멀티캠퍼스 데이터분석 4월 22일 수업 내용 — BeautifulSoup 심화, Selenium, SQLAlchemy, DB 저장
📌 목차
- 크롤링 가능 여부 확인 — robots.txt
- 크롤링 예제 — 상품 정보 사이트
- 데이터 정제 — 불필요한 텍스트 제거
- 접근 방식 2 — class 기준으로 컬럼별 추출
- CSV 저장 & 로드 옵션
- Selenium — 웹 브라우저 제어
- 네이버 쇼핑 크롤링 — Selenium + BeautifulSoup
- 스크롤 제어 & 데이터 추가 수집
- 수집 데이터 → MySQL DB 저장
- SQLAlchemy — to_sql() 로 DataFrame 저장
- 문제 — Selenium + BeautifulSoup + DB 저장
1. 크롤링 가능 여부 확인 — robots.txt
크롤링을 시작하기 전에 해당 사이트에서 허용하는 범위를 반드시 확인해야 합니다.
https://www.google.com/robots.txt도메인 뒤에 /robots.txt 를 붙이면 해당 사이트의 크롤링 허용/불허 규칙을 확인할 수 있습니다.
⚠️ 사이트마다 크롤링이 가능한 주소가 지정되어 있으며, 상업적 용도의 크롤링은 법적 문제가 생길 수 있습니다.
2. 크롤링 예제 — 상품 정보 사이트
import requests
from bs4 import BeautifulSoup as bs
import pandas as pd
# 1. 서버에 요청
res = requests.get('http://moons-86.iptime.org:8080/')
# 2. BeautifulSoup으로 파싱
soup = bs(res.text, 'html.parser')
# 3. id가 'product-1001'인 div 찾기
div_data = soup.find('div', attrs={'id': 'product-1001'})
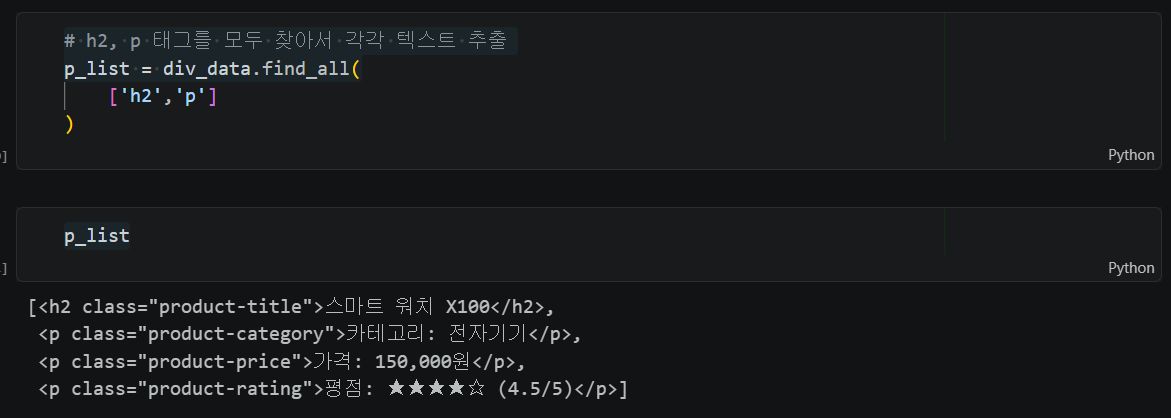
# h2, p 태그를 모두 찾아 텍스트 추출
p_list = div_data.find_all(['h2', 'p'])
[p.get_text() for p in p_list]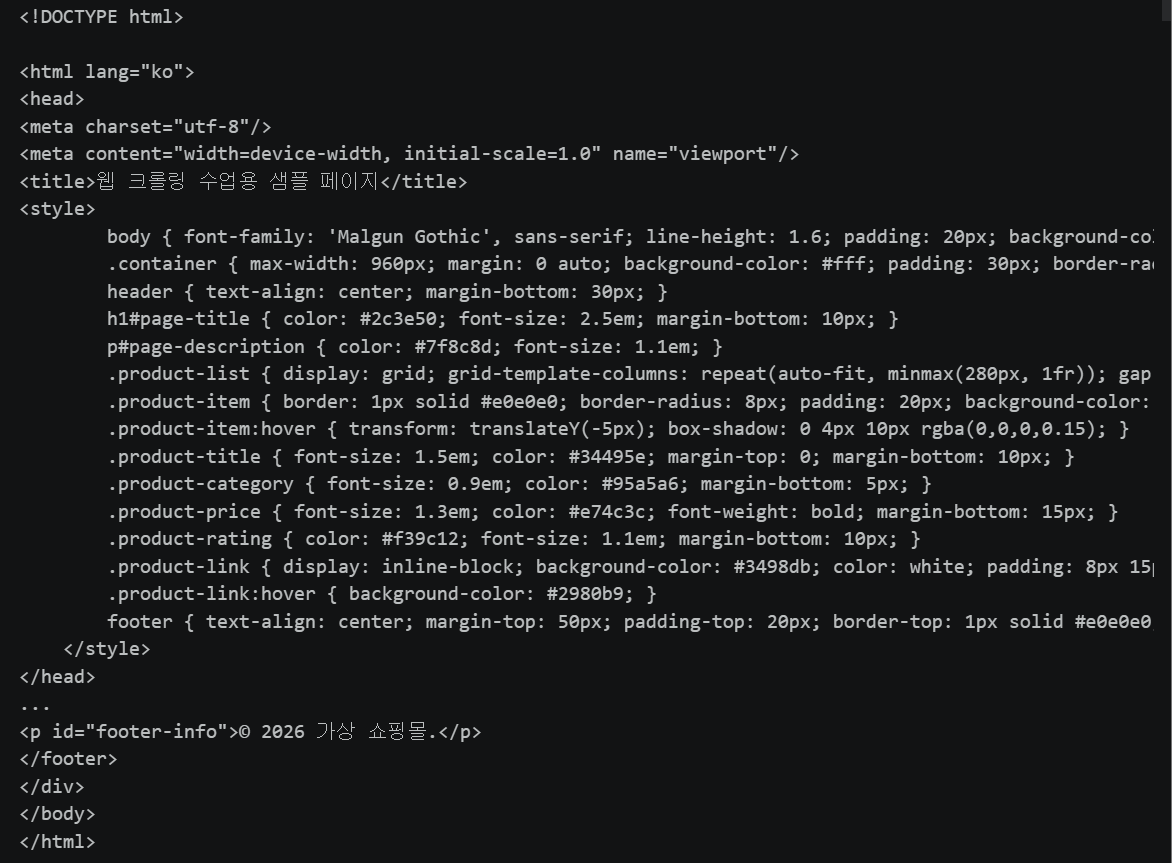
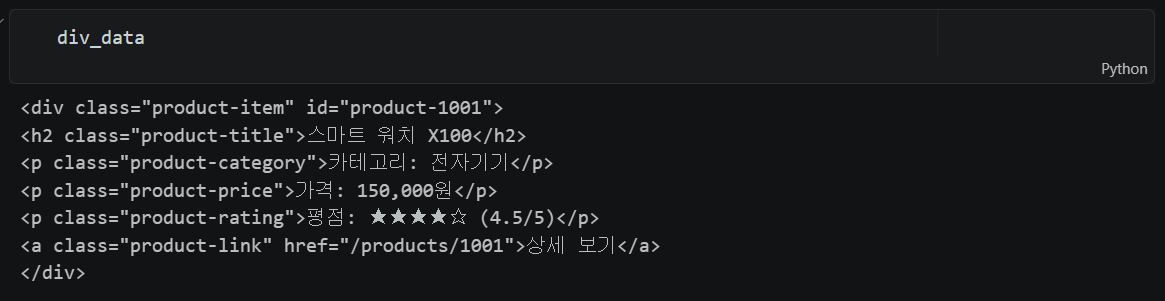
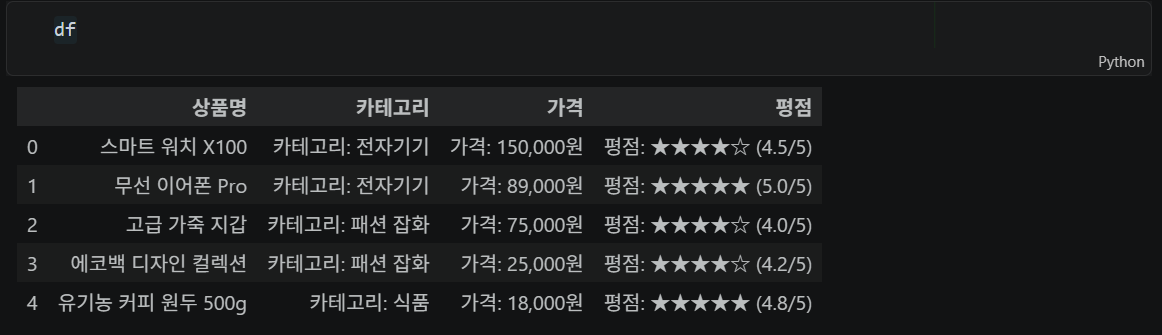
모든 상품 정보 추출 — 접근 방식 1
# class가 'product-item'인 div를 모두 찾기
div_list = soup.find_all('div', attrs={'class': 'product-item'})
values = []
for div in div_list:
p_list = div.find_all(['h2', 'p'])
value = [p.get_text() for p in p_list]
values.append(value)
df = pd.DataFrame(values, columns=['상품명', '카테고리', '가격', '평점'])
3. 데이터 정제 — 불필요한 텍스트 제거
크롤링한 데이터에는 '카테고리: ', '가격: ' 같은 접두 텍스트가 포함됩니다.
제거하는 방법 3가지입니다.
# 방법 1 — for문
for i in df['카테고리']:
print(i.replace('카테고리: ', ''))
# 방법 2 — Series.map() + lambda
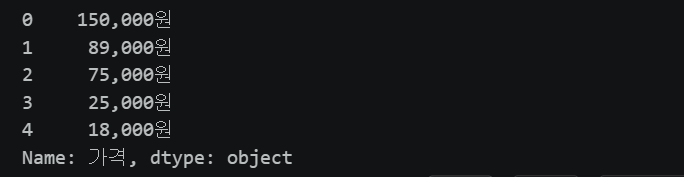
df['가격'].map(lambda x: x.replace('가격: ', ''))
# 방법 3 — Series.str.replace() ✅ 권장
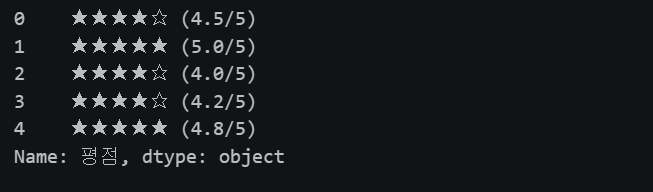
df['평점'].str.replace('평점: ', '')
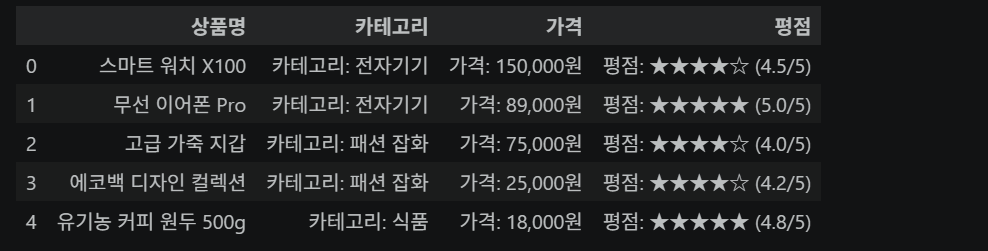
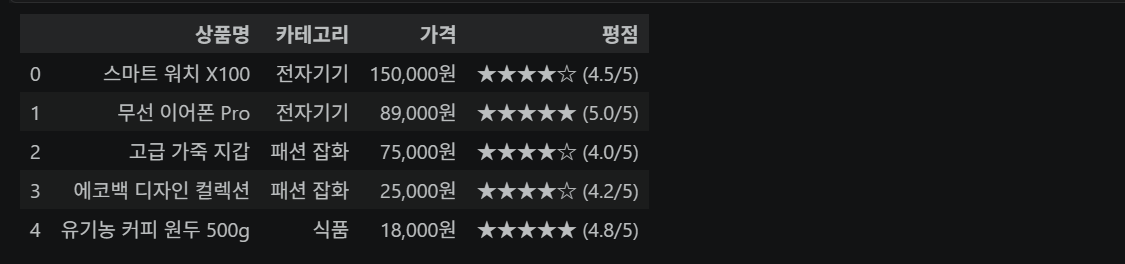
DataFrame 전체에 map() 적용
# ':' 기준으로 뒤의 값만 추출 + 공백 제거
df.map(lambda x: x.split(':')[-1].lstrip())💡
Series.replace()— value 단위로 치환
Series.str.replace()— 문자열 안의 특정 문자 치환
문자열 치환이 목적이라면.str.replace()를 사용하세요.
4. 접근 방식 2 — class 기준으로 컬럼별 추출
각 항목의 class를 직접 지정해 더 정확하게 데이터를 추출하는 방법입니다.
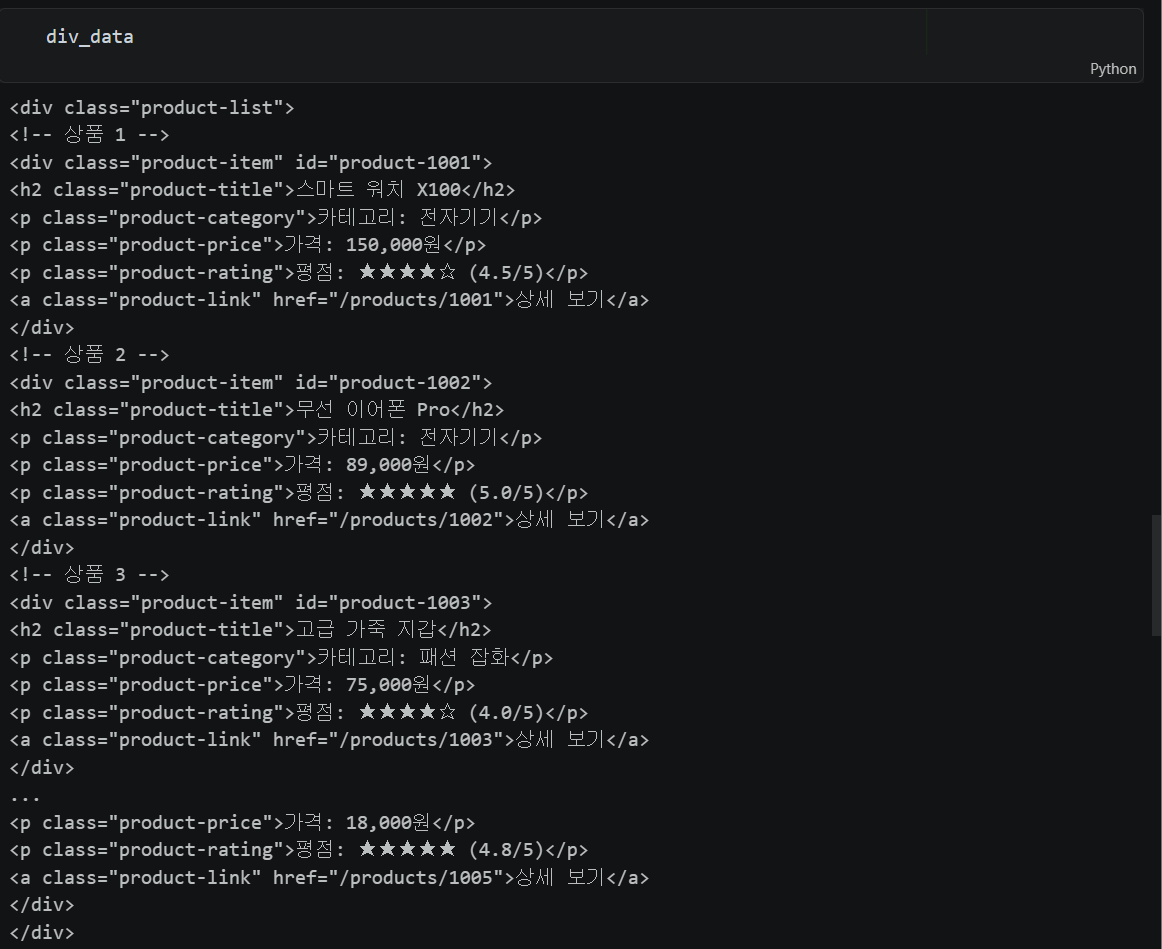
div_data = soup.find('div', attrs={'class': 'product-list'})
class_list = ['product-title', 'product-category', 'product-price', 'product-rating', 'product-link']
base_url = 'https://moons-86.iptime.org:8080'
dict_data = {}
for cls in class_list:
_list = div_data.find_all(attrs={'class': cls})
if cls == 'product-link':
# a 태그의 href 속성값 추출 후 base_url 결합
value = [base_url + link['href'] for link in _list]
else:
# ':' 뒤의 값만 추출 + 공백 제거
value = [data.get_text().split(':')[-1].strip() for data in _list]
# 'product-title' → 'title' (마지막 단어만 key로 사용)
key = cls.split('-')[-1]
dict_data[key] = value
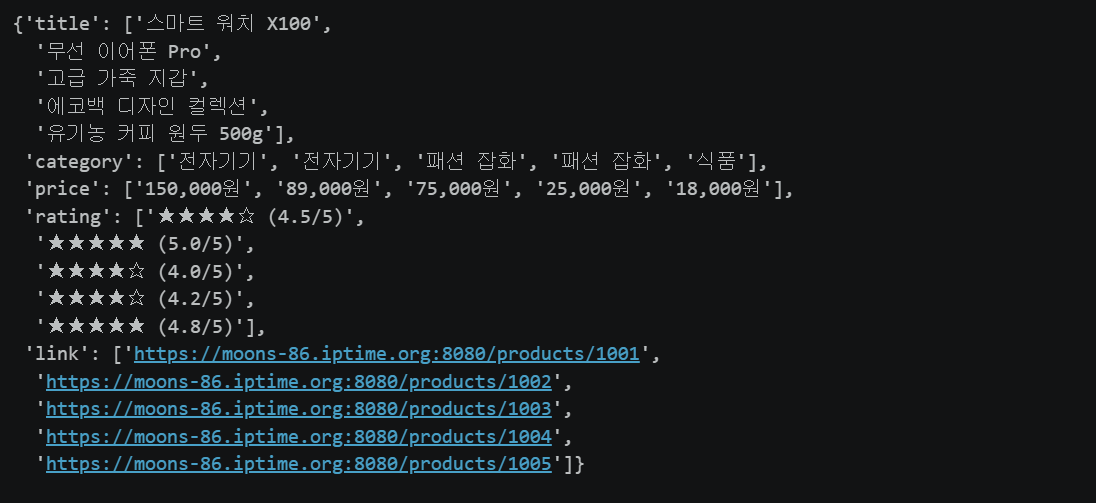
df = pd.DataFrame(dict_data)💡
태그['href']— 태그의 속성값을 딕셔너리처럼 접근합니다.
link['href']→'/product/1001'형태로 반환되므로base_url을 앞에 붙여야 합니다.
5. CSV 저장 & 로드 옵션
# 인덱스 제외하고 저장
df.to_csv('test.csv', index=False)
# 특정 컬럼만 선택해서 로드
pd.read_csv('test.csv', usecols=['title', 'category'])
# 특정 컬럼을 인덱스로 지정해서 로드
pd.read_csv('test.csv', index_col=0)| 매개변수 | 설명 |
|---|---|
index=False | 인덱스를 CSV에 저장하지 않음 |
usecols=[...] | 불러올 컬럼 선택 (위치 또는 컬럼명) |
index_col=n | n번째 컬럼을 인덱스로 사용 |
💡 인덱스를 저장하지 않으면(
index=False) 로드 시 불필요한 unnamed 컬럼이 생기지 않습니다.

6. Selenium — 웹 브라우저 제어
Selenium은 파이썬 코드로 웹 브라우저를 직접 제어하는 라이브러리입니다.
requests만으로는 접근할 수 없는 동적 웹 페이지(JS 렌더링) 크롤링에 사용합니다.
# webdriver -> 웹 브라우저를 제어
from selenium import webdriver
# By -> element(Tag) 접근하기 위한 기능
from selenium.webdriver.common.by import By
# Keys -> 키보드의 이벤트들
from selenium.webdriver.common.keys import Keys
# 브라우저 실행
driver = webdriver.Chrome()
# 주소 접속
driver.get('https://www.naver.com')
Selenium Tag 탐색 함수
| 함수 | 설명 | BS4 대응 |
|---|---|---|
find_element(By.xxx, 값) | 조건에 맞는 첫 번째 태그 | find() |
find_elements(By.xxx, 값) | 조건에 맞는 모든 태그 | find_all() |
By 속성 종류
| By | 설명 |
|---|---|
By.ID | id 속성으로 탐색 |
By.CLASS_NAME | class 속성으로 탐색 |
By.TAG_NAME | 태그명으로 탐색 |
By.LINK_TEXT | 링크 텍스트 내용으로 탐색 |
By.CSS_SELECTOR | CSS 셀렉터로 탐색 |
By.XPATH | XPath로 탐색 |
# 검색창 찾기 (id='query')
search_element = driver.find_element(By.ID, 'query')
# 텍스트 입력
search_element.send_keys('아이폰')
# ENTER 키 입력
search_element.send_keys(Keys.ENTER)
# 링크 텍스트로 버튼 찾아 클릭
shopping_button = driver.find_element(By.LINK_TEXT, '쇼핑')
shopping_button.click()
7. 네이버 쇼핑 크롤링 — Selenium + BeautifulSoup
HTML 가져오기 & 탭 전환
# 현재 탭의 HTML 가져오기
html_data = driver.page_source
# 탭이 여러 개인 경우 — 탭 목록 확인 후 전환
driver.window_handles # ['탭1id', '탭2id', ...]
driver.switch_to.window(driver.window_handles[1]) # 두 번째 탭으로 전환
html_data = driver.page_source
soup = bs(html_data, 'html.parser')re.compile — 부분 일치 class 탐색
동적 사이트는 class명에 랜덤 문자열이 붙는 경우가 많습니다.
re.compile()로 부분 일치를 사용합니다.
import re
# class명이 'product_item'으로 시작하는 div 모두 찾기
# product_item들의 상품의 이름과 가격을 추출
# 상품명 -> product_title_xxxx
# 가격 -> price
# 배송비 -> price_delivery_fee_xxxxxx
item_list = items_div.find_all(
'div',
attrs={'class': re.compile('product_item')}
)
# CSS 셀렉터 방식 (^= 로 시작하는 값 탐색)
items_div.select("div[class^='product_item']")상품 정보 추출 — 반복문
values = []
for item in item_list:
item_name = item.find('div', attrs={'class': re.compile('product_title')}).get_text()
item_price = item.find('span', attrs={'class': 'price'}).get_text()
item_fee = item.find('div', attrs={'class': re.compile('price_delivery_fee')}).get_text()
# a 태그의 href 속성으로 상품 URL 추출
name_tag = item.find('div', attrs={'class': re.compile('product_title')})
item_url = name_tag.find('a')['href']
values.append({
'상품명': item_name,
'가격': item_price,
'배송비': item_fee,
'url': item_url
})
df = pd.DataFrame(values)

8. 스크롤 제어 & 데이터 추가 수집
동적 페이지는 스크롤을 내려야 새 데이터가 로드됩니다.
# 맨 아래로 스크롤
driver.execute_script('window.scrollTo(0, document.body.scrollHeight)')
# 일정 간격으로 스크롤
driver.execute_script('window.scrollBy(0, 1000)')
# 스크롤 후 다시 HTML 가져오기
html_data = driver.page_source
soup = bs(html_data, 'html.parser')
# 데이터 재추출
item_list = items_div.find_all('div', attrs={'class': re.compile('product_item')})# CSV 저장 후 브라우저 종료
df.to_csv('아이폰.csv', index=False)
driver.quit()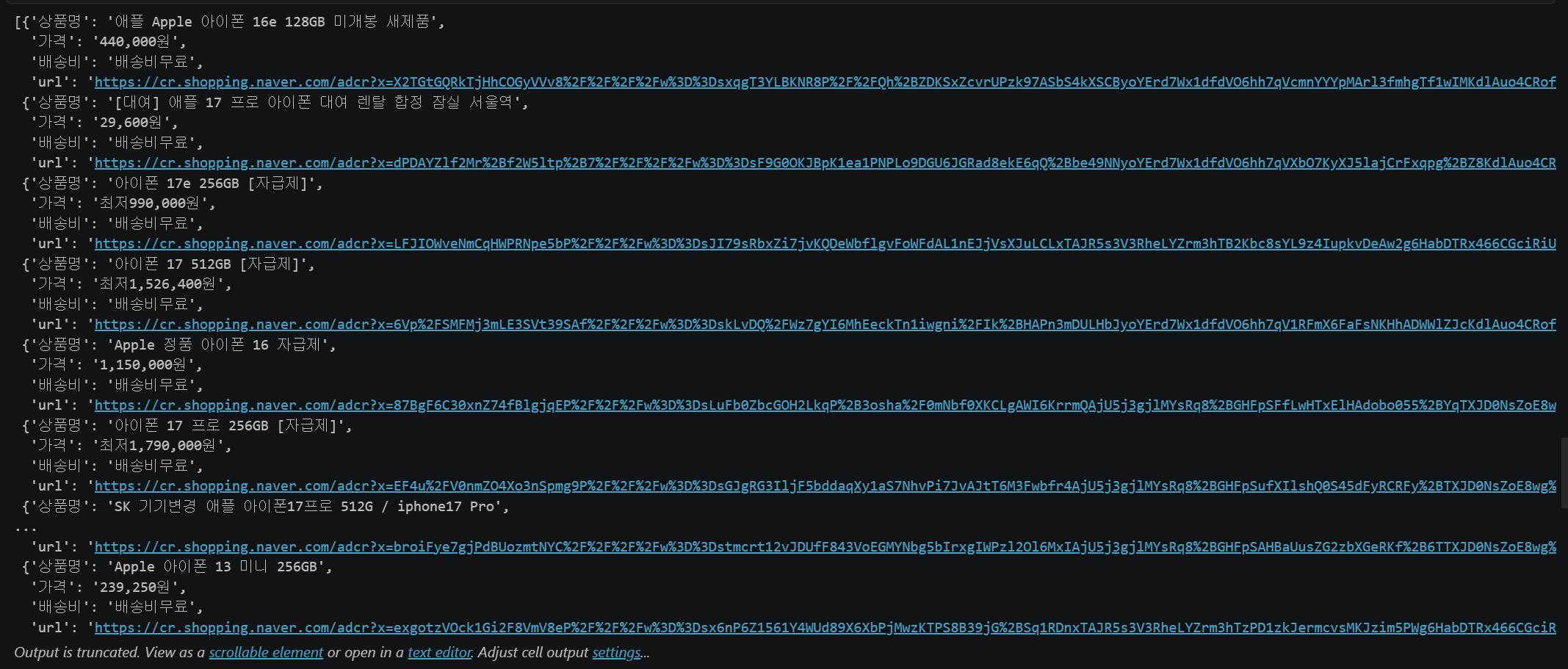
9. 수집 데이터 → MySQL DB 저장
db.py 모듈로 저장
from db import MyDB
db = MyDB()
# 데이터가 저장될 테이블 생성
table_query = """
CREATE TABLE IF NOT EXISTS `naver_shopping` (
`No` INT PRIMARY KEY AUTO_INCREMENT,
`name` VARCHAR(64),
`price` VARCHAR(32),
`delivery_fee` VARCHAR(32),
`url` TEXT
)
"""
db.sql_query(table_query)
# insert 쿼리 — No는 AUTO_INCREMENT이므로 생략
insert_query = """
INSERT INTO `naver_shopping` (`name`, `price`, `delivery_fee`, `url`)
VALUES (%s, %s, %s, %s)
"""
# 반복문으로 행별 삽입
for i in range(len(df)):
value = list(df.values[i])
db.sql_query(insert_query, *value) # 언패킹으로 전달
db.commit() # 확정 + 연결 종료💡
db.sql_query(insert_query, *value)—*value로 리스트를 언패킹하여 가변인자로 전달합니다.
10. SQLAlchemy — to_sql() 로 DataFrame 저장
to_sql()을 사용하면 반복문 없이 DataFrame 전체를 한 번에 DB에 저장할 수 있습니다.
# sqlalchemy 라이브러리 설치
# !pip install sqlalchemy
from sqlalchemy import create_engine
# create_engine을 이용해서 서버의 정보를 입력
# 연결 주소 형식: mysql+pymysql://유저명:비밀번호@서버주소:포트/DB명
engine = create_engine('mysql+pymysql://root:1234@localhost:3306/multicam')
# DataFrame to_sql() 함수를 이용
# name : 테이블의 이름 (필수)
# con : 데이터베이스의 주소(engine) (필수)
# index : 인덱스 저장 여부 (기본값 : True)
# if_exists :
# replace(교체) -> 기존의 데이터는 제거, 새로운 데이터 대입
# fail(실패처리, 기본값) -> 기존의 테이블이 존재하면 에러 발생
# append(추가 -> 기존의 데이터 밑에 데이터를 추가하는 방식)
df.to_sql(
name = 'naver', # 테이블 이름
con = engine, # 연결 엔진
index = False, # 인덱스 저장 여부
if_exists = 'append' # 기존 테이블에 추가
)if_exists 옵션
| 값 | 설명 |
|---|---|
'fail' | 테이블이 이미 존재하면 에러 (기본값) |
'replace' | 기존 테이블 삭제 후 새로 생성 |
'append' | 기존 테이블에 데이터 추가 |
💡
db.pyvsto_sql()차이
db.py (pymysql) to_sql() (sqlalchemy) 코드량 반복문 필요 한 줄로 저장 유연성 쿼리 직접 제어 가능 자동 처리 컬럼 타입 직접 지정 pandas 타입 자동 변환
11. 문제 — Selenium + BeautifulSoup + DB 저장
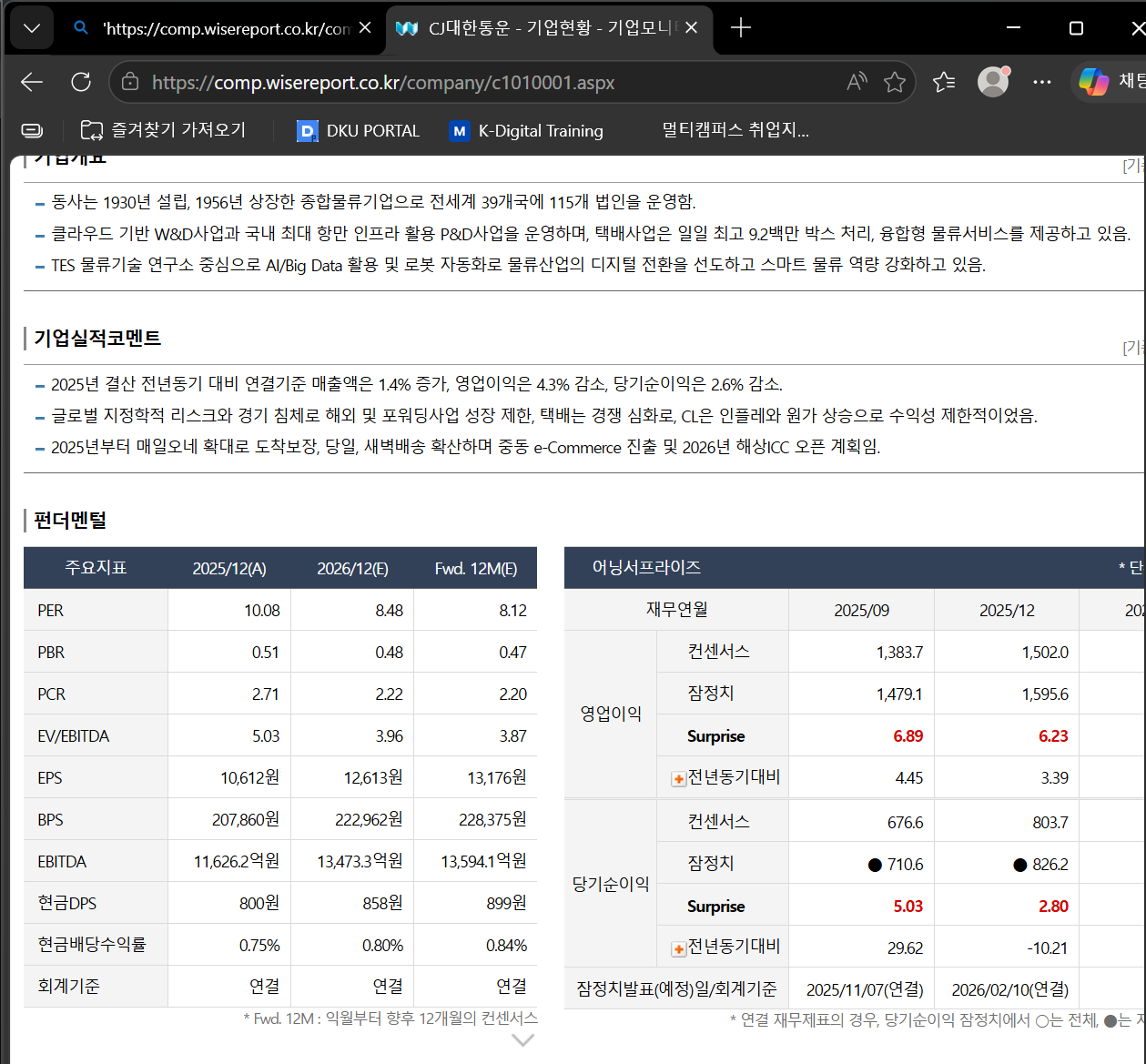
wise report 사이트에서 주요지표, 어닝서프라이즈 테이블을 크롤링하여 DB에 저장합니다.
풀이
import pandas as pd
from bs4 import BeautifulSoup as bs
from selenium import webdriver
from sqlalchemy import create_engine
# 1. 브라우저로 접속
driver = webdriver.Chrome()
driver.get('https://comp.wisereport.co.kr/company/c1010001.aspx')
# 2. HTML 파싱
html_data = driver.page_source
soup = bs(html_data, 'html.parser')
# 3. class가 'fl_le'인 div 모두 찾기
div_list = soup.find_all('div', attrs={'class': 'fl_le'})class가 fl_le인 태그를 모두 찾기
# div 태그중 class가 fl_le인 태그를 모두 찾는다
div_list = soup.find_all(
'div',
attrs = {
'class' : 'fl_le'
}
)
len(div_list)
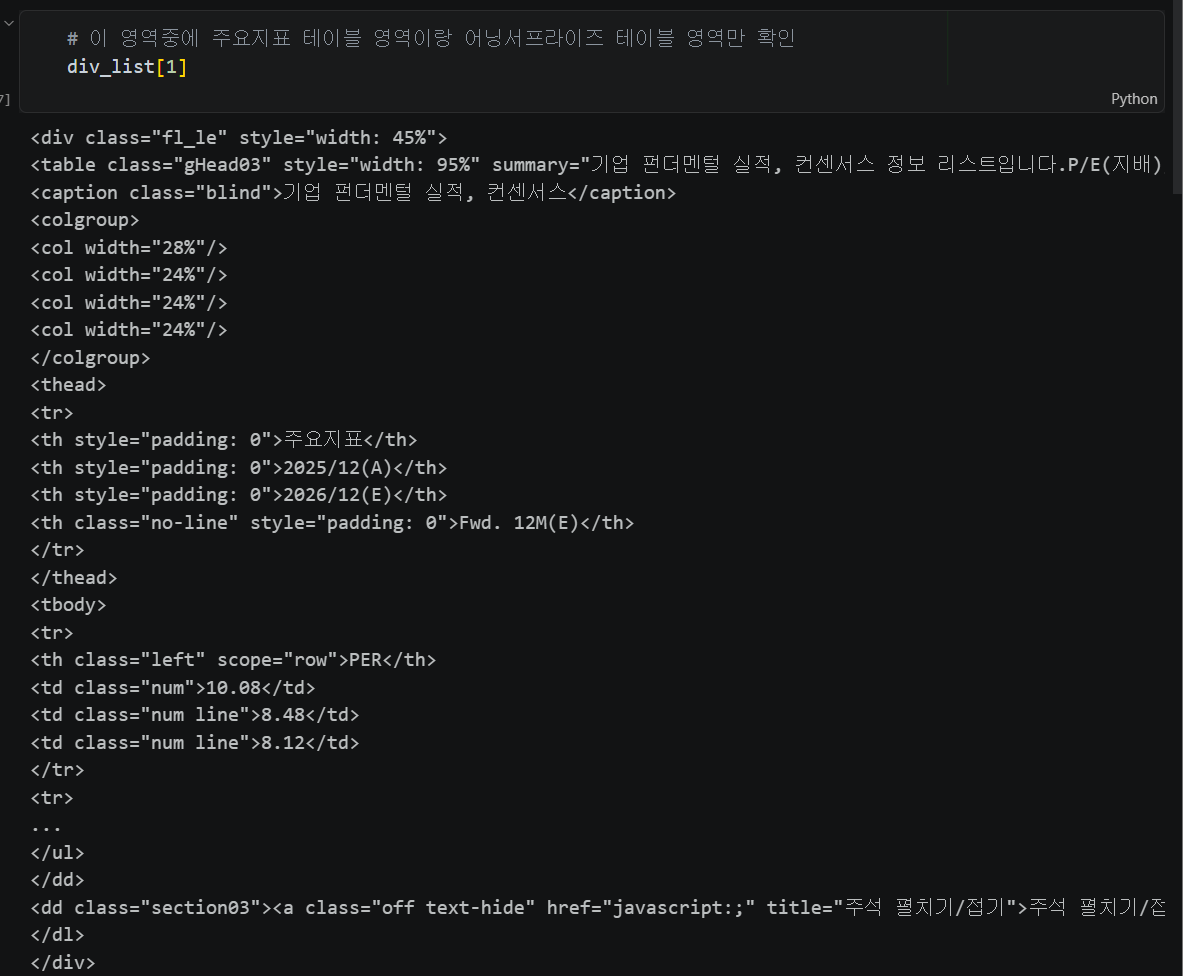
원하는 div만 필터링 — 키워드 포함 여부로 판별
# '주요지표' 또는 '어닝서프라이즈' 텍스트가 포함된 div만 True
list(map(
lambda x: '주요지표' in x.get_text() or '어닝서프라이즈' in x.get_text(),
div_list
))
# → [False, True, True, ...]read_html()로 DataFrame 변환
# 문자열로 변환 후 read_html() 적용
df1 = pd.read_html(str(div_list[1]))[0] # 주요지표
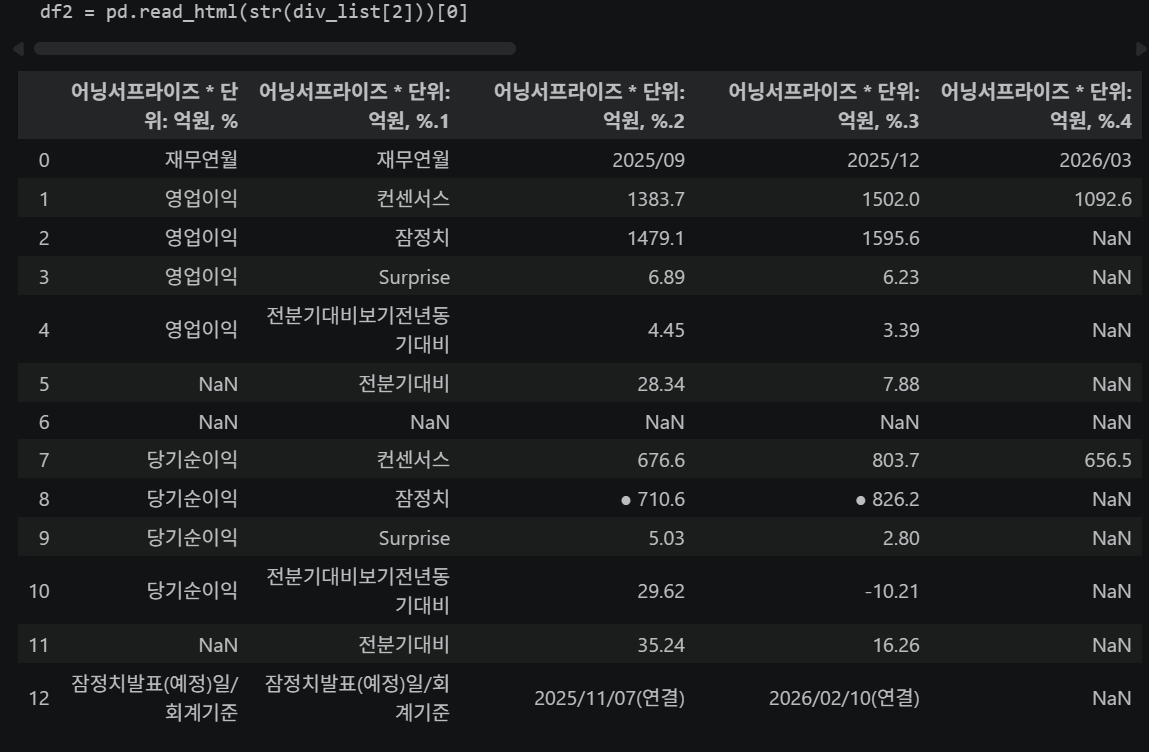
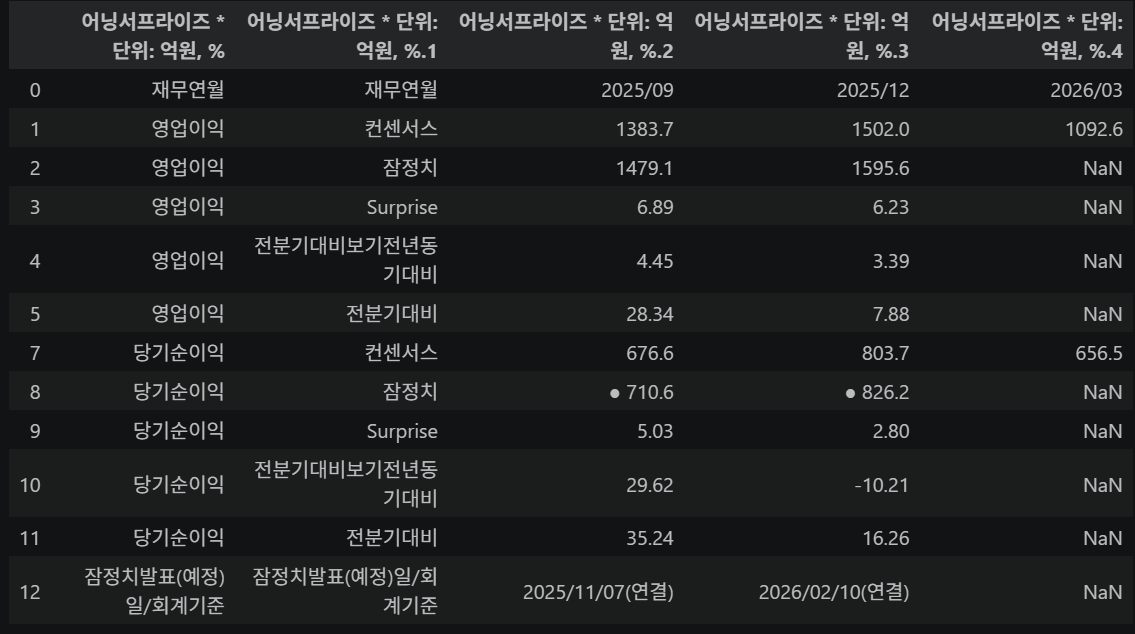
df2 = pd.read_html(str(div_list[2]))[0] # 어닝서프라이즈
# df2 데이터 정제
df2.drop(index=6, inplace=True) # 불필요한 행 제거
df2.iloc[:, 0] = df2.iloc[:, 0].ffill() # 결측치를 앞 값으로 채우기
df2.set_index([df2.columns[0], df2.columns[1]]) # 멀티 인덱스 설정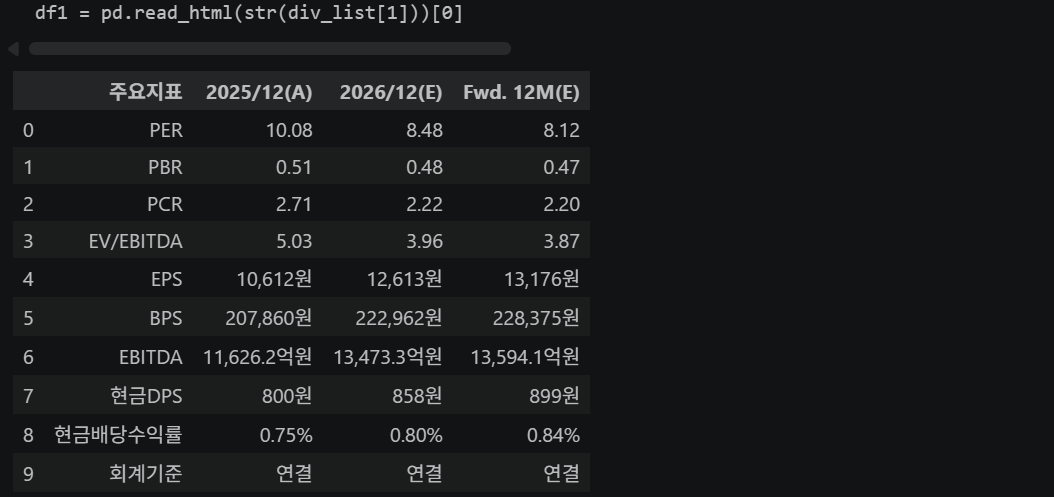
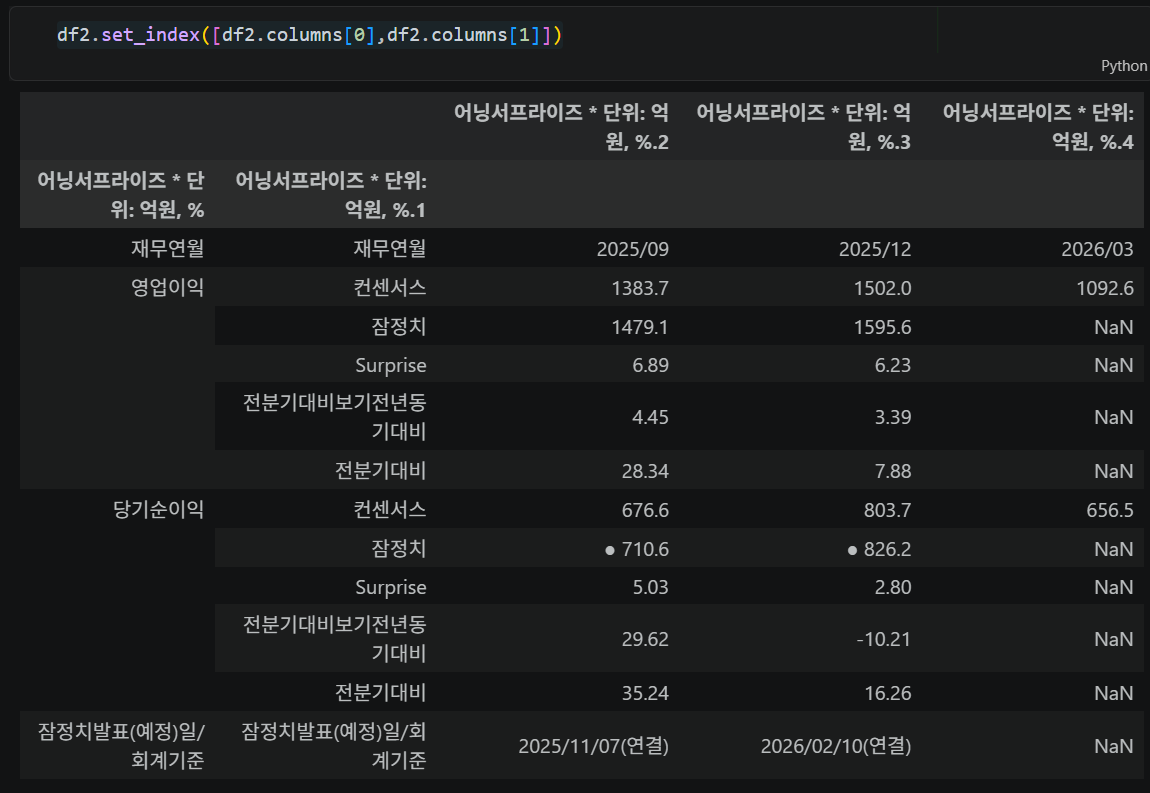
DB 저장
engine = create_engine('mysql+pymysql://root:1234@localhost:3306/multicam')
df1.to_sql(name='table1', con=engine)
df2.to_sql(name='table2', con=engine)
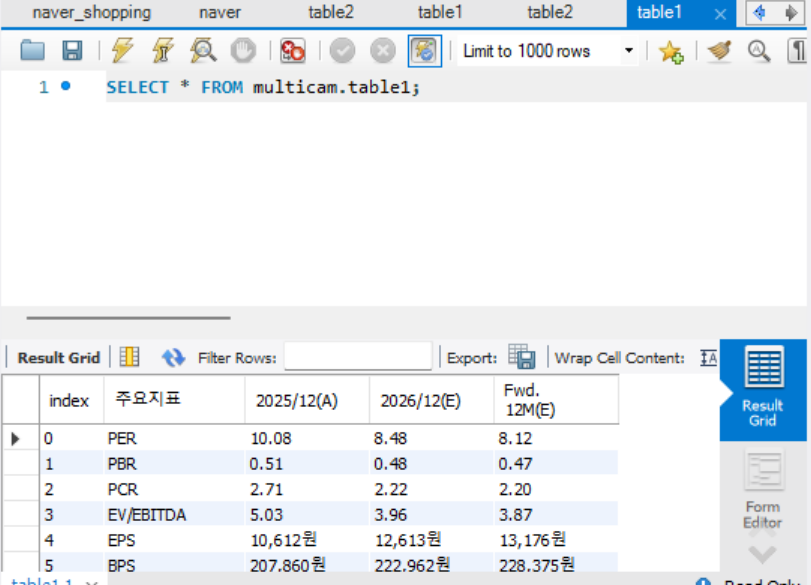
📎 핵심 함수 요약
| 함수 | 설명 |
|---|---|
webdriver.Chrome() | Chrome 브라우저 실행 |
driver.get(url) | 브라우저에 주소 입력 |
driver.page_source | 현재 페이지 HTML 가져오기 |
driver.window_handles | 열린 탭 목록 반환 |
driver.switch_to.window(탭) | 탭 전환 |
driver.execute_script(js) | JS 코드 실행 (스크롤 등) |
driver.quit() | 브라우저 종료 |
element.send_keys(텍스트) | 입력창에 텍스트 전달 |
element.click() | 요소 클릭 |
re.compile('패턴') | 정규식으로 부분 일치 탐색 |
soup.select('CSS셀렉터') | CSS 셀렉터로 탐색 |
create_engine('주소') | SQLAlchemy 엔진 생성 |
df.to_sql(name, con, ...) | DataFrame → DB 저장 |
df.to_csv(파일명, index=False) | CSV 저장 (인덱스 제외) |
pd.read_csv(파일명, usecols=[...]) | 특정 컬럼만 로드 |
