- 조인과 집계 데이터
- 조인과 집계데이터= Grouping Set절
- 조인과 집계데이터 = Roll up 절
- 조인과 집계데이터 = Cube 절
- 조인과 집계데이터 = 분석 함수란
- 조인과 집계데이터 = AVG함수
- 조인과 집계데이터 = Row Number , Rank , Dense_Rank 함수
- 조인과 집계데이터 = First_Value , Last_Value함수
- 조인과 집계데이터 = Lag, Lead 함수
| 종류 | 설명 |
|---|---|
| INNER 조인 | 특정 컬럼을 기준으로 정확히 매칭된 집합을 출력한다. |
| OUTER 조인 | 특정 컬럼을 기준으로 매칭된 집합을 출력하지만 한쪽의 집합은 모두 출력하고 다른 한쪽의 집합은 매칭되는 컬럼의 값 만 |
| 을 출력한다. | |
| SELF 조인 | 동일한 테이블 끼리 의 특정 컬럼을 기준으로 매칭되는 집합을 출력한다. |
| FULL OUTER 조인 | INNER, LEFT OUTER, RIGHT OUTER 조인 집합을 모두 출력한다. |
| CROSS 조인 | Cartesian Product이라고도 하며 조인되는 두 테이블에서 곱집합을 반환한다. |
| NATURAL 조인 | 특정 테이블의 같은 이름을 가진 컬럼 간의 조인집합을 출력한다. |
-
LEFTOUTER조인
- 한쪽의 집합은 모두 출력하고 다른 한쪽의 집합은 매칭되는 컬럼의 값만 출력한다.
-
SELF 조인
-
예시 -> 조직에서 누군가는 누군가의 부하직원이면서 누군가는 누군가의 윗사람일때
- 이때 같은 테이블에 rank순으로 담겨 있으면 사용한다.
ON M.EMPLOYEE_ID = E.MANAGER_ID이런식으로 주어지면 직원 ID가 누군가의 매니저 ID가 되는데 그러면 각 매니저별로 나열할수있다 (ORDER BY 사용)
-
또다른 예시로는 아래와 같은 부분이 있다.
FILM 테이블과
FILM 테이블을 SELF 조인함
서로다른영화인집합을출력
영화의 상영 시간은 동일하면서SELECT F1.title, F2.title, F1.length FROM film F1 INNER JOIN film F2 -- f1 , f2 로 지정하고 합친다. ON F1.film_id <> F2.film_id AND F1.length = F2.length;
-
-
Full outer 조인
-
아래 그림과 같다
.png)
.png)
-
CROSS JOIN
.png)
-
Natural JOIN
-
같은 컬럼 있으면 알아서 INNERJOIN
-
NATURAL 조인은 INNER 조인의 또 다른 SQL 작성 방식이다. v 즉 조인 컬럼을 명시하지 않아도 된다.
📌 집계 데이터
-
-
Grouping Set절
-
UNION ALL을 쓰지 않고 쉽게 그룹화 하고 싶다 - GROUPING SETS 절을 사용함
-
UNION ALL을 이용하여 (BRAND, SEGMENT 기준), (BRAND기준), (SEGMEN기준), (전체기준)으로 QUANTITY 합계의 값을 구할 수 있다
-
공식
SELECT c1 , c2 , 집계함수(c3) FROM table_name GROUP BY grouping sets ( (c1, c2) , (c1) , (c2) , ()SELECT brand, segment, Sum (quantity) FROM sales GROUP BY grouping sets ( ( brand, segment ), ( brand ), ( segment ), ( ) ); ----- -- 위랑 같은 결과
- BRAND, SEGMENT 컬럼 기준으로 합계를 구한다.
- BRAND 컬럼 기준으로 합계를 구한다.
- SEGMENT 컬럼 기준으로 합계를 구한다.
- 테이블 전체를 기준으로 합계를 구한다.
-
SELECT **Grouping**(brand) GROUPING_BRAND,
**Grouping**(segment) GROUPING_SEGEMENT,
brand,
segment,
Sum (quantity)
FROM sales
GROUP BY grouping sets ( ( brand, segment ), ( brand ), ( segment ), ( ) )
ORDER BY brand,
segment;
-- 해당 컬럼이 집계에 사용 되었으면 0,
-- 그렇지 않으면 1을 리턴한다.SELECT CASE
WHEN Grouping(brand) = 0
AND Grouping(segment) = 0 THEN '브랜드별+등급별'
WHEN Grouping(brand) = 0
AND Grouping(segment) = 1 THEN '브랜드별'
WHEN Grouping(brand) = 1
AND Grouping(segment) = 0 THEN '등급별'
WHEN Grouping(brand) = 1
AND Grouping(segment) = 1 THEN '전체합계'
ELSE ''
END AS "집계기준",
brand,
segment,
Sum(quantity)
FROM sales
GROUP BY grouping sets ( ( brand, segment ), ( brand ), ( segment ), ( ) ).png)
- 조인과 집계데이터 = Roll up 절
- BRAND, SEGMENT 컬럼 기준으로 ROLL UP 한다.
- = BRAND 컬럼 기준으로 합계, BRAND 컬럼 , 기준으로 합계 전체 합계를 구한다.
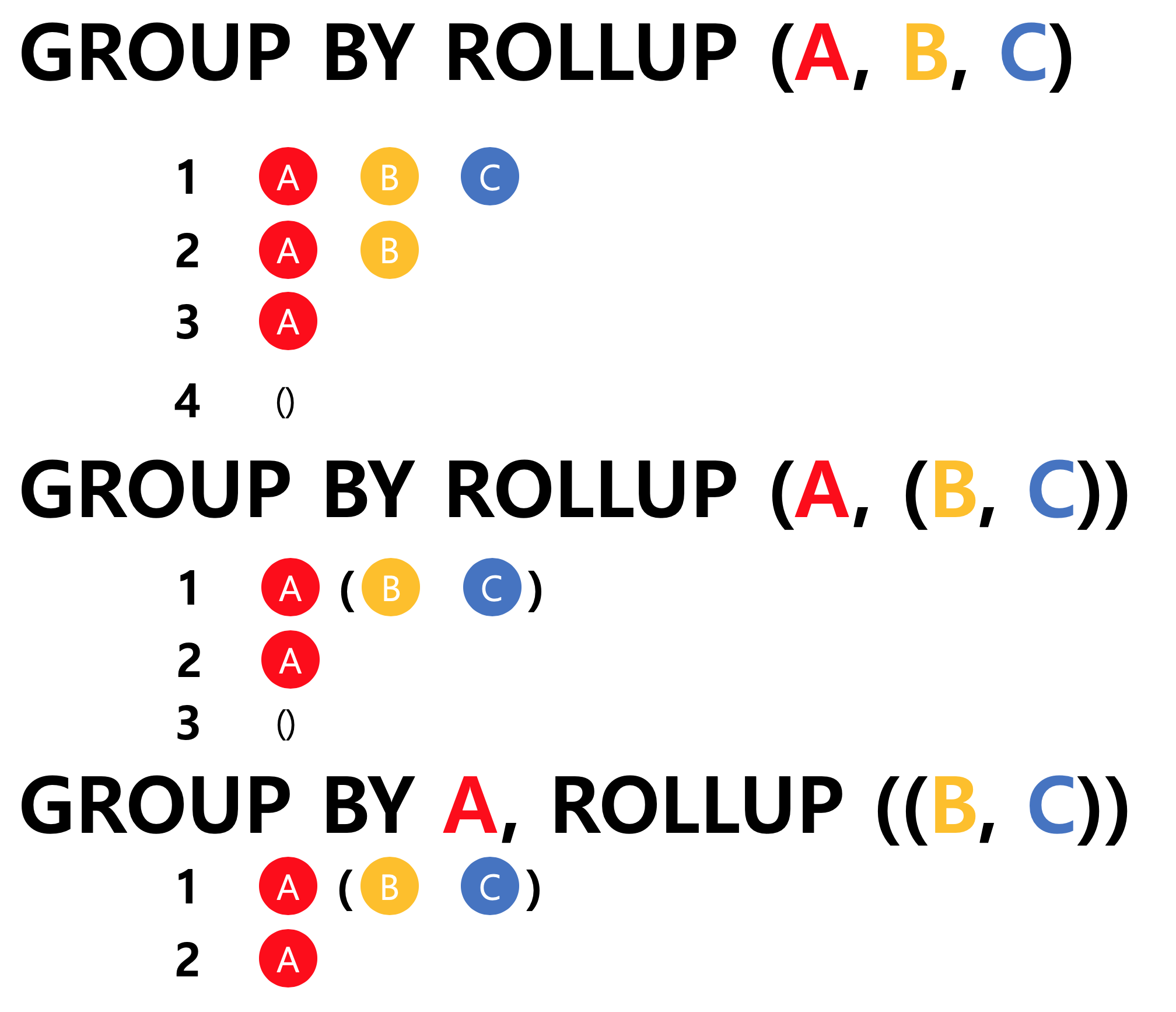
SELECT brand,
segment,
Sum (quantity)
FROM sales
GROUP BY **rollup** ( brand, segment )
ORDER BY brand,
segment;- SEGMENT 기준으로 GROUP BY 한다.
- BRAND 컬럼 기준으로 ROLL UP 한다. SELECT segment,
brand,
Sum (quantity)
FROM sales
GROUP BY segment,
rollup ( brand )
ORDER BY segment,
brand;
-- 위랑 다른점은 Segment 기준으로 그룹화 하고 브랜드 기준으로 롤업함
-- 부분 ROLLUP 시 전체 합계는 구하지 않는다.- 조인과 집계데이터 = Cube 절
-
Grouping column의 다차원 소계를 생성한다.
SELECT c1, c2, c3, 집계함수(c4) FROM table_name GROUP BY cube ( c1, c2, c3 ); -- CUBE(C1,C2,C3) -- => GROUPING SETS ( (C1,C2,C3), 3개묶 -- (C1,C2),(C1,C3),(C2,C3), 2개씩 묶 -- (C1), (C2), (C3), 1개씩 묶 -- () ) 여긴 아무것도 없음 -
(2의 N승=소계의 수)
SELECT brand, segment, Sum (quantity) FROM sales GROUP BY cube ( brand, segment ) ORDER BY brand, segment; -- 인자가 2개 이므로 총 4개의 경우에 수가 합계로 출력
-
- 브랜드 컬럼 기준 2개
- 세그먼트 컬럼 기준 2개
- 합이 4개 + 전체 합계 1개 까지 해서 총 5개 합계가 뜬다.
즉 정리하자면 Grouping Set 은 UNION ALL과 같은 역할
Roll up 절은 자동으로 합계 구하기 (전체 합계는 구하지 않는다.)

data analyst