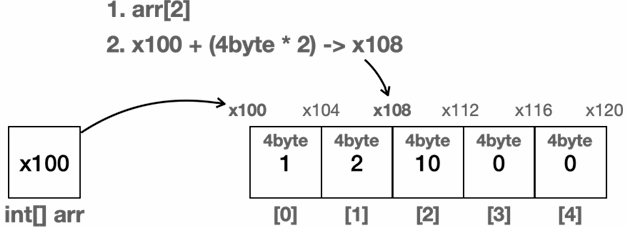
arr[2]에 위치한 자료를 찾는다고 가정- 배열은 메모리상에 순서대로 붙어서 존재함
int는4byte를 차지- 따라서 배열의 시작 위치인
x100부터 시작해서 자료의 크기(4byte)와 인덱스 번호를 곱하면 원하는 메모리 위치를 찾을 수 있음 - 배열의 시작 참조(
x100) + (자료의 크기(4byte) * 인덱스 위치(2)) =x108이 나온다. 여기에는 숫자10이 들어있음
간단 정리
- 공식: 배열의 시작 참조 + (자료의 크기 * 인덱스 위치)
arr[0]:x100 + (4byte * 0): x100arr[1]:x100 + (4byte * 1): x104arr[2]:x100 + (4byte * 2): x108
-
배열의 경우 인덱스를 사용하면 한 번의 계산으로 매우 효율적으로 자료의 위치를 찾을 수 있음
-
인덱스를 통한 입력, 변경, 조회 모두 한 번의 계산으로 필요한 위치를 찾아서 처리할 수 있음
-
정리하면 배열에서 인덱스를 사용하는 경우 데이터가 아무리 많아도 한 번의 연산으로 필요한 위치를 찾을 수 있음
배열의 검색
- 배열에 들어있는 데이터를 찾는 것을 검색이라고 함
- 배열에 들어있는 데이터를 검색할 때는 배열에 들어있는 데이터를 하나하나 비교해야 함
- 이때는 이전과 같이 인덱스를 사용해서 한 번에 찾을 수 없음
- 대신에 배열 안에 들어있는 데이터를 하나하나 확인해야 함
- 따라서 평균적으로 볼 때 배열의 크기가 클수록 오랜 시간이 걸림
배열의 크기와 검색 연산
- 배열의 크기 1:
arr[0]연산 1회- 배열의 크기 2:
arr[0],arr[1]연산 2회- 배열의 크기 3:
arr[0],arr[1],arr[2]연산 3회- 배열의 크기 10:
arr[0],arr[1],arr[2]...arr[9]연산 10회- 배열의 크기 1000:
arr[0],arr[1],arr[2]...arr[999]연산 1000회
- 배열의 순차 검색은 배열에 들어있는 데이터의 크기 만큼 연산이 필요함
- 배열의 크기가 n이면 연산도 n만큼 필요함
2. 빅오(O) 표기법
-
빅오(Big O) 표기법은 알고리즘의 성능을 분석할 때 사용하는 수학적 표현 방식임
-
이는 특히 알고리즘이 처리해야할 데이터의 양이 증가할 때, 그 알고리즘이 얼마나 빠르게 실행되는지 나타냄
-
여기서 중요한 것은 알고리즘의 정확한 실행 시간을 계산하는 것이 아니라, 데이터 양의 증가에 따른 성능의 변화 추세를 이해하는 것임
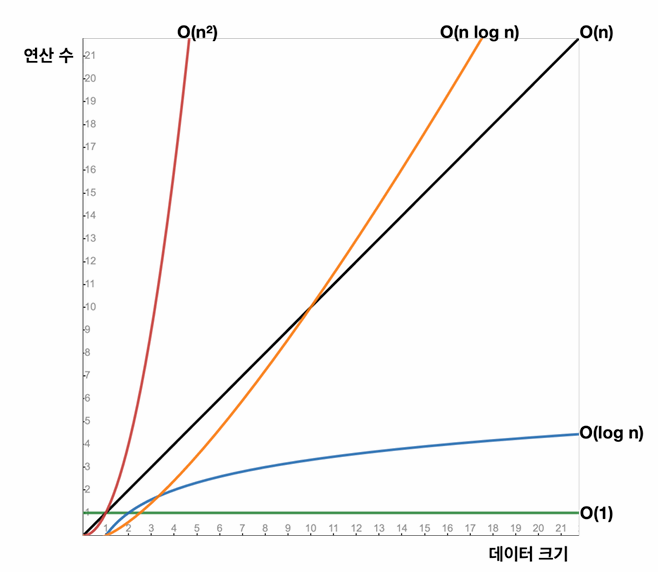
빅오 표기법의 예시
O(1)- 상수 시간 : 입력 데이터의 크기에 관계없이 알고리즘의 실행 시간이 일정함
- 예) 배열에서 인덱스를 사용하는 경우
O(n)- 선형 시간 : 알고리즘의 실행 시간이 입력 데이터의 크기에 비례하여 증가함
- 예) 배열의 검색, 배열의 모든 요소를 순회하는 경우
O(n^2)- 제곱 시간 : 알고리즘의 실행 시간이 입력 데이터의 크기의 제곱에 비례하여 증가한다
- 예) 보통 이중 루프를 사용하는 알고리즘에서 나타남
O(log n)- 로그 시간 : 알고리즘의 실행 시간은 데이터 크기의 로그에 비례하여 증가함
- 예) 이진 탐색
O(n log n)- 선형 로그 시간
- 예) 많은 효율적인 정렬 알고리즘들
-
빅오 표기법은 매우 큰 데이터를 입력한다고 가정하고, 데이터 양 증가에 따른 성능의 변화 추세를 비교하는데 사용함
- 쉽게 이야기해서 정확한 성능을 측정하는 것이 목표가 아니라 매우 큰 데이터가 들어왔을 때의 대략적인 추세를 비교하는 것이 목적임
- 따라서 데이터가 매우 많이 들어오면 추세를 보는데 상수는 크게 의미가 없어짐
-
이런 이유로 빅오 표기법에서는 상수를 제거함
- 예를 들어
O(n + 2),O(n / 2)도 모두O(n)으로 표시함
- 예를 들어
- 빅오 표기법은 별도의 이야기가 없으면 보통 최악의 상황을 가정해서 표기함
- 물론 최적, 평균, 최악의 경우로 나누어 표기하는 경우도 있음
- 예를 들어서 앞서 살펴본 배열의 순차 검색의 경우를 나누어 살펴보면,
- 최적의 경우
: 배열의 첫 번째 항목에서 바로 값을 찾으면O(1)이 됨 - 최악의 경우
: 마지막 항목에 있거나 항목이 없는 경우 전체 요소를 순회함, 이 경우O(n)이 됨 - 평균의 경우
: 평균적으로 보면 보통 중간쯤 데이터를 발견하게 됨- 이 경우
O(n/2)가 되지만, 상수를 제외해서O(n)으로 표기함 - 최악과 비교를 위해
O(n/2)로 표기하는 경우도 있음
- 이 경우
- 최적의 경우
- 배열의 인덱스를 사용하면 데이터의 양과 관계없이 원하는 결과를 한 번에 찾기 때문에 항상
O(1)이 됨
배열 정리
- 배열의 인덱스 사용 :
O(1)- 배열의 순차 검색 :
O(n)
-
배열에 데이터가 100,000건이 있다면 인덱스를 사용하면 1번의 연산으로 결과를 찾을 수 있지만, 순차 검색을 사용한다면 최악의 경우 100,000번의 연산이 필요함
-
배열에 들어있는 데이터의 크기가 증가할수록 그 차이는 매우 커짐
-
따라서 인덱스를 사용할 수 있다면 최대한 활용하는 것이 좋음

Backend development