OS 입장에서 어떻게 하면 사용자가 몰라도 잘 사용할 수 있을지 고민
File System Implementation
In-memory structure
실제 운영체제가 시작해서 해당 프로세스가 파일을 엑세스 할 때 필요한 구조
메모리에서 어떠한 것들이 이루어져서 파일 시스템의 성능이나 동작을 지원할 것인가에 대한 이야기
On-disk structure
전원이 꺼져도 세컨더리 스토리지에 데이터를 저장을 해야하는데 그것을 어떻게 하는가.
In-Memory Structure
특정 프로세스가 파일에 접근을 하기 위해 open을 수행을 하면 file descriptor가 반하게 되고 이것을 가지고 read write을 한다. 운체가 다른 것들은 abstraction해 두곤 file system 번호만 주고 이런거 할래 저런거 할래 할 수 있게 해줌
-
오픈을 할 때 경로가 포함되어 있는 파일 이름을 지정하면 디렉토리 구조에따라 디스크에 액세스 할 수 있다.
-
여러개의 프로세스들이 파일에 액세스할 때 어떻게 할거냐.
-
프로세스가 파일을 리드 라이트하는 주체, 실제 처리하는 것은 os.
-
프로세스들이 system call로 운영체제한테 부탁
-
운영체제 입장에서는 관리를 해야하는 상황이니까
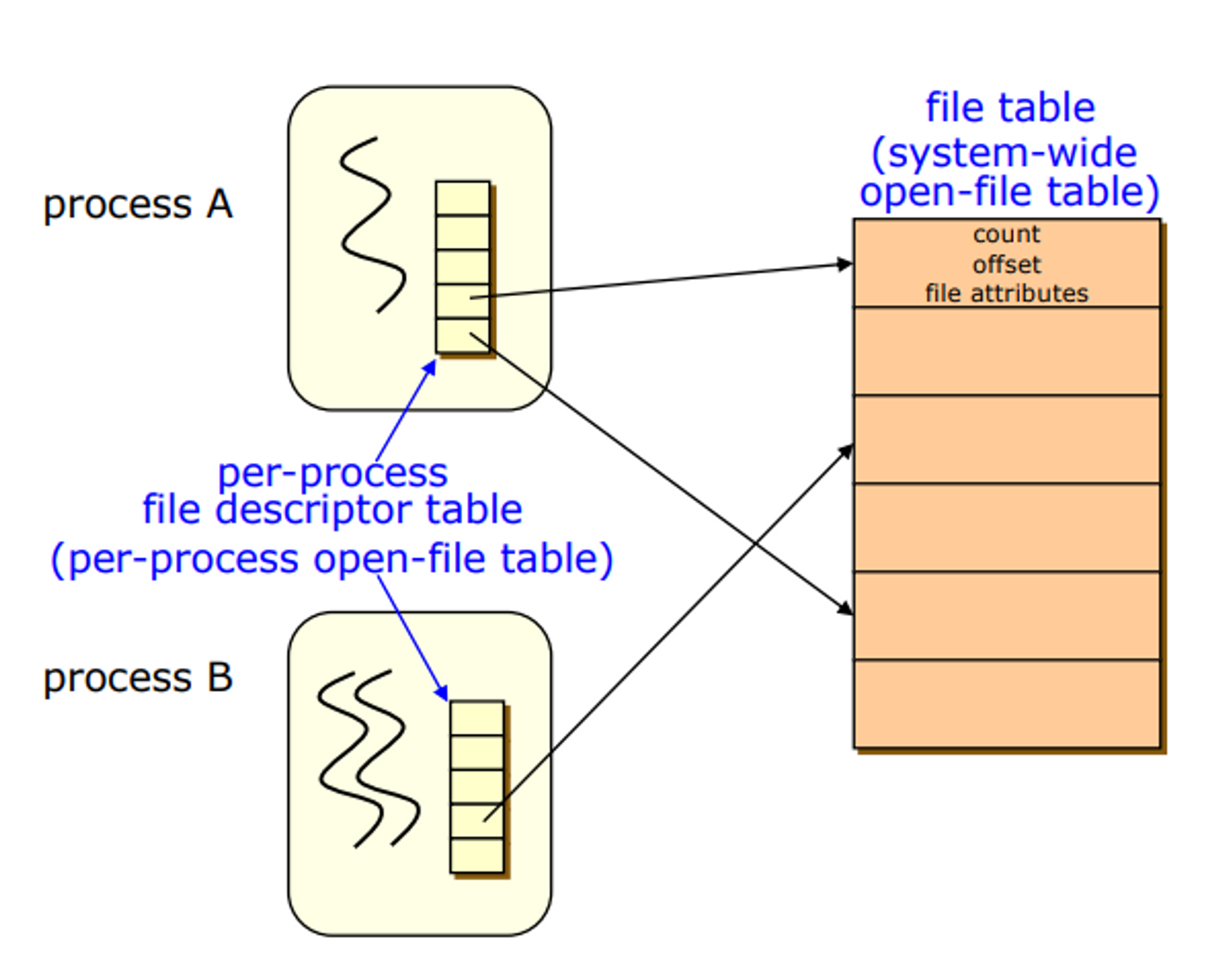
system-wide-open-file-table이라는 것을 유지한다. 내위에서 동작하고 있는 모든 프로세스들이 요청한 모든 파일에 대한 정보들을 통으로 갔고 있다. -
프로세스는 자신이 오픈한 파일에 대한
per-process open-file table을 유지한다,
→이 테이블 엔트리에서 요청한 파일은 커널의 system-wide-open-file -table에도 저장
-
프로세스 입장에서는 특정 file descriptor을 가지고 가르킬 수 있으니까 운체한테 내가 가르키고 있는 요쪽(ystem-wide-open-file -table) 정보를 가지고 있는 특정 파일에 대해 read/write 해주세요.
-
unix 기반으로 두고 있는 것들 : file 뿐만 아니라 다른 io 디바이스들도 descriptor라는 개념을 써서 관리를 한다.
-
고급 객체 프로그래밍하면 기본적으로 파일 3개를 오픈한다.
→ stasdarf input & output & error
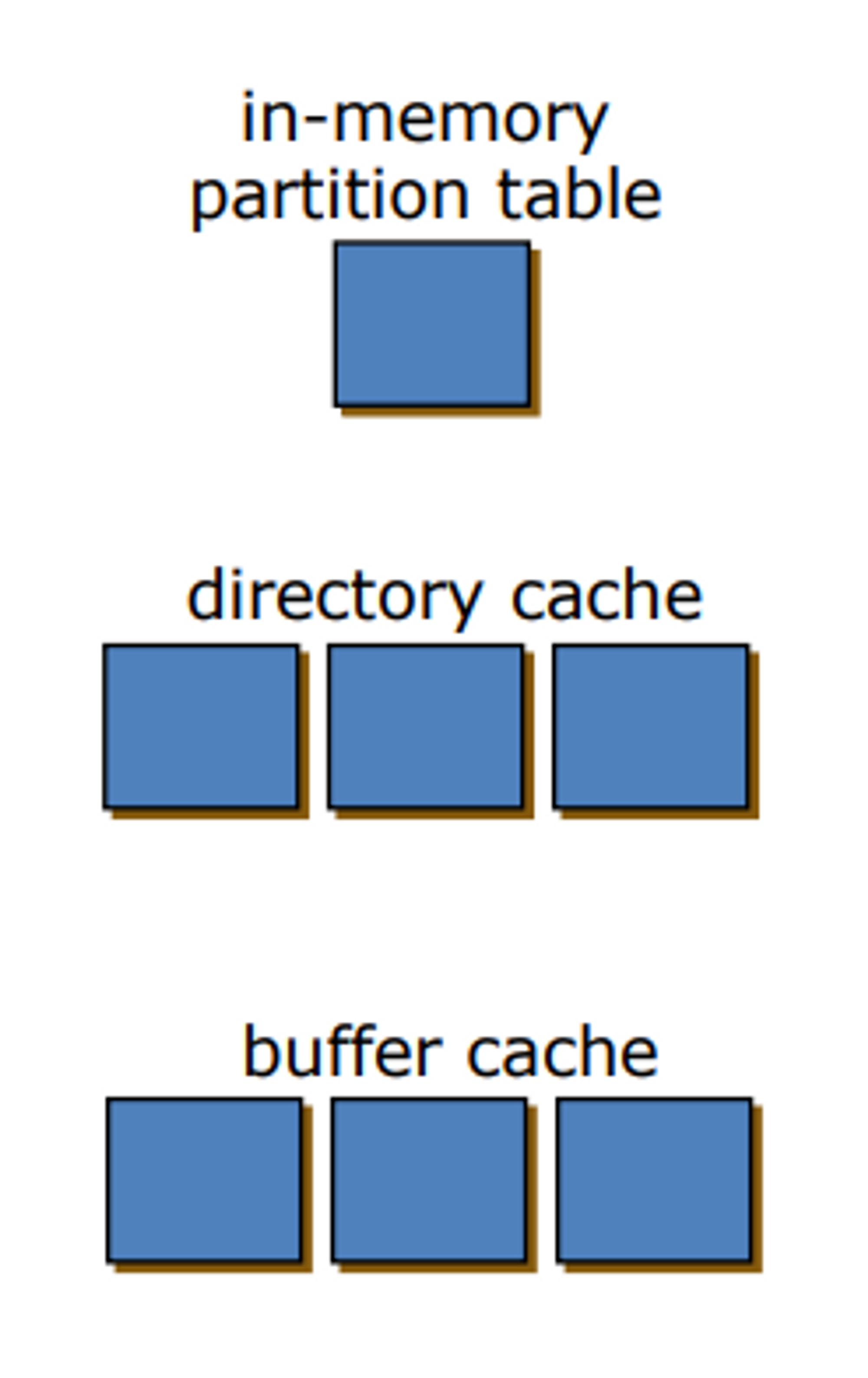
- 디스크에 있는 내용들인데 디스크에 자주 액세스하면 bottle neck이어서 성능이 안 좋아 지니까 자주 쓰는 것을 메모리에 올려두고 쓰면 빨라진다.
in-memory partition table,directory cach,buffer cache통칭하여 Buffer Cache 라고 한다
Virtual File System
요즘 운영체제들은 파일 스스템 자체가 많다 보니까 이것을 따로 관리하기는 힘들다. 호환성 문제도 있고 그래서 요즘은 공통적인 것을 하나로 묶어서 관리한다. 다른 부분들만 따로 개발을 한다.
- 어쩌면 약간 상속의 개념
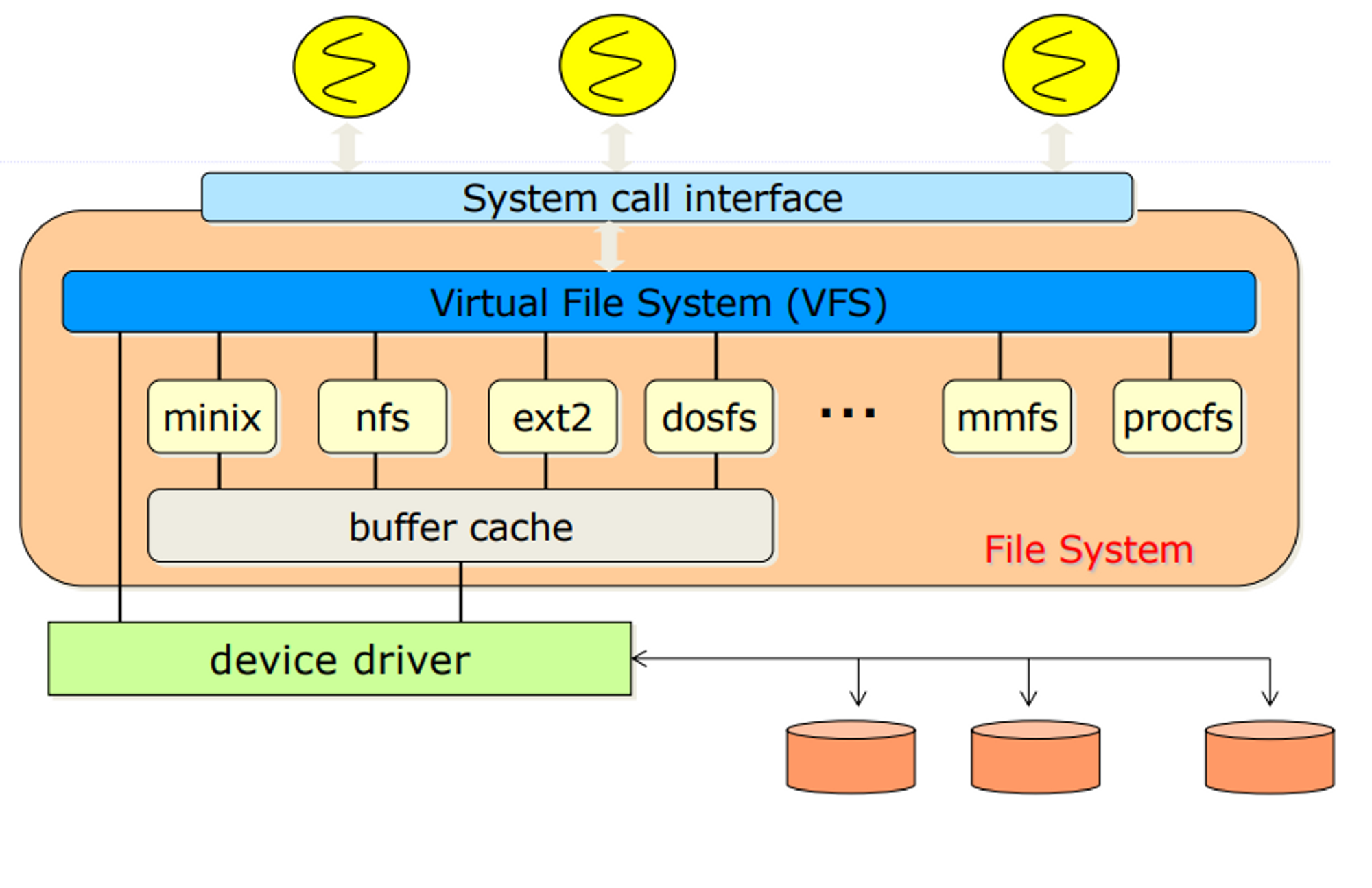
Layered File System
- virtual file system이랑 일맥상통하는 이야기
- 나누어서 개발하면 dependency가 떨어지지 좋다

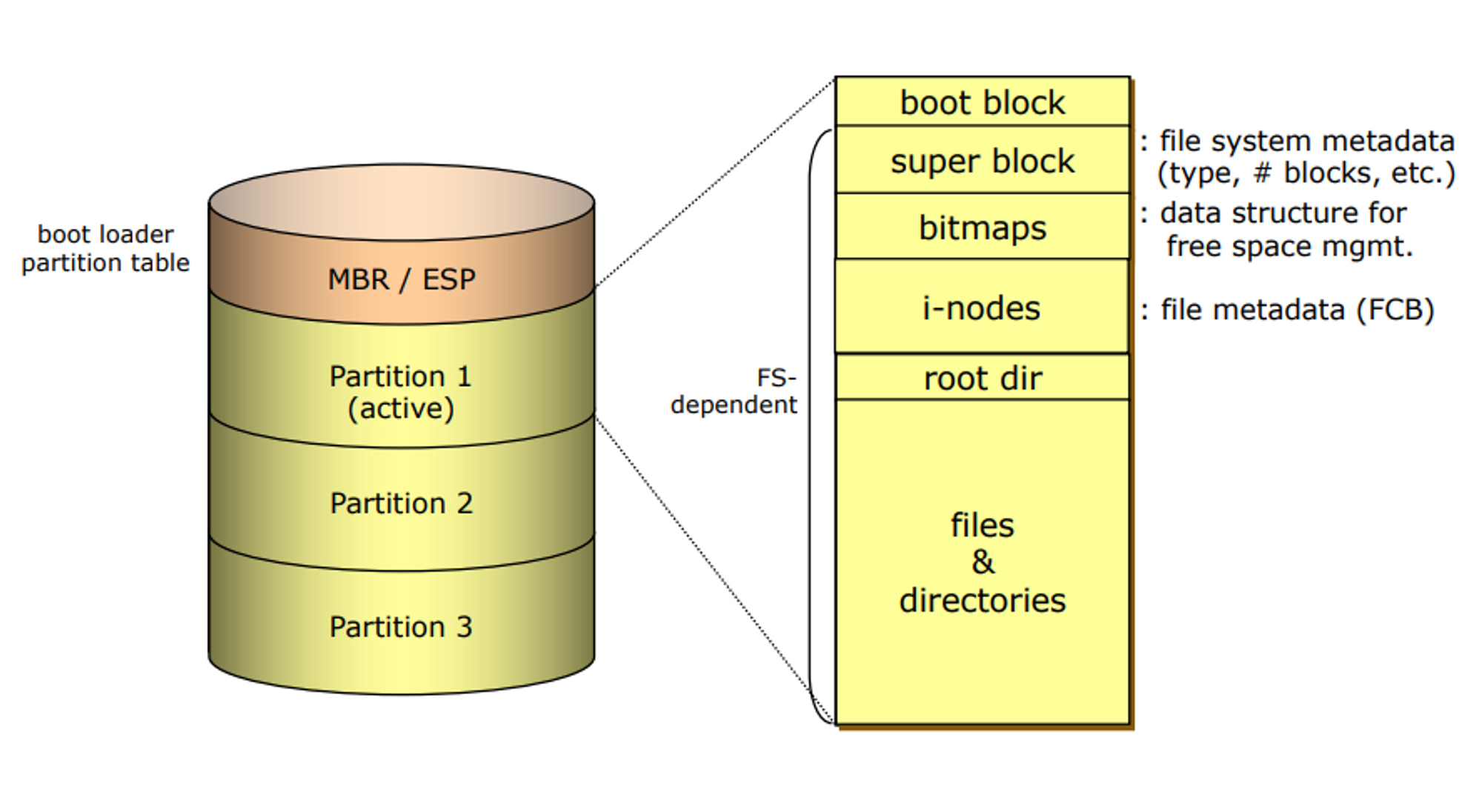
On-Disk Structure
- 하드디스크 하나가 있으면 메인 하드디스크 sector 0번에 마스터 부트 레코드 라고 하는 것이 있다.
- 마스터 부트 레코드에는 부트 로더가 저장이 된다.
→ MBR
- 로드할 운영체제가 하나가 아니라 여러개일 수 있다. 파티션을 나누어서
부트로더에서는 어떤 파티션에 설치된 운영체제로 실제 부팅을 할 것인가를 선택할 수 있다.
- 만약 디폴트 파티션으로 부팅되는 것이 1번이라면
- 오른쪽 표처럼 파일 시스템이 구성되어 있다.
- 조립컴으로 사서 포맷을 ssd에 아무것도 들어있지 않는 상태가 된다. 하지만 포맷을 한 이후에 제대로 파일을 저장하고 읽고 쓰고 하려면 오는쪽 아래와 같은 기본 구조는 만들어주어야 한다.
- 포맷하는데 시간이 오래 걸리는 것은 이 구조를 만들기 때문
1. boot block
부팅에 필요한 것들을 저장하는 블록, 운영체제가 저장
- 만약에 1번에만 윈도우 있고 2번 파티션은 데이터 저장용도라면 여기에는 boot block에 없는 상태로 포맷
→ boot sector in windows
2. super bock
: 파일 시스템의 정체에 대한 정보를 가짐
→ 어떤 파일 시스템이고 등등
→ 실제 400GB 짜리 디스크를 가져 다가 쓰면 페이징하는 것 처럼 블락이라는 단위러 쪼개서 쓴다.
→ master file sector in windows
3. bitmaps
: 존재하는 디스크 블락들이 사용중인지, 400gb 하드디스크이면 100mb 개의 블락들이 존재 이 블락들 중에 몇번째 블락이 사용 중인지 아닌지 저장.
- 사용중이지 않은 블락을 관리하기 위해 존재
- bitmap block의 크기 계산
400gb 하드 디스크가 block수가 1메가. bitmap 블락은 사용중인지 아닌지 1bit만 필요하니 100bit가 필요하다.
4. i-nodes
: 하나하나 파일에 대한 정보를 저장
→ 이름, 언제 생성 변경되었는지, 어넺 액세스가 되었는지, 로지컬 경로는 어떻게 되는 지 등등 → 이런 정보를 FCB(File contrl block)이라고 한다.
→ FCB는 보톤 4kb를 사용.
→ file별로 하나씩 필요
5. root dir
: 스페셜한 파일이고, 이것을 사용해서 hierachy 한 디텍토리 구조를 만들 수 있다.
→ windos
6. files $ diresctories
file을 새로 저장을 하여면 비어는 블럭을 찾아야 한다.
→ 연속적으로 배치를 하면 좋을 것이더
→ 그러면 파일이 생겼다 없어졌다 반복을 하면서 hole이 생긴다. 파편화 발생
→ a랑b 파일이 있을 때 붙어 있는데 갑자기 a파일이 커져야 하는 순간이 생김. a 뒤에 더 써야 하는데 b가 바로 붙어 있어서 연속적으로 배치를 못하니까 더 큰 빈공간을 쭈욱 써야함
→ 하드디스크처럼 데이터가 가변적으로 바뀌는 것에 쓰는 것이 그다지 좋은 상황은 아님
→ 연속적으로 쓰기에 좋은 상황? 데이터가 바뀌지 않는 상황
- CD, DVD, Bluray
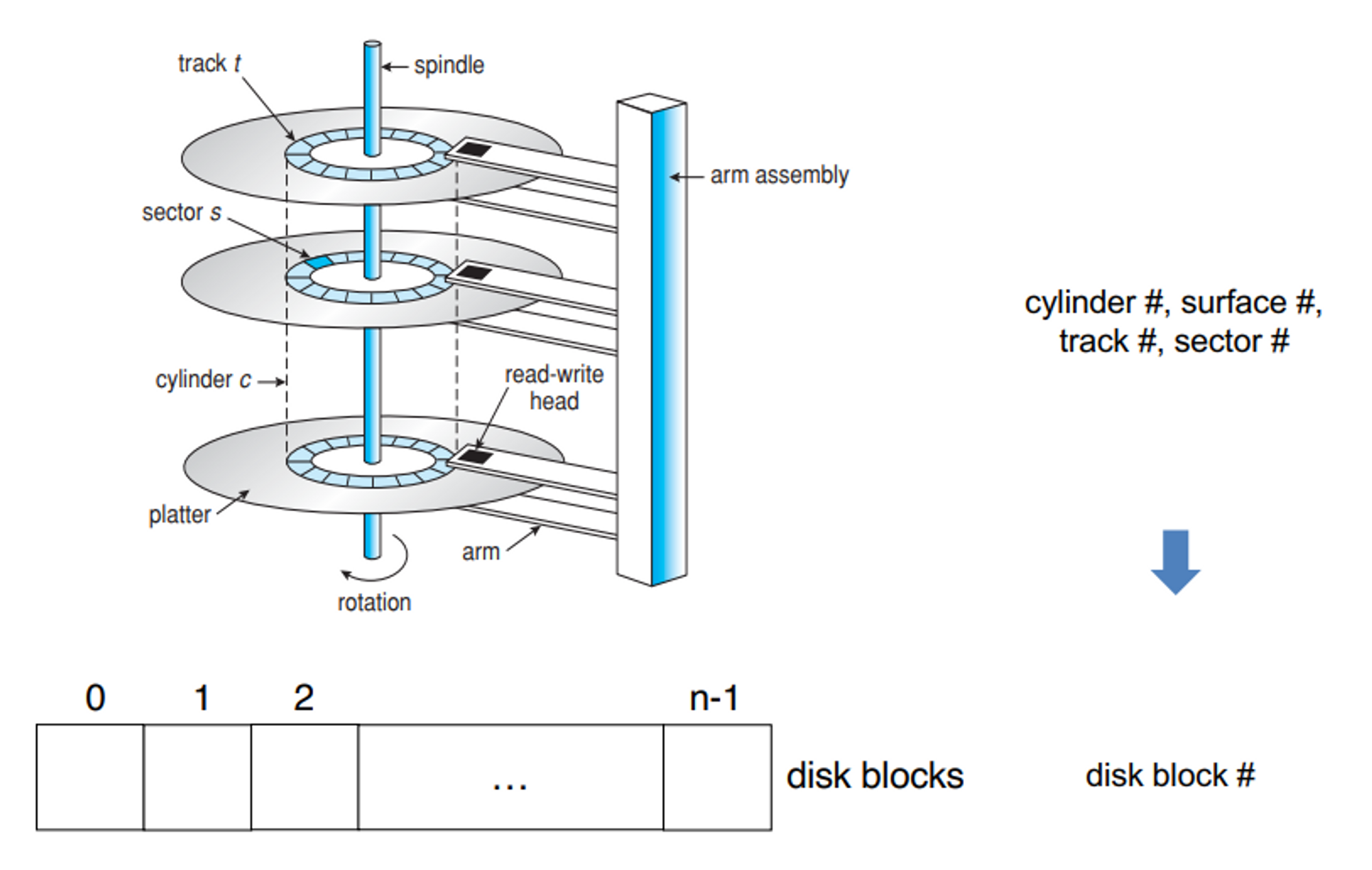
Disk Block
- 섹터 크기 512byte
- 운영체제 입장에서는 512로 하면 오버헤드가 너무 크다
- 그래서 섹터 단위를 쓰지 않고 블락이라는 단위 사용 4kb
- 디스크 block 0번은 하드 디스크 제일 위에 있는 플랫터에 가장 밖에 있는 섹터부떠 쓰여진다. 하나의 블럭이 4kb, 하나의 섹터는 512byte=0.5kb → 8개를 동그랗게 돌아가면서 쓴다.
- 다음 블럭은 같은 실린더 내에 8개의 섹터들을 묶어서 write을 함
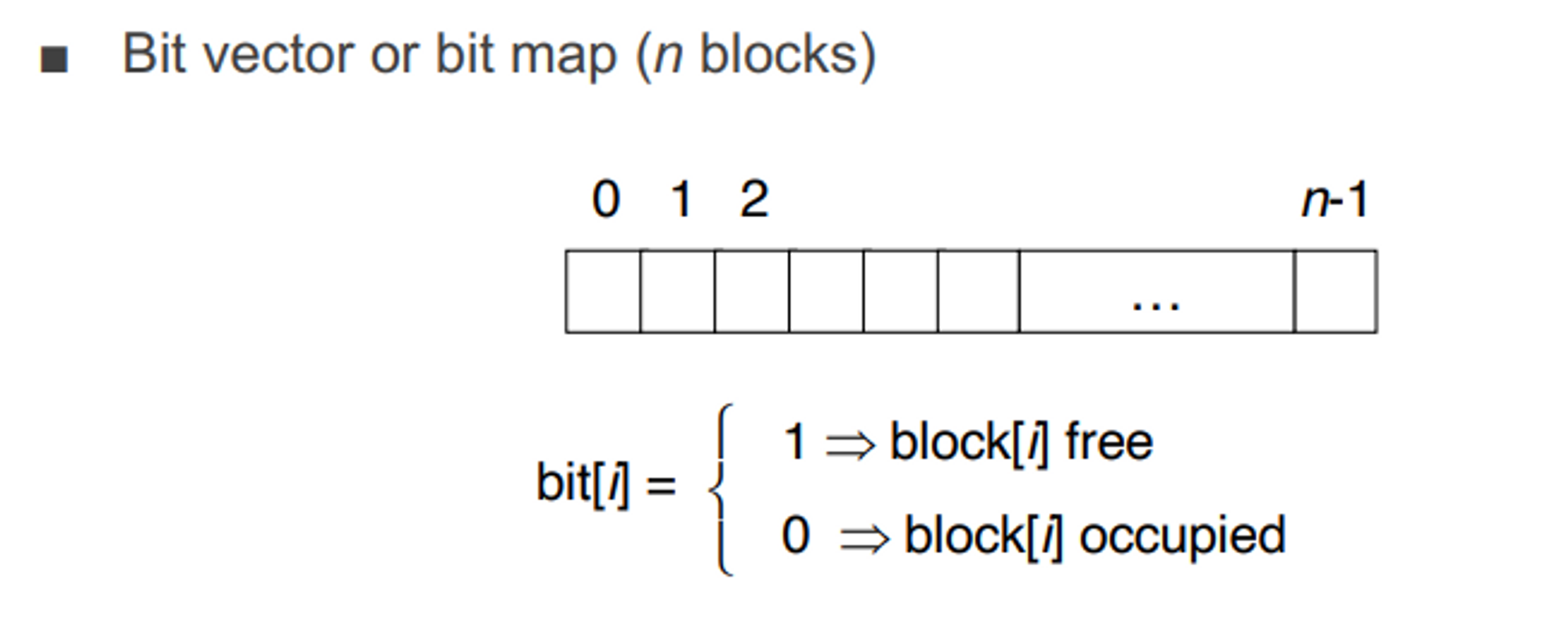
Free-Space Management
- 1이면 free, 0이면 사용하고 있는 것
- 비트맵 전체 크기 = 전체 디스크 크기 / 블락 사이즈
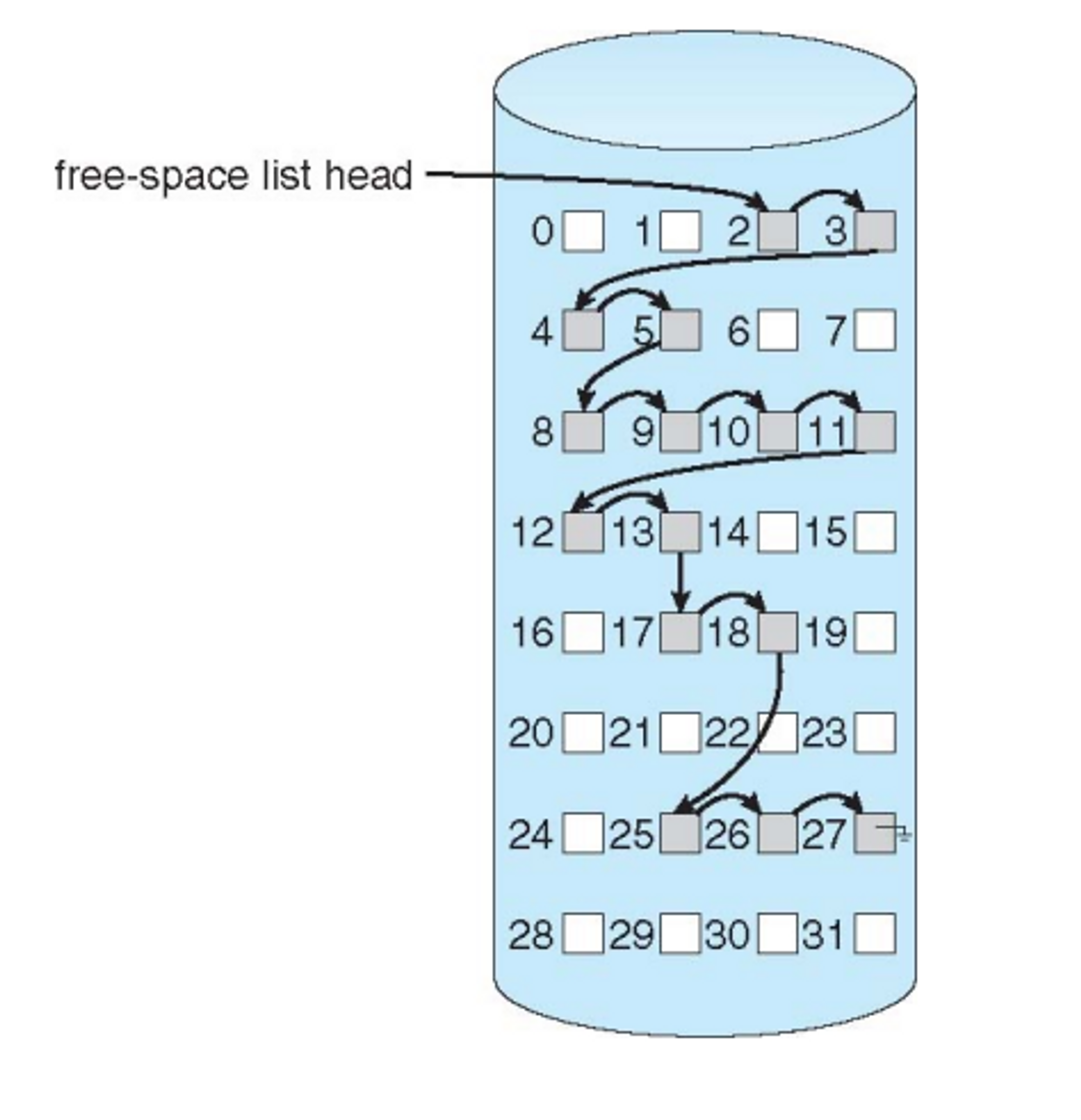
- 비트맵 안에 비어있는 블락들을 관리를 하는데 contiguous 안 좋음
- linked list
- grouping
- counting
- space maps
A Typical File Control Block
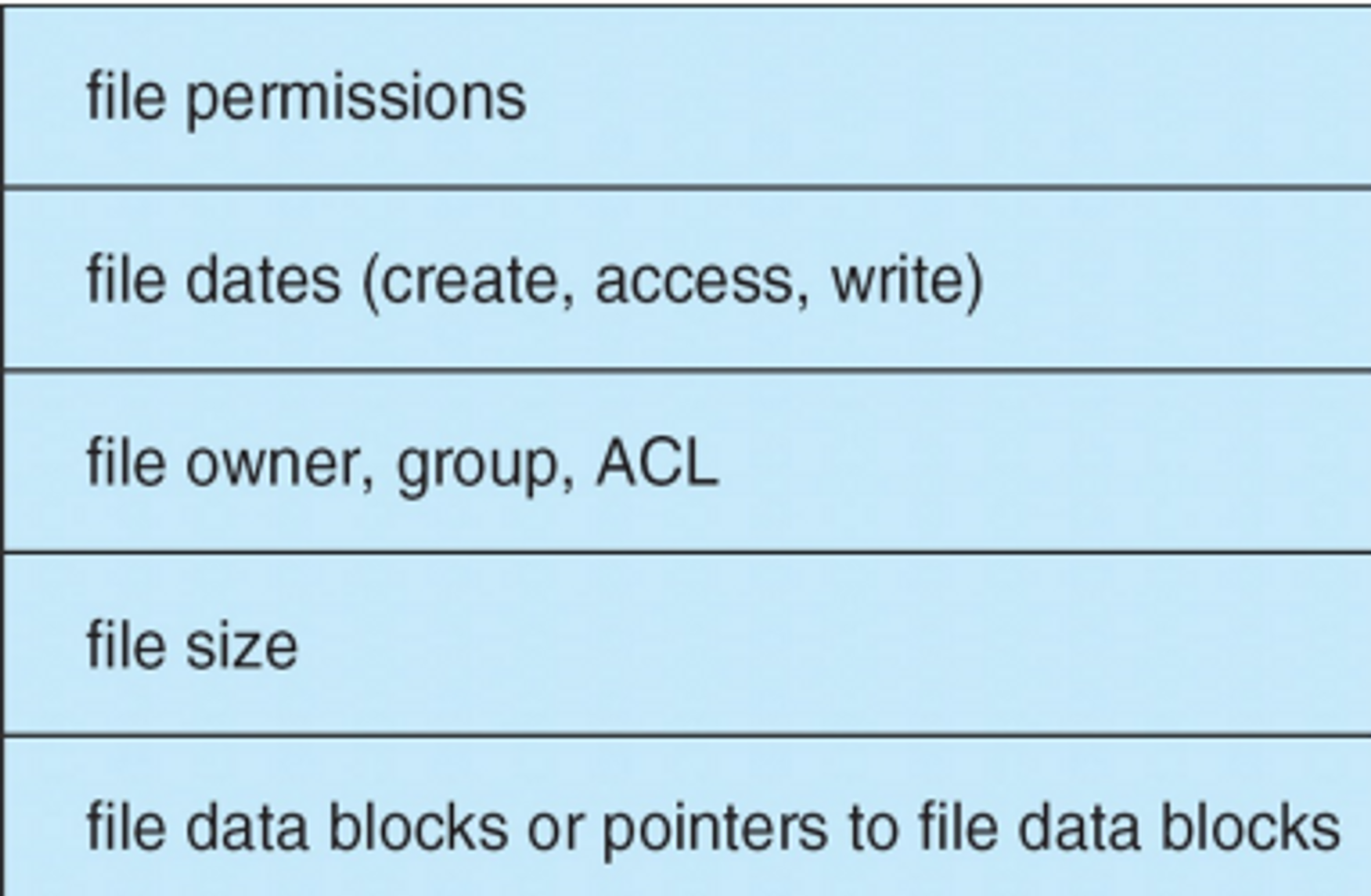
Directory Implementation
The location of metadata (FCB)
- 위치에 대한 정보, 디텍토리에 어떤 파일이 있는지에 대한 정보
- 디텍토리 하나가 생기면 크게 3가지 방법으로 구현 가능
-
file 이름
: file이름, file constol block 을 다 때려 넣는 것특정 디렉토리 안에 들어가 있는 다른 파일들에 대한 모든 파일 컨트롤 블락을 다 때려 넣는 방법
-
in the separate
: file 이름이 그에 해당하는 FCB를 포인팅하는 거- 실제로 디렉토리 안에는 파일이랑 포인터, 파일이랑 포인터 만 존재
→ 유닉스가 사용
-
A hybrid approach
→ 두 개를 짬뽕한 것
- 중요한 것들은 FCB에 저장을 하고 file spedific한 내용들은 포인터로 가르켜 저장
→ 윈도우가 사용 NTFS
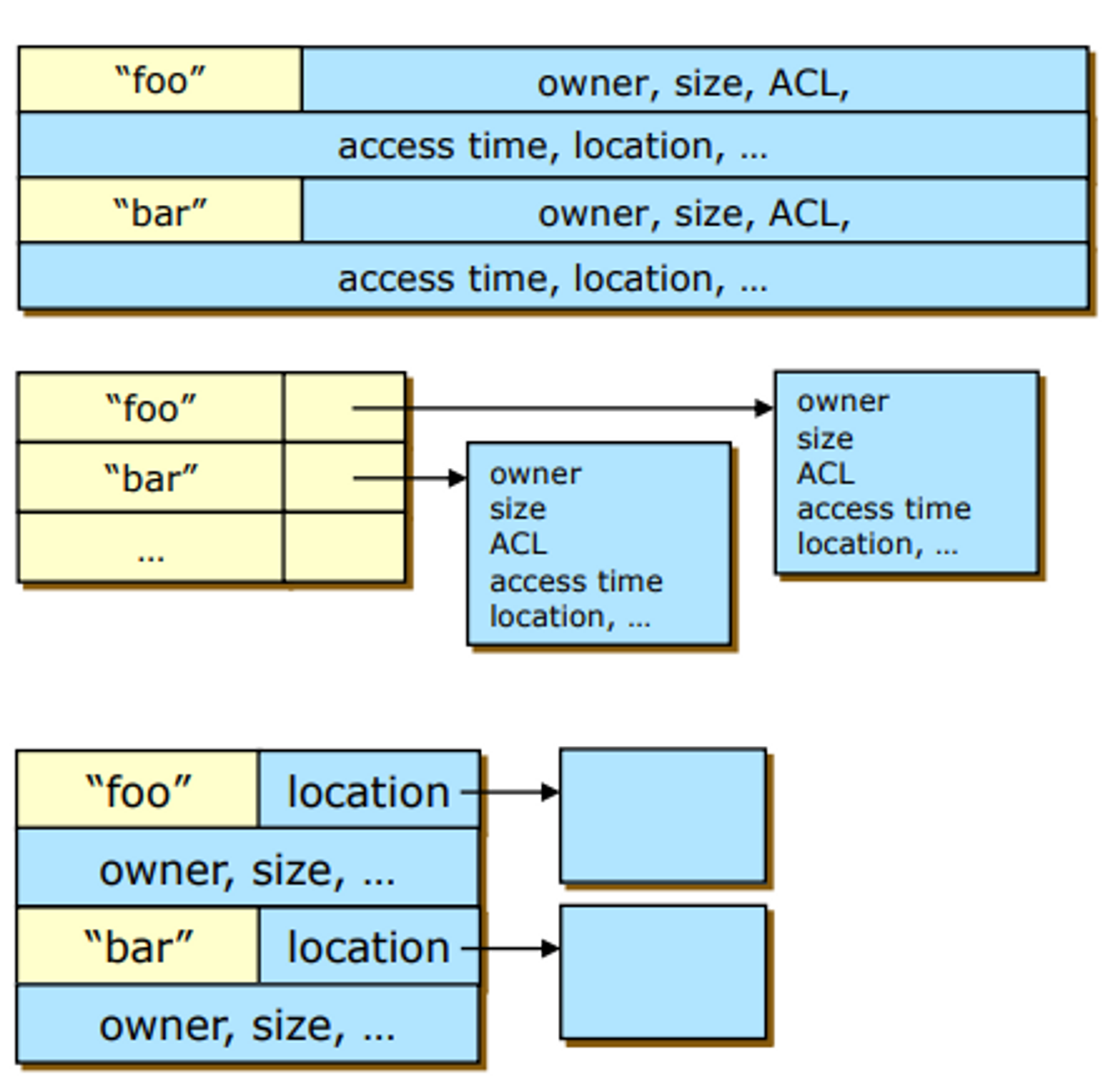
Allocation Methods
파일 하나가 블럭 하나를 사용하는 경우는 거의 없다 . 어떻게 관리를 하고 디스크에 어떻게 배치를 할 것 인가?
Contiguous Allocation
✅ 장점
- file에 대한 위치 정보를 구성힐 때 파일 이름. 시작위치랑 길이 정보만 가지면 됨
- 디스크는 한 번에 많이 읽어올수록 spatial locality 때문에 성능이 좋아지는데 근처에 있으니까 쫙 읽으면 되니 좋다 → 디스크 조각 모음: 관련되어 있는 것들끼리 모아 주는 기능
- 데이터가 변하지 않는 매체에서는 아주 우수 → cdRom
✅ 단점
- fragmantation
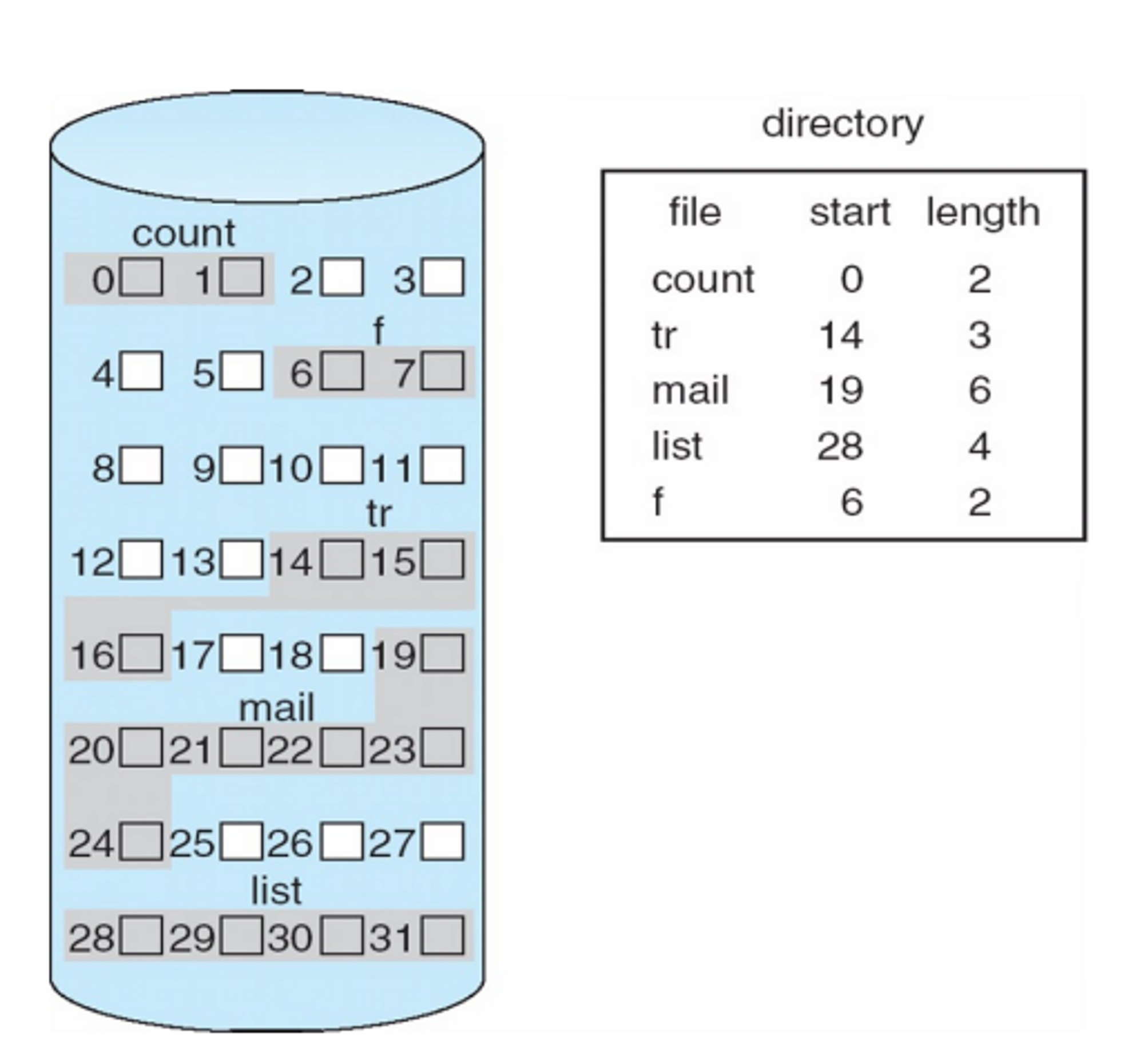
Linked Allocation
block에다가 포인터를 두고 마지막 블록에는 null 을 넣음
✅ 장점
- externel fragmantation이 없음
- file 크기가 가변적이어도 제약잉 없다. 비어있는 곳 링크해서 쓰면 된다
✅ 단점
- spatial locality를 활용한 효율성이 떨어짐
→ seek time이 길어지게 되고 sequencial access가 불가능
- 포인터가 깨지면 파일 전체가 날아감 → 신뢰성의 문제
→ 약간의 해결)
- 디스크 블럭은 디스크 그래도 있ㄱ 별도의 특정 파일에다가 포인터만 막 저장을 해두는 것. 포인터만 잔뜩 들어있는 블락이 있고 실제 블락에다가 포인터 정보를 넣지 않고 따로 빼서 한 블락에 몰아 넣는다. 디스크 스케쥴링도 더 편하게 할 수 있다.
- 블락에 포인터 정보를 때려 넣은 것을 여러개 만들어 신뢰성 문제 해결
File-Allocation Table (FAT)
- 포인터를 모아 둔 블락 자체를 FAT라고 부른다
- 이 이름이 곧 파일 시스템 이름
- pointer allocation했을 때 root directoy 의 포인터 정보가 날라가면 다 날라간다. → 신뢰성 하락 이것을 해결하기 위해 나옴
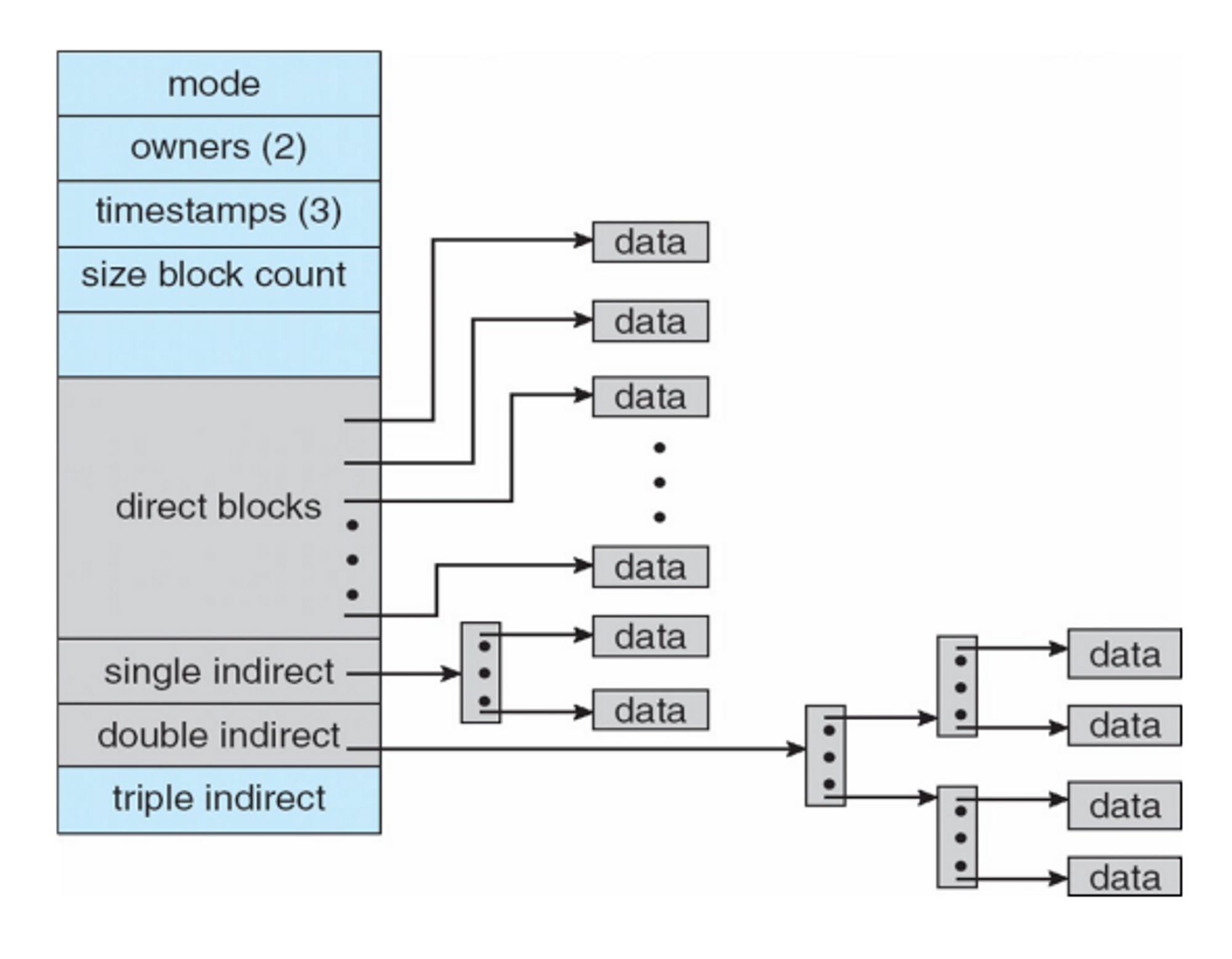
Indexed Allocation
: 개선된 형태의 링크드 Allocationd을 사용하는 것
-
포인터를 두지말고 말고 블락 한테 인덱스를 준 다음에 인덱스로 관리를 하는 방법
-
ramdom access도 index값을 쭈욱 읽어서 해주면 되니 가능
-
FAT에서는 tabel이 날라가면 file system 전체가 날라갔는데 인덱스만 날아가면 특정 파일만 날아가게 된다 그래서 안전하다
-
인덱스를 저장하고 있는 block을 줄여서 i-node라고 부름
-
각 블락엔 인덱스를 부여하고 특정 파일이 이러한 인덱스를 분산되어 저장이 되어 있어
-
400mb짜리 파일을 저장해야 할 때 block이 100kb만큼 필요 index 정수가 32bit / i-node는 4kb이니 다 못 넣는다. 그래서 다 넣을 수 있는 방법이 필요
-
file 크기가 12개의 블락의 크기를 합친 것을 벗어나면 처음에는 single indirect 블럭으로 가면 새로운 i node를 만남. 이건 통으로 아이노드로 쓸 수 있다. 1000개 만큼의 블락을 가질 수 있는 inode.
-
만약에 이걸로도 (12+1000)에서도 부족하면 double indirect 블락으로 간다.
i-node로 가고, 각각의 inode 엔트리가 또 inode로 간다. 거기서 실제로 블락이 인덱스 값들을 가짐. (1000*1000) ⇒ 4GB
-
Triple indirect → 4TB 근데 안씀
-
indirect block은 왜 12개까지만 했을 까?
→ 통계적으로 대부분의 파일들이 50kb(12개 48kb)를 넘지 않더라
⇒ unix, linux, ntfs
inode
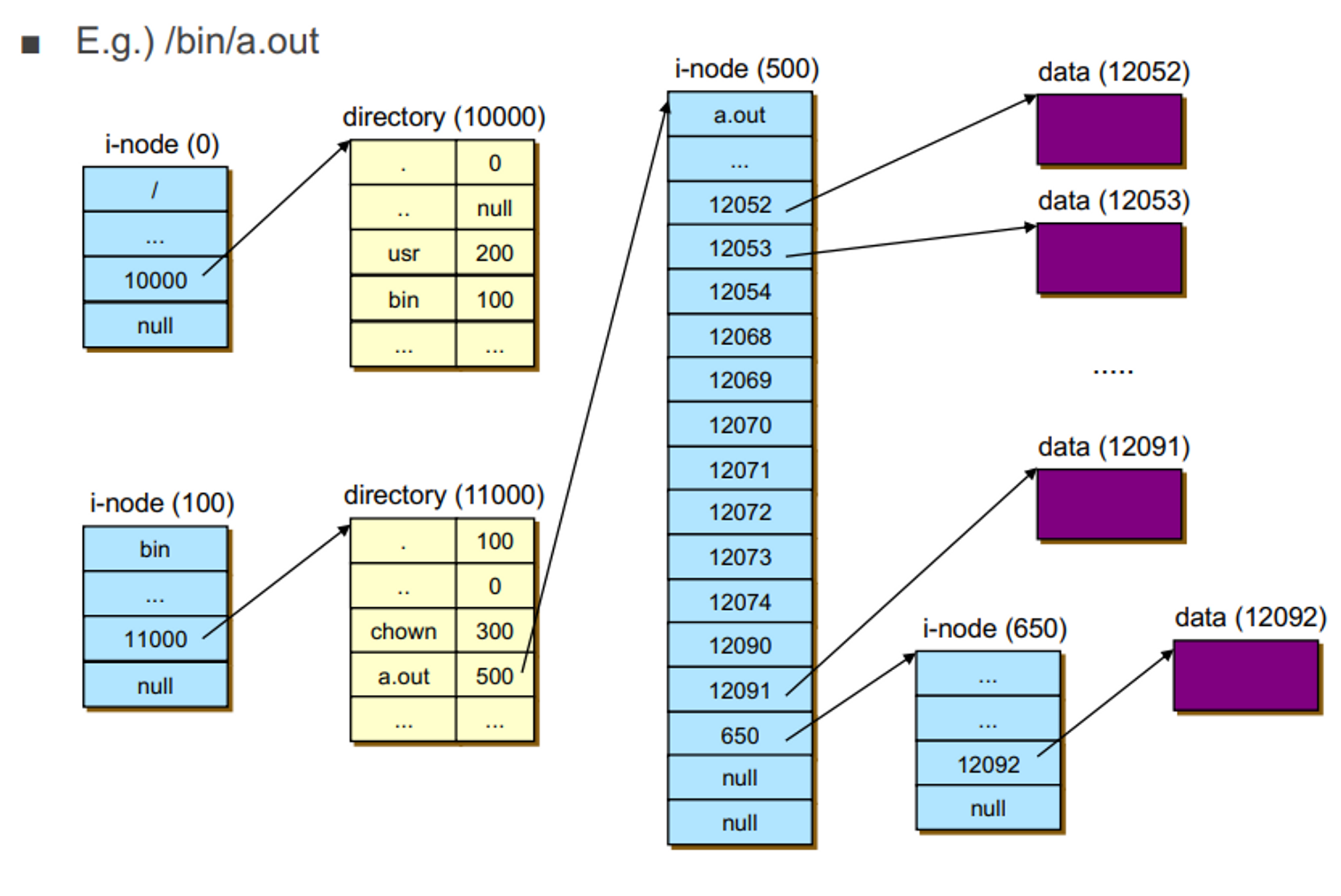
예시) root에서 bin의 a.out에 접근을 하고 싶음
→ root에 inode에 디렉토리 정보가 10000
→ 따라 갔더니 빈이 100에 있더라
→ 따라 가서 bin inode를 봤더니 거기 안에 있는 리스트가 11000에 있더라
→11000에 방문, a,out이 500번 따라가면
→ 12개 까지만 하나씩 근데 이걸로 부족하면 single indirect block을 사용 inode 튀어 나옴
- a.out을 여러명의 사용자가 사용한다 했을 때
→ 버퍼 캐싱을 하지 않으면 1, 2, 3번 사용자가 전부 다 이 과정을 겪어야 하니 버퍼링을 해줘야 한다.
→ 버퍼링(캐싱) 하고 있을 때 디렉토리 정보가 바뀌게 되면 캐시는 메모리 위에 있는데 메모리에 있는 정보랑 디스크의 consistent를 어케 유지?
⇒ cpu cache와 디스크의 일관성 : write-through, write-back을 수행
근데 write-through하면 너무 느려서 디스크의 성능이 떨어지니 write-back을 수행. 근데 비정상적인 크래쉬나 비정상적인 종료가되면 캐시랑 정보가 달라질 수 있는데 이것을 inconsistent하다라고 함.
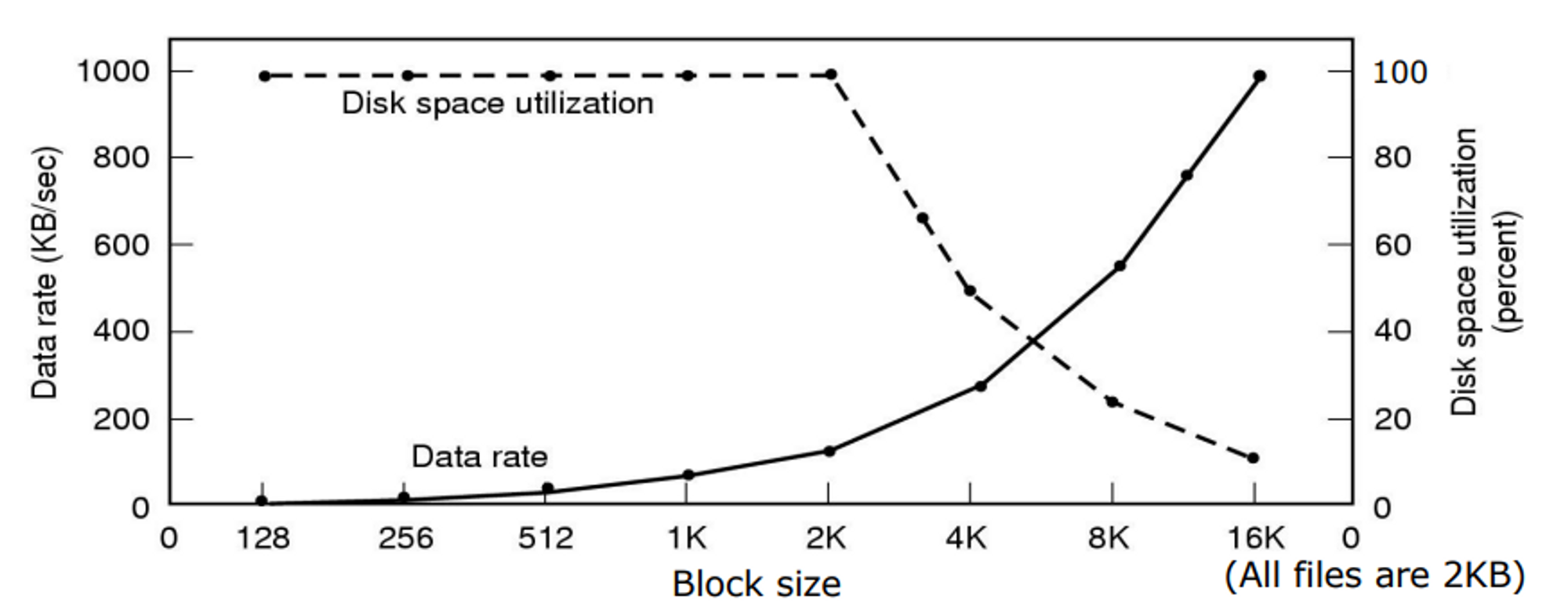
Block Size Performance vs. Efficiency
Block size
- x축 : block size
- 오른쪽 y축 : 공간 효율성
- 연구한 분들이 4kb가 적당하다고 말함.
Read-Ahead
spatial locality 특성을 적극활용해서 액세스하는 부분 근처에 있는 데이터도 한 번에 다 읽어오면 근처에 있는 것도 또 쓰일 것이다.
- 미리 읽어서 버퍼 캐시에 다 때려 넣으면 성능은 좋아지겠지
- 하드 디스크는 암시크가 크기 때문에 한 번 갈 때 많이 읽러오는 것이 좋음
Caching Writes
- write- back : inconsistent한 상황 발생
→ Reliability 떨어짐
Reliability
- inconsistent 한 상황 발생 왜? 성능 높이겠다고 버퍼 캐시 써서 → 이런 상황을 대비해서 scandisk, fsck 이런게 있는데 커버를 할수고 못할수고 있다
Log Structured File Systems
→ 조금 더 신뢰성을 업그레이드
Journaling file systems
- 디스크에 log를 씀, log 데이터는 작자나 그래서 나중에 정상적으로 캐시에 있는거가 디스크에 써지면 log를 디스크에서 지움
- 만약에 inconsistent한 상황에서 재부팅이 되면 로그가 저장되어 있는 파트를 봐.
- 비어 있다 → 제대로 됐군
- 남아 있다 → 제대로 안됨
⇒ log 가지고 복구를 시작
- inconsistent한 것은 캐시에는 써지는데 디스크에 안써지는 경우
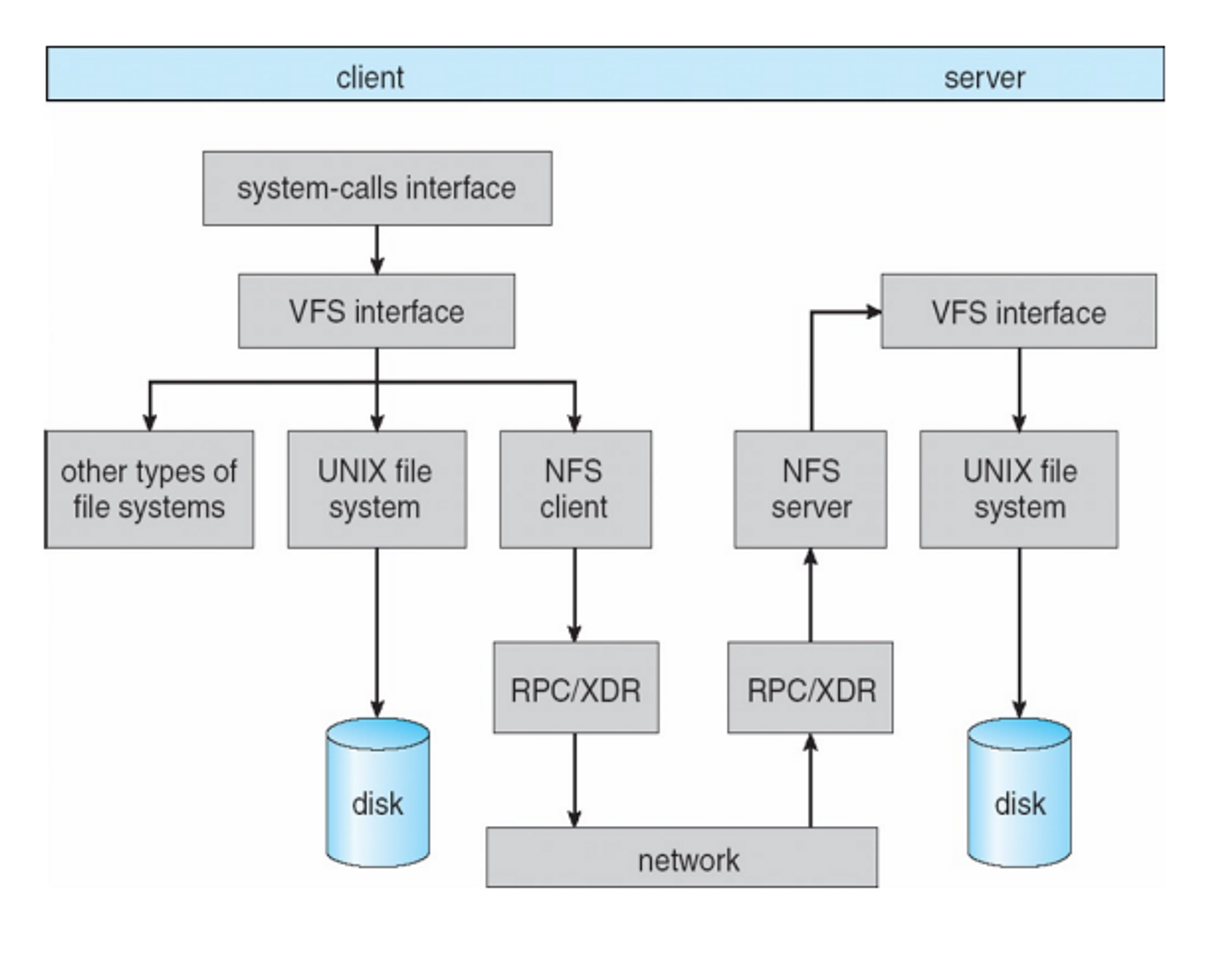
Remote File Systems
원격에 있는 디스크를 내 컴퓨터에 붙어 있는 것처럼 쓰게 하는 것
→ Network File Systems (NFS)