introduction
NLP에서도 pre-trained된 모델을 사용하는 기법은 있지만, pre-train에서 단방향의 architecture만 사용할 수 있다는 한계점이 존재했다. 이는 양방향 문맥 정보가 중요한 token-level task에서 좋은 성능을 보이지 못하는 원인이 되었다.
따라서 본 논문에서는 MLM(masked Language Model)을 사용해 bidirectional한 context도 담을 수 있는 BERT 모델을 제시한다.
MLM이란 문장에서 단어를 선택해 masking을 하고 그 model이 bidirectional context를 통해 해당 단어를 predict하도록 하는 것이다.
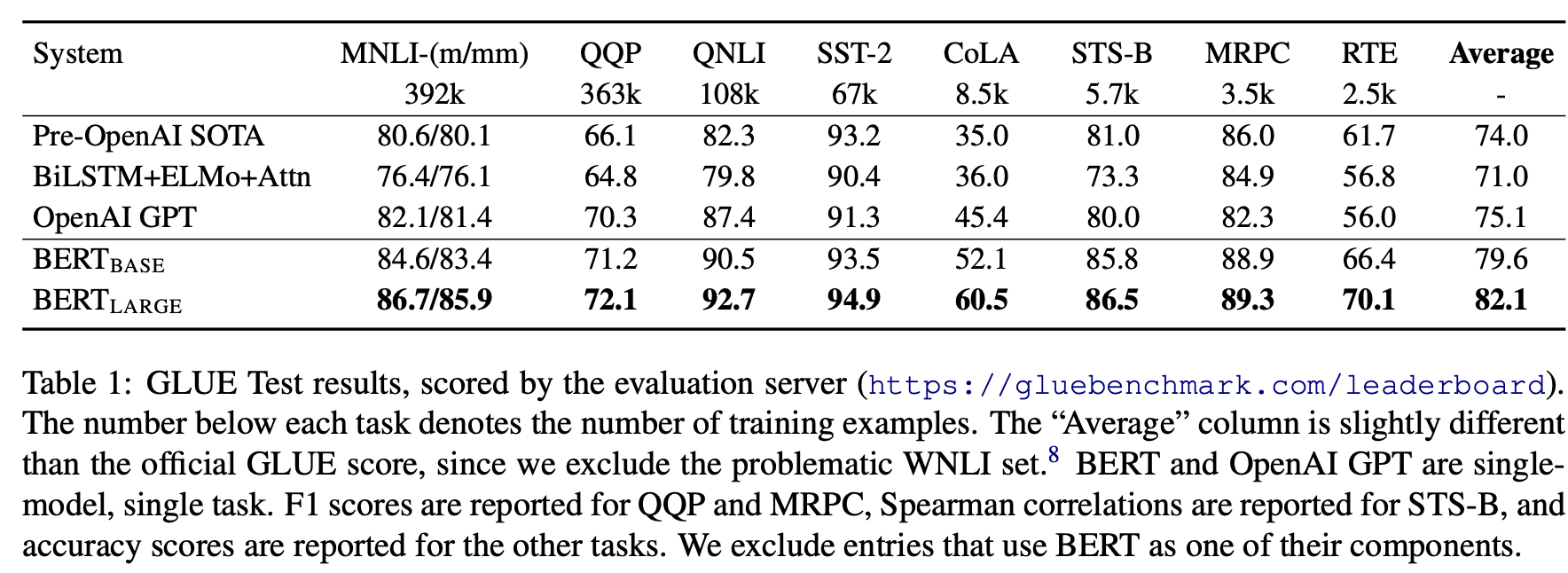
BERT 모델은 총 11개의 NLP task에서 SOTA를 달성했다.
BERT architecture
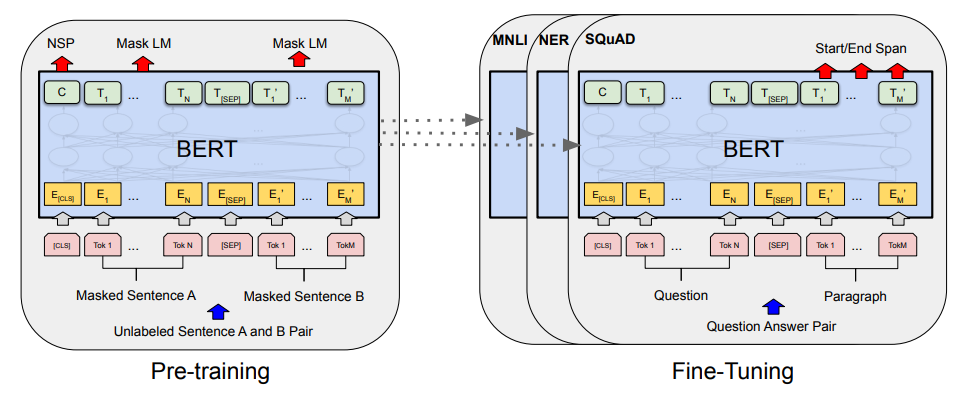
BERT는 fine-tuning approach를 채택했다. 따라서 Pre-training, Fine-tuning의 2가지 Step으로 구분된다.
Pre-Training에서는 Unsupervised Learning을 통해 Language 자체의 representation을 학습한다. 특정 task에 부합하는 학습이 아닌 language의 일반적 특성을 학습한다.
이후 Fine-tuning에서는 각각의 task에 맞는 labeled data를 사용해 Supervised Learning을 수행한다.
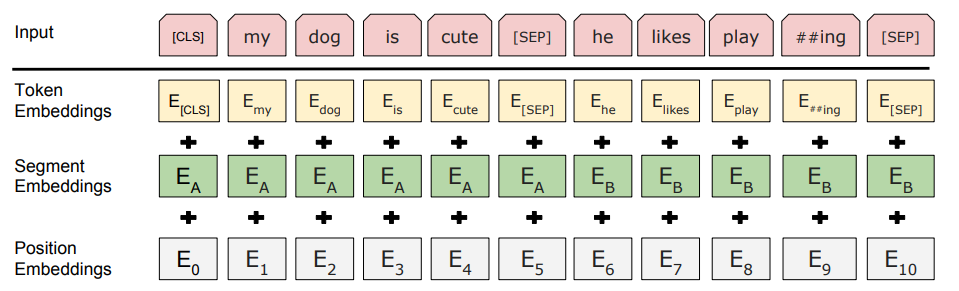
input은 Token Embedding + Segment Embedding + Position Embedding의 형태이다.
BERT는 input으로 최대 2개의 sentence까지 입력받을 수 있는데, 이는 Q&A task와 같은 2개의 문장에 대한 task도 처리하기 위함이다. 따라서 이를 처리하기 위해 seperate token SEP을 추가하였다.
Experiments
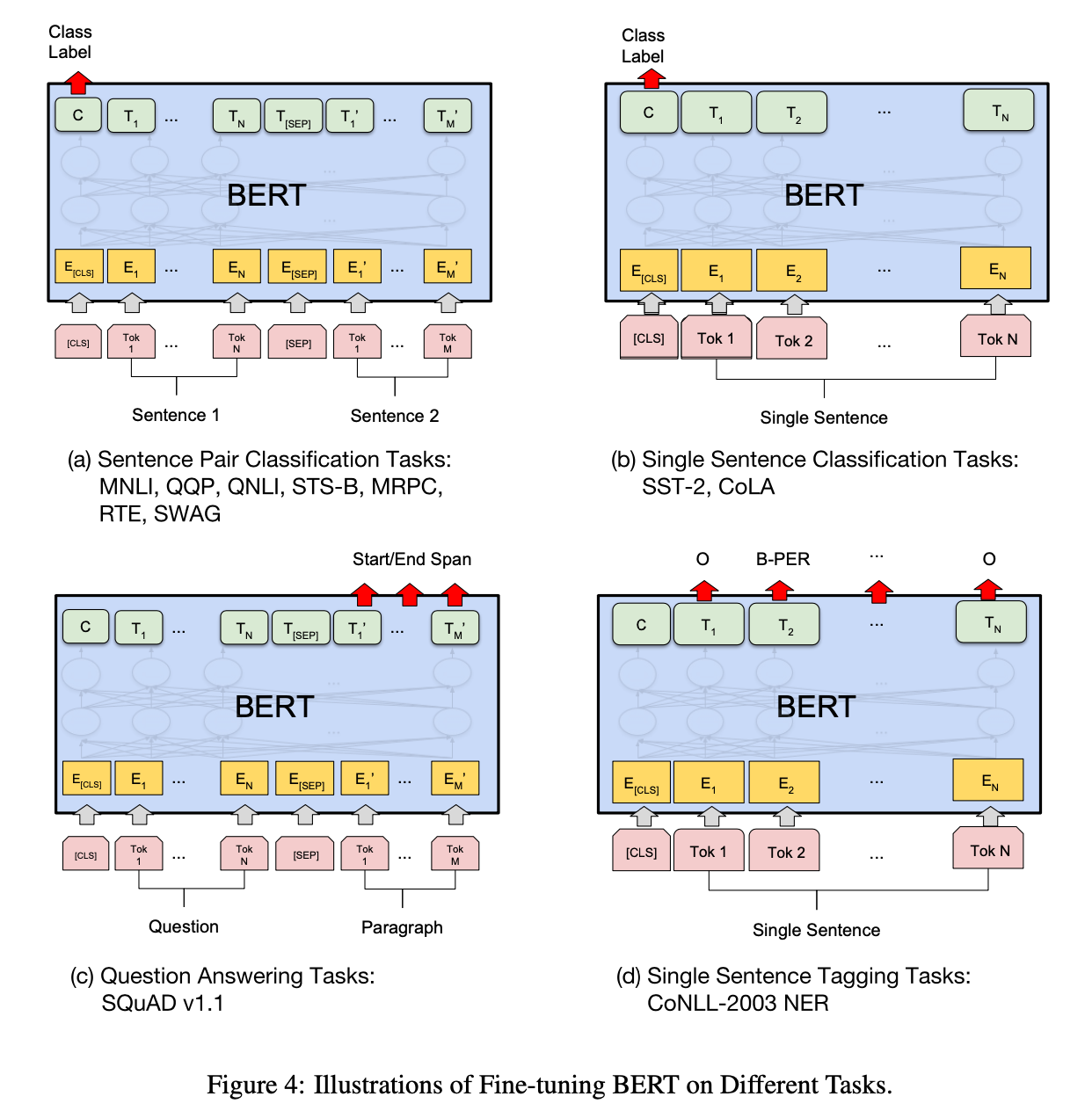
GLUE에 대한 실험이다. GLUE에 대해 fine-tuning을 진행한다. batch-size는 32, # of epoch는 3으로 학습을 진행했다.
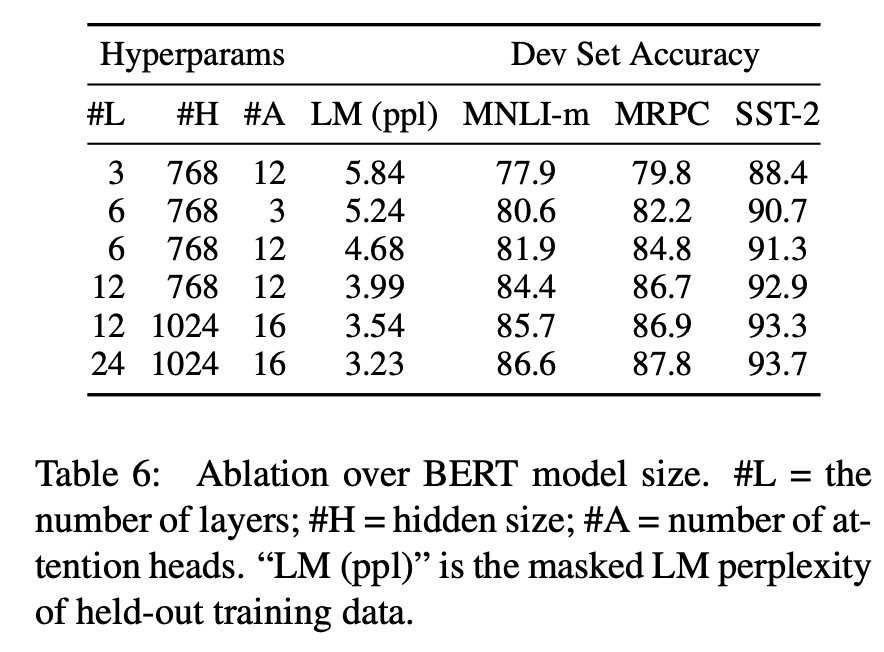
GLUE task 중 3개를 뽑아 Model Size에 따라 성능을 측정했다. Model Size가 증가할수록 성능이 높아지는 경향을 확인할 수 있다.
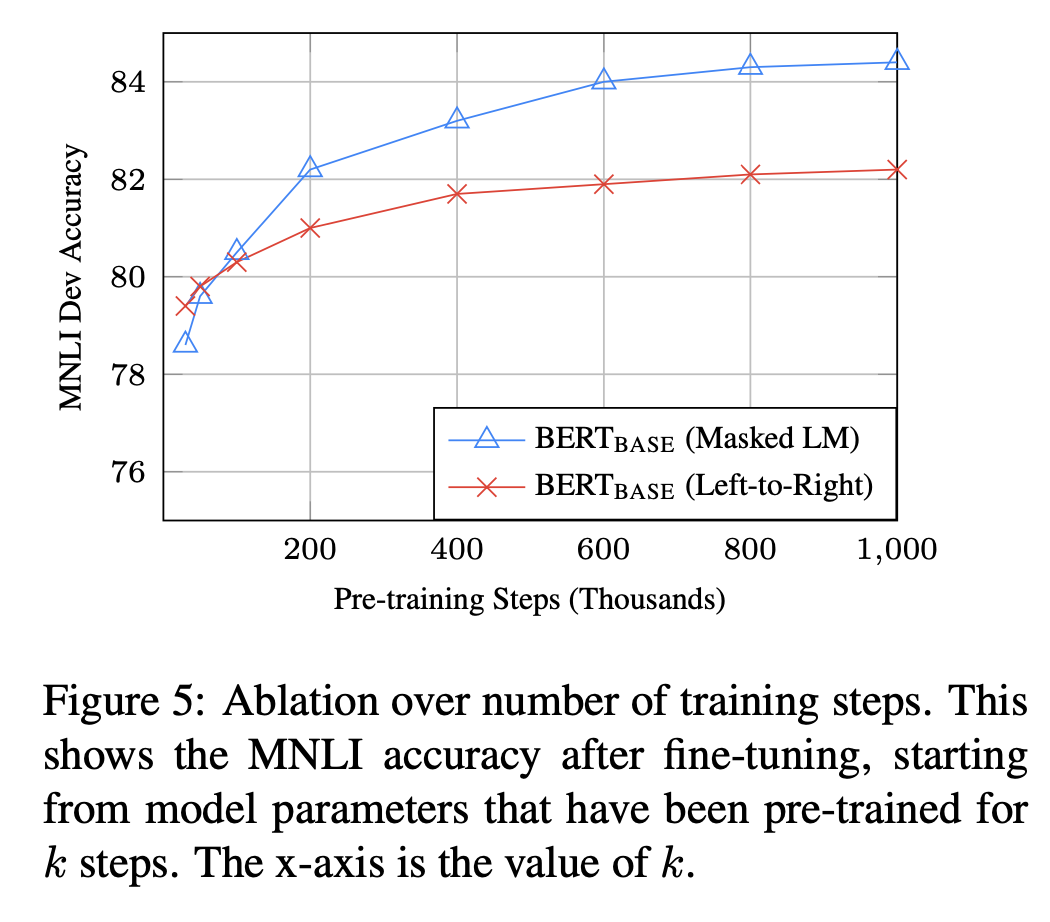
Training을 많이 수행할 수록 성능은 향상되지만, 일정 수준 이상을 지나면 점차 converge하게 된다.