.png)
Let’s say there is a network that looks like this:
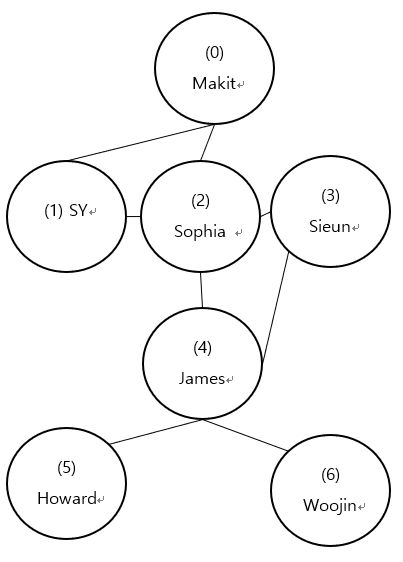
We want to visit each node by following the edges that are connected to each other. Therefore, we want to know the path through which we can follow to reach every single node in this network. How are we going to do this?
First, let’s turn the network into a code. In other words, we will abstract the concept of network into a code. Through abstracting the given information, it is possible to see that there are only two types of information that needs processing: The names and the relationship. From now on, these will be called nodes and edges, respectively.
We could process this information through two lists: key list that contains the node information and two-dimensional list that contains the relationship information. Since the each node has its own ‘number’, each node can be placed at the relative index of the list. For example, since ‘Makit’ is node number 0, ‘Makit’ is the first item of the key list. Let’s take a look at the list:
node_info = ['makit', 'sy' , 'sophia', 'sieun', 'james', 'howard', 'woojin']
By using a two-dimensional list, we can describe the relationship a node has to other nodes. Each list in the two-dimensional list can be dedicated to one node, where each item in the list can be configured either 0 or 1 to denote its relationship to other 6 nodes. Therefore, the size of the list will be n*n, when n is the number of nodes. The code will look like this:
m = [[0, 1, 1, 0, 0, 0, 0],
[1, 0, 1, 0, 0, 0, 0],
[1, 1, 0, 1, 1, 0, 0],
[0, 0, 1, 0, 1, 0, 0],
[0, 0, 0, 0, 1, 0, 0],
[0, 0, 0, 0, 1, 0, 0]]After turning the network into a code, it is time to devise a search algorithm. This search algorithm will use a Breadth First Algorithm (BFS) because we want to search every single node in the network. When the user chooses a node as a positional argument of the function, the algorithm will use that node as a starting point to search through the network. The algorithm will first check for the nodes that are directly connected to current node and secondly check whether if the algorithm already visited the node. If the node is directly connected and has not been visited, the algorithm will check them as visited and conduct the same process from that node.
To work this algorithm, queue concept will be used: each identified connected node will be put into a queue and be used for the algorithmic loop through the function pop(). Each loop, the 0th index of q will pop out and be deleted.
After being used, that node will be put into a list called ‘visited’. For this, two empty list will be made and the algorithm will be initialized with the argument start. (1)
(3)
def search_idx(start):
for i in range(len(node_info)):
if start == node_info[i]:
return i
return None
(4)
def search_name(idx):
for i in range(len(node_info)):
if idx == i:
return node_info[i]
return None
(1)
q = []
visited = []
def BFS1(start):
q.append(start)
visited.append(start)
(2)
while q:
x = q.pop(0)
print(x, end = ' ')
idx = search_idx(x)
cnt = 0
for i in m[idx]:
if i == 1:
name = search_name(cnt)
if name not in visited:
q.append(name)
visited.append(name)
cnt +=1
Then when does this algorithm end? It ends when there is no more node to be searched. In other words, it ends when the queue is empty. Hence, algorithm continues while q.
How should we find the node to search? We will use the for loop for this. First, let’s make two functions each that finds the index at which the node is placed and vice versa. (3) (4)
This way, when the node to search (x) pops out, the function search_idx() can convert it to an index that allows the for loop to operate within the list of the two-dimensional list. search_idx() does this through identifying the index where the name is placed at in node_info list. For example, when the name ‘makit’ is given as the positional argument, search_idx() will find its index, 0, which will be inserted in the for i in m[idx] loop. In this loop, the algorithm will check each item in the 0th index of m, which is a list. Each item of the list has an index, and that index corresponds with the names in the network. If the item is 1, it indicates that the ‘makit’ is directly connected to that item. By using the search_name() function, the name of the item is returned. Here, cnt variable is used as its positional argument and added 1 every loop. Since the for loop checks for the items that is only equal to 1, only the names that have a direct relationship to the item in discussion is returned. (2)
The algorithm continues to check if that item has already been visited. If the returned name is not in the list visited, the name will be added to q and visited by using append() function. (2)
Therefore, only the names that have a direct relationship to the item and have never been visited will be added to the queue, and every time the name at the 0th index will be printed, returning the path needed to search the whole network.
There is a shorter way to program this. Use a dictionary! If you use a dictionary, there is no need to make a set list (which is kind of confusing by the way), because all you have to do is insert the names that the target node is directly attached to to the dictionary. Let’s look at how this works:
m = {}
m['makit'] = ['sy','sophia']
m['sy'] = ['makit', 'sophia']
m['sophia'] = ['sy', 'sophia', 'sieun', 'james']
m['sieun'] = ['sophia', 'james']
m['james'] = ['sophia', 'sieun', 'howard', 'woojin']
m['woojin'] = ['james']
m['howard'] = ['james']The rest of the code follows the same logic as before when we used the two-dimensional list. The difference is we don’t make extra functions the convert the name to index and vice versa. So much easier. So as we did before, we make a empty list q and visited:
q = []
visited = []For this algorithm that use dictionary instead of the list, we do not need the extra if loop because the dictionary only includes the names that are directly connected to the target node. So while q is not empty, q will pop the first item x, print x, search if the names directly connected to x has already been visited, and if not append it to q and visited. This will allow q to spit out the items in the order of its search algorithm, returning the same results as we did for the method using two-dimensional list.
def BFS2(start):
q.append(start)
visited.append(start)
while q:
x = q.pop(0)
print(x, end = ' ')
for i in m[x]:
if i not in visited:
q.append(i)
visited.append(i)Let’s see if this checks out by commanding the functions:
print('Two-dimensional list method: ')
BFS1('makit')
print()
print()
print('Dictionary method: ')
BFS2('makit')
The result is:
>>>
Two-dimensional list method:
makit sy sophia sieun james howard woojin
Dictionary method:
makit sy sophia sieun james howard woojin
>>>