Mass-Storage
- HDD (Hard Disk Drive)
- SSD (Solid State Disk)
- RAM disk
- Magetic tape
Disk Attachment
-
Host attached via an I/O port
: io 포트를 활용하여 시스템에 바로 들러 붙는 것
: 호스트에 직렬로 붙이는 것
→ PCI, SATA, IDE(PC에서 사용하는 인터페이스), SCSI(서버같은 장치) -
Network attached via a network connection
→ NAS, SAN
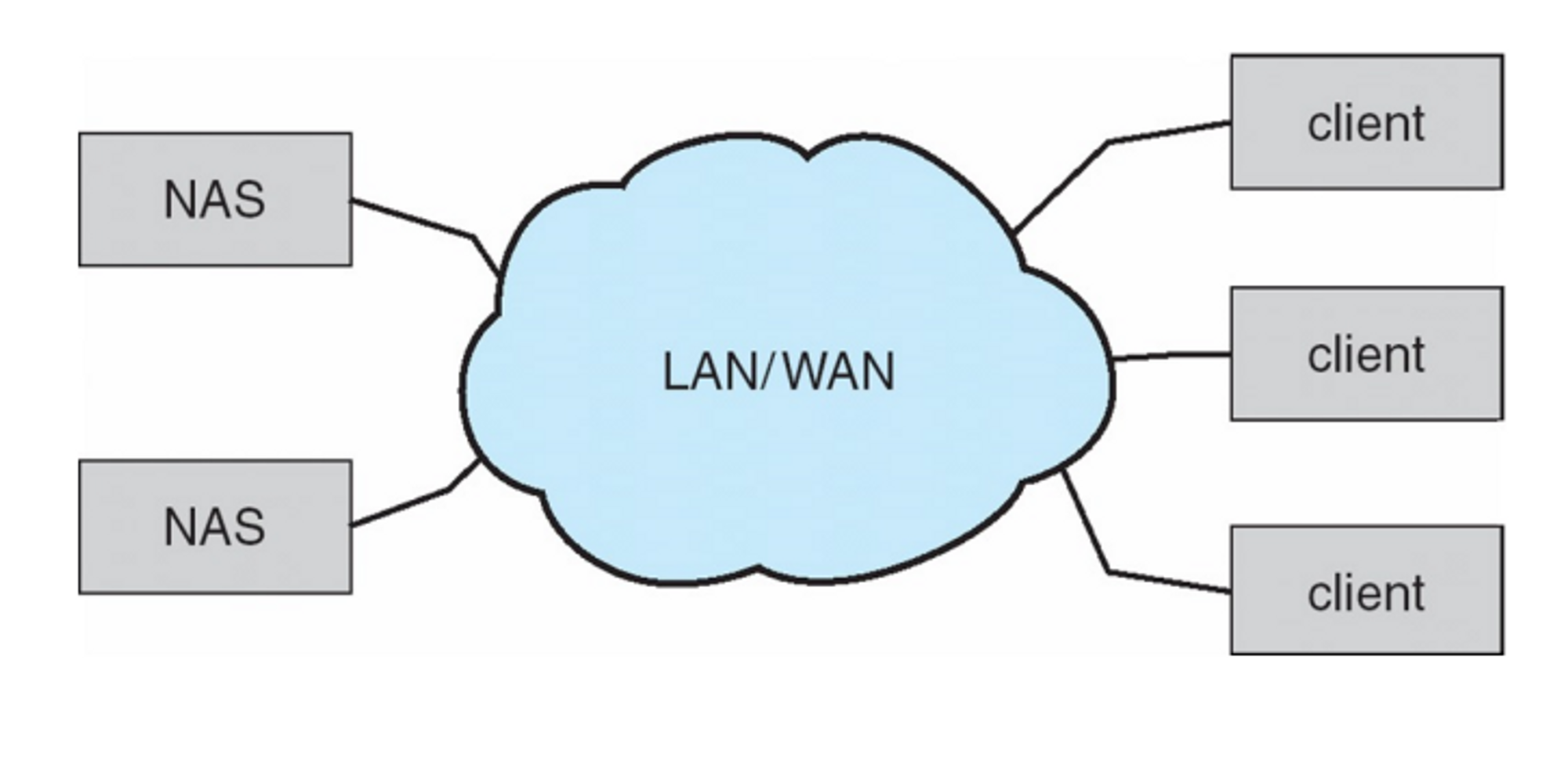
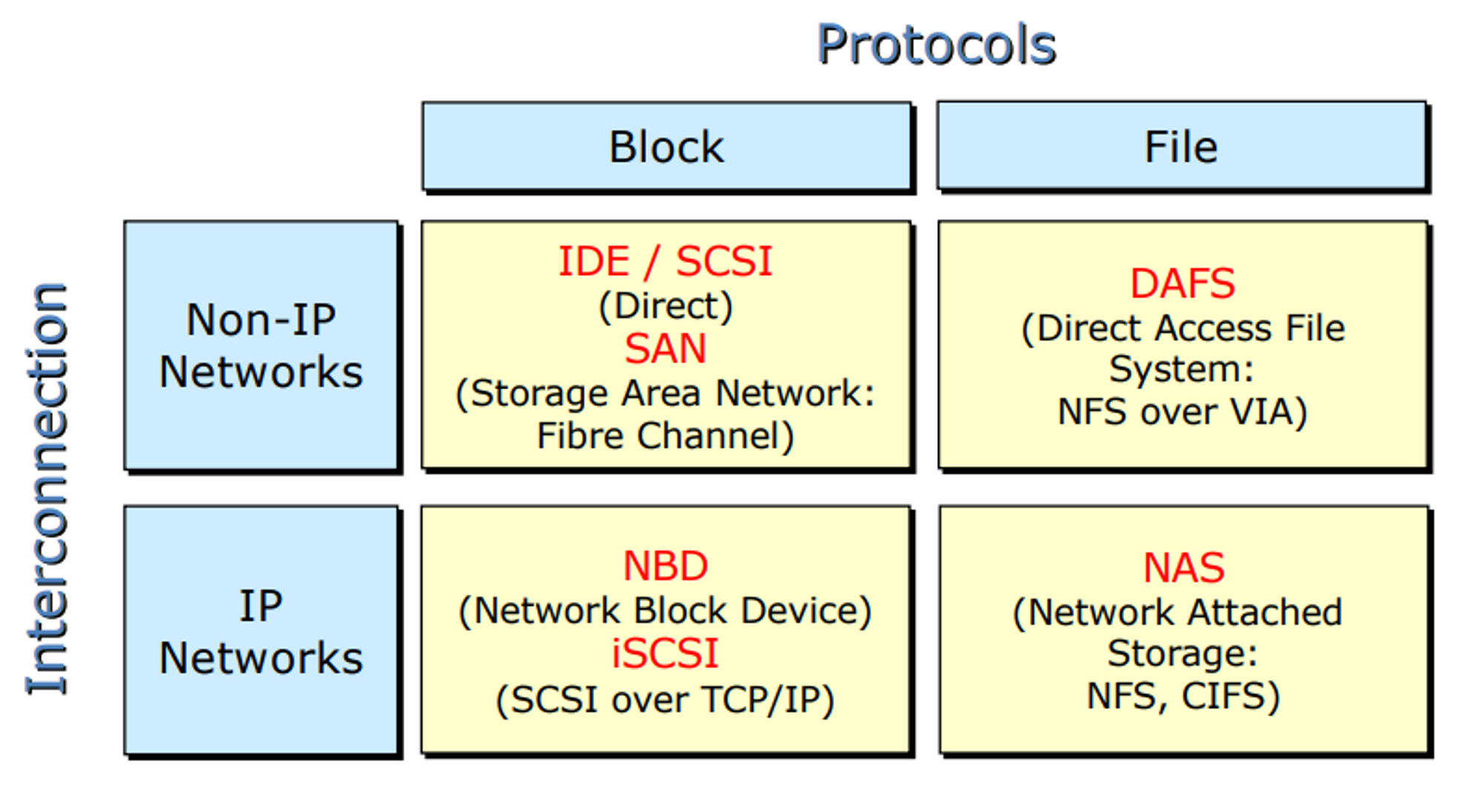
Network-Attached Storage (NAS)
- File-level access
- IDE나 SCSI 같은 경우 블락 단위로 read/write를 한다.
- 반면 NAS같은 경우 독립적인 파일 시스템을 가지고 있기 때문에 운영체제가 무언가 따로 처리할 것도 없고 한 번 잘 세팅해두면 클라이언트 입장에서도 잘 쓸 수 있다.
- 중소규모 회사나 학교에서 많이 사용
→ 용도 : 시크릿한 데이터를 쓰려고, 어둠의 경로로 다운받은 비싼 소프트웨어 공유할 때, 여러 사람들이 틀라이언트가 공유해서 사용,
- IP 기반으로 동작
- 별도의 file 시스템이 존재 → NFS, CIFS, etc.
- 네트워크를 통해 어태치를 하니 로컬에 붙어 있는 디스크처럼 마운트 시킬 수 있다. 원격에 있는 것을 가상으로 연결을 시키는 것이기 때문에
- NAS : 사설 클라우드 스토리지
→ 백업용
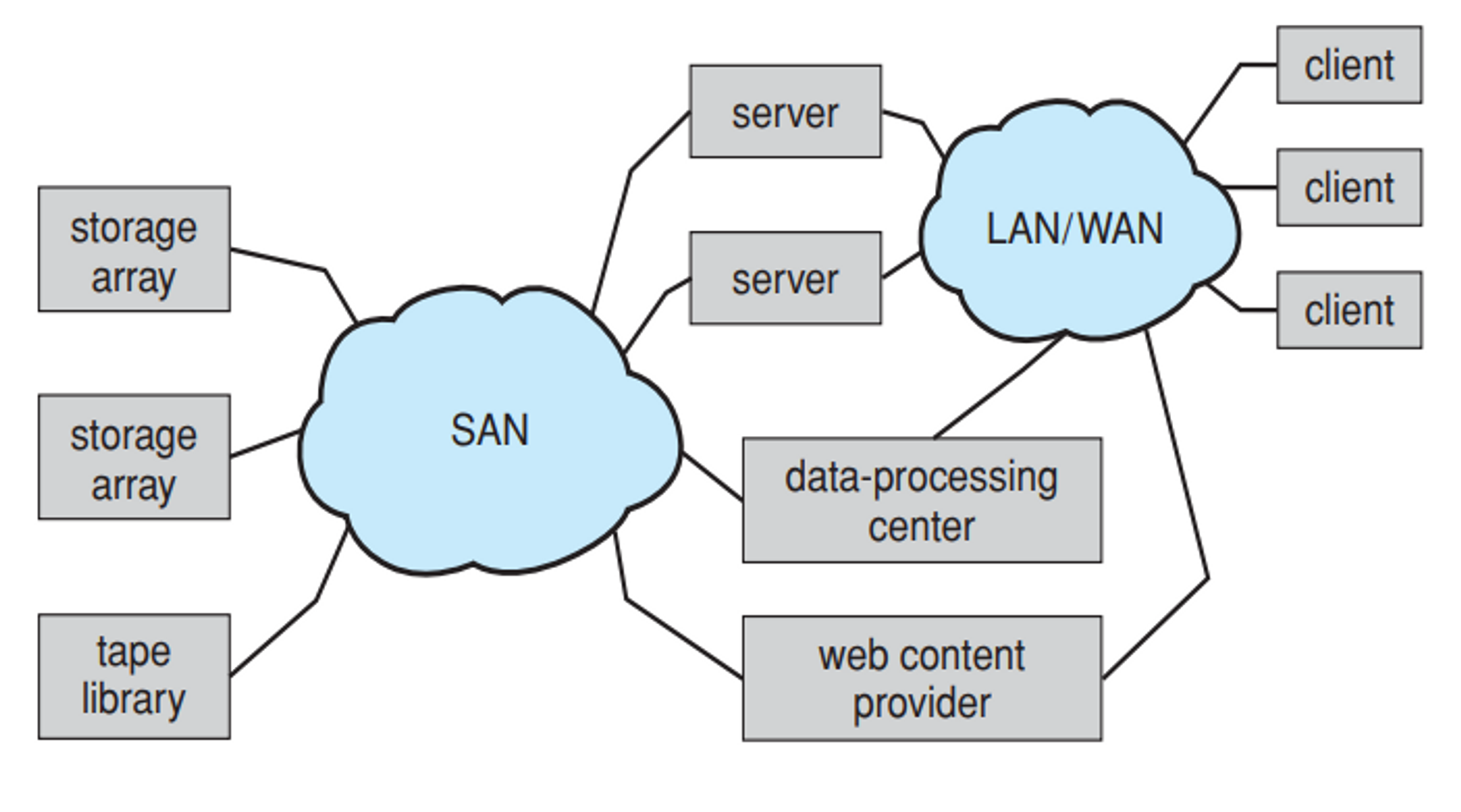
Storage-Area Network (SAN)
-
스토리지를 연결한 네트워크
-
NAS보다 훨씬 큰 것
-
네트워크 자체가 하나의 스토리지
-
SAN을 구성한 네트워크는 일반 네트워크가 아니라 전용의 인터 커넥션 네트워크를 사용한다. 빠르게 동작하도록
-
대량의 데이터를 빠르게 처리해야 하는 곳 → 백엔드, 서버 사이드, 데이터 센터
-
NAS와는 다르게 블락 레벨로 접근할 수 있게 되어 있다
-
샌은 엄청나게 큰 하드디스크라고 생각하면 된다. 전체가 하나의 파일 시스템
File systems for SAN is another story (e.g. GFS)
-
넷플리스에서 샌을 이용하여 영상데이터를 잘 정리해두고 스트리밍 서비스를 한다.
-
서버의 스토리지 시스템
-
NAS와는 다른 점이 나누어져 있는 스토리지 어레이들이 하나로 논리적으로 묶인다
-
Block-level access → Block 단위로 잘라서 넣는다
Storage Architecture
- IDE/ SCSI : OS의 서포트를 받음
- NAS : 별도의 파일 시스템을 가지고 있음.
HDD
- 최소 단위 섹터
- 섹터 들이 모인 것이 트랙
- 같은 트랙에 해당하는 영역을 실린더
- 판떼기 하나하나를 플랫터
- 실제 데이터를 읽을 수 있는 부분이 헤더, 헤드가 달려 있는 곳이 암
Disks and the OS
-
운영체제가 디스크를 관리할 때 피지컬과 로지컬 영역을 나누어서 관리를 한다.
-
로지컬 영역에
-
로지컬 영역이 하이 레벨
Disk logical block (disk block #) -
피지컬 영역이 로우 레벨
Physical disk block (surface, cylinder, sector
Interacting with disks
- 디스크에서 데이터를 읽으려면 어느 트랙에서 어느 실린더에 있느지 이런 정보를 다 알아야하는데 이런것들을 운영체제가 다 처리하는 것은 과거 방식이고 요즘에는 디스크 컨트롤러가 똑똑해서 운영체제에서 몇 번 디스크에 뭐 읽어줘 라고 명령 내리면 디스크 컨트롤러가 알아서 데이터를 읽을 때 필요한 정보들을 저장하고 있다가 알아서 해준다.
- OS의 할 일이 줄어든는 거고 그만큼 성능이 좋아짐. 옛날에 비해
Disk performance
- Arm Seek Time이 성능에 큰 영향을 끼친다.
- Disk scheduling → seel time을 최소화 해서 성능을 높일 수 있는가
Disk scheduling Algorithms
1. FCFS
- 가장 fair
- 성능 구림
- queue에 실린더 번호를 놓고 들어온 순서대로 처리
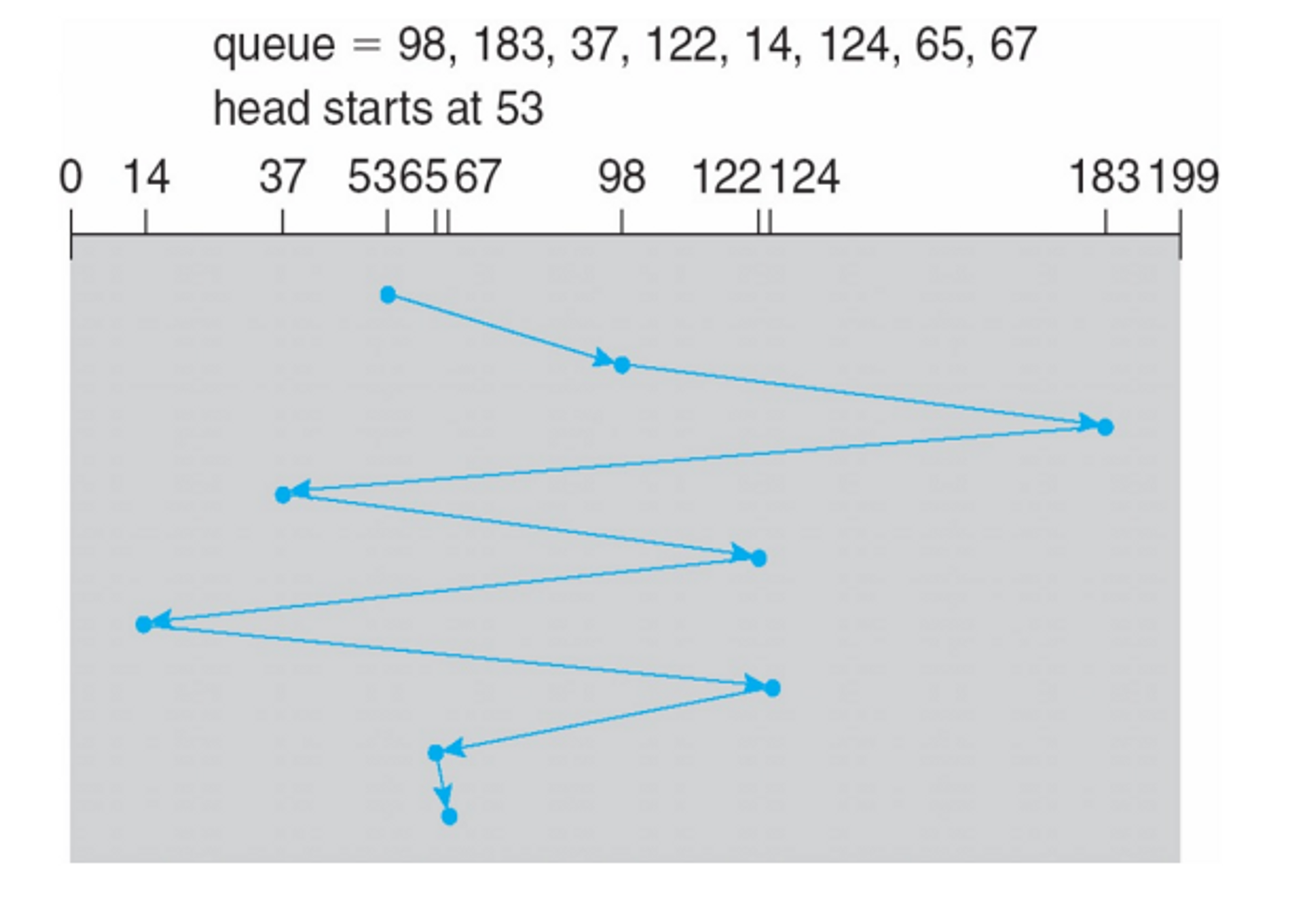
이렇게 하면 640 실린더를 움직여야 함
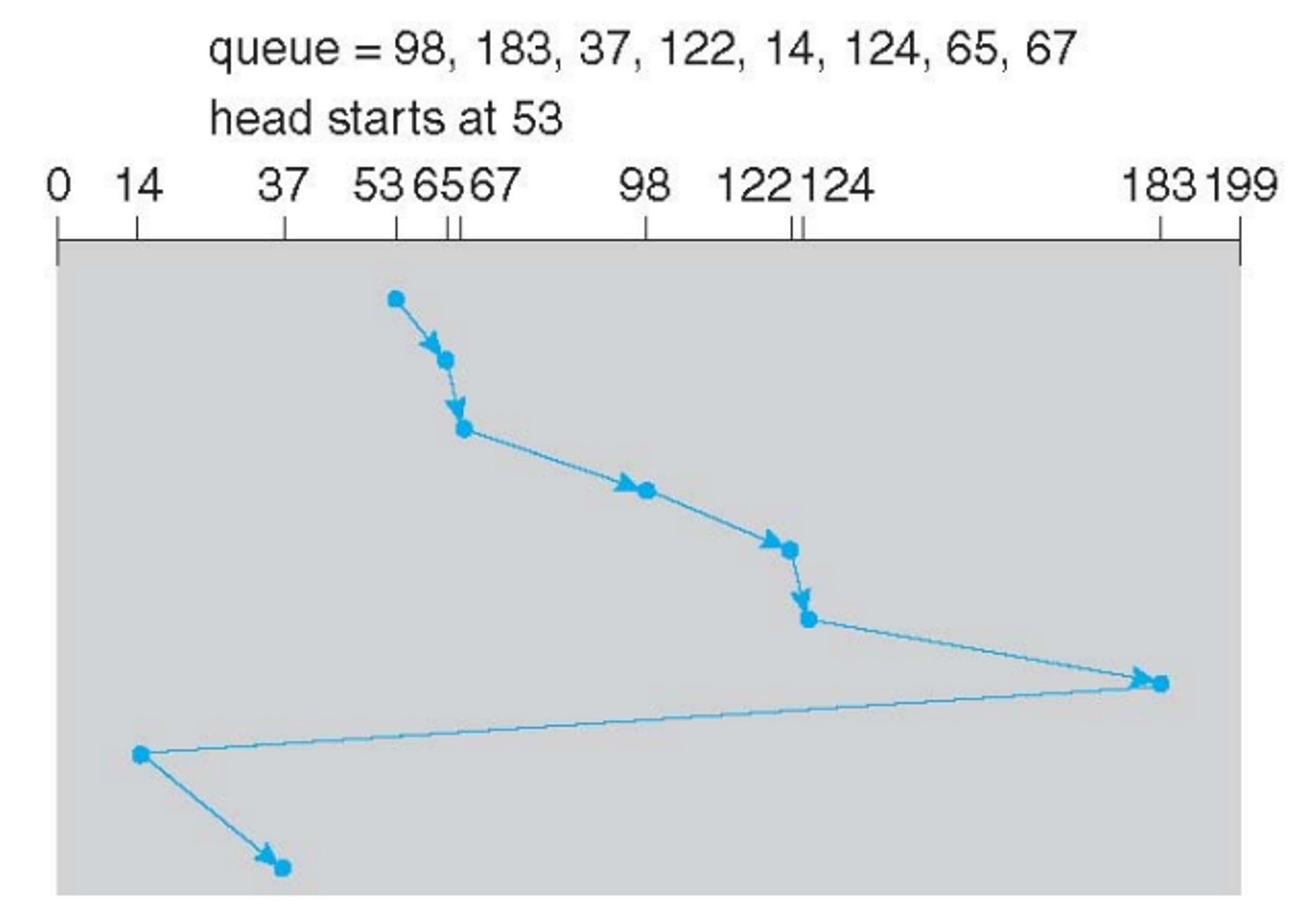
2. SSTF
- 수행시간이 짧은 것을 최우선으로 둠
- Shortest Seek Time First
- seek time이 가장 짧은 방향으로 움직이자
- 큐에 들어온 것 순서를 고려해봤을 때 전체 seek time을 최소화 할 수 있는 순서를 정해 순서대로 진행
- queue가 고정되어있으면 starvation이 존재하지 않는데 중간에 계속 앞쪽에 있는거 있으면 뒤에 있는거는 starvation일어날 수 있다. → 근데 뭐 Aging같은거 쓴다
- 실제로 많이 쓰고 디스크에서 가장 많이 쓰는 버전이다.
- seek time 병목현상의 99%차지

3. SCAN
- elevator algorithm
- 한쪽 방향으로 쭉 끝까지 갔다가 다시 반대로 쭉 가는 방식
- 특정 실린더에 대해 wait time이 길어지는 문제가 있긴 하다

4. C-SCAN
- Provides a more uniform wait time than SCAN
- 한쪽 방향으로 쭉 갔다가 암을 맨 왼쪽으로 쭈욱 가져오고 다시 간다
5. C- Look
- 끝까지 가냐 안가냐에 차이
Selecting a Disk-Scheduling Algorithm
Disk-Scheduling 은 어떤 상황에서 가장 효과가 좋을가?
-> 디스크 엑세스가 많은 경우 Disk-Scheduling이 유효하다
Disk Controllers
-
과거에는 운체가 하던일을 디스크 컨트롤러가 하드웨어적으로 처리를 하기 때문에 더 빠르게 처리가 가능하다
-
Intelligent features
- Read-ahead: the current track → spatial locality
디스크 읽을 때 앞에것도 미리 읽어서 운체에게 올려서 캐싱하고 있음
- Request reordering
운영체제가 로지컬 레벨에서 파일 시스템을 구축하고 있고 거기서 어떤 것을 읽어오는데 그게 미스가 나는경우 조금더 옵티멀하게 동작하도록 하기위해서 request자체를 최적화해서 다시 오더리하는 과정
- Bad Sector 쓰지 않도록 알아서 처리
- hardware failure의 fail이 날 대마다 운영체제한테 올려주는 것이 아니라 어느정도 핸들링할 수 있는 부분은 알아서 해준다
- Read-ahead: the current track → spatial locality
-
Request retry on hardware failure
Swap-Space Management
: Virtual memory쓸 때 필요
언제 얼만큼 만들어 쓸 것인가 중요
- 유닉스 계열은 별도의 파티션을 만들고 이거의 용량을 메인 메모리에 두배만큼 잡은
- 윈도우는 시스템 디렉토리 밑에 파일로 관리한다.
- 윈도우 운영체제가 설치된 c드라이브에 남은 용량을 피지컬 메모리에 두배 정도 만큼의 여유공간이 남겨야 성능이 나온다.
RAID(Redundant Array of Inexpensive Disks)
여러개의 디스크를 어떻게 하면 효과적(신뢰성+ 성능)으로 쓸 수 있는지
- Redundant Array of Inexpensive Disks
싼 디스크를 배열로 주르륵 나열해서 쓰겠다. Storage system - Motivations
- 퍼포먼스를 높이면서 신뢰성을 높이는 것
신뢰성 - 중복해서 쓰는 것 (복사본을 만들어 두는 것)
- Mirroring : 특정 데이터를 디스크1에 쓰면 디스크2에도 똑같은 위치에 쓰는 것. 디스크1 지워지더라고 2에 남아 있음, 완전히 중복해서 쓰는 것.
- 특정 부분이 crack이 난다던지 물리적인 이슈가 생겨도 복사본을 가지고 신뢰성을 높이는 방법
- Parity or error-correcting codes
-
깨진 데이터를 복구하는 code
-
Parity 는 error-correcting codes 보다 복구할 수 있는 범위가 적다.
-
Mirroring은 완전히 복사본을 만드는 것이라면 이건 기존의 원본 데이터를 복구 가능한 형태로 줄여두는 것.
-
error-correcting codes는 조금 긴 대신에 복구할 수 있는 확률이 높다. 반면 Mirroring 코드는 짧은데 복구할 확률이 낮아진다.
-
하드 디스크 중복 작성에 Mirroring 보다 용량을 줄일 수 있다는 장점
-
Mirroring 은 있는 그대로 복사를 했으니까 안되면 바로 접근했을 때 data가 튀어 나오는데 이건 복구하기 위해서 연산이 필요하기 때문에 오버헤드가 크다.
- 디스크123 이 있는데 이것들을 복구할 수 있는 erroe correction code를 한 쪽 파티션에 집어 넣어서 a0 a1이 고장이 나도 error correction code를 활용하여 복구를 할 수 있다
⇒ 1,2 번 다 안 사용, 1번만 사용, 2번만 사용, 12번 다 사용 총 4가지 경우의 수
- 아무것도 안해버리기
퍼포먼스 Improving performance via parallelism
Data striping: bit-level vs. block-level
bit-level: 써야할 하나의 disk block이 있다
하나의 block을 쪼개서 각각의 디스크에 나누어 저장하는 것
block-level
특정 파일이 여러개의 블록으로 구성이 되어 있으면 블럭 단위로 나누어 striping을 하는 것
💁♀️ 어떨 때 가장 효과가 좋을까?
넷플릭스에서 운영하는 데이터 센터에 디스크가 3개가 있다. Data striping을 사용하지 않는다고 가정. 사람들이 많이 보는 영화를 1, 적당히 보는 영화를 2, 고전영화를 3이라고 한다. 각각의 디스크에 1, 2, 3을 저장. 데이터 서버에 연결이 되어 있다. 수많은 클라이언트들이 1번만 보면 1번만 고생하고 나머지 둘은 고생을 하게 된다.
그런데 만약 각각의 디스크에 1-1, 1-2, 1-3 컨텐츠를 삼등분해서 나누어 저장을 하면 병렬적으로 노는 디스크가 없도록 분산되어 동작한다.
✔ bit level이 좋을까 block level이 좋을까?
spatial locality 때문에 block레벨로 읽고 저장하는 것이 좋다
⇒ striping을 안하는 방식 하나, bit level쓰는 방식 하나, block level하나 총 3가지
⇒ 3x4 =12 r가지 중 유의미한 것이 10개
Multiple Disks vs. RAID
- Disck Controller : 각각의 디스크를 별개의 디스크로 바라본다
- RAID : 디스들을 하나의 디스크로 보게 된다.
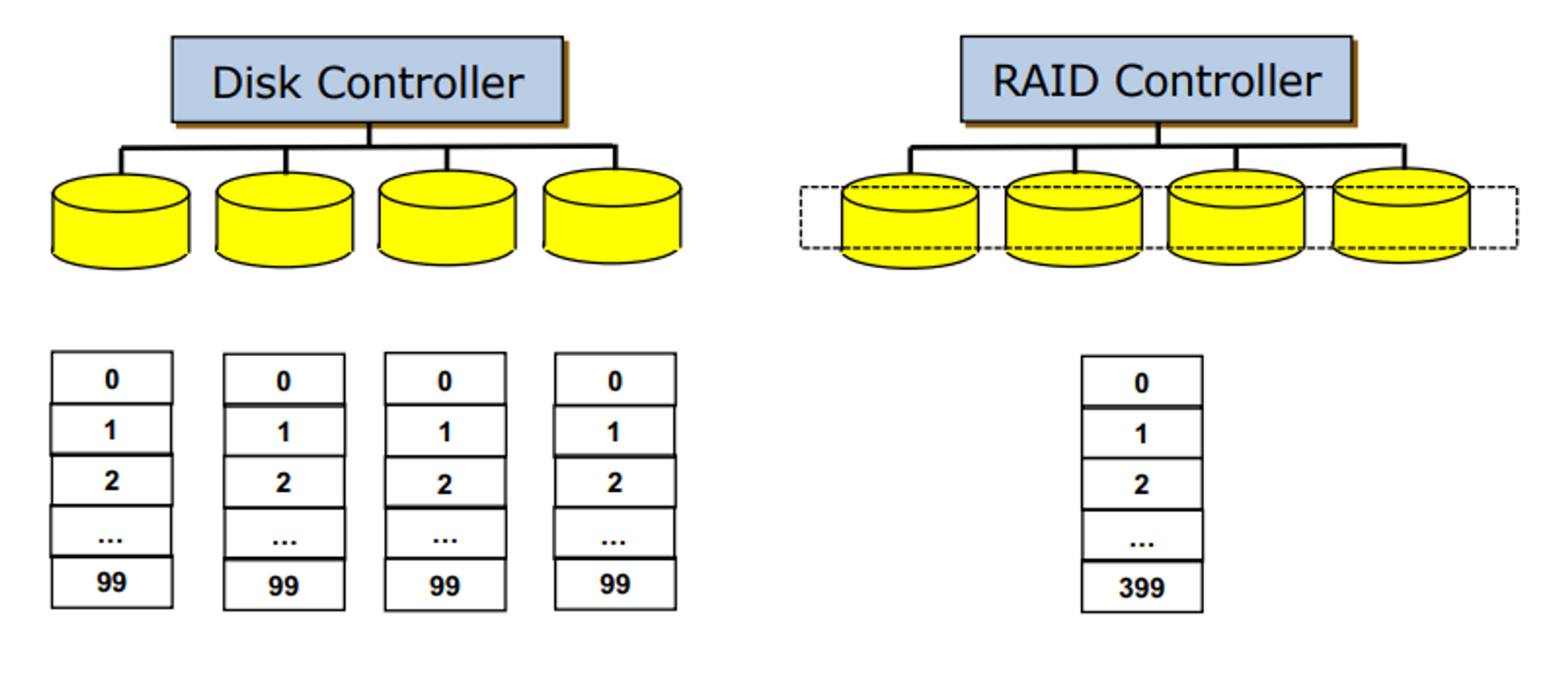
- 다수의 디스크를 하나의 디스크로 묶어서 사용
- 목적: 성능 + 신뢰성
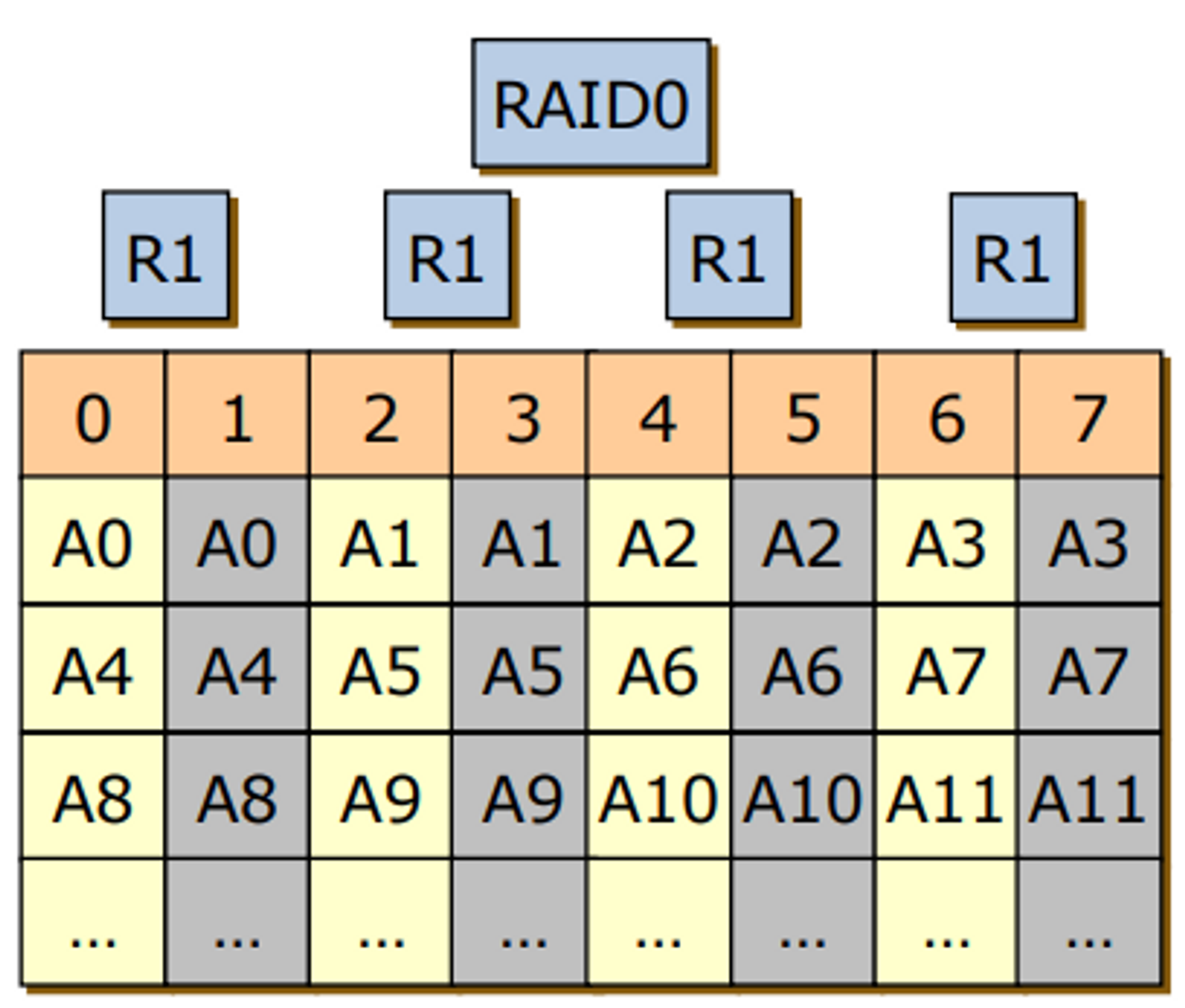
RAID 0
- 무조건 성능, 신뢰성을 제로
- block level에 data striping
- 유저 어플리케이션에서 A를 읽을래
- OS한테 부탁
- OS가 처리를 해서 raid controller에게 명령
- 각각의 디스크에게 a라는 file과 관련되어 있는 block들 다 내놔
- 0-3번 디스크에 중복되어 있는 것이 없기 때문에 4개의 디스크가 있으면 acsess time이 1/4로 줄어 성능이 4배로 늘어난다.
RAID 1
- 성능보다 신뢰성
- 미러링만 한다. no data striping
- 신뢰성은 확보할 수 있지만 비싸다
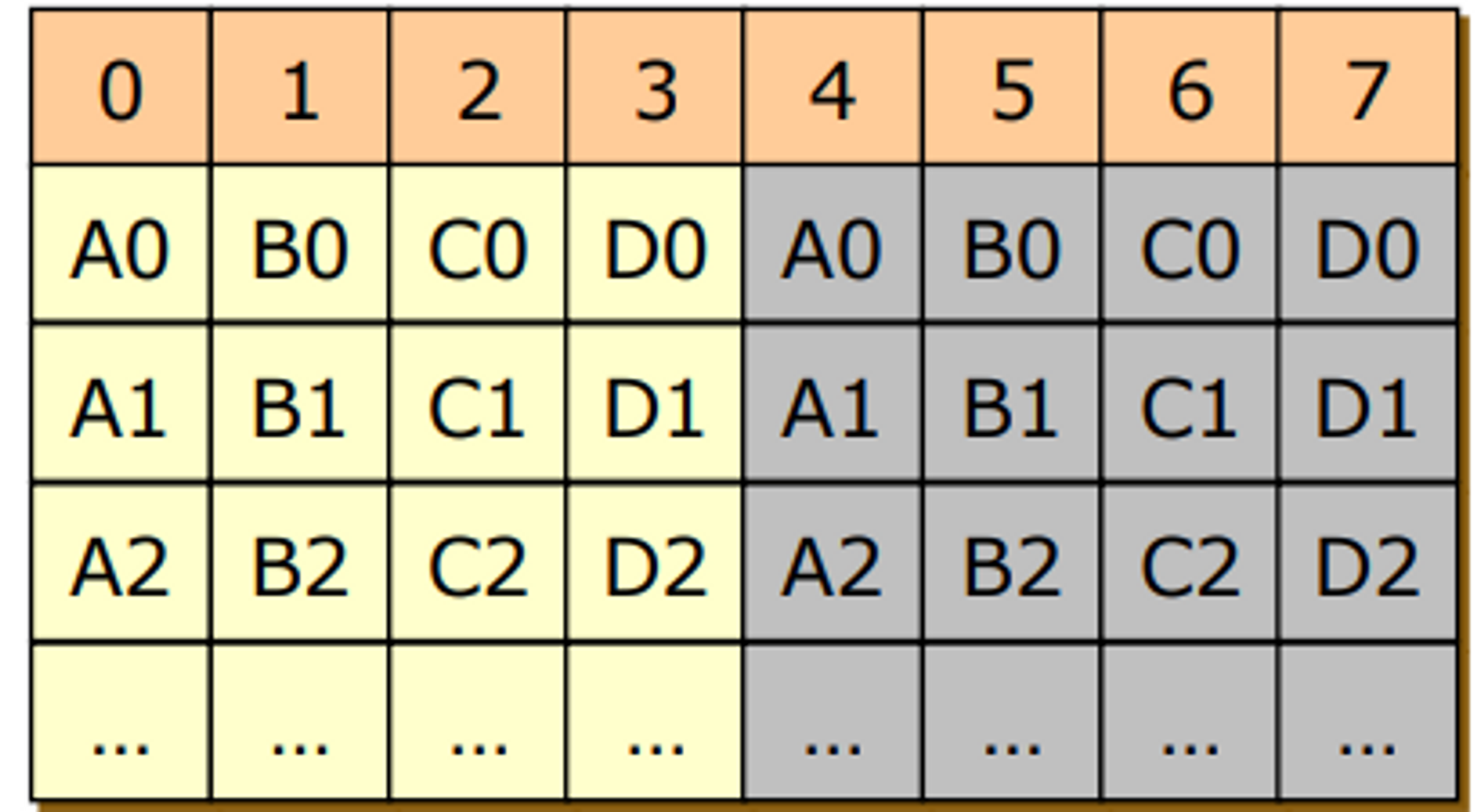
RAID 2
- 성능도 신리성도 둘 다
- error-correcting codes (ECC)를 사용해서 3개의 레코드로 구성된 에러 코렉팅 코드를 4-6에 유지, 원래 데이터를 0-3에 유지
- 연산을 통해 복구가 가능
- 연산이 많이 필요하고 striping을 bit level로 했기 때문에 더 안쓰이는 기법이다.
- bit 레벨
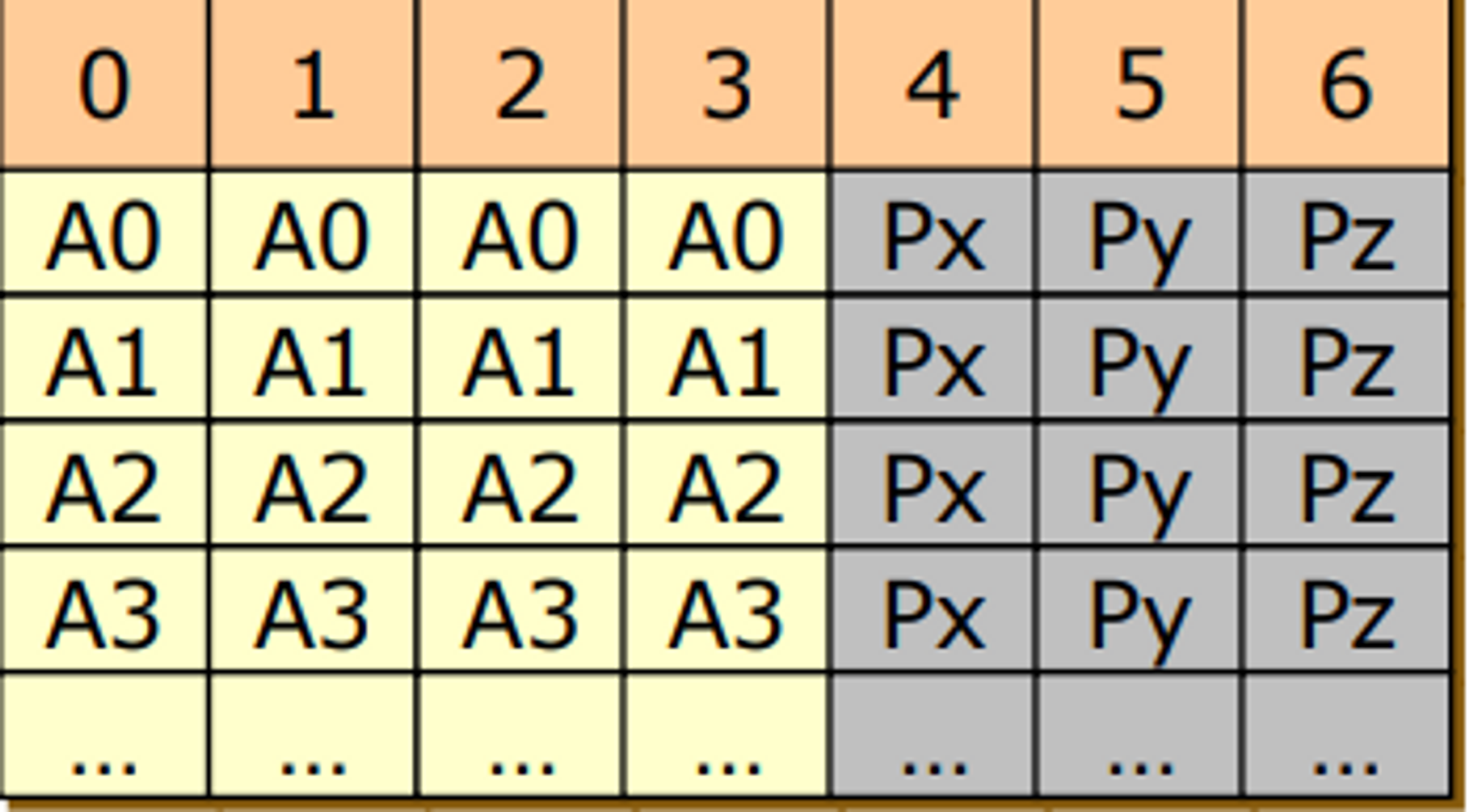
RAID 3
- error-correcting codes를 썼더니 디스크가 미러링하는 것과 별차잉가 없네? 더 줄여보자
- parity 적용
- bit level striping 을 수행하기 때문에 성능이 좋진 않음! 안씀
- RAID2와 비교했을 때 용량을 적게 사용
- 앞에 있는 데이터가 문제가 생겼을 때 복구가 가능하도록
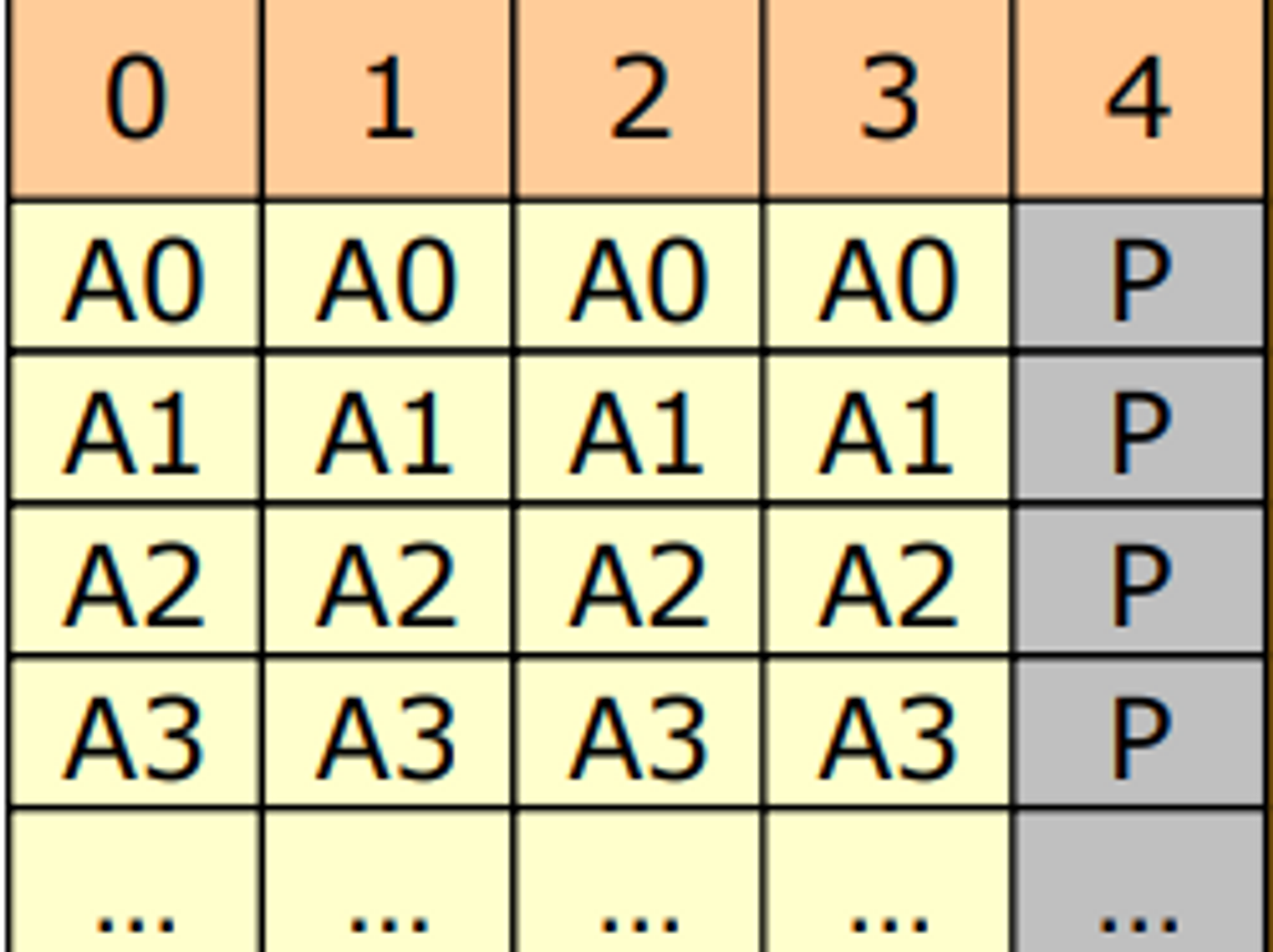
RAID 4
- RAID3의 단점인 bit level striping 을 block level로 바꾼 것
- 신뢰성을 높이기 위해 parity bit 사용
- 성능이 좀더 향상
- 비트를 써서 스패셜 로켈리티 확보가 안되서 성능이 안나오니
- 3를 block level로 바꾼 것
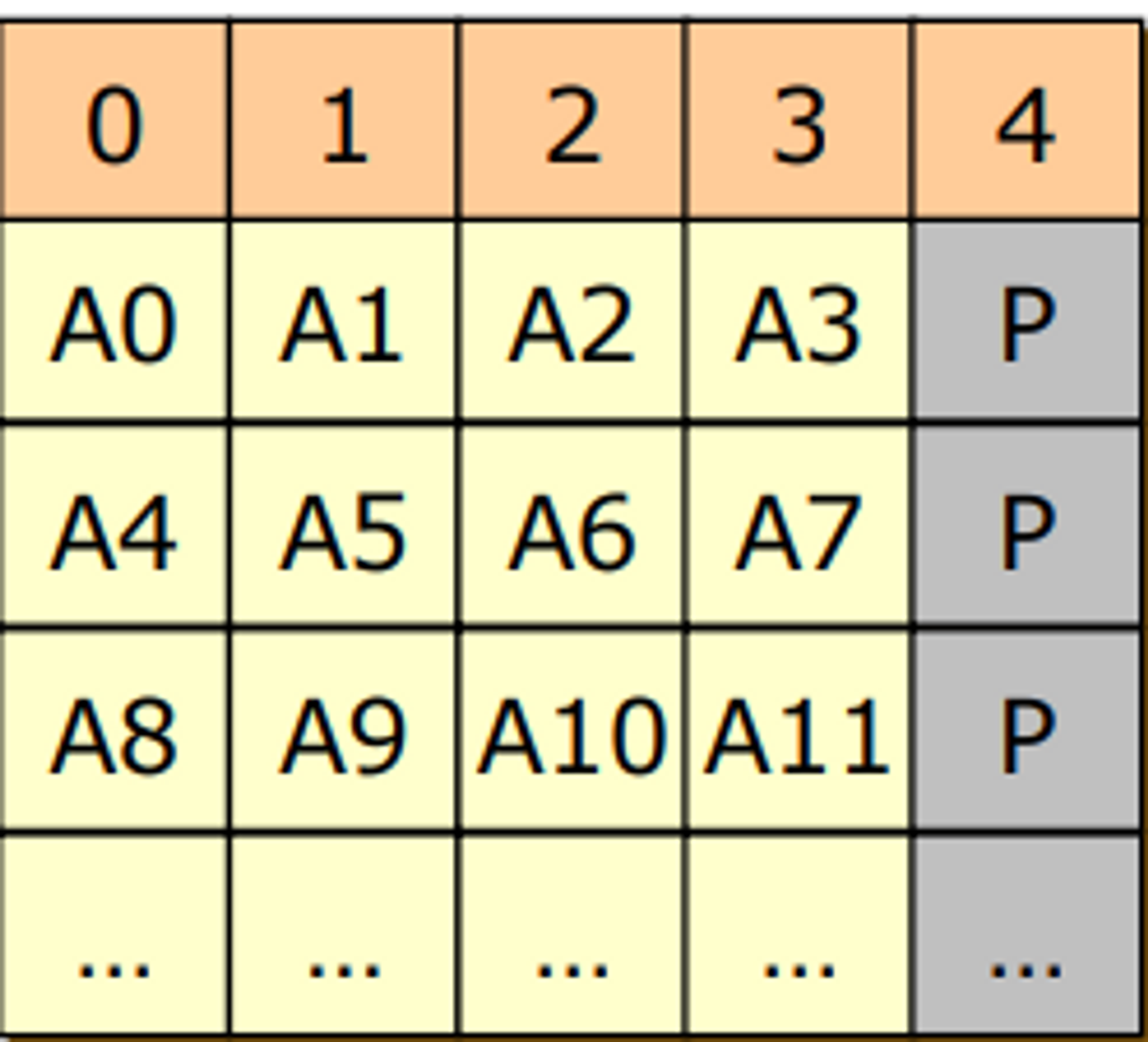
RAID 5
- block level로 data striping을 쓰고 신뢰성을 위해 parity를 사용하는데 이 parity도 striping 하는 것이다
- 한 디스크의 복구 코드를 몰아서 저장하면 A0가 변경이 되면 4에 있는 Parity도 바꾸어주어야 한다. 그러다보면 acsess 나 write되는 횟수가 4번 디스크에 몰리게 된다.
- 예를 들어 a0, a5, a10, a3이 변경되면 0-3 디스크는 각각 한 번씩만 접근이 되는데 4번 디스크는 4번이 접금이 된다 →
bottle neck
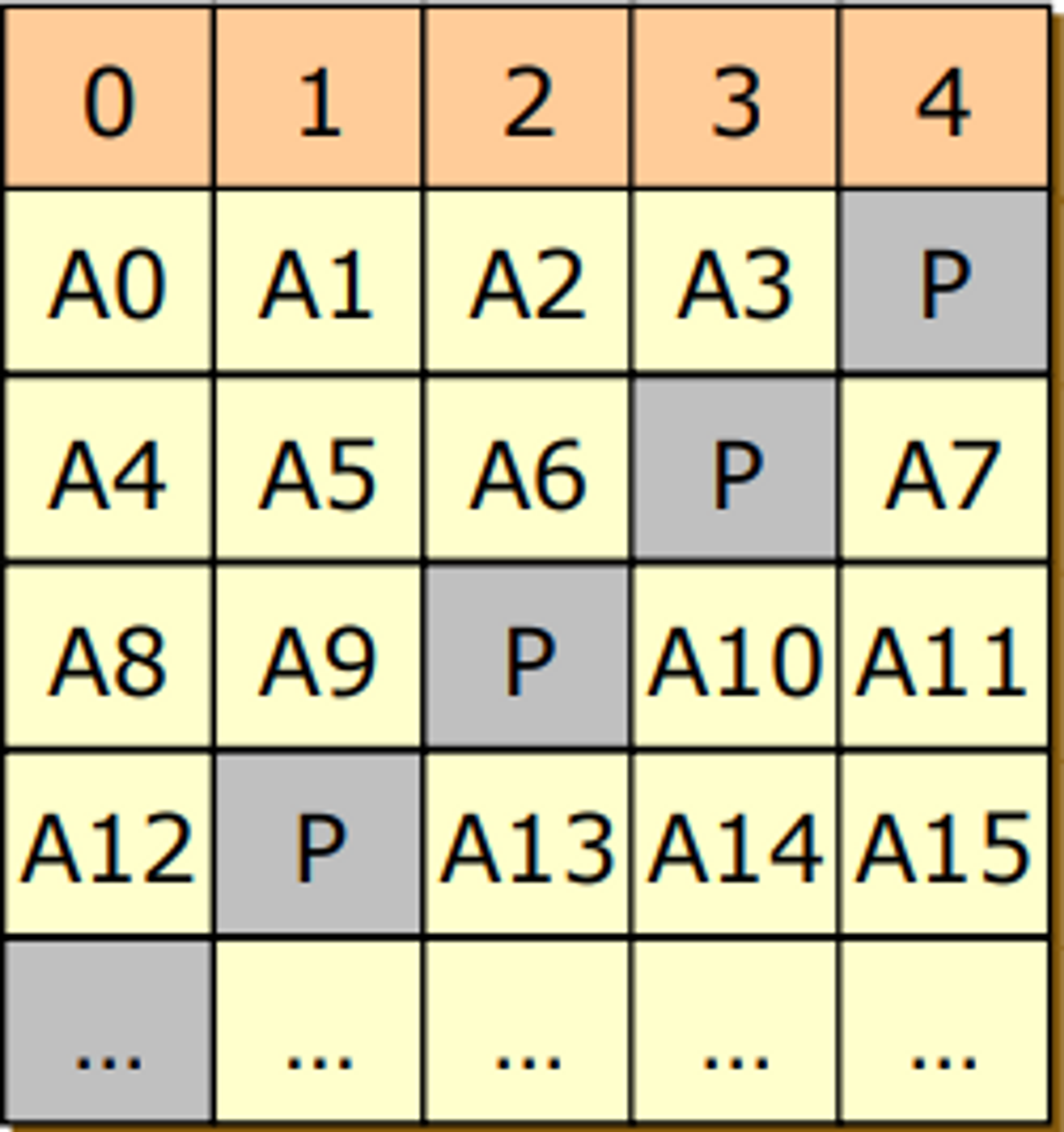
RAID 6
- parity bit를 2개를 사용 (RAID 5가 신뢰성이 좀 부족한뎅? 해서 나옴)
- error correcting code 사용
- disk의 오버헤드가 커진다.
그런데 디스크가 어처피 저렴하니까 하나 더 붙이는것 쯤이야 그렇게 비싸진 않다.
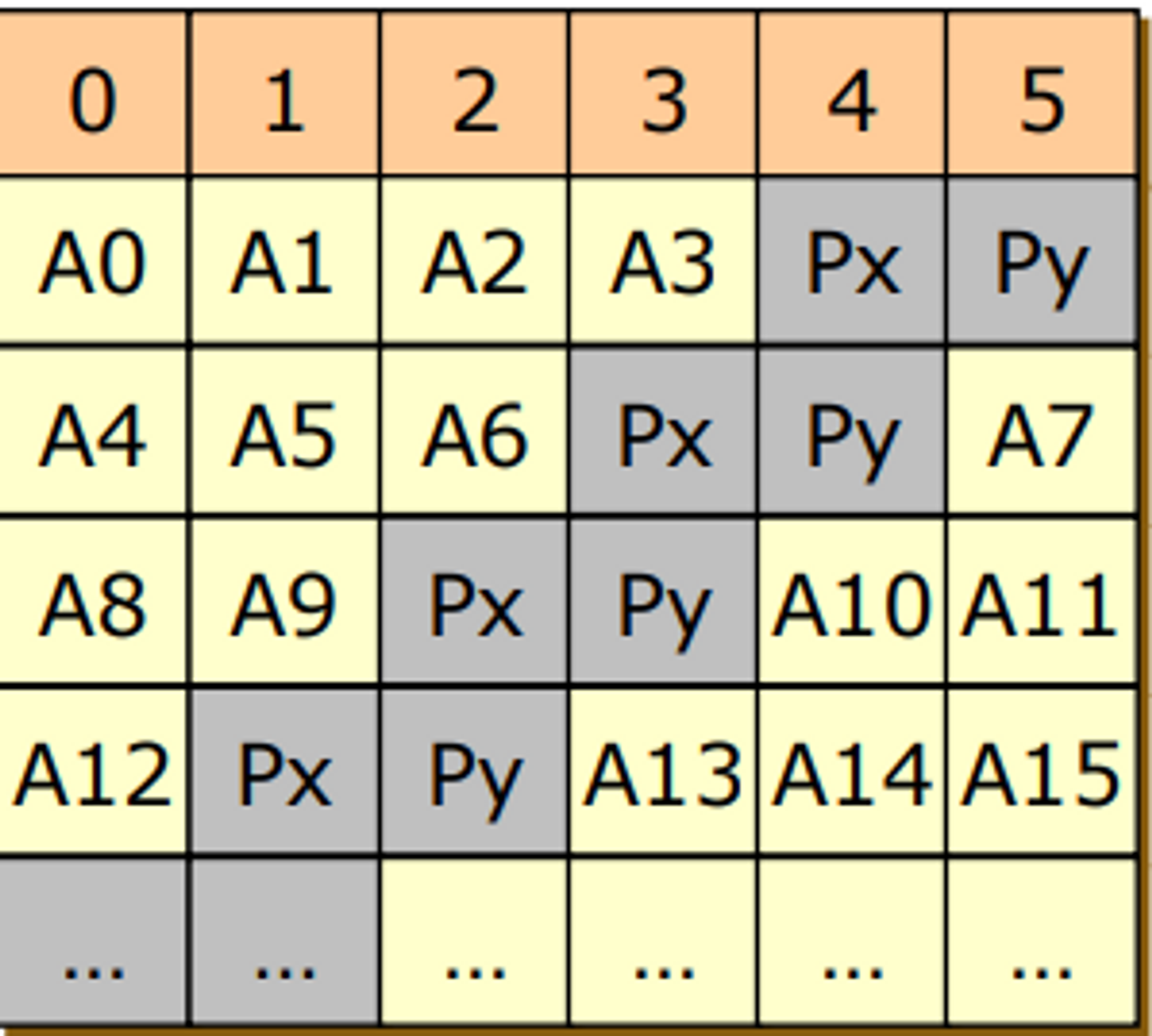
RAID 0+1
- RAID 0 : 신뢰성은 개나 줘버려 난 오직 성능만을 볼거야 → block striping 을 한덩어리 두고
- 신뢰성을 보장하기 위에 위에서 만든 한 덩어리를 복사 떠두면 되겠다.
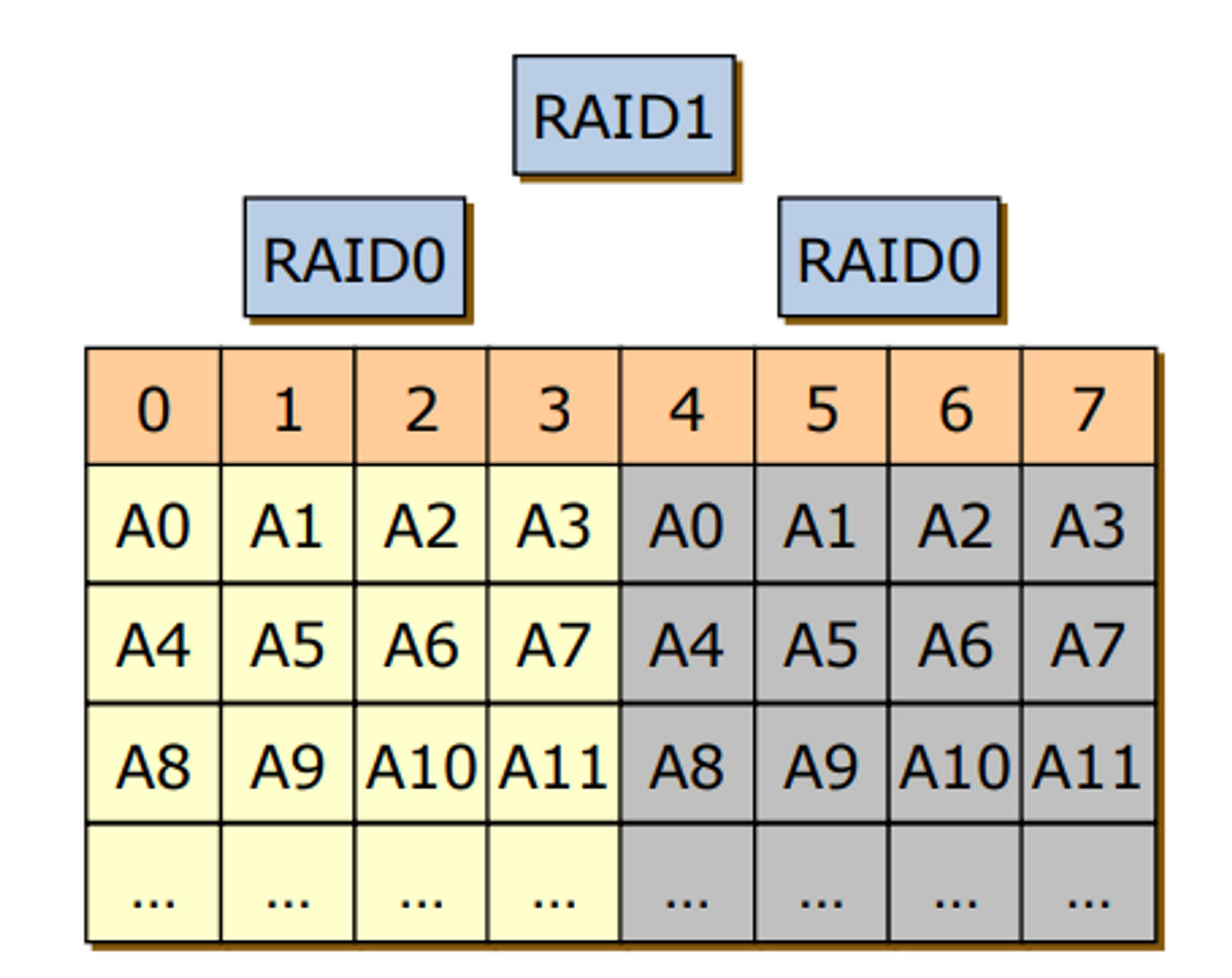
RAID 10 (1+0)
- RAID 1 으로 미러링 되어 있는 것들을 RAID0로 묶어버리자
- RAID 0+1 보다 성능이 좋다
→ 예를 들어 2번 디스크의 a6이 망가졌다. 그러면 6의 a6에 접근하면 되겠다. RAID1로 묶는 단위가 RAID0로 묶여있는 단위가 통째로 미러링이 된 것이다. RAID는 묶여 있는 디스크가 별개로 있다고 하더라도 하나의 디스크로 인식을 해서 0,1,3이 문제없이 동작할 수 있음에도 다 사용하지 않는다.
→ 반면 RAID10에서는 4번 디스크의 a6이 손상이 갔을 때, RAID1에서 보면 4번 디스크의 문제가 생겼을 때 복사본이 5번 디스크의 a6이다. 그러면 4번 디스크만 안 쓰면 된다.
→ 문제가 생겼을 때 사용불가능한 디스크의 비율이 차이가 난다.