직접 구현하는 Set1 - MyHashSetV1
add(value): 셋에 값을 추가한다. 중복 데이터는 저장하지 않는다.contains(value): 셋에 값이 있는지 확인한다.remove(value): 셋에 있는 값을 제거한다
package collection.set;
import java.util.Arrays;
import java.util.LinkedList;
public class MyHashSetV1 {
static final int DEFAULT_INITIAL_CAPACITY = 16;
LinkedList<Integer>[] buckets;
private int size = 0;
private int capacity = DEFAULT_INITIAL_CAPACITY;
public MyHashSetV1() {
initBuckets();
}
public MyHashSetV1(int capacity) {
this.capacity = capacity;
initBuckets();
}
private void initBuckets() {
buckets = new LinkedList[capacity];
for (int i = 0; i < capacity; i++) {
buckets[i] = new LinkedList<>();
}
}
public boolean add(int value) {
int hashIndex = hashIndex(value);
LinkedList<Integer> bucket = buckets[hashIndex];
if (bucket.contains(value)) {
return false;
}
bucket.add(value);
size++;
return true;
}
public boolean contains(int searchValue) {
int hashIndex = hashIndex(searchValue);
LinkedList<Integer> bucket = buckets[hashIndex];
return bucket.contains(searchValue);
}
public boolean remove(int value) {
int hashIndex = hashIndex(value);
LinkedList<Integer> bucket = buckets[hashIndex];
boolean result = bucket.remove(Integer.valueOf(value));
if (result) {
size--;
return true;
}
else {
return false;
}
}
private int hashIndex(int value) {
return value % capacity;
}
public int getSize() {
return size;
}
@Override
public String toString() {
return "MyHashSetV1{" + "buckets=" + Arrays.toString(buckets) + ", size=" + size + '}';
}
}buckets: 연결 리스트를 배열로 사용한다.- 배열안에 연결 리스트가 들어있고, 연결 리스트 안에 데이터가 저장된다.
- 해시 인덱스가 충돌이 발생하면 같은 연결 리스트 안에 여러 데이터가 저장된다.
initBuckets()- 연결 리스트를 생성해서 배열을 채운다. 배열의 모든 인덱스 위치에는 연결 리스트가 들어있다.
- 초기 배열의 크기를 생성자를 통해서 전달할 수 있다.
- 기본 생성자를 사용하면
DEFAULT_INITIAL_CAPACITY의 값인 16이 사용된다.
add(): 해시 인덱스를 사용해서 데이터를 보관한다.contains(): 해시 인덱스를 사용해서 데이터를 확인한다.remove(): 해시 인덱스를 사용해서 데이터를 제거한다.
package collection.set;
public class MyHashSetV1Main {
public static void main(String[] args) {
MyHashSetV1 set = new MyHashSetV1(10);
set.add(1);
set.add(2);
set.add(5);
set.add(8);
set.add(14);
set.add(99);
set.add(9); //hashIndex 중복
System.out.println(set);
//검색
int searchValue = 9;
boolean result = set.contains(searchValue);
System.out.println("set.contains(" + searchValue + ") = " + result);
//삭제
boolean removeResult = set.remove(searchValue);
System.out.println("removeResult = " + removeResult);
System.out.println(set);
}
}실행 결과
MyHashSetV1{buckets=[[], [1], [2], [], [14], [5], [], [], [8], [99, 9]], size=7}
bucket.contains(9) = true
removeResult = true
MyHashSetV1{buckets=[[], [1], [2], [], [14], [5], [], [], [8], [99]], size=6}MyHashSetV1은 해시 알고리즘을 사용한 덕분에 등록, 검색, 삭제 모두 평균O(1)로 연산 속도를 크게 개선했다.
남은 문제
- 해시 인덱스를 사용하려면 데이터의 값을 배열의 인덱스로 사용해야 한다.
- 그런데 배열의 인덱스는 0, 1, 2 같은 숫자만 사용할 수 있다. "A", "B"와 같은 문자열은 배열의 인덱스로 사용할 수 없다.
- 다음 예와 같이 숫자가 아닌 문자열 데이터를 저장할 때, 해시 인덱스를 사용하려면 어떻게 해야할까?
예)
MyHashSetV1 set = new MyHashSetV1(10);
set.add("A");
set.add("B");
set.add("HELLO");문자열 해시 코드
- 지금까지 해시 인덱스를 구할 때 숫자를 기반으로 해시 인덱스를 구했다. 해시 인덱스는 배열의 인덱스로 사용해야 하므로 0, 1, 2, 같은 숫자(양의 정수)만 사용할 수 있다.
- 따라서 문자를 사용할 수 없다.
- 문자 데이터를 기반으로 숫자 해시 인덱스를 구하려면 어떻게 해야 할까?
package collection.set;
public class StringHashMain {
static final int CAPACITY = 10;
public static void main(String[] args) {
//char
char charA = 'A';
char charB = 'B';
System.out.println(charA + " = " + (int)charA);
System.out.println(charB + " = " + (int)charB);
//hashCode
System.out.println("hashCode(A) = " + hashCode("A"));
System.out.println("hashCode(B) = " + hashCode("B"));
System.out.println("hashCode(AB) = " + hashCode("AB"));
//hashIndex
System.out.println("hashIndex(A) = " + hashIndex(hashCode("A")));
System.out.println("hashIndex(B) = " + hashIndex(hashCode("B")));
System.out.println("hashIndex(AB) = " + hashIndex(hashCode("AB")));
}
static int hashCode(String str) {
char[] charArray = str.toCharArray();
int sum = 0;
for (char c : charArray) {
sum += c;
}
return sum;
}
static int hashIndex(int value) {
return value % CAPACITY;
}
}실행 결과
A = 65
B = 66
hash(A) = 65
hash(B) = 66
hash(AB) = 131
hashIndex(A) = 5
hashIndex(B) = 6
hashIndex(AB) = 1- 모든 문자는 본인만의 고유한 숫자로 표현할 수 있다. 예를 들어서
'A'는65,'B'는66으로 표현된다. - 가장 단순하게
char형을int형으로 캐스팅하면 문자의 고유한 숫자를 확인할 수 있다. - 그리고
"AB"와 같은 연속된 문자는 각각의 문자를 더하는 방식으로 숫자로 표현하면 된다.65 + 66 = 131이다.
참고
- 컴퓨터는 문자를 직접 이해하지는 못한다.
- 대신에 각 문자에 고유한 숫자를 할당해서 인식한다.
- 상세한 내용은 ASCII 코드 표 찾아보기
해시 코드와 해시 인덱스
- 여기서는 hashCode()라는 메서드를 통해서 문자를 기반으로 고유한 숫자를 만들었다.
- 이렇게 만들어진 숫자를 해시 코드라고 한다.
- 여기서 만든 해시 코드는 숫자이기 때문에 배열의 인덱스로 사용할 수 있다.
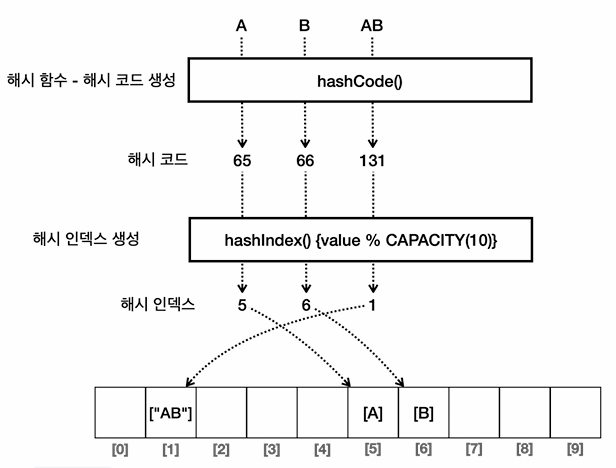
- hashCode() 메서드를 사용해서 문자열을 해시 코드로 변경한다.
- 그러면 고유한 정수 숫자 값이 나오는데, 이것을 해시 코드라고 한다.
- 숫자 값인 해시 코드를 사용해서 해시 인덱스를 생성한다.
- 이렇게 생성된 해시 인덱스를 배열의 인덱스로 사용하면 된다.
용어 정리
해시 함수(Hash Function)
-
해시 함수는 임의의 길이의 데이터를 입력으로 받아, 고정된 길이의 해시값(해시 코드)을 출력하는 함수이다.
- 여기서 의미하는 고정된 길이는 저장 공간의 크기를 뜻한다. 예를 들어서 int 형 1, 100은 둘 다 4byte를 차지하는 고정된 길이는 뜻한다.
-
같은 데이터를 입력하면 항상 같은 해시 코드가 출력된다.
-
다른 데이터를 입력해도 같은 해시 코드가 출력될 수 있다. 이것을 해시 충돌이라 한다
-
해시 충돌의 예
- "BC" B(66) + C(67) = 133
- "AD" A(65) + D(68) = 133
해시 코드(Hash Code)
- 해시 코드는 데이터를 대표하는 값을 뜻한다. 보통 해시 함수를 통해 만들어진다.
- 데이터 A의 해시 코드는 65
- 데이터 B의 해시 코드는 66
- 데이터 AB의 해시 코드는 131
해시 인덱스(Hash Index)
- 해시 인덱스는 데이터의 저장 위치를 결정하는데, 주로 해시 코드를 사용해서 만든다.
- 보통 해시 코드의 결과에 배열의 크기를 나누어 구한다.
- 요약하면, 해시 코드는 데이터를 대표하는 값, 해시 함수는 이러한 해시 코드를 생성하는 함수, 그리고 해시 인덱스는 해시 코드를 사용해서 데이터의 저장 위치를 결정하는 값을 뜻한다
정리
-
문자 데이터를 사용할 때도, 해시 함수를 사용해서 정수 기반의 해시 코드로 변환한 덕분에, 해시 인덱스를 사용할 수 있게 되었다.
-
따라서 문자의 경우에도 해시 인덱스를 통해 빠르게 저장하고 조회할 수 있다.
-
여기서 핵심은 해시 코드이다.
- 세상의 어떤 객체든지 정수로 만든 해시 코드만 정의할 수 있다면 해시 인덱스를 사용할 수 있다
자바의 hashCode()
-
해시 인덱스를 사용하는 해시 자료 구조는 데이터 추가, 검색, 삭제의 성능이 O(1)로 매우 빠르다. 따라서 많은 곳에서 자주 사용된다.
-
그런데 앞서 학습한 것 처럼 해시 자료 구조를 사용하려면 정수로 된 숫자 값인 해시 코드가 필요하다.
-
자바에는 정수 int, Integer 뿐만 아니라 char, String, Double, Boolean 등 수많은 타입이 있다.
- 뿐만 아니라 개발자가 직접 정의한 Member, User와 같은 사용자 정의 타입도 있다.
-
이 모든 타입을 해시 자료 구조에 저장하려면 모든 객체가 숫자 해시 코드를 제공할 수 있어야 한다
Object.hashCode()
- 자바는 모든 객체가 자신만의 해시 코드를 표현할 수 있는 기능을 제공한다.
- 바로 Object에 있는
hashCode()메서드이다.
public class Object {
public int hashCode();
}- 이 메서드를 그대로 사용하기 보다는 보통 재정의(오버라이딩)해서 사용한다.
- 이 메서드의 기본 구현은 객체의 참조값을 기반으로 해시 코드를 생성한다.
- 쉽게 이야기해서 객체의 인스턴스가 다르면 해시 코드도 다르다
package collection.set.member;
import java.util.Objects;
public class Member {
private String id;
public Member(String id) {
this.id = id;
}
public String getId() {
return id;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Member member = (Member) o;
return Objects.equals(id, member.id);
}
@Override
public int hashCode() {
return Objects.hash(id);
}
@Override
public String toString() {
return "Member{" + "id='" + id + '\'' + '}';
}
}- IDE가 제공하는 자동 완성 기능을 사용해서
equals(),hashCode()를 생성하자. - 여기서는
Member의id값을 기준으로equals비교를 하고,hashCode도 생성한다
package collection.set;
import collection.set.member.Member;
public class JavaHashCodeMain {
public static void main(String[] args) {
//Object의 기본 hashCode는 객체의 참조값을 기반으로 생성
Object obj1 = new Object();
Object obj2 = new Object();
System.out.println("obj1.hashCode() = " + obj1.hashCode());
System.out.println("obj2.hashCode() = " + obj2.hashCode());
//각 클래스마다 hashCode를 이미 오버라이딩 해두었다.
Integer i = 10;
String strA = "A";
String strAB = "AB";
System.out.println("10.hashCode = " + i.hashCode());
System.out.println("'A'.hashCode = " + strA.hashCode());
System.out.println("'AB'.hashCode = " + strAB.hashCode());
//hashCode는 마이너스 값이 들어올 수 있다.
System.out.println("-1.hashCode = " + Integer.valueOf(-1).hashCode());
//둘은 같을까 다를까?, 인스턴스는 다르지만, equals는 같다.
Member member1 = new Member("idA");
Member member2 = new Member("idA");
//equals, hashCode를 오버라이딩 하지 않은 경우와, 한 경우를 비교
System.out.println("(member1 == member2) = " + (member1 == member2));
System.out.println("member1 equals member2 = " + member1.equals(member2));
System.out.println("member1.hashCode() = " + member1.hashCode());
System.out.println("member2.hashCode() = " + member2.hashCode());
}
}실행 결과
obj1.hashCode() = 762218386
obj2.hashCode() = 796533847
10.hashCode = 10
'A'.hashCode = 65
'AB'.hashCode = 2081
-1.hashCode = -1
(member1 == member2) = false
member1 equals member2 = true
member1.hashCode() = 104101
member2.hashCode() = 104101Object의 해시 코드 비교
- Object가 기본으로 제공하는 hashCode()는 객체의 참조값을 해시 코드로 사용한다.
- 따라서 각각의 인스턴스마다 서로 다른 값을 반환한다.
- 그 결과 obj1, obj2는 서로 다른 해시 코드를 반환한다.
자바의 기본 클래스의 해시 코드
- Interger, String과 같은 자바의 기본 클래스들은 대부분 내부 값을 해시 코드를 구할 수 있도록 hashCode()메서드를 재정의해 두었다.
- 따라서 데이터의 값이 같으면 같은 해시 코드를 반환한다.
- 해시 코드의 경우 정수를 반환하기 때문에 마이너스 값이 나올 수 있다.
동일성과 동등성 복습
-
Object는 동등성 비교를 위한 equals() 메서드를 제공한다.
-
자바는 두 객체가 같다는 표현을 2가지로 분리해서 사용한다.
- 동일성(Identity) :
==연산자를 사용해서 두 객체의 참조가 동일한 객체를 가리키고 있는지 확인 - 동등성(Equality) :
equals()메서드를 사용하여 두 객체가 논리적으로 동등한지 확인
- 동일성(Identity) :
-
쉽게 이야기해서 동일성(Identity)은 물리적으로 같은 메모리에 있는 객체인지 참조값을 확인하는 것이고, 동등성은 논리적으로 같은지 확인하는 것
- 동일성은 자바 머신 기준이고 메모리의 참조가 기준으로 물리적이다.
- 동등성은 보통 사람이 생각하는 논리적인 것에 기준을 맞춘다. 따라서 논리적이다.
동등성은 예를 들면 같은 회원 번호를 가진 회원 객체가 2개 있다고 가정해보자.
User a = new User("id-100")
User b = new User("id-100")- 이런 경우 물리적으로 다른 메모리에 있는 객체이지만, 논리적으로는 같다고 표현할 수 있다.
- 따라서 동일성은 다르지만, 동등성은 같다.
문자의 경우도 마찬가지이다.
String s1 = new String("hello");
String s2 = new String("hello");- 이 경우 물리적으로는 각각의 "hello" 문자열이 다른 메모리에 존재할 수 있지만, 논리적으로는 같은 "hello"라는 문자열이다.
