4.4 애그리거트 로딩 전략
JPA 매핑을 설정할 떄 항상 기억해야 할 점은 애그리거트에 속한 객체가 모두 모여야 완전한 하나가 된다는 것이다. 즉 애그리거트는 하나여야 한다. JPA 즉시 로딩(FetchType.EAGER)으로 구현할 수 있지만 그리 좋은 방법은 아니다.
루트 엔티티를 로딩하는 시점에 애그리거트에 속한 객체를 모두 로딩해야 하는 것은 아니다. 애그리거트가 완전해야 하는 이유는 두 가지 정도로 생각해 볼 수 있다.
- 상태를 변경하는 기능을 실행할 때 애그리거트 상태가 완전해야 한다
- 표현 영역에서 애그리거트의 상태 정보를 보여줄 때 필요하다
@Transactional
public void revmoeoptions(ProductId id, int optIdxToBeDeleted) {
//Product를 로딩. 컬렉션은 지연 로딩으로 설정했다면 Option은 로딩되지 않음
Product product = productRepository.findByid(id);
// 트랜잭션 범위이므로 지연 로딩으로 설정한 연관 로딩 가능
product.removeOption(optIdxToBeDeleted);
}
@Entity
public class Product {
@ElementCollection(fetch = FetchType.LAZY)
@CollectionTable(name = "product_option",
joinColumns = @JoinColumn(name = "product_id"))
@OrderColumn(name = "list_idx")
private List<Option> options = new ArrayList<>();
public void removeOption(int optIdx) {
//실제 컬렉션에 접근할 때 로딩
this.options.remove(optIdx);
}
}상태 변경 기능을 실행하기 위해서 조회시점에 즉시 로딩을 이용해서 애그리거트를 완전한 상태로 로딩할 필요는 없다. JPA는 트랜잭션 범위 내에서 지연 로딩을 허용하기 때문에 다음 코드처럼 실제로 상태를 변경하는 시점에 필요한 구성요소만 로딩해도 문제가 되지 않는다.
일반적으로 상태를 변경하기 보다는 조회하는 빈도 수가 높다. 이런 이유로 애그리거트 내의 모든 연관을 즉시 로딩으로 설정할 필요는 없다. 물론, 지연 로딩은 즉시 로딩보다 쿼리 실행 횟수가 많아질 가능성이 더 높다. 따라서, 무조건 즉시 로딩이나 지연 로딩으로만 설정하기보다는 애그리거트에 맞게 즉시 로딩과 지연 로딩을 선택해야 한다.
4.5 애그리거트의 영속성 전파
애그리거트는 완전한 상태여야 한다는 것은 조회할 때뿐만 아니라 저장하고 삭제할 때도 필요하다.
- 저장 메서드는 애그리거트 루트만 저장하면 안 되고 애그리거트에 속한 모든 객체를 저장해야 한다
- 삭제 메서드는 애그리거트 루트뿐만 아니라 애그리거트에 속한 모든 객체를 삭제 해야 한다.
4.6 식별자 생성 기능
식별자는 크게 세가지 방식으로 생성한다.
- 사용자가 직접 생성
- 도메인 로직으로 생성
- DB 를 이용한 일련번호 사용
식별자 생성 규칙이 있다면 별도 서비스로 식별자 생성 기능을 분리해야한다. 이는 도메인 규칙이므로 도메인 영역에 위치시켜야 한다.
public class WriteArticleService {
private ArticleRepository articleRepository;
public Long write (NewArticleRequest req) {
Article article = new Article("7|5", new ArticleContent ("content", "type"));
articleRepository.save(article); // Entityanager#saveO 실행 시 식별자 생성
return article.getIdO; // 저장 이후 식별자 사용 가능
}
...
4.7 도메인 구현과 DIP
JPA 를 사용할 경우 도메인에 @Entity, @Table 등 구현 기술에 특화된 애너테이션을 사용하고 있다. DIP 에 따르면 이는 구현 기술에 속하므로 도메인 모델이 구현 기술인
JPA 에 의존하면 안된다.
import org.springframwork.data.repository.Repository;
public interface ArticleRepository extends Repository<Article, Long> {
void save(Article article);
Optional<Article> findById(Long id);
}Repository의 경우 스프링 데이터 JPA의 Repository 인터페이스를 상속하고 있으므로 이는 도메인이 인프라에 의존하는 것이다.
인터페이스를 상속받지 않도록 수정하고 ArticleRepository 인터페이스를 구현한 클래스를 인프라에 위치시켜야 한다.
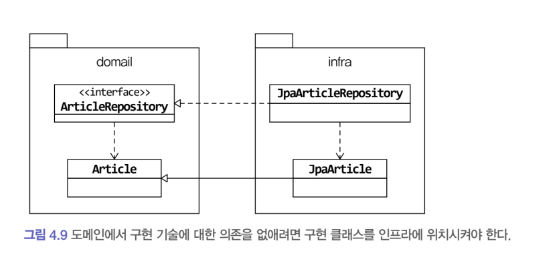
위 구조를 가지면 구현 기술을 변경하더라도 도메인이 받는 영향을 최소화할 수 있다. DIP를 적용하는 이유는 저수준 구현이 변경되어도 고수준이 영향 받지 않도록 하기 위함인데 리포지터리와 도메인 모델의 구현 기술은 거의 바뀌지 않는다.
