[IBM data analyst]-Understanding Data Repositories and Big Data Platforms
코세라 - IBM 데이터 분석가 과정
- 데이터 리포지토리는 비즈니스 운영에 사용하거나 보고 및 데이터 분석을 위해 마이닝할 수 있도록 수집, 구성 및 격리된 데이터를 참조하는 데 사용되는 일반적인 용어
- 데이터베이스 관리 시스템(DBMS)은 데이터베이스를 생성하고 유지 관리하는 일련의 프로그램
- 플랫 파일과 달리 RDBMS는 많은 테이블과 훨씬 더 큰 데이터 볼륨을 포함하는 데이터 작업 및 쿼리에 최적화
- NoSQL은 빅 데이터 처리에 널리 사용
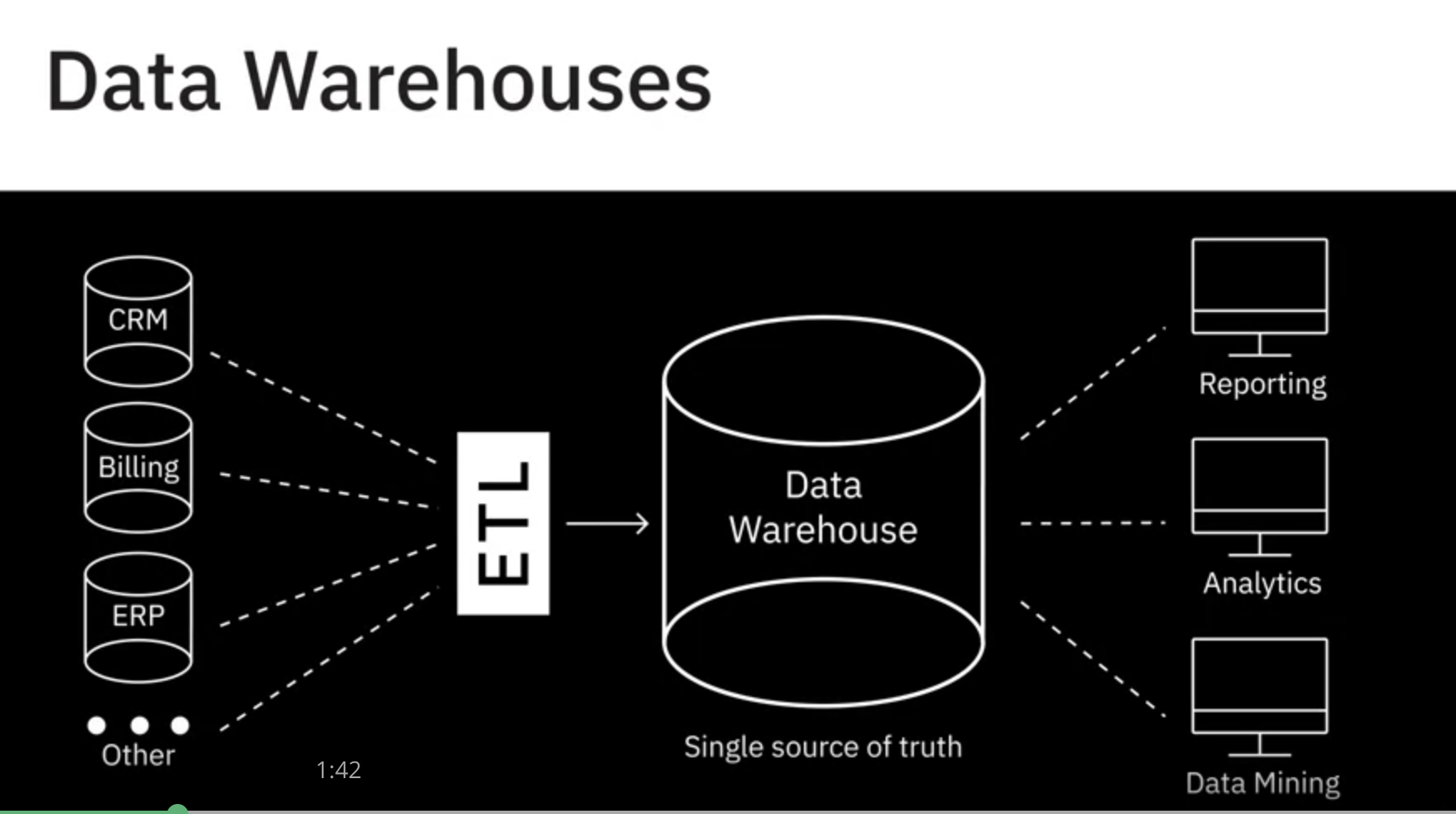
- 데이터 웨어하우스는 서로 다른 소스에서 오는 정보를 병합하고 ETL 프로세스라고도 하는 추출, 변환 및 로드 프로세스를 통해 분석 및 비즈니스 인텔리전스를 위한 하나의 포괄적인 데이터베이스로 통합하는 중앙 리포지토리로 작동




- 복잡한 검색 쿼리 및 다중 작업 트랜잭션을 실행하려는 경우문서 기반 데이터베이스는 최선의 선택이 아닐 수 있습니다.MongoDB, DocumentDB, CouchDB 및 Cloudant는 널리 사용되는 문서 기반 데이터베이스입니다.
- column based
열 기반 모델은 행 대신 데이터 열로 그룹화된 셀에 데이터를 저장합니다.일반적으로 함께 액세스되는 열의 논리적 그룹화를 호출합니다
열 데이터베이스는 열에 해당하는 모든 셀을 연속 디스크 항목으로 저장하므로 액세스데이터 검색이 매우 빨라집니다.
시계열 데이터, 날씨 데이터 및 IoT 데이터
- Graph based
그래프 기반 데이터베이스는 그래픽 모델을 사용하여 데이터를 표현하고 저장합니다


데이터 마트, 데이터 레이크, ETL 및 데이터 파이프라인
데이터 마트는 데이터 웨어하우스의 제한된 영역에 대한 분석 기능을 제공하기 때문에,격리된 보안과 격리된 성능을 제공합니다
데이터 마트의 가장 중요한 역할은 비즈니스별 보고 및 분석입니다
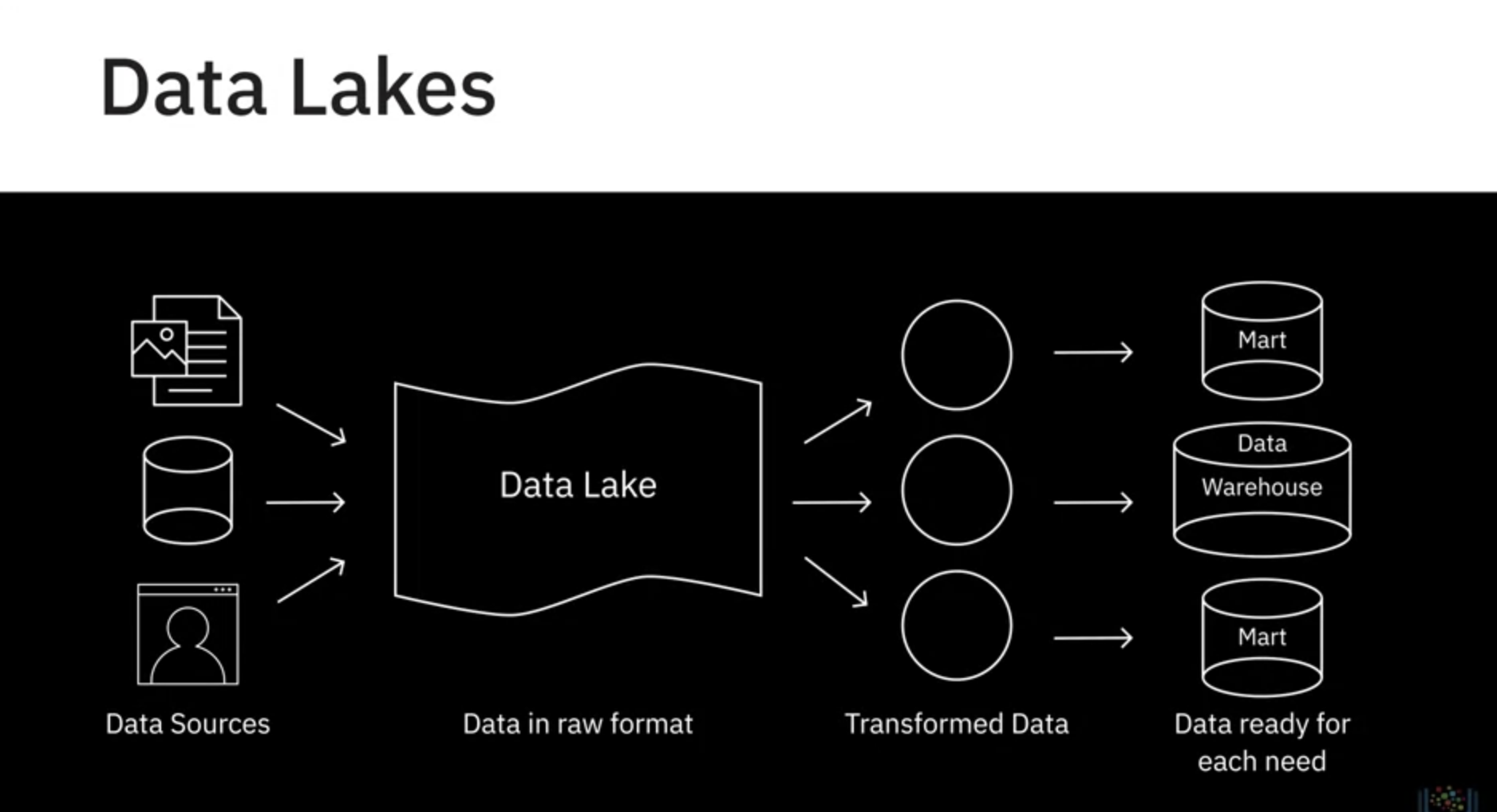
데이터 웨어하우스와 달리 데이터 레이크는 제외 없이 모든 소스 데이터를 유지합니다.그리고 데이터에는 모든 유형의 데이터 소스와 유형이 포함될 수 있습니다.
ETL은 원시 데이터를 분석 준비 데이터로 변환하는 방법

- 배치
- 일정 시간에 데이터 ETL 작업
- 스트림 프로세싱
- 실시간 처리

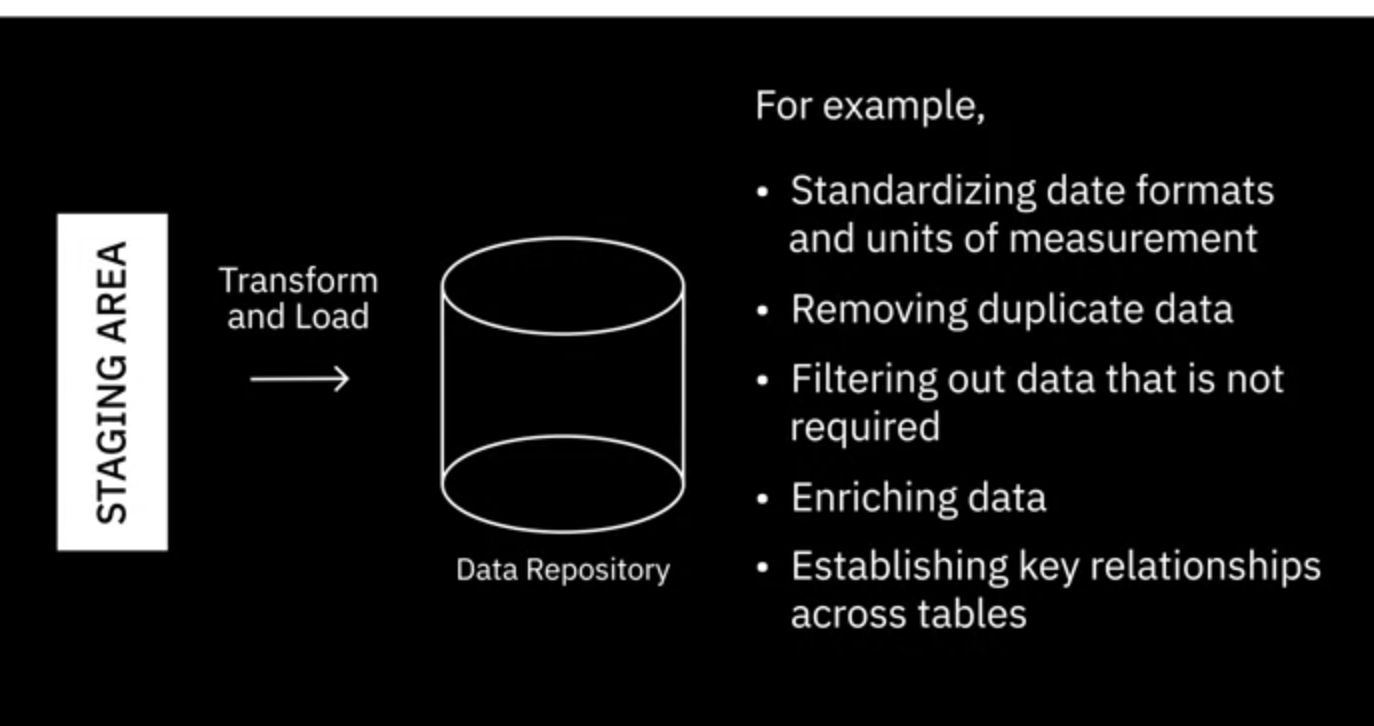
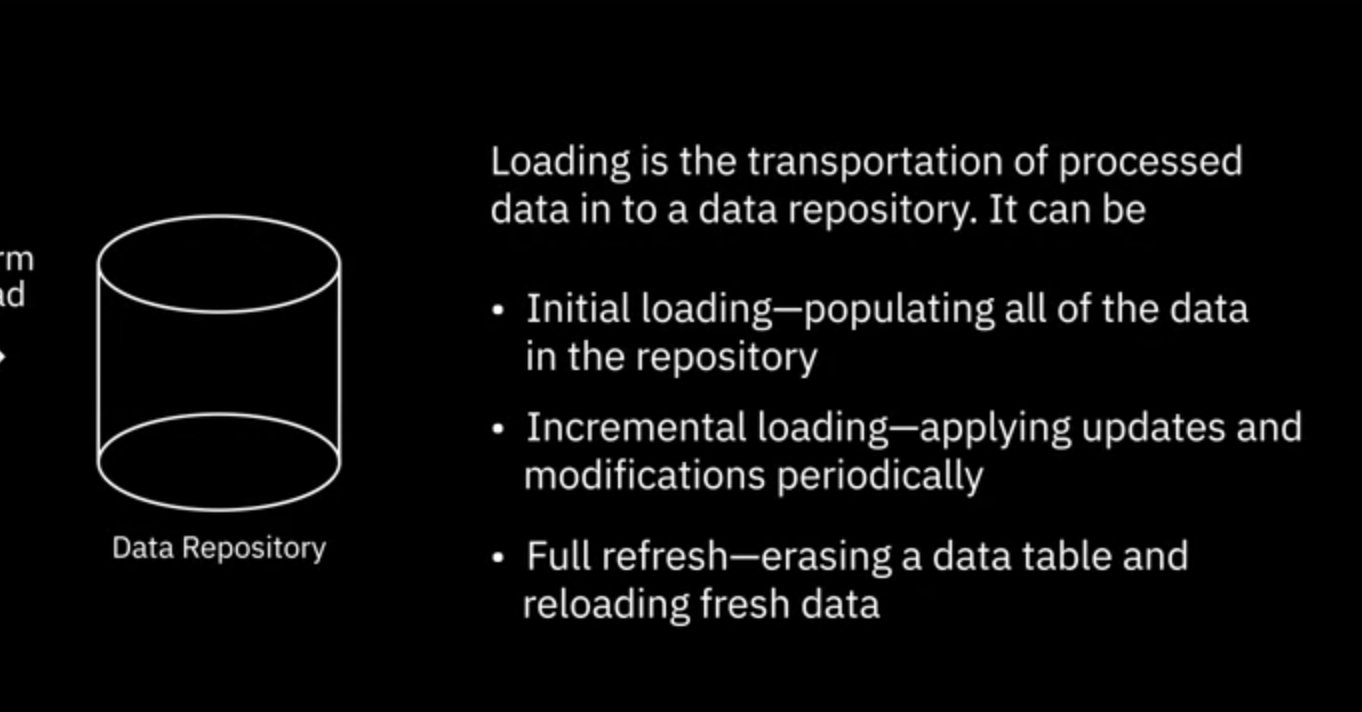
로드는 처리된 데이터를 대상 시스템이나 데이터 저장소로 전송하는 단계

데이터 파이프라인은 장기 실행 일괄 쿼리를 모두 지원하는 고성능 시스템

빅 데이터 처리 도구

Hadoop은 대용량 데이터의 분산 저장 및 처리를 제공하는 도구 모음
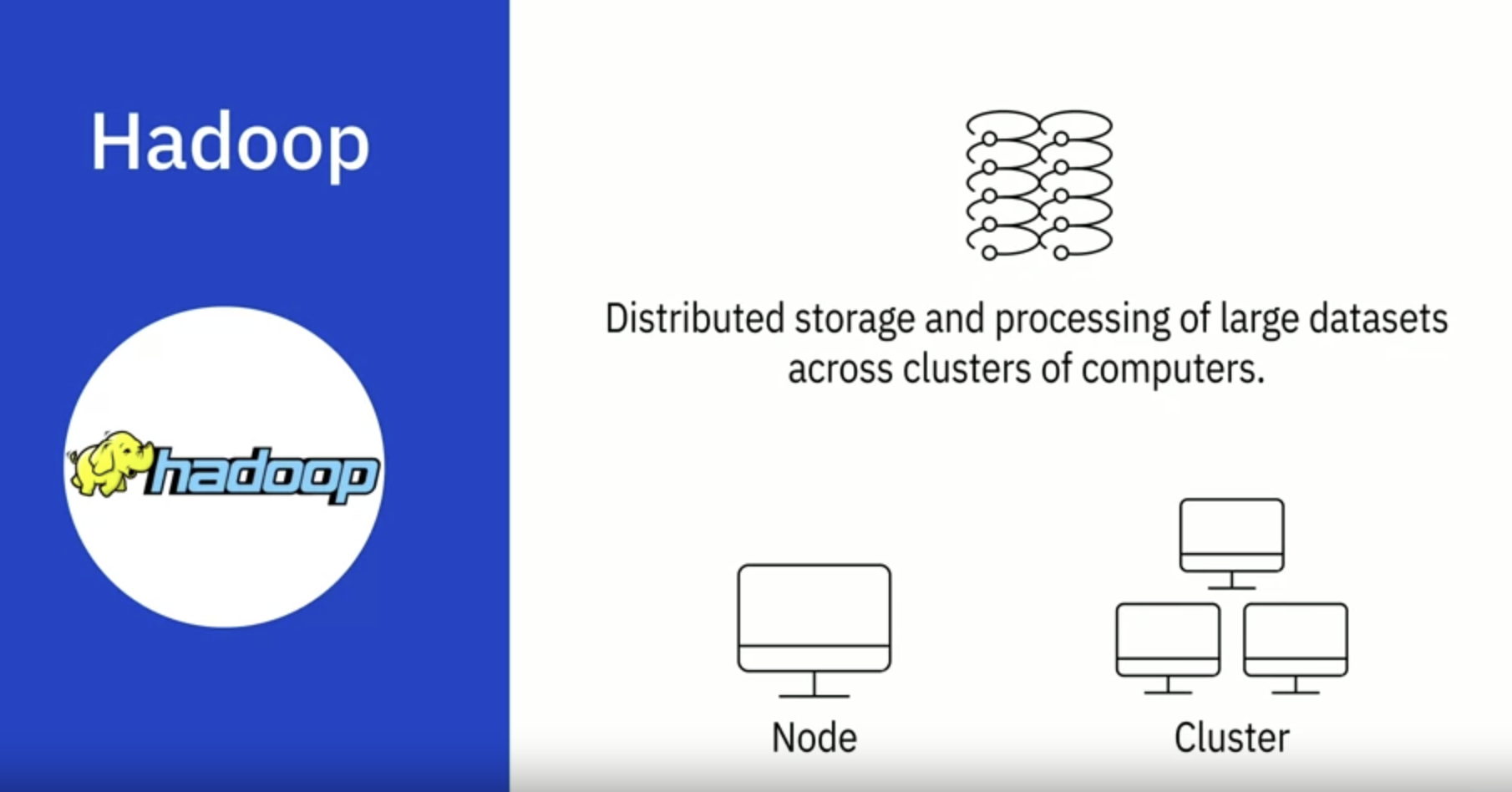
Hadoop은 데이터 저장을 위한 안정적이고 확장 가능하며 비용 효율적인 솔루션을 제공
데이터를 통합하여 엔터프라이즈 데이터 웨어하우스의 비용을 최적화하고 간소화
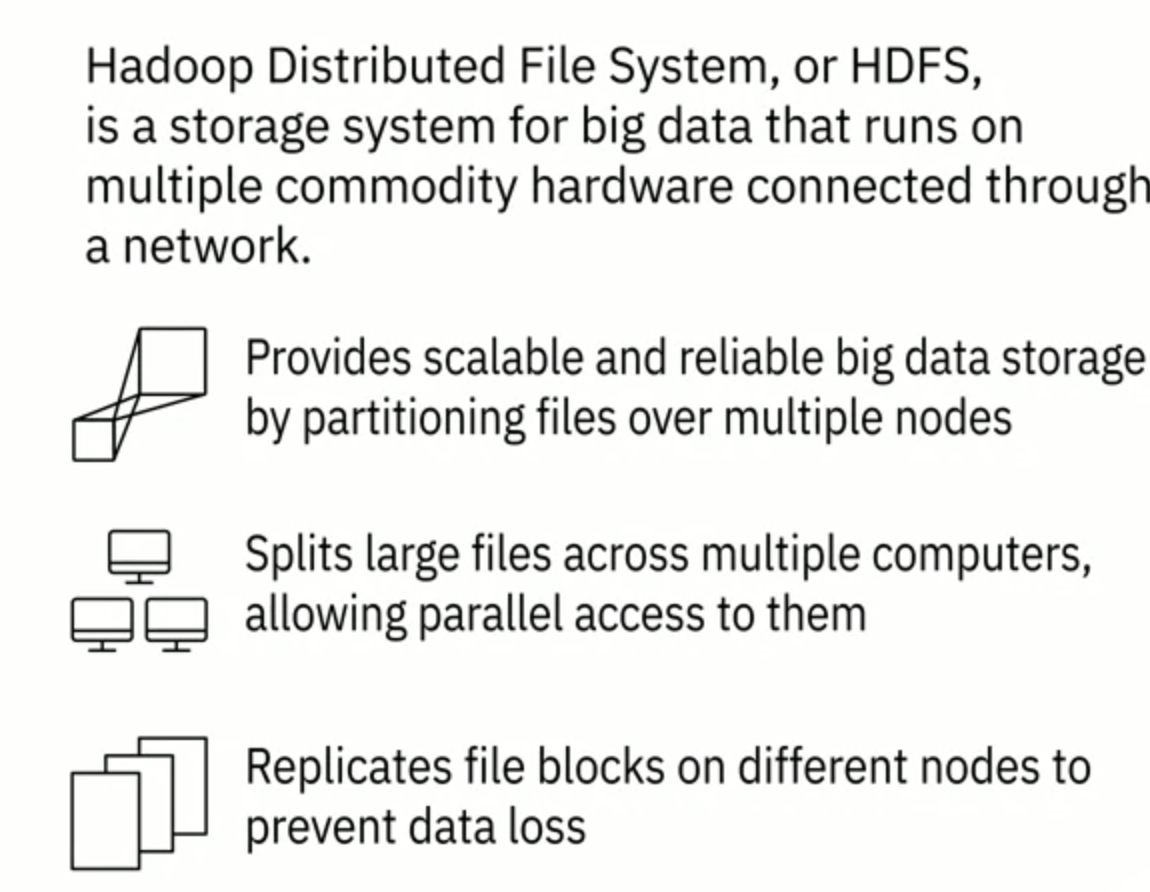
Hadoop의 4가지 주요 구성 요소 중 하나는 Hadoop 분산 파일 시스템(HDFS)

Hive는 Hadoop을 기반으로 구축된 데이터 쿼리 및 분석을 위한 데이터 웨어하우스
Hive는 대용량 데이터를 읽고, 쓰고, 관리하기 위한 오픈 소스 데이터 웨어하우스 소프트웨어
Hive는 Hadoop을 기반으로 하기 때문에 쿼리지연 시간이 매우 길기 때문에 Hive는 다음과 같은 애플리케이션에 적합하지 않습니다
Hive는 ETL, 보고 및 데이터 분석과 같은 데이터 웨어하우징 작업에 더 적합

Spark는 복잡한 데이터 분석을 수행하도록 설계된 분산 데이터 분석 프레임워크

인메모리 처리를 활용하여 계산 속도를 크게 높입니다
-
인메모리 처리 ?
- 하드디스크 시스템이 전체 시스템의 성능을 저하하는 병목- 인공지능이나 빅데이터, 사물인터넷 같은 새로운 기술의 발전에 따라 IT 시스템이 처리해야 할 데이터 양이 기존의 캐시 시스템으로 지원하기에는 너무 급속하게 증가함에 따라 다른 방법으로 이런 폰 노이만 병목을 해결해야 할 필요성이 급격하게 증대
- 해결하기 위해 인메모리 컴퓨팅(In-Memory Computing)이 자연스럽게 제안
- 인메모리 컴퓨팅은 기존의 디스크 기반 컴퓨팅과는 달리 데이터를 하드디스크에 저장하고 관리하는 것이 아니라, 전체 데이터를 메모리에 적재하여 사용하는 것을 의미
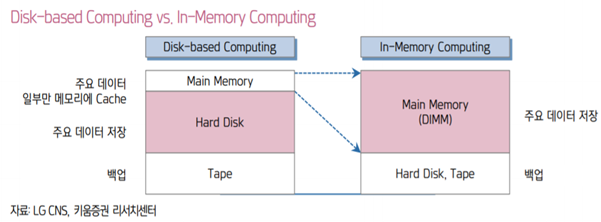
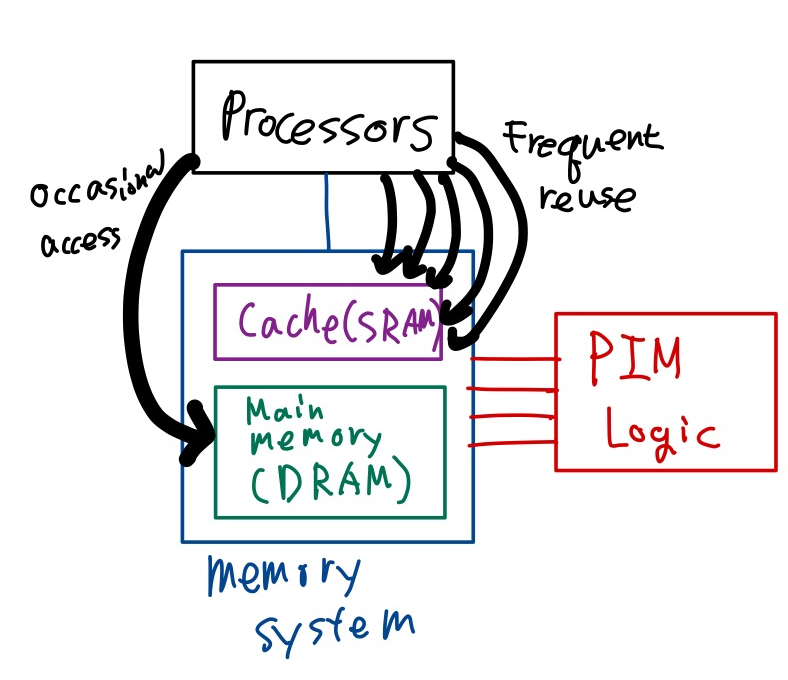
- 이거 두장으로 설명가능
Spark에는 Java, Scala, Python,R 및 SQL.
독립형 클러스터링 기술은 물론 다른 인프라에서도 실행할 수 있습니다
