💁🏻♀️ Summary
☑ MMU in CPU
☑ Page Table in Physical Memory
☑ TLB(cache) in MMU
Memory Management
1. Goals
-
개발자가 메모리의 이슈들을 신경쓰지 않아도 편하게 개발할 수 있도록 추상화 하는 것
→ To provide a convenient abstraction for programming -
메모리는 비싼 자원이기 때문에 아껴 쓰고 효율적으로 사용해야 한다.
→ To allocate scarce memory resources among competing processes to maximize performance with minimal overhead -
프로세스간의 양쪽이 사용하는 메모리 영역을 완전히 격리 시킨다 (메모리 프로텍션)
→ To provide isolation between processes
2. Batch programming
한 번의 하나의 프로그램만 동작을 하니 메모리 관리가 필요하지 않았다. 그냥 프로그램이 운영체제에서 추상화 필요없이 피지컬 메모리를 그냥 써도 상관이 없었다.
3. Multiprogramming
다수의 사용자가 컴퓨터를 동작, 여러 프로세스가 동작 하는 상황… → 메모리 관리가 필요해짐
✔ Requirements
- Protection: isolation을 사용
- Fast translation : logical 메모리에서 피지컬 메모리로의 전환이 빠르게 되어야 한다
4. Issues
-
Support for multiple processe
-
Enable a process to be larger than the amount of memory allocated to it
실제 피지컬 메모리보다 더 큰 용량을 가지는 프로세스도 지원을 해주어야 한다 (virtual memry로 해결) -
Protection
-
Sharing
-
Support for multiple regions per process (segments)
-
Performance
Solution: Virtual Memory (VM)
✅ 메모리 자체를 virtual(로지컬) 메모리랑 피지컬한 메모리로 나누어서 관리를 한다는 것이 핵심
- 이론적으로 메모리를 무한대 사용 가능
- 메모리는 한정적이기 때문에 메모리가 부족한 상황이 발생할 수 있는데 그 문제를 해결하기 위해서 만든 것임.
- 하드웨어의 특정 공간을 메모리처럼 사용하자
- swap in / swap out
- paging이라는 메모리 기법을 바탕으로
Binding of Instructions and Data to Memory
✅ 데이터를 메모리에 저장하기 위해서 메모리 공간을 확보하면, 확보된 메모리 공간에 주소를 알 수 있어야 하는데 그 주소를 명시하는 타임에 따라 세가지로 나뉜다.
- Compile time - 임베디드 시스템에서만 사용
→ 단) 똑같은 메모리 주소 번지를 중복해서 사용할 수 없다. 그래서 임베디드에서만 사용한다.
무조건 100번지에 들어간다 적어두면 실행할 때 무조건 그곳에 넣음
- load Time : 디스크에 있는 것들을 메모리로 가지고 오는 시간에
- Execution time : 실행되는 상황에서 동적으로 정하는 방법
Binding of Memory Address
✅ Compile time
→ 컴파일, 로드, 실행할 때 모두 overhead가 없지만 실행주고가 정적이라는 단점.
✅ load time
- 프로그램이 클 때 로드 타임이 길어진다
→ 컴파일은 쉽지만, 로드할 때 주소들을 다 만져야하니 로드가 오래 걸려 overhead가 크다.
✅ execution time
- 실행을 할 때 offset을 더해주어야 해서 overhead가 크다
→ 컴파일 타임에 고려해야할 것이 없으니 overhead가 없다.
→ 매번 수행할 때마다 add연상을 해주어야 해서 overhead가 크다.
⇒ cpu가 더하기 연산을 하면 overhead가 크니 hw 지원을 받아 성능의 한계를 극복한다.
→ 실제로 사용하는 방식이며 , 하드웨어 로직으로 mmu에 넣어서 위의 문제를 해결
✅ Address mapping
→ 메모리가 모자른 경우에 세컨더리 스토리지에 넣었다 뺐다 하면서 진행
→ 세컨더리 스토리지의 일부를 메모리처럼 활용하여 피지컬 메모리보다 더 큰 메모리를 가상으로 가지고 컴퓨터가 동작하도록
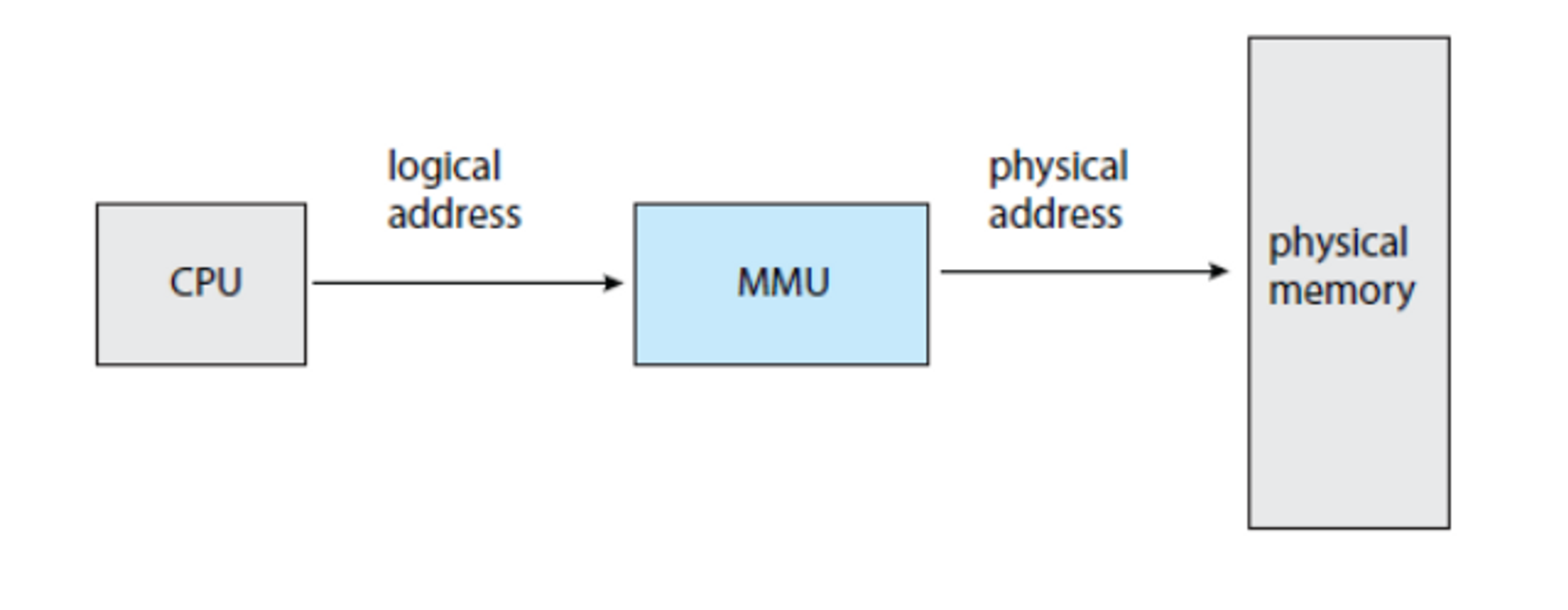
Memory-Management Unit (MMU)
✅ Logical Memory, Physical Memory 주소간의 매핑을 주도적으로 담당하는 하드웨어 로직을 MMU라고 한다. MMU는 CPU 안에 있다.
- 컴파일 타임에 동작하는 임베디드용 에는 mmu가 없는 경우도 존재.
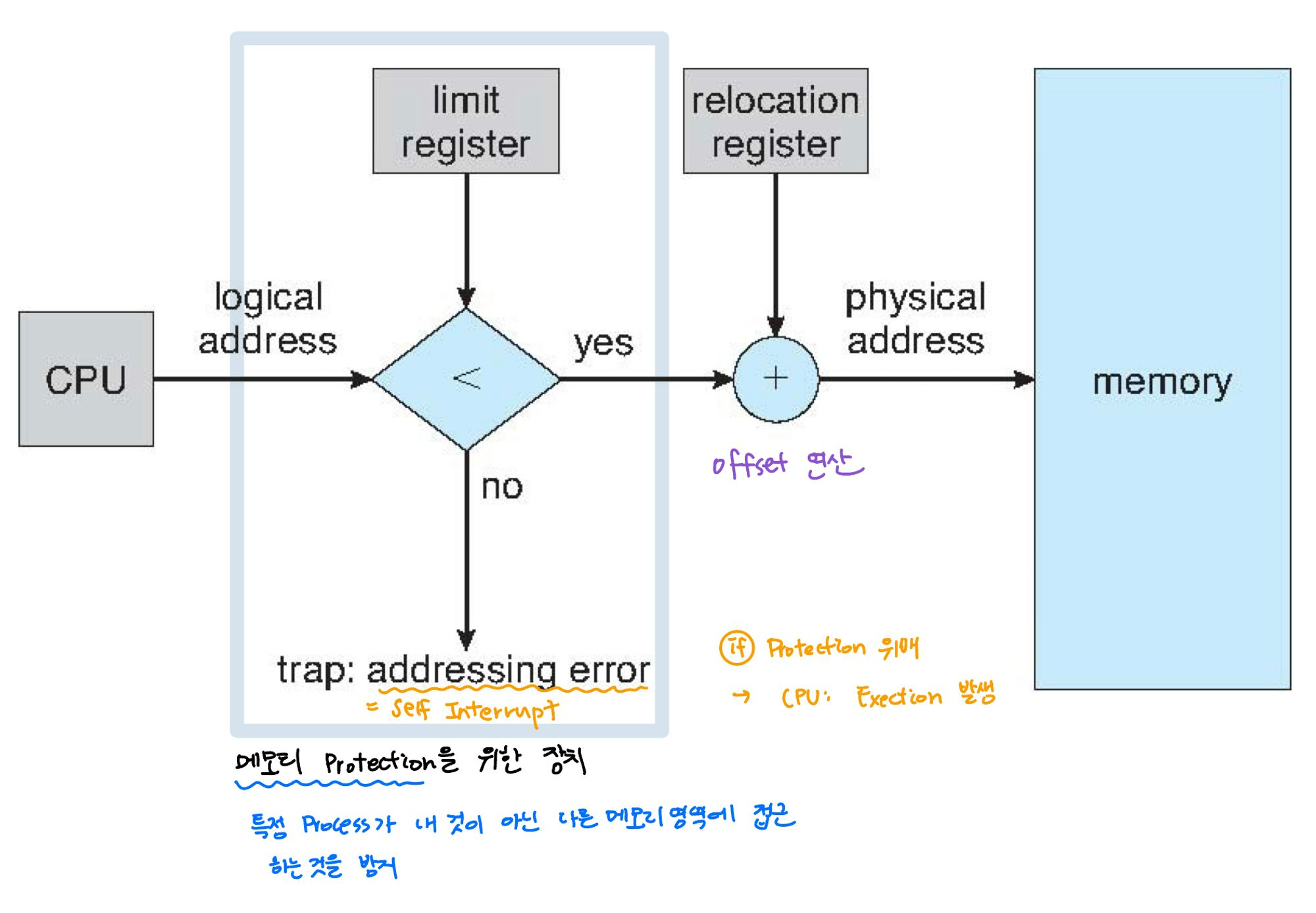
1. Contiguous Allocation
- 메모리에 올릴 때 통째로 빈공간에 넣는 것
Physical address = logical address + relocation register→ MMU가 다 처리를 해준다.
- 로지컬을 피지컬로 매핑시킬 때 어떤 방식으로 할당을 할 것인가에 대한 이슈
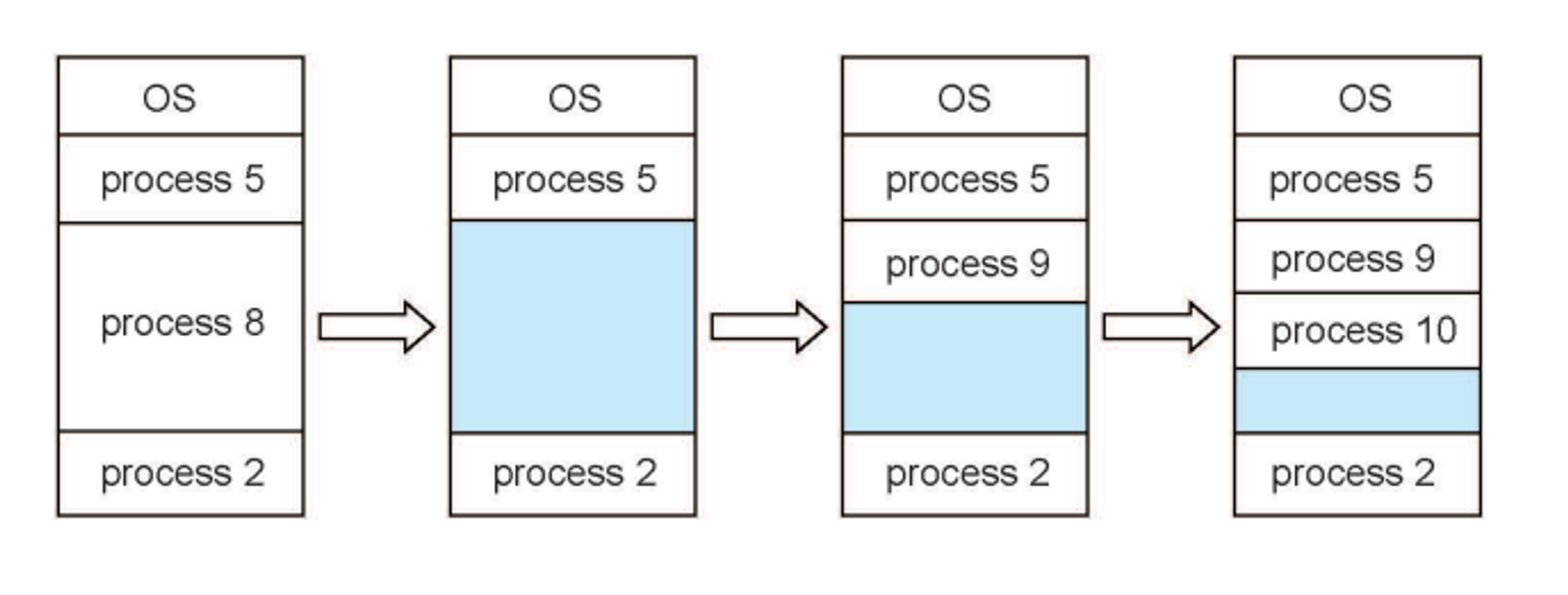
Dynamic Storage - Allocation Problem
Hole이 생김 →fragmentation- 아주 작은 사이즈로 메모리 곳곳에 생길 수 있다 → 비어있는 메모리 공간을 합치면 프로세스 하나를 로드할 수 있는데… 메모리 utilization이 떨어짐..!!
⇒ 짜투리 공간 생김 (cpu utiliaztion 떨어짐)
Solution : 프로세스를 단편화 되어 있는 어떤 hole에 로드를 하는 것이 좋을까?
-
First-fit
무지성으로 처음 만나는 들어갈 수 있는 곳에 넣기 -
Best-fit
전체 홀 중에서 올려야 하는 메모리의 크기와 가장 딱 맞는것에 가까운 것에 집어 넣자 -
Worst-fit
제일 큰 홀에 넣기
→ 제일 큰 홀이 무엇인지 알아내기 위해서 모든 홀을 다 조사 해야한다. overhead가 아주 크다. 그럴바에는 처음부터 끝까지 다 조사하고 비교하지 말고 그냥 처음 만나 곳에다가 넣자! 해서 나온 관점이First-Fit이다.
⇒ 이 세가지를 시뮬레이션으로 검증을 해보았더니 first와 best가 worst보다 조금 더 좋다. 지금은 메모리가 많이 싸졌지만 예전에는 크기도 작고 엄청 비쌌다. 메모리 메니지먼트를 할 때 여러 사용자가 프로세스를 생성했다가 없앴다가 생성했다가 없앴다가를 반복하면 단편화가 심해진다. fragmentation 영역들이 못쓰는 영역이 될 수도 있다. utilization이 떨어진다.
Fragmentation
→ Internal Fragmentation, External Fragmentation
→ External Fragmentation (contiguos allocation에서 발생)이 문제다
compaction이라는 홀을 합쳐주는 해결방안이 있기는 하다. 그런데 i/o가 두번 발생하면서 매우 느리고 오버헤드가 매우 크다
- compaction : 디스크에 모두 내리고 다시 차곡차곡 쌓으면서 큰 홀을 만드는 방식.
💁🏻♀️ 결론 Contiguous Allocation
이론적으로 가능 - 가장 단순하게 로지컬 주소와 피지컬 주소를 트랜지션할 수 있는 방법 이다. 동작하는 로직의 특성상Hole이 생기게 되고 그 홀이 점차 단편화가 이루어지고fragmentation때문에 메모리가 낭비되는 일이 많아진다. 메모리가 낭비되는 것은 큰 문제인데 이것을 해결하기 위한 방법으로compaction이라는 홀을 재구성하는 방법이 존재한다. 그러나 이것을 수행시키기 위해서는 세컨더리 스토리지에다 파편화된 것들 사이에 있는 프로세스를 전부 뺐다가 다시 넣어서 재구성을 해야해서 i/o가 쓰는 것 한 번 읽는 것 한 번 두번이나 해야함으로 느려진다. 그래서 이론적으로 가능하지만 사용하진 않는다.
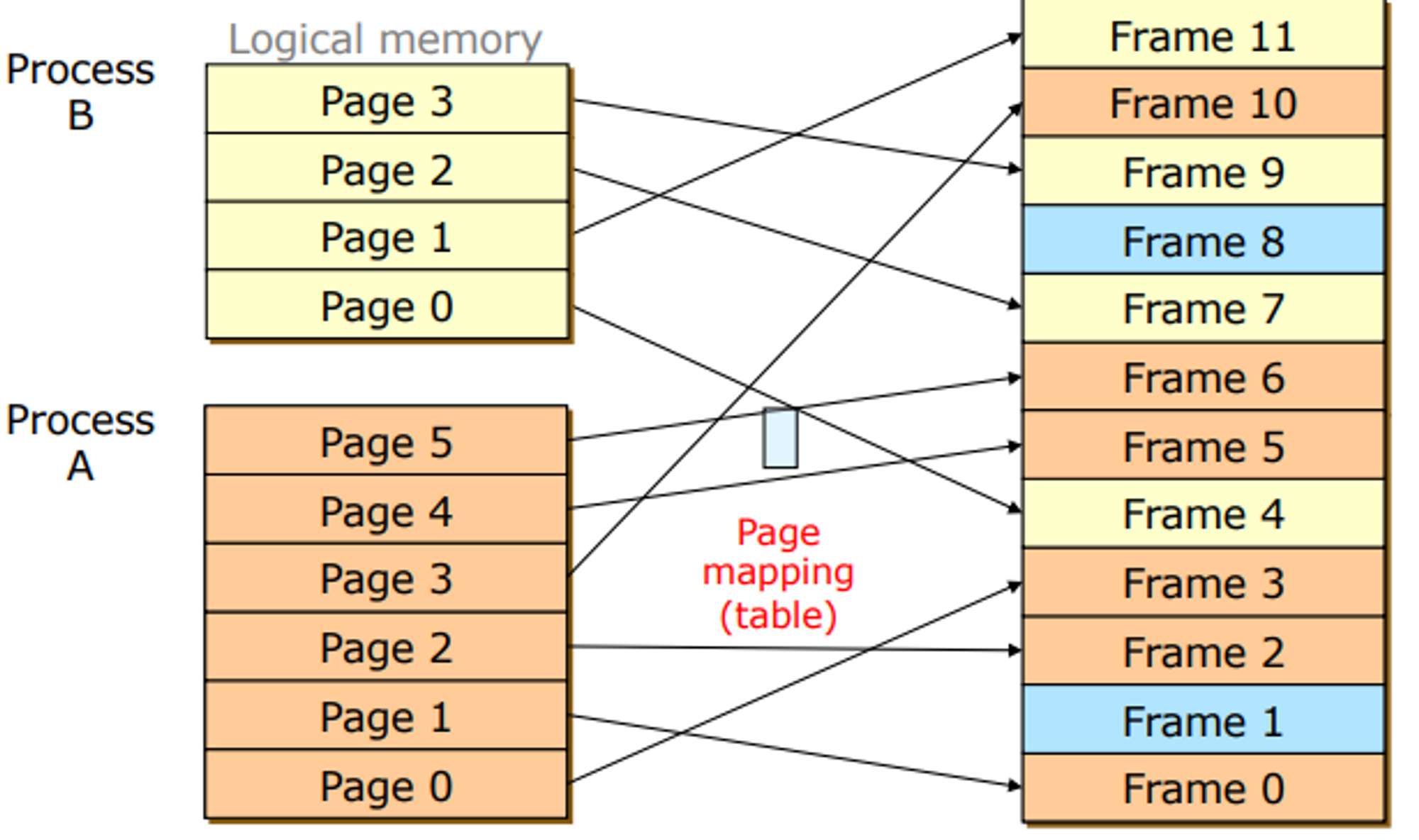
2. Paging
- External Fragmentation 의 문제를 해결하기 위해 등장
- 로지컬 메모리와 피지컬 메모리를 특정 크기를 가지는 유닛으로 쪼개서 테이블을 가지고 매핑을 해준다.
→ 이론적으로는 메모리를 100% 사용이 가능하다. 그러나 실제로는 그렇지 않다.
단위 유닛으로 나누어져 있는 페이지 안에서의 단편화가 일어난다. →Internel Fragmentation- 그러나 단편화된 메모리들을 다 합쳐도 contiguous 보다 훨신 적어 성능이 훨씬 좋아진다.
→ 매핑 테이블도 메모리를 필요로 하고 매핑 과정이 복잡하다는 단점이 있긴 하다.
- 그러나 단편화된 메모리들을 다 합쳐도 contiguous 보다 훨신 적어 성능이 훨씬 좋아진다.
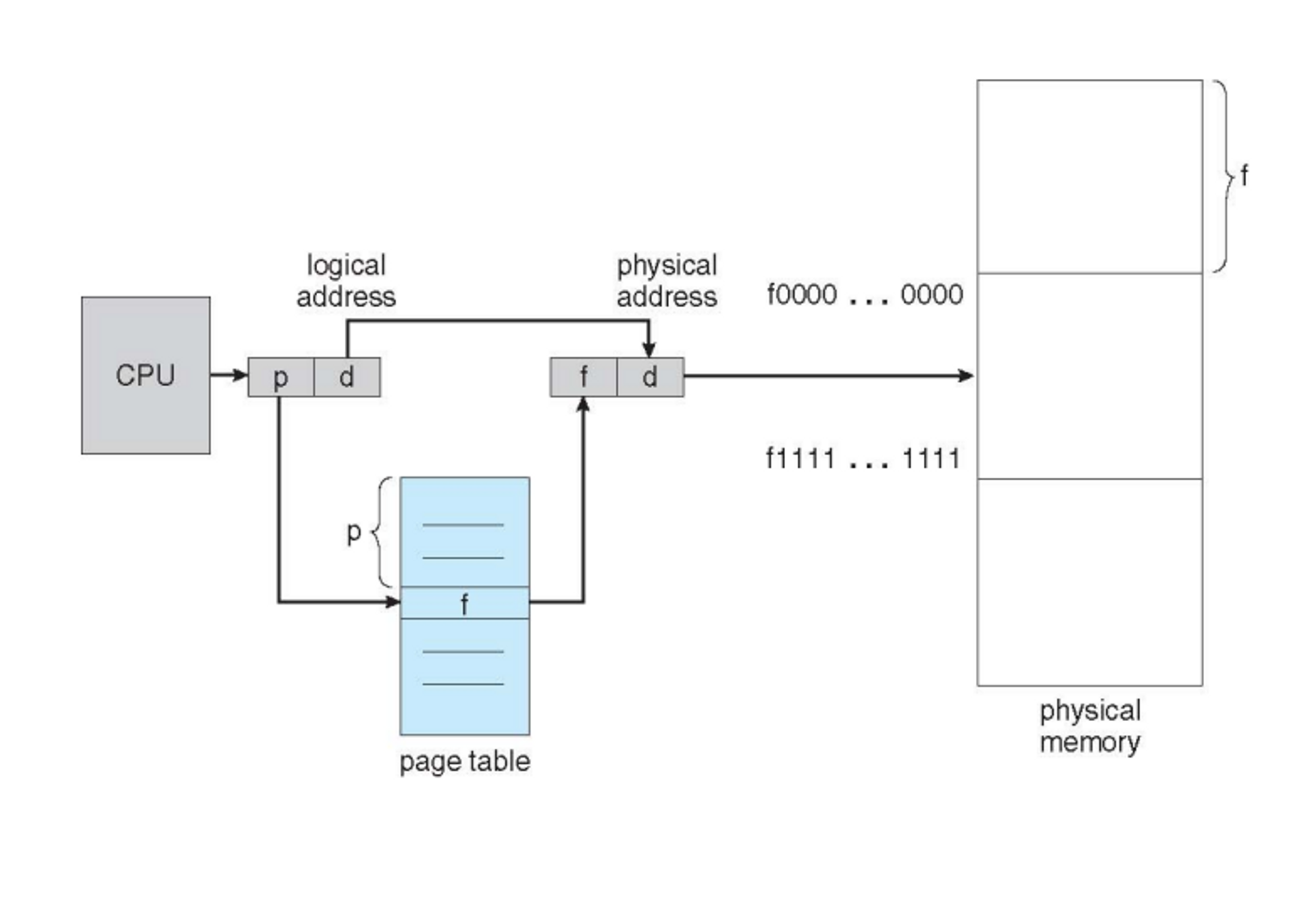
Address Translation
✅ Translating addresses
- logical address : i.e., (p, d)
- Physical address : i.e., (f, d)
✅ Page Tables
- os가 관리
- page number와 frame number 두가지로 매핑 프로그램 실행 → 메모리에 접근이 필요 → 페이지 테이블을 들여다 봐 → 페이지 테이블에 어떤 프레임에 할당이 되어 있는지 찾아보깅
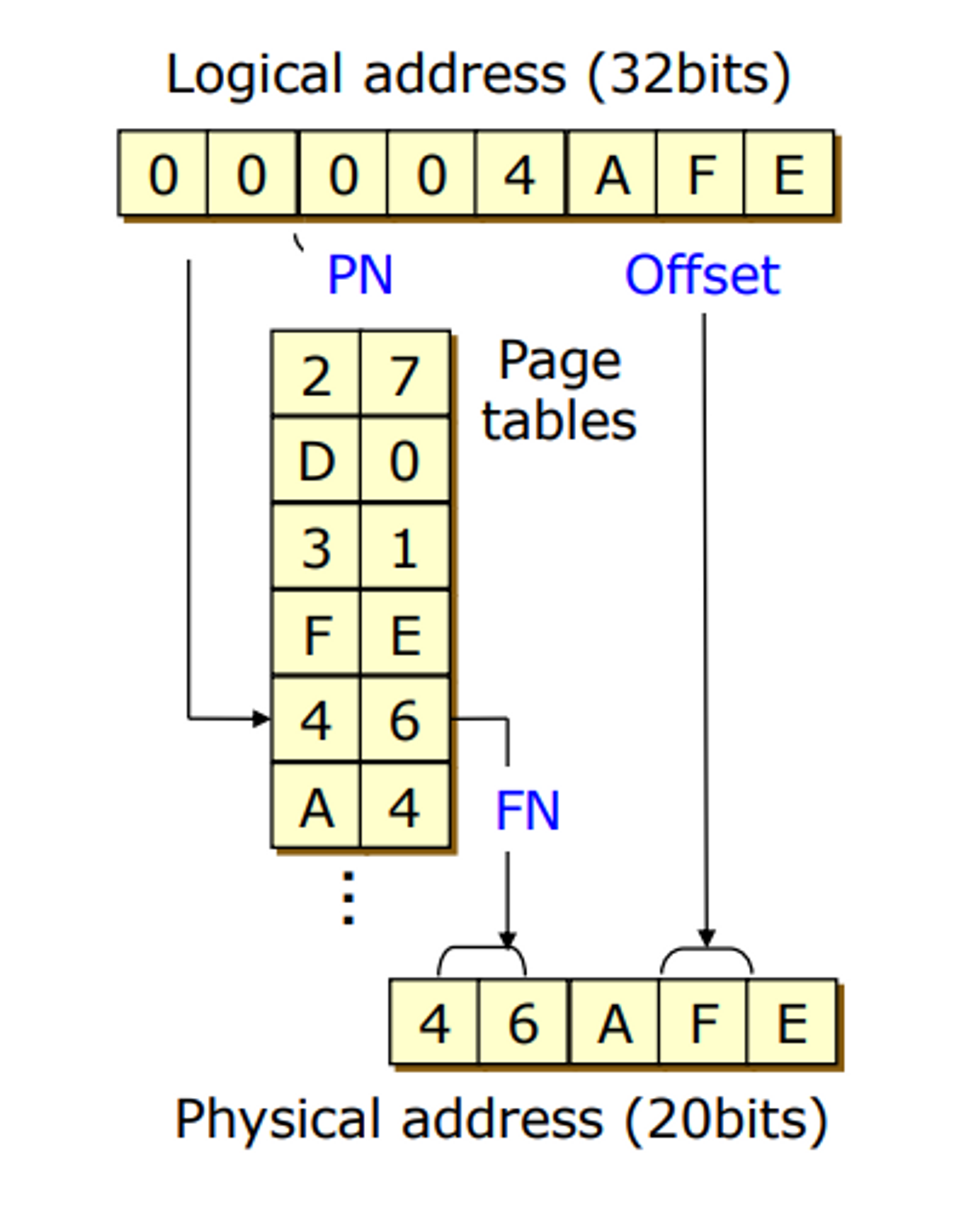
Paging Example
- 최적의 페이지 사이즈 : 4KB
- 페이지를 2^20 개 사용
- 유저 어플리케이션이 동작할 때 0번지 부터 max번지 까지 다 쓸 수 있다고 가정 →32비트 전체를 다 관리해야함. → 프로세스마다 2^20개 만큼 페이지 테입블 엔트리를 가지는 테이블을 다 가지고 있음.
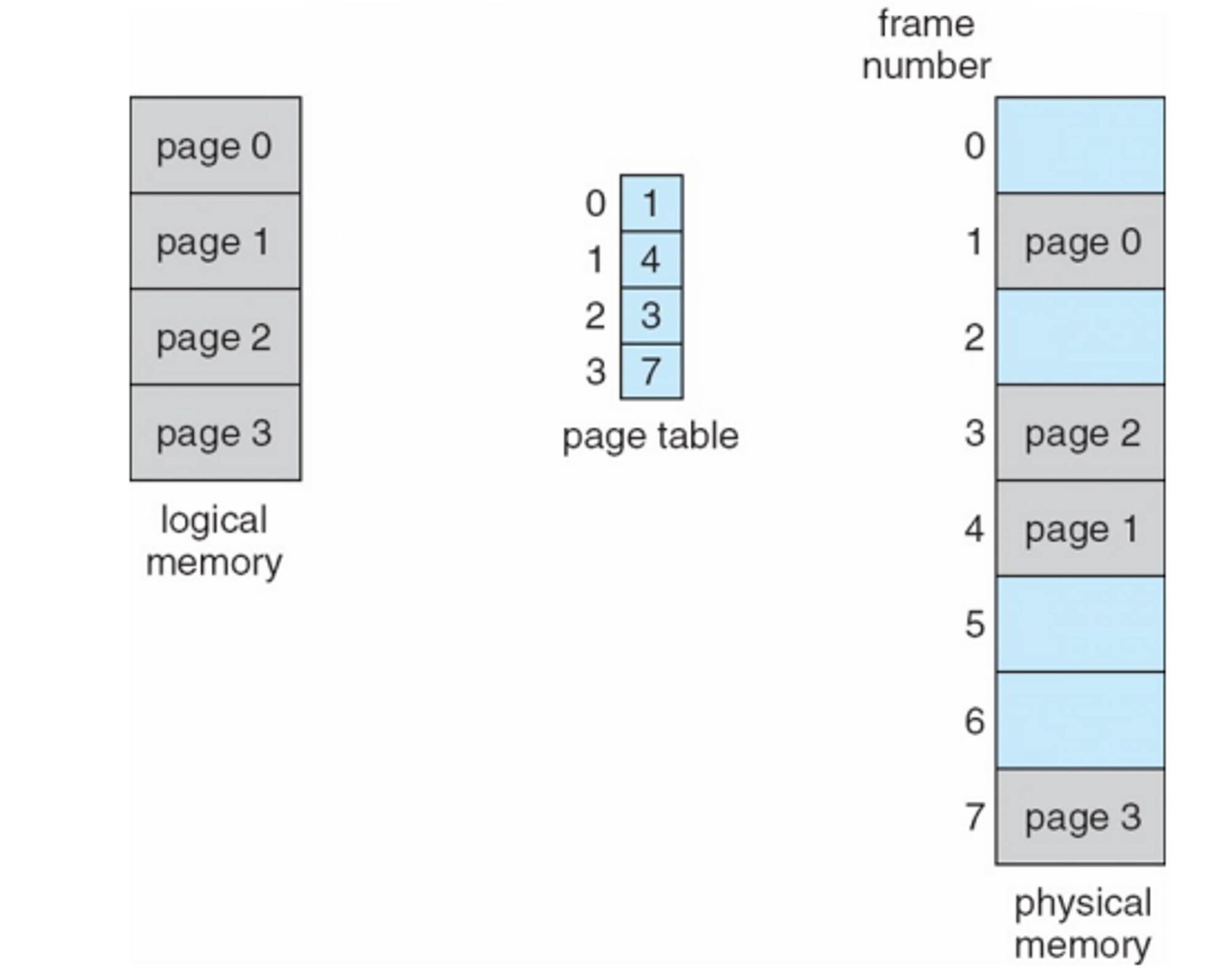
Free Frames
: 비어 있는 Frame
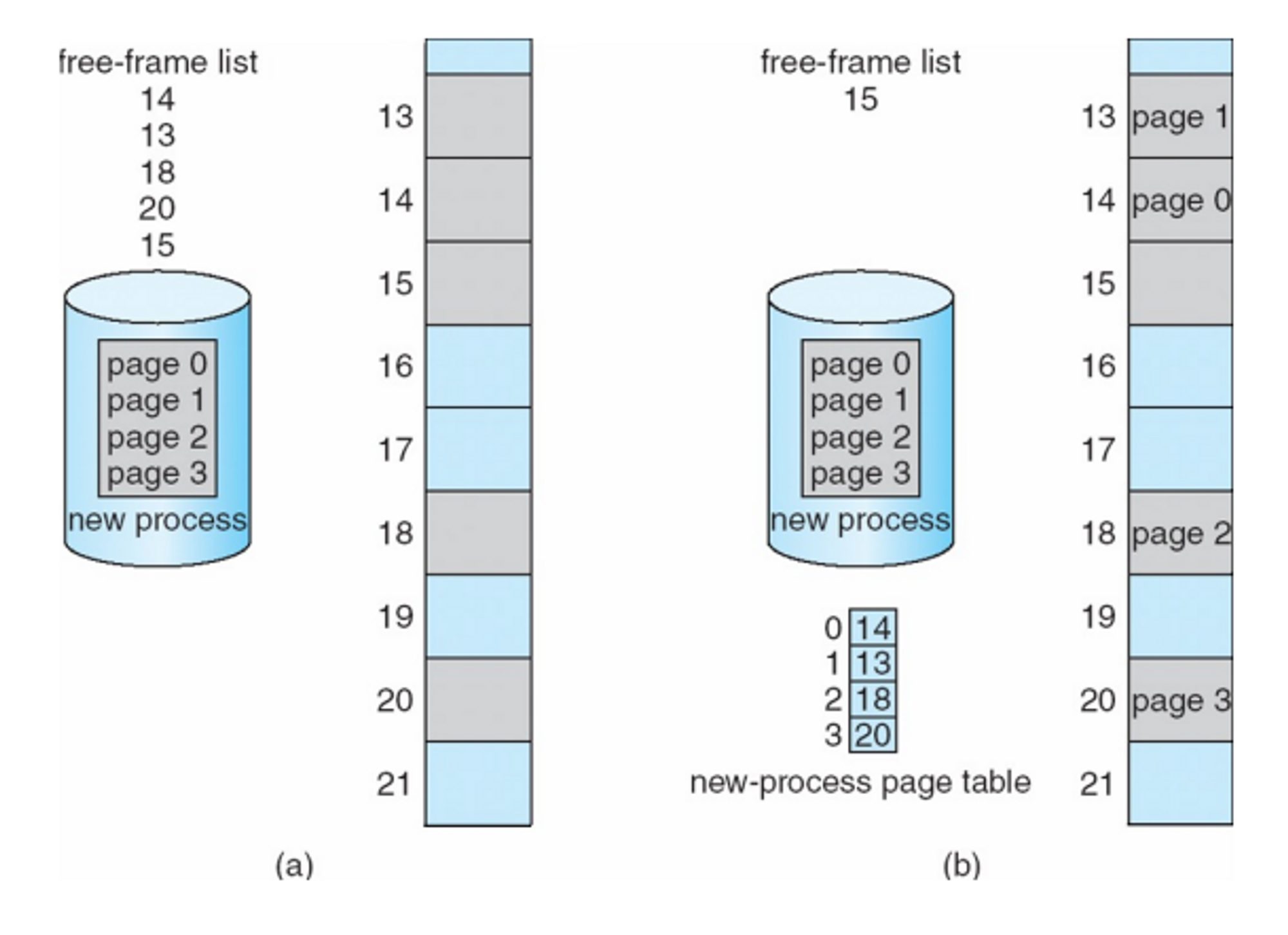
안 쓰는 것을 swap out 필요한 것을 swap in → Virtual memory
Implementation of Page Table
- 프로세스마다 하나씩 존재
- 페이지 테이블 용량이 4mb 먹는당 → 프로세스 마다 있어 → 400mb 아니 너무 크자나 배보다 배꼽이 더 크자나 → 메모리에서의 오버헤드가 커진다.
- 특정 메모리에 접근하기 위해 연산을 두 번 해주어야 하니 오버헤드다 커진다.
📌 메모리에 두 번 접근- 정해져 있는 메모리의 페이지 테이블에 한 번 접근
- 이 때 나온 frame 넘버에다가 offset값을 더한 실질적으로 접근해야하는 주소가 계산이 되고 그 주소로 한 번 더 메모리에 접근
⇒ 이를 해결하기 위해서..
-
Cache the virtual-to-physical translation in hardware
짧은 시간안에 근처에 액세스할 확률이 매우 높음 -
Translation Look-aside Buffer (TLB): 캐시
: Page Table을 Caching하고 있는 것, MMU 안에 특별한 캐시 메모리를 버퍼로 사용하여 페이지 테이즐의 일부를 캐싱할 수 이도록.
: 로켈리티를 활용한 캐싱의 장점을 가져다 쓸 수 있음
→ MMU만 사용하는 캐시
Associative Memory
= CAM (Content Addressable Memory)
- 실제 페이지 넘버에 해당하는 데이터를 주면 대응되는 데이터를 뱉어내는 성격
- parellel하게 서치(비교)가 가능
- Address translation (p, d)
- 특정 페이지에 접근을 하고 싶을 때 MMU에게 페이지 넘버를 물으면 캐싱 되고 있는 테이블이 존재한다면 그에 해당하는 Frame 넘버가 튀어나오는데 그 frame 넘버 가지고 offset 값을 적용해서 메모리에 접근하며 된다. (cache hit)
- 그런데 만약 페이지 5번에 접근하고 싶다고 요청해서 MMU가 TLB에 5번을 집어 넣었는데 대응되는 것이 없어 아무것도 뱉어내지 못할 때는 메모리에 있는 페이지 테이블에 5번에 다시 참조해서 가지고 돌아오고 한 번 참조된 것은 다시 쓰일 수 있으니 버퍼에 업데이트를 해준다.
- cache hit rate 비율이 얼마가 될지가 중요.. → 실제로 99%가 넘는다.
(로켈리티라는 특성 때문에)
💁🏻♀️ 페이지 테이블의 사이즈가 크다. 페이지 테이블은 프로세스마다 독립적으로 가지고 있기 때문에 프로세스 개수만큼 용량도 n배로 늘어난다. 이것들을 전부 mmu에 둘 수 없으니 메모리로 내려야 하는데 메모리에 있으면 2번 접근해야하는 오버헤드가 발생을 한다. mmu에 TLB라고 하는 특이한 캐싱을 할 수 있는 버퍼를 둔다. TLB는 content addressavle memory로 구성이 되어 있기 때문에 값을 던져주면 값을 바로 반환하는 성격을 가지고 있어서 페이지 테이블을 구축하기에 아주 적합한 메모리다. MMU 에 TLB를 집어 넣고 자주 사용되는 페이지들만 캐싱을 해서 사용하게 되면 cache hit이 발생하여 성능이 좋아지게 된다. 실제로 돌려 보았더니 cache hitting rate이 99%가 넘는다.
TLB
- hit ratiio가 높다
- Locality
→ Temporal locality : 한 번 사용이 되면 조만간 또 사용될 확률이 높다
→ Spatial localit : 어떤 특정 부분이 참조가 되면 그 인근에 있는 것도 참조가 될 확률이 높다.
⇒ 이 두가지가 모두 적용이 되어서 Cache hitting ratio가 99%가 넘는다.
✅ Handling TLB misses
- Hardware (MMU): Intel x86
→ MMU가 처리
- Software loaded TLB (OS)
→ OS가 처리하면 overhead가 엄청 크기 때문에 대부분 MMU가 처리하는 방식 사용
✅ Managing TLBs
- Context Switching이 일어나서 현재 수행되던 프로세스가 종료되고 새 프로세스가 실행될 때 이전 프로세스에 대한 TLB는 초기화가 된다.
- 한 프로세스 안에 여러 스레드가 동작을 할 때, 스레드 끼리 context switching이 일어나면 TLB를 초기화하지 않는다.
Effective Access Time (EAT)
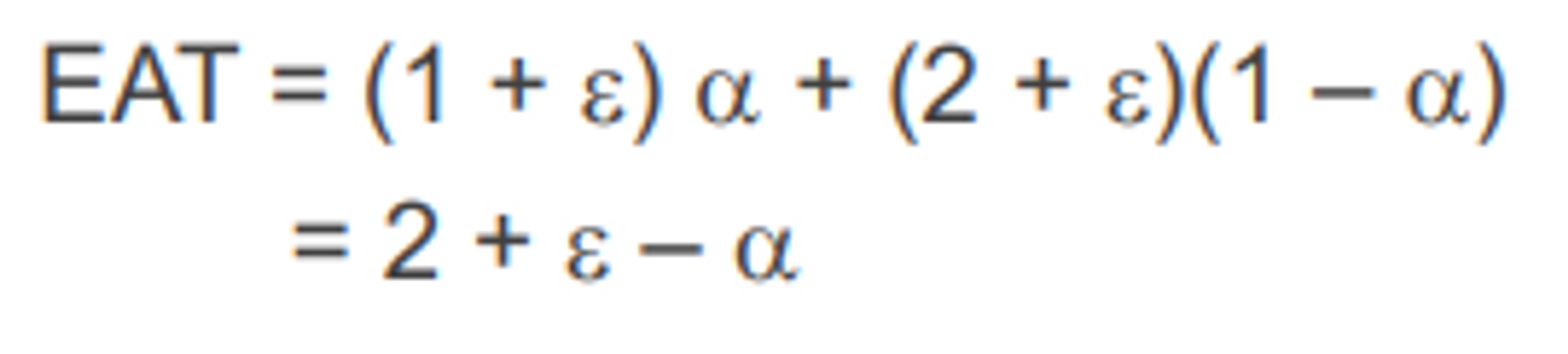
Main Memory Protection
페이지 번호가 0부터 시작해서 최대치를 초과하는지 아닌디를 체크하기
valid-invalid bit → 메모리가 가용한 상태(Frame할당을 받음)이면 valid 가용하지 않은 상태(Frame에 할당이 되어 있지 않음)이면 invalid
Page Table Entries (PTEs)

- Valid bit (V) : 유효한 비트인지 아닌지 검사
- Reference bit (R) : 참조되어있는 페이지인지 아닌지 검사
- Modify bit (M) : 변경되었는지 아닌지
- Protection bits (Prot) : 상태값 저장
- Frame number (FN)
Page Table Structure
페이지 테이블 사이즈가 프로세스마다 4MB이면 좀 과하자나..
Paging 에서의 근본적인 문제
→ Page Table 이 너무 크다 —> 그럼 작게 하면 되겠네?
📌 각각의 기법들이 페이지 테이블의 크기를 줄일 수 있는지, 왜 페이지 테이블이 줄어드는지에 초점을 맞추어 살펴보자
1. Hierarchical Page Tables
→ 실제로 사용되는 방식
페이지 넘버에 해당되는 20bit를 통으로 다 쓰는 것이 아니라 반으로 쪼개서 사용
2. Hashed Page Tables
해쉬 알고리즘을 사용해서 테이블의 사이즈를 줄이자
3. Inverted Page Table
특정 프로세스가 할당받아 사용하는 페이지 테이블은 독립되어 있는데 페이지 테이블을 두는 것이 아닌 프레임 테이블을 둔다.
실제 프로세스가 동작할 때 논리주소는 다 쓰는 경우가 드물어서 페이지 테이블 자체가 낭비이다. 이 문제를 해결 → 피지컬 메모리 관점에서 메모리의 특정 공간은 한 순간에 하나의 프로세스에게만 할당이 된다. 물리주소를 논리주소로 바꾸어서 테이블을 만든다. 로직컬 메모리에 대한 페이지 테이블을 만드는 것이 아니라 frame table을 만든 것이라 생각하면 된다.
→ 프로세스마다 독립적으로 가지는 page table을 만들지 않아도 된다.
→ 효율이 떨어진다. 피지컬 메모리 계속 늘어나..?
Shared Pages Example
페이지 테이블을 유지함으로써 데이터를 공유할 수 있고 이것을 활용해서 피지컬 메모리를 아껴 쓸 수 있다.
EX) 처음 한 번만 실행된 프로세스를 할당을 하고 이후 실행되는 프로세스들은 이미 할당받아진 것들을 공유해서 사용한다. Code Segment는 write가 불가는하고 read와 execution만 가능하다. 그렇기 때문에 가능하다
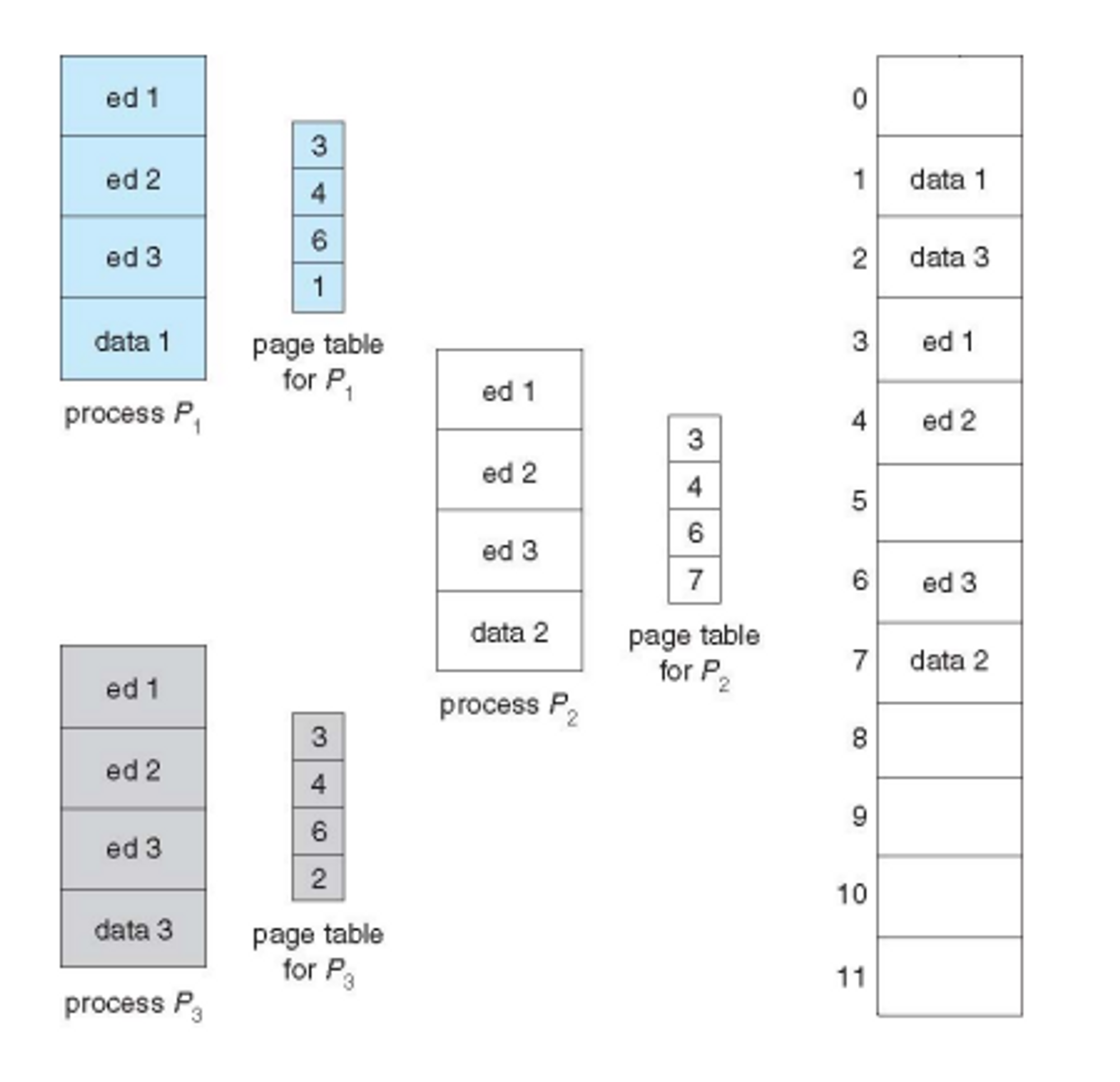
Advantages of Paging
✔ page
✅ 장점
- Physical Memory 할당이 쉽다
- Externel fraagmentation 발생하지 않는다
- 잘 안 쓰는 페이지를 하드 디스크로 옮겨서 메모리 효율을 높일 수 있다
- 페이지를 공유하기 쉽다
- protection하기 쉽다
✅ 단점
- internerl fracmentation
- 두 번 메모리 접근 → TLB로 해결
- 너무 테이블이 크기가 큼 → hierachy
3. Segmentation
페이지로 나눈 부분에 cs랑 const부분이랑 혼재되어 들어갈 수도 있다.
→ protection하기 어렵다
- Externel Fragmentation이 발생할 수 있다.
프로세스의 메모리 맵 구조를 생각해보면 C-S, Data, Heap, Stack 을 따로따로 메모리에 할당을 해주면 좋지 않을까?
특정 Segment에서 어느정도 오프셋을 적용해서 데이터를 읽어줘 라고 명령이 떨어지면 MMU가 그 명령을 받아와서 Segment 테이블에서 s번째 있는 Segment를 찾고 거기에 대응되어 있는 베이스 주소를 주고 혹시나 오프셋이 리밋을 넘어서 이상한 곳을 접근하는 것은 아닌지 검사하여 memort protection. 문제가 없으면 베이스 주소만큼 더하기 해서 오프셋 적용을 해서 피지컬 메모리 읽기
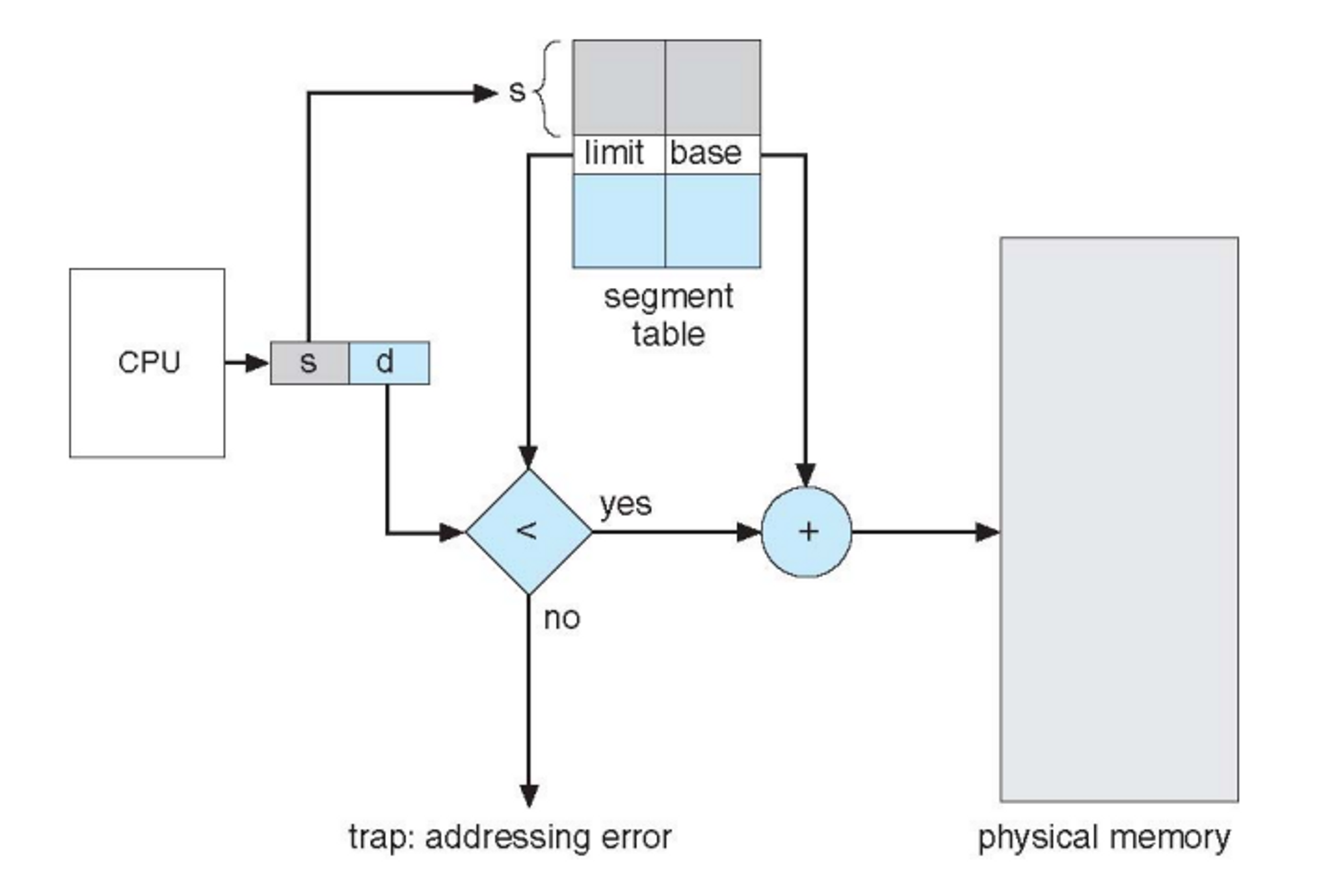
- 프로세스를 fork 했을 때 Code Segment에 해당하는 부분은 바뀌지 않으니 공유해서 사용하고 data 부분은 따로 나누어서 독립적으로 활용
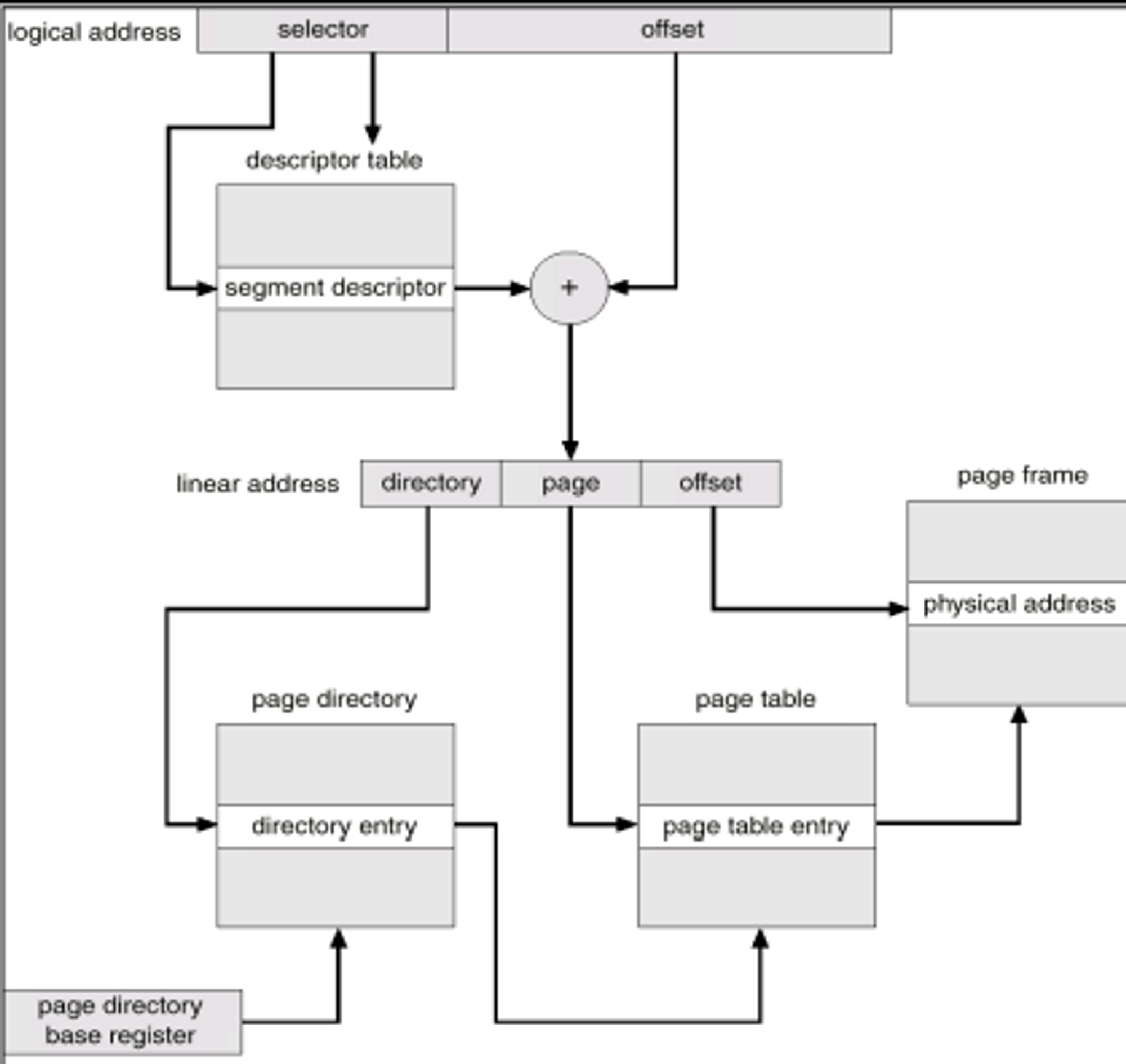
✅ 장점
- 쉐어링하기 편하다
- 테이블의 수(크기)가 작다
- 로켈리티가 좋아진다. (의미 있는 단위로 나누어지기 때문에)
✅ 단점
사이가 다 다르다 → External fragmentation
⇒ 실제로 쓰는건 Paging과 Segmentation을 섞어서 사용한다.
4. Paged segments, Segmentation with Paging
ETC
Address Translation in IA-32
