
📌 Scheduling
→ ready queue에 있는 것들 중 어느 것을 cpu에 올릴 것인가
Process Execution
✔ CPU burst
load store, add store과 같이 일반 CPU연산에 해당
✔ I/O burst
I/O waiting → OS에게 I/O요청
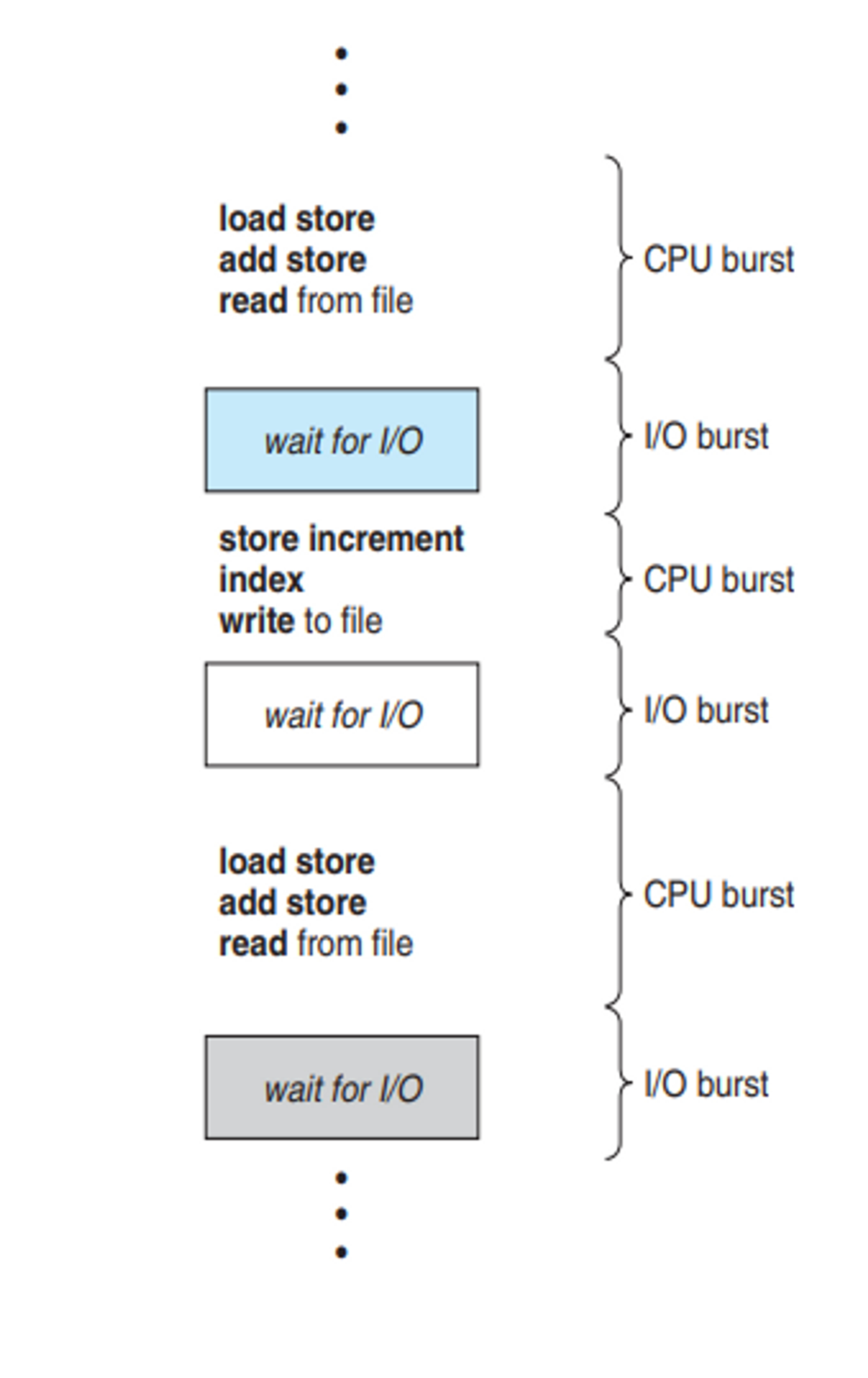
CPU burst vs. I/O burst
- CPU-bound process : CPU burst의 비율이 크다
- I/O-bound process : io burst의 비율이 크다 → 사용자와 interactive, 응답성이 좋아야 한다 → 우리가 사용하는 대부분
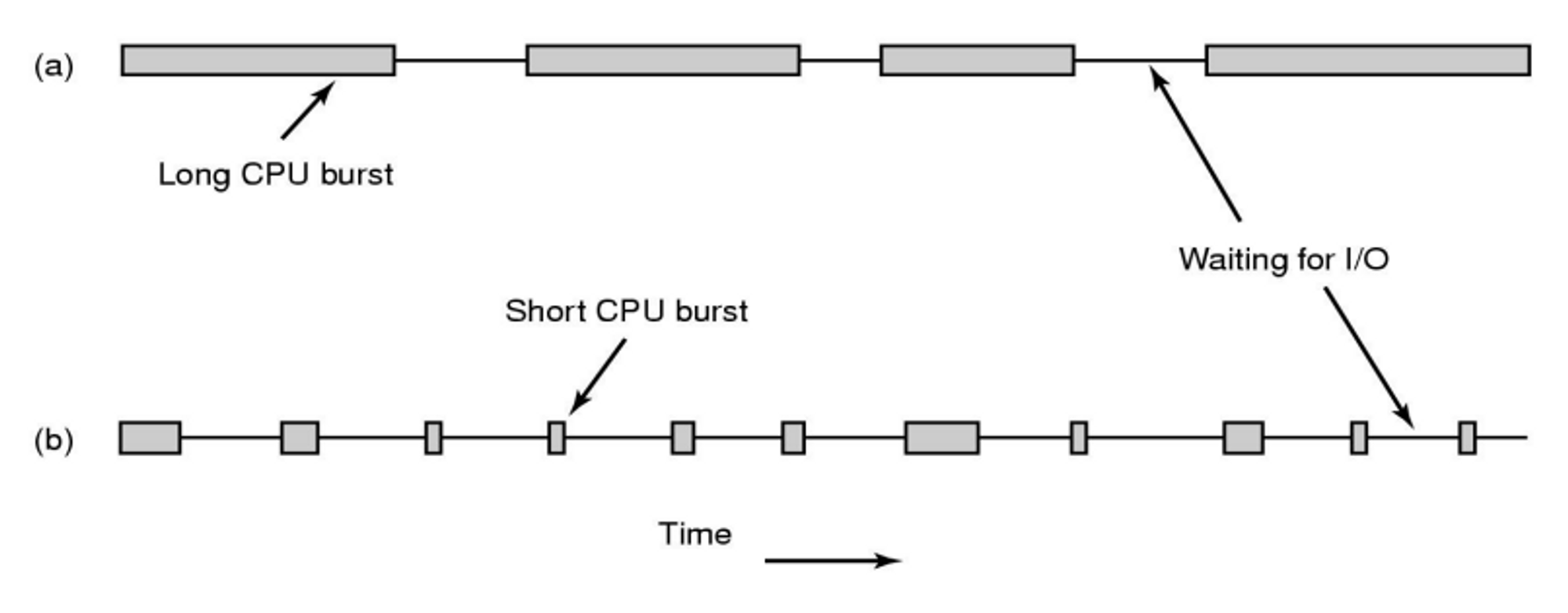
-> 일상 생활에서 대부분 사용하는것은 I/O-bound process 이다.
Dispatcher
스케쥴러가 선택한 프로세스의 현재 context(레지스터값)을 cpu 레지스터로 로드시키는 실행시킬 준비를 하는 과정이 디스패치이다. ready queue에서 cpu로 올리는것. 그 과정을 수행하는 주체가 Dispather이다.
✅ Dispatch latency
: 이전 프로세스의 runnning 상태가 끝나는 시점부터 다음 프로세스가 running이 시작되는 그 시점까지
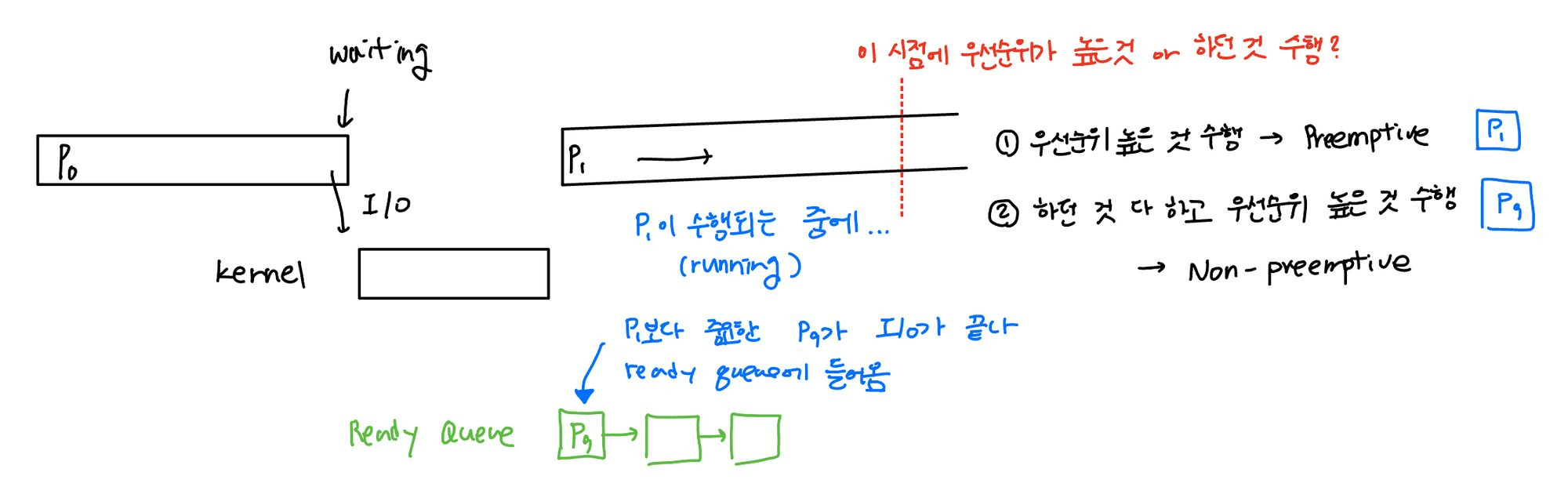
Preemptive vs. Non-preemptive
: scheduling policy
✅ Non-preemptive scheduling
✅ Preemptive scheduling
Scheduling Criteria
✔ CPU utilization
: CPU 사용률
→ cpu가 놀지 않고 실행시킨 프로그램들을 돌리는 비율
✔ Throughput
→ 단위시간 당 처리양(실행한 Instruction의 수)
- cpu : 높은게 좋음
✔ Turnaround time
: 특정 프로세스가 메모리에 로드가 되서 종료될 때까지의 시간
✔ Waiting time
: ready 상태에 진행한 순간부터 running 상태가 될 때까지
✔ Response time
: 요청이 들어오고 나서 그 요청이 올 때 까지의 시간
-> 사용자한테 보여지는 반응시간
- 짧을 수록 좋은 밑에 세개 cpu에서 양립할 수 없다 TRADE-OFF
Scheduling Goals
✅ All systems
✔ Fairness : 공평하게 스케쥴링하는 것이 가장 중요
✔ Balance: 시스템 전체의 밸런스를 맞추는 것도 중요
Batch systems
Context switching의 개념이 없음
✔ Throughput: maximize jobs per hour
✔ Turnaround time: minimize time between submission and termination
✔ CPU utilization: 100%에 수렴할 수 있도록
Interactive systems
time sharing, multi process를 지원하는
✔ Response time : 사용자와 interactive하게 대화형으로 동작할 수 있게 response time을 최소화하는 것이 아주 중요, 가장 중요
✔ Waiting time : 최소화
✔ Proportionality : Response time을 줄이면 자연스럽게 줄어듬
Real-time systems
dead line을 반드시 지켜야하는 시스템
✔ Meeting deadlines : 정해진 기한을 맞추어야 한다.
✔ Predictability : 남은 수행 시간을 예측하는 것
Scheduling Non-goals
💣Starvation
스케쥴러가 fairness를 보장할 수 없기 때문에 발생, 특정 process가 run 상태가 되지 못하는 것을 말한다.
🤖Scheduling Algorithms
FCFS Scheduling (FIFO)
: 먼저 들어온 프로세스가 가장 높은 우선순위를 갖고 가장 먼저 처리 된다
- non-preemptive
- 가장 자연스러운 스케쥴링 → 실생활이 그렇기 때문에
- burst time 짧은 것들이 앞에 배치가 되면 극단적으로 waiting time이 줄어듬
- 장점 : fairness를 가장 잘 보장해 줄 수 있다. starvation이 없다.
- 단점 : waiting time이 길어진다. cpu-burst, io-burst에 모두 영향을 줄 수 있다.
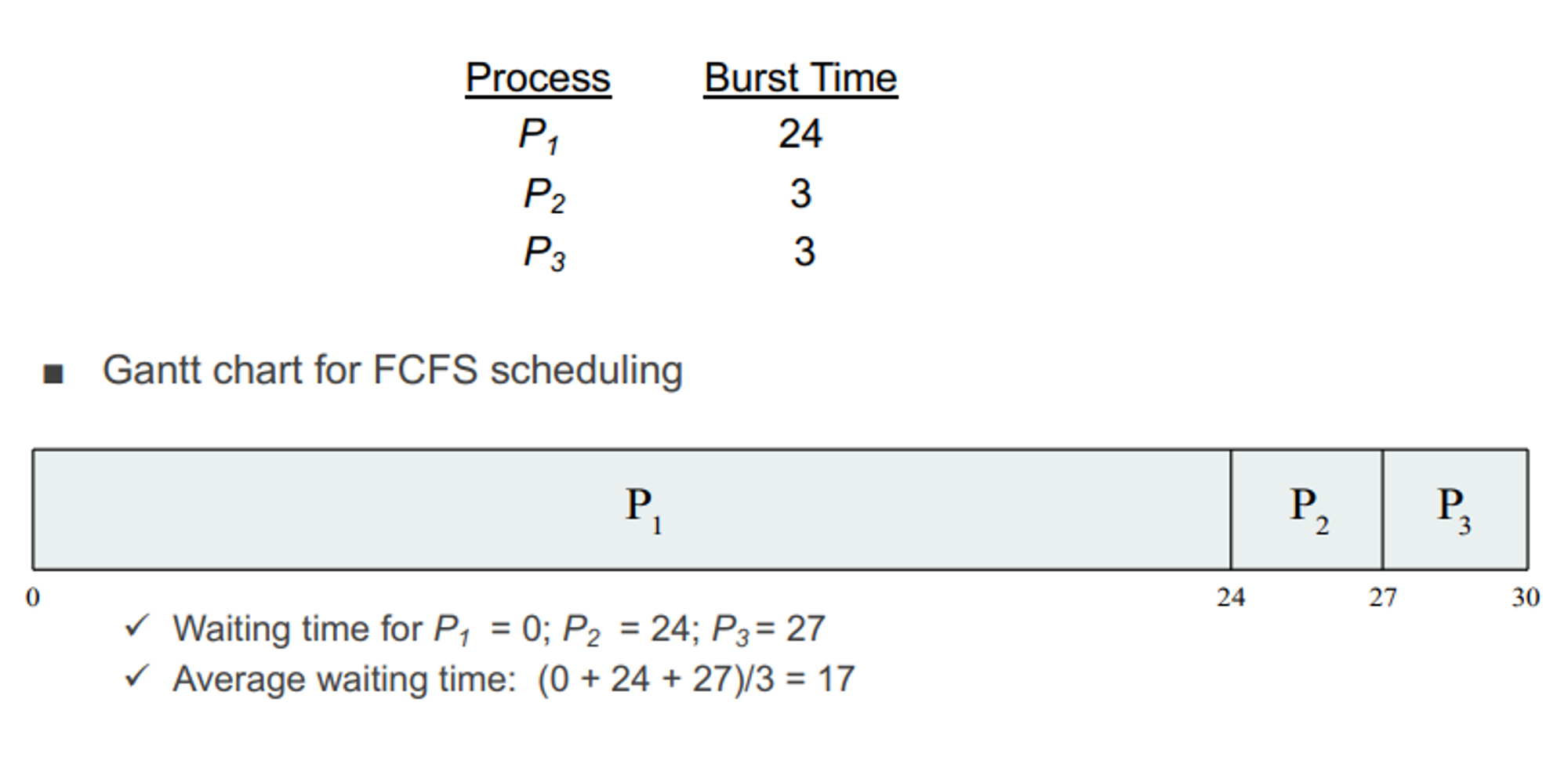
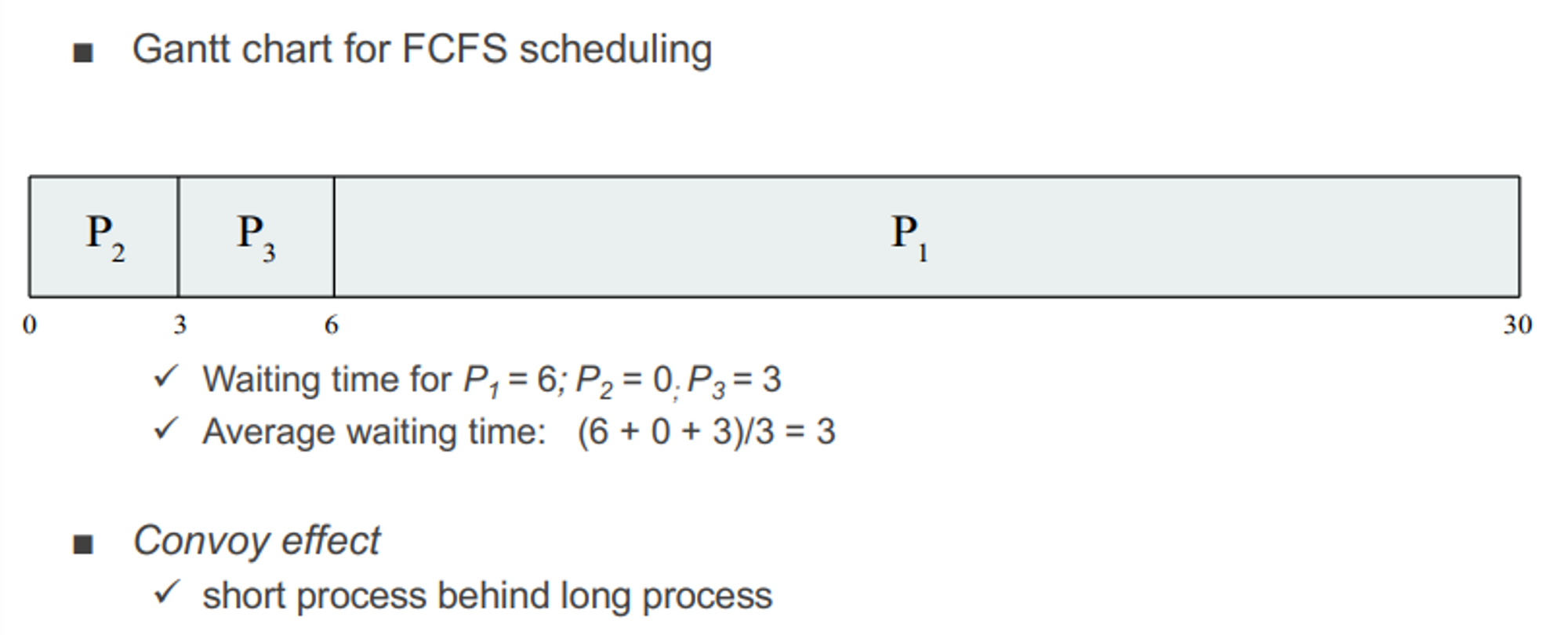
✅ convoy effect
: 짧은 수행 시간을 가지는 프로세스가 긴 수행 시간을 가지는 프로세스 이전에 수행될 수 있는 조건이 성립되는 case
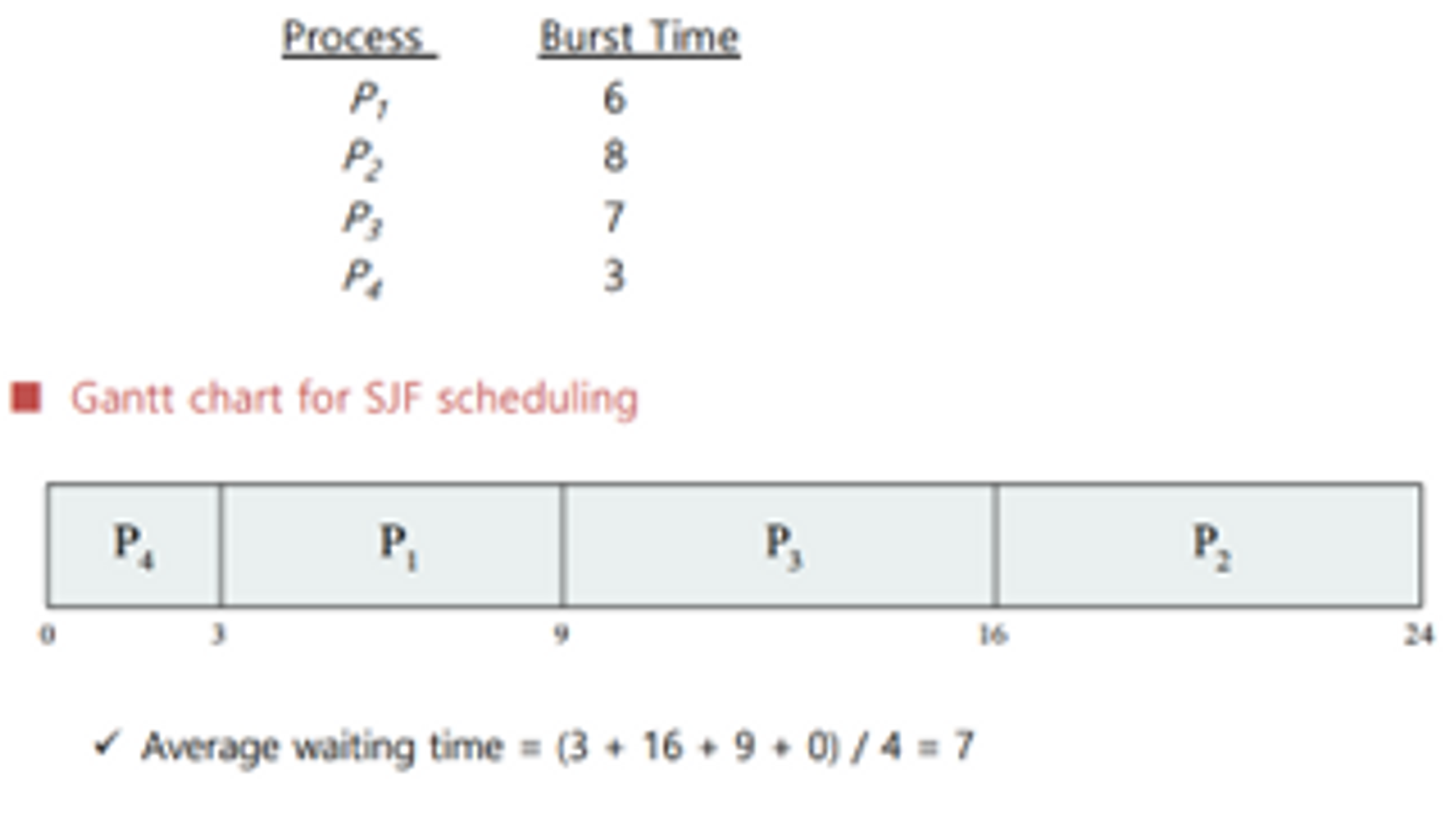
SJF Scheduling
유저와 상호소통을 하는 interactive한 시스템의 경우 waiting time이 짧아야 리스폰 타임이 줄어든다. 우선적으로 리스폰 타임이 줄이려면 수행시간이 적은 것을 먼저 실행시켜야 한다.
✔ Shortest Job First
- 버스트 타임이 가장 짧은 것이 먼저 스케쥴링 되도록 하는 것
- non Preemptive 하다
optimal한 알고리즘이다.- optimal :최적 → 유일하지 않지만 더 나은 것은 없다.
- best : 최고 → 유일
SRTF (Shortest Remaining Time First)
- Preemptive
- Preemptive SJF
💣문제점
1. 시간 예측 불가
2. 스타베이션 발생

Priority Scheduling
우선순위 기반의 스케쥴링 알고리즘
✅장점
- fliexible
→ 시스템이 어떤 목적으로 설계하는냐에 따라 상황에 맞게끔 조정이 가능 - preemptive , non-preemptive
- 스케쥴 대상인 프로세스들 한테 우선순위를 부여, 우선순위 높은 녀셕이 머저 스케쥬릴 되도록 우선순위 기준을 어떻게 주냐에 따라 성능, 적합한 시스템이 달라짐
💁♀️예시
- 라이벌 타임이 빠른 녀석일수록 무조건 우선 순위를 빨리 준다. → FCFS
- 버스트 타임이 제일 짧은 녀셕을 먼저 해주자 → SJF
- 남아있는 버스트 타임이 블라블라 → SRJF
✅단점
- starvation발생 가능, not fair
→ 우선순위가 낮은 프로세스이 존재하가 계속에서 높은 우선순위를 가진 프로세스이 ready queue에 도달하면 낮은 우선순위를 가지는 프로세스가 starvation
⇒ 해결 방안 : Aging
→ waiting time이 커질수록 우선순위가 낮은 프로세스가 계속 남아있으면 우선 순위를 올려준다.
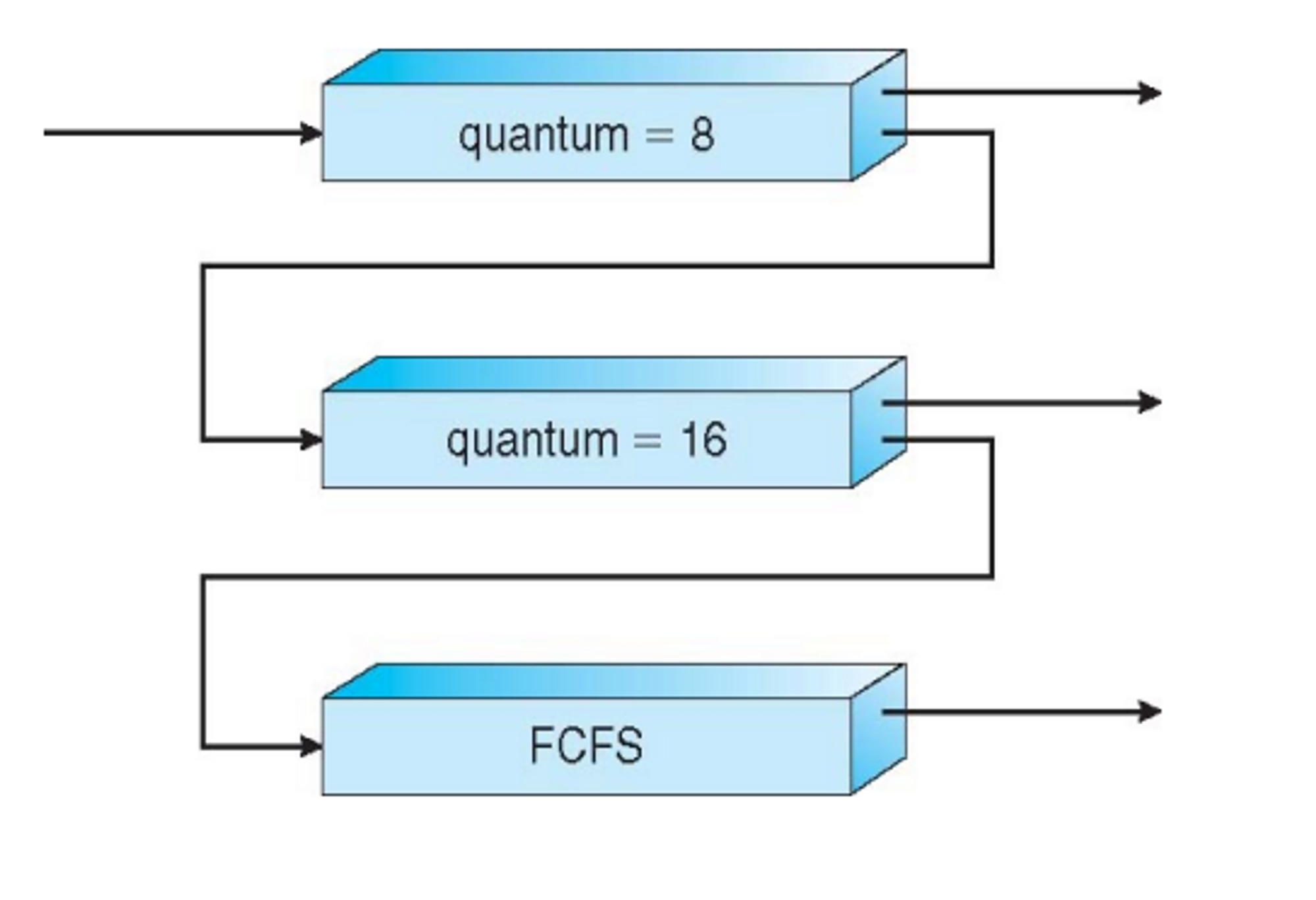
Round Robin (RR) Scheduling
각각의 프로세스가 정해진 타임 퀀텀만큼 수행되면 ready queue로 돌아간다.
shortest job first 보다 turn around time이 더 긴데, 응답성이 더 좋다
타임 퀀텀
프로세스가 한 번 스케쥴링 되었을 때 최대로 쓸 수 있는 시간
→ 더 적게 쓸 수도 있음
1. interrupt에 의해 ready queue
2. system call로 인해 waiting queue
타이머 인터럽스 context switching 되는 조건이 io 요청이 들어왔을 때나 인터럽트가 걸렸을 때 인데 이때 타이머 인터럽트에 설정된 시간이 타임 퀀텀이다.
타임 퀀텀은 스케쥴링 대상이 프로세스가 cpu를 점유해서 사용할 수 있느 최대 시간을 말한다. 최대시간만큼 쓸 수 없는 상황이 io요청이나 타이머 인터럽트를 제외한 다른 인터럽트가 걸렸을 때이다.
💭타임 퀀텀을 얼마로 잡을 것인가.
- 타임 퀀텀을 엄청 길게 했으면… 들어온 순서대로 FCFS와 똑같다
→ 페어하지만 구림.
- 0에 수렴하게 잡으면..?
→ 프로세스가 동작하는 시간보다 더 많은 시간을 스케쥴링, context scheduling 하는데 사용해야한다. 오버헤드가 엄청 커짐 → cpu utilization 감소
⇒ 따라서 이 시간을 적절하게 설정해야 한다. 일반적으로 타임 퀀텀은 평균 cpu burst time의 평균 정도로 둔다. 일반적으로 타임 퀀텀 타임은 10~100ms로 잡아두면 된다고 이야기 한다.
Problems of RR
- 저적한 타임 퀀텀을 어떻게 설정하느냐에 따라 완정히 달라짐
- 오버헤드가 생긴다. → 예를 들어 수행되어야 하는 프로세스가 A하나만 남아있고 A의 burst time이 20이다. 그런데 Time Quantum이 4라면 timer interuppt, context switching이 계속 일어나야 함으로 오버헤드가 커진다
📌 엄지손가락의 법칙
: cpu의 burst 의 80%를 포함할 수 있도록 설정.
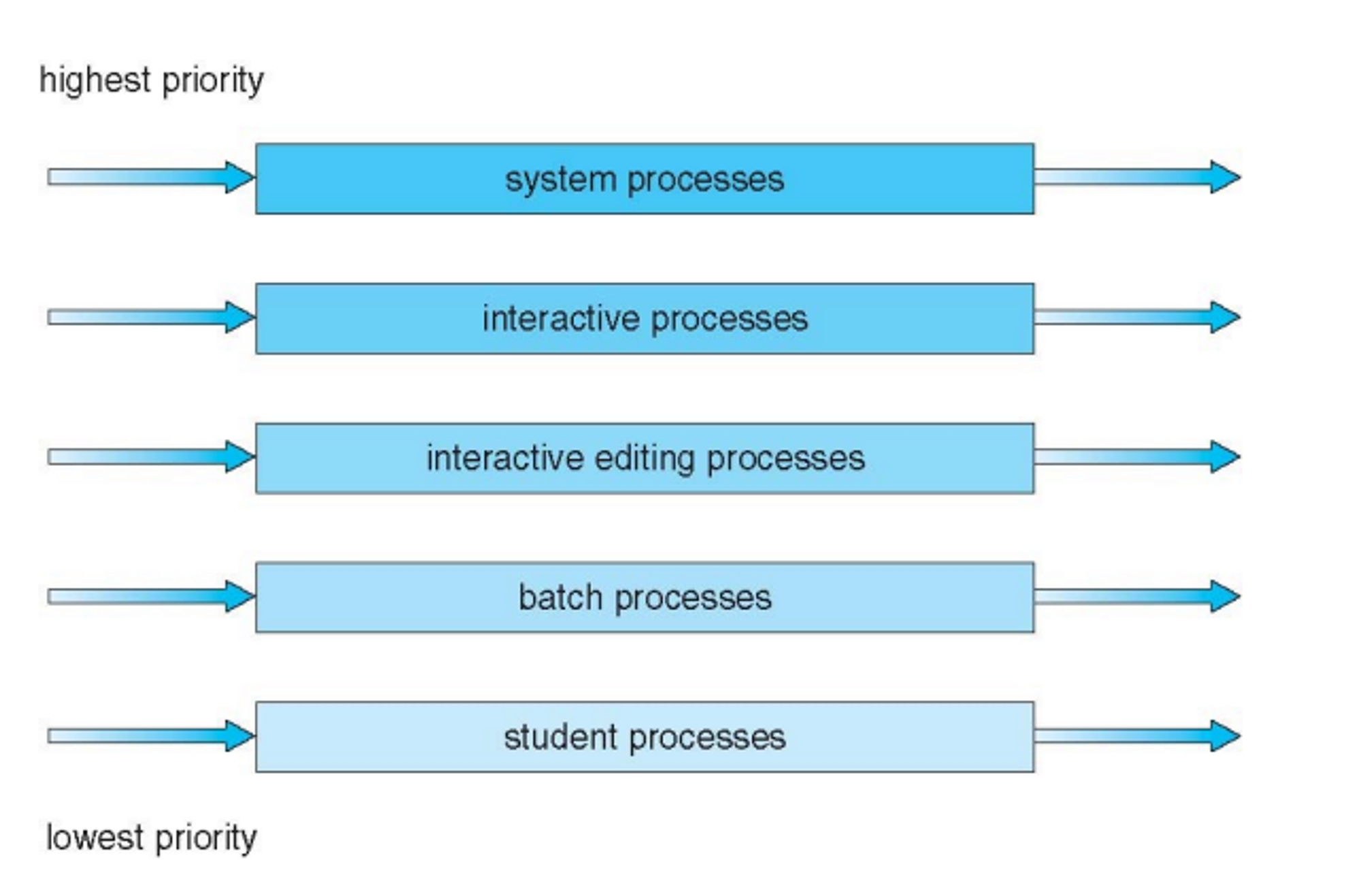
Multilevel Queue Scheduling
Queue를 여러개를 두고 각 큐에다가 큐마다 부여하고 있는 특성에 맞는 프로세서들을 비슷한 것들을 한큐에 몰아 넣고 돌린다.
- foreground - interactive(i/o bound) response time이 중요하기 때문에 RR
- background - cpu burst FCFS로 쭉 수행할 수 있도록
=⇒ 두 큐 사이는 Priority Scheduling
기존의 Priority Scheduling 는 Starvation 문제가 있어서 이를 Aging 방식으로 해결을 했는데 Multilevel Queue Scheduling에서는 다른 방식으로 해결 한다.
✔Time slice
단위 시간을 두고 앞의 80%는 foreground 뒤에 20%는 Background
📌 문제점
: 어떤 프로세스를 어떤 큐에 넣을 것인가.
예를 들어 IDE는 Editing을 할 때는 interactive process에 적합하고 Compile 할 때는 batch process에 적합하다. 이 프로세스가 어떤 큐에 들어갈지는 알고리즘을 제작한 사람이 임의로 설정을 하게 된다. 그럼 과연 이것이 신뢰가능한가?
Multilevel Feedback Queue Scheduling
: Multilevel Queue Scheduling 과는 달리 Queue의 목적성이 없다. 실제 Process를 큐에 넣어보고 I/o, CPU Bound 중 어디에 더 가까운지 판단하여 그에 맞는 큐에 넣는다.
→ 대부분 덩치 있는 OS들에서 채택하고 있는 방법이다.
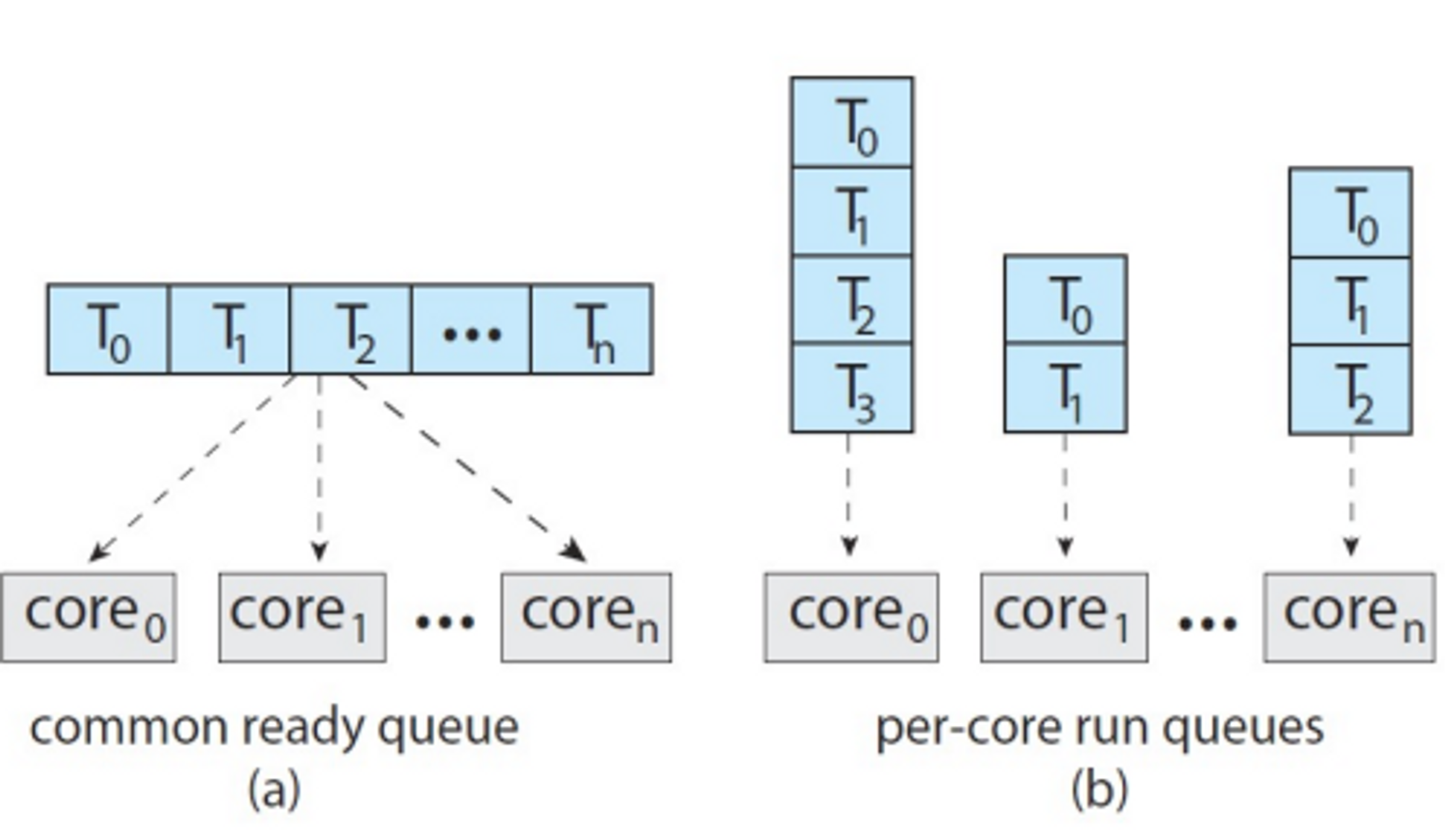
Multiple-Processor Scheduling
앞선 방법들과는 달리 cpu가 여러 개일때의 스케쥴링이다.
-
Load balancing
→ Push : 바쁜 녀석이 노는 녀석한테 넣어준다
→ Pull migration : 노는녀석이 바쁜 녀석한테 받아온다 -
Processor affinity
→ Soft : 오버헤드가 적음, 스케쥴링 알고리즘 복잡도 상승, 코어의 성능을 극대화 할 수 있지만 캐싱에서 병목현상이 발생
→ Hard : cache hit ratio를 고려해서 연관되어 있는 프로세스를 한 큐에 다 집어 넣음, 여러가지 캐싱 단계에서 발생할 수 있는 병목현상이 줄어든다. 스케쥴링 오버헤드가 크다.
Real-Time Scheduling
3가지를 고려해야함
1. Burst Time
2. Period
3. Dead line
→ 적절히 고려를 해서 모든 테스크가 데드라인을 넘지 않도록 스케쥴링을 돌려야 한다.
Static vs. Dynamic priority scheduling
✔ Static: Rate-Monotonic algorithm
→ 주기가 짧은 것이 더 중요 데드라인이 더 빠르게 온다.
→ 주기의 임벌스가 곳 rate가 되고 이 rate가 짧을 수록 먼저 처리
→ 주기가 짧은 것에게 우선순위를 먼저 주기 때문에 우선순위가 변하지 않는다
❗ Missed deadline
- 좋은 MCU를 써서 버스트 타임 자체를 극단적을 줄여 해결
- 코드 최적화 같은 것 을 써서 버스트 타임을 줄임
😎 더 많이 사용
우선순위를 부여해주는 알고리즘 → 단순하고 오버헤드가 적기 떄문에
✔ Dynamic: EDF (Earliest Deadline First) algorithm
→ 데드라인에 가까워질수록 우선순위를 높여준다
- 사용하지 않는 이유
: real time을 사용하는 cpu 성능이 좋지 않다. Point마다 ready queue에 들어가 있는 모든 프로세스의 데드라인을 전부 검토하여 제일 높은 우선순위를 가진 것에게 우선 순위를 부여한다. 이 과정이 일이 많고 복잡하여 스케쥴링 자체의 오버헤드가 크다.
Operating System Examples
1. Linux Scheduling
유저 프로세스를 할당
2. Windows Scheduling
→ 바이너리 트리로 관리를 한다. 참고정도로만 보기~
3. Solaris Scheduling
Algorithm Evaluation
- 수학적인 분석 : 제일 쉽게 할 수 있으면서 변수 통제가 되는 방법
- 시뮬/애뮬레이션
- 실제로 구현해서 측정
→ 제일 정확하지만 쉽지가 않다

글이 귀엽고 이모티콘이 유용하네요