UNet이란?
- 의료 영상 분할(Semantic Segmentation)을 위한 딥러닝 모델로 2015년에 개발됨.
- 오토인코더(autoencoder)와 같은 인코더-디코더(encoder-decoder) 기반 모델
- 근데 이제 스킵 연결이 추가된..
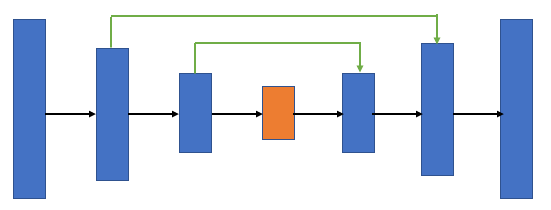
UNet의 구조
개요
- 인코딩(압축)과 디코딩(복원) 과정을 거치는 U자형 구조.
- 인코딩 단계에서 이미지를 점점 작게 만들면서 중요한 특징을 추출하고, 디코딩 단계에서 다시 그 특징을 기반으로 원래 이미지와 비슷하게 복원한다.
채널 수, 이미지 크기의 변화를 이해하기 위해 gpt에게 물어봤음.
Forward 과정에서의 변화
- 입력 (
x):- 채널 수: 3 (RGB 이미지)
- 차원 수: 2차원 이미지 (너비 × 높이)
MaxPool2d와Conv2d함수로 2차원 데이터 임을 짐작할 수 있음. - 특징 수: x
- 이미지 크기: 입력 이미지 크기 (예: 256×256)
인코딩 (Downsampling)
-
Conv1 (첫 번째 Conv Block):
- 채널 수: 3 → 64 (64개의 필터 사용)
- 차원 수: 그대로 (2D 이미지)
- 특징 수: 64개의 특징 맵이 생성됨.
- 이미지 크기: 256×256 (입력 크기 유지)
-
MaxPool:
- 채널 수: 그대로 (64)
- 차원 수: 그대로
- 이미지 크기: 256×256 → 128×128 (풀링으로 크기 절반 감소)
-
Conv2 (두 번째 Conv Block):
- 채널 수: 64 → 128 (128개의 필터 사용)
- 차원 수: 그대로
- 특징 수: 128개의 특징 맵이 생성됨.
- 이미지 크기: 128×128 유지
-
MaxPool:
- 채널 수: 그대로 (128)
- 차원 수: 그대로
- 이미지 크기: 128×128 → 64×64
-
Conv3 (세 번째 Conv Block):
- 채널 수: 128 → 256
- 특징 수: 256개의 특징 맵 생성.
- 이미지 크기: 64×64 유지
-
MaxPool:
- 채널 수: 그대로 (256)
- 이미지 크기: 64×64 → 32×32
-
Conv4 (네 번째 Conv Block):
- 채널 수: 256 → 512
- 이미지 크기: 32×32 유지
디코딩 (Upsampling)
-
Up4:
- 채널 수: 512 → 256
- 이미지 크기: 32×32 → 64×64 (업샘플링으로 이미지 크기 복원)
-
Concatenation:
- 채널 수: 256 + 256 → 512 (업샘플된 것과 Conv3 결과를 결합)
- 이미지 크기: 64×64 유지
- Up_conv4:
- 채널 수: 512 → 256
- 이미지 크기: 64×64 유지
- Up3:
- 채널 수: 256 → 128
- 이미지 크기: 64×64 → 128×128
- Concatenation:
- 채널 수: 128 + 128 → 256 (Conv2 결과와 결합)
- 이미지 크기: 128×128 유지
- Up_conv3:
- 채널 수: 256 → 128
- 이미지 크기: 128×128 유지
- Up2:
- 채널 수: 128 → 64
- 이미지 크기: 128×128 → 256×256
- Concatenation:
- 채널 수: 64 + 64 → 128 (Conv1 결과와 결합)
- 이미지 크기: 256×256 유지
- Up_conv2:
- 채널 수: 128 → 64
- 이미지 크기: 256×256 유지
- Conv_1x1:
- 채널 수: 64 → 1 (출력 채널)
- 이미지 크기: 256×256 유지
UNet 코드 flow
class U_Net(nn.Module):
def __init__(self, img_ch=3, output_ch=1):
super(U_Net, self).__init__()
self.MaxPool = nn.MaxPool2d(kernel_size=2, stride=2)
self.Conv1 = conv_block(ch_in=img_ch, ch_out=64)
self.Conv2 = conv_block(ch_in=64, ch_out=128)
self.Conv3 = conv_block(ch_in=128, ch_out=256)
self.Conv4 = conv_block(ch_in=256, ch_out=512)
self.Up4 = up_conv(ch_in=512, ch_out=256)
self.Up_conv4 = conv_block(ch_in=512, ch_out=256)
self.Up3 = up_conv(ch_in=256, ch_out=128)
self.Up_conv3 = conv_block(ch_in=256, ch_out=128)
self.Up2 = up_conv(ch_in=128, ch_out=64)
self.Up_conv2 = conv_block(ch_in=128, ch_out=64)
self.Conv_1x1 = nn.Conv2d(64, output_ch, kernel_size=1, stride=1, padding=0)
def forward(self, x):
# encoding path
x1 = self.Conv1(x)
x2 = self.MaxPool(x1)
x2 = self.Conv2(x2)
x3 = self.MaxPool(x2)
x3 = self.Conv3(x3)
x4 = self.MaxPool(x3)
x4 = self.Conv4(x4)
d4 = self.Up4(x4)
d4 = torch.cat((x3, d4), dim=1)
d4 = self.Up_conv4(d4)
d3 = self.Up3(d4)
d3 = torch.cat((x2, d3), dim=1)
d3 = self.Up_conv3(d3)
d2 = self.Up2(d3)
d2 = torch.cat((x1, d2), dim=1)
d2 = self.Up_conv2(d2)
net = self.Conv_1x1(d2)
return netconv_block: 여러 개의 Convolution layer를 사용하는 블록
up_conv: 디코딩 단계에서 이미지 크기를 복원(업샘플링)
Mermaid 다이어그램

con_block
class conv_block(nn.Module):
def __init__(self, ch_in, ch_out):
super(conv_block, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(ch_in, ch_out, kernel_size=3, stride=1, padding=1, bias=True),
nn.LeakyReLU(inplace=True),
nn.Conv2d(ch_out, ch_out, kernel_size=3, stride=1, padding=1, bias=True),
nn.LeakyReLU(inplace=True)
)
def forward(self, x):
x = self.conv(x)
return x구조
- (
3x3 convolution layer+LeakyReLU 활성화 함수)패턴이 2중으로 구성됨.
up_conv
class up_conv(nn.Module):
def __init__(self, ch_in, ch_out):
super(up_conv, self).__init__()
self.up = nn.Sequential(
nn.Upsample(scale_factor=2),
nn.Conv2d(ch_in, ch_out, kernel_size=3, stride=1, padding=1, bias=True),
# nn.LeakyReLU(inplace=True)
nn.ReLU(inplace=True)
)
def forward(self, x):
x = self.up(x)
return x구조
-
업샘플링
nn.Upsample(scale_factor=2): 이미지의 크기를 2배로 확대- 원래 이미지가 64×64라면, 업샘플링 후 128×128가 된다.
-
3x3 convolution layer 1개
nn.Conv2d(ch_in, ch_out, kernel_size=3, stride=1, padding=1) -
ReLU 활성화 함수
nn.ReLU(inplace=True)

천천히 꾸준히 취미처럼 냐미😋