멀티 스레드 프로그래밍 소개
멀티 스레드를 다루는 과정의 기초가 되는 가시성과 원자성을 정의해볼 것
사실 가시성과 원자성이라고 하는 단어는 문제를 해결하기 위한 원칙이다.
바꿔 말해 Multi Thread를 구성하다보니, 비 가시성, 비 원자성 문제가 발생했고, Multi Thread를 문제없이 사용하려면 가시성과 원자성을 확보해야한다.
여기서 ~해야한다는 비단 개발자의 노력만으로 이루어질 수 없음을 말한다. (CPU, OS, JVM 등이 지원해야한다.)
참고로 가시성과 원자성은 여러 Thread가 동시에 접근 가능한 공유 변수에 대한 이야기다.
공유변수에 대한 Thread간 경합 (race condition)
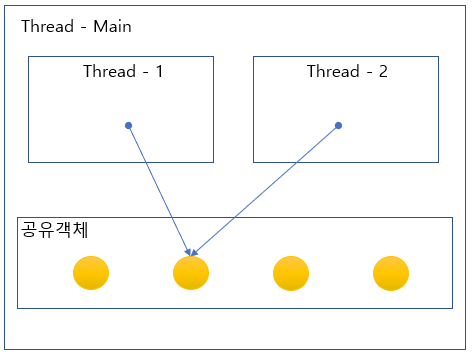
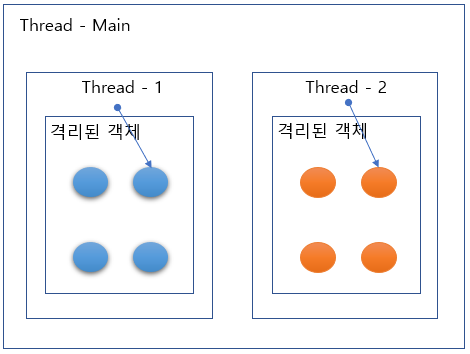
Thread 내에서 생성된 변수 또는 로직적으로 잘 격리된 멤버변수 접근 (비경합)
가시성(Visibility)
가시성, 그러니까 잘 보임의 대상은 무엇일까?
위에서 이미 거론했지만, 우리는 공유하는 변수에 대해 다루고 있다.
이 변수가 HW에서는 Main Memoruy에 적재된다고 알고있다. 맞다. 헌데 int i = 10;이렇게 하면 그냥 메모리에 딱 하고 들어가면 좋겠는데, 성능이니 뭐니 하면서 시스템은 아주 복잡한 설계를 해놨다.
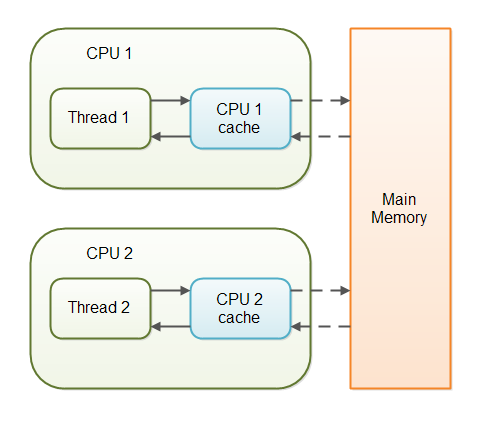
Thread는 동작하는 시점에 하나의 CPU(요즘에는 core라고 해야 맞다)를 점유하고 동작을 한다.
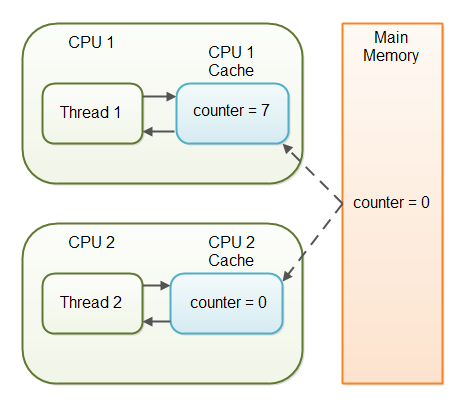
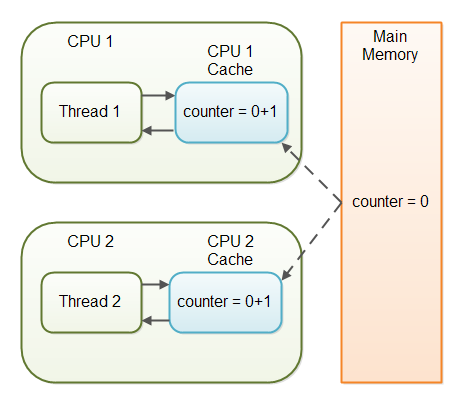
선언한 변수의 값이 Memory에만 존재하는 것이 아니라, CPU cahce라고 하는 영역에도 존재한다. 이는 CPU가 Memory에서 값을 읽어들여오고 다시 쓰고 하는 시간을 아끼기 위함이다. 더 큰 문제는 CPU cache에 값이 Memory에 언제 옮겨갈지도 모른다는 것이다. 이를 해결하는 것을 가시성이라고 한다.
각 Thread가 각기 바라보는 CPU의 cache
CPU1은 7까지 증가했으나, CPU2의 cache는 아직도 0으로 알고있다.
원자성 (Atomicity)
가시성이라는 용어도 그렇지만, 원자성이라는 이 단어 역시 상당히 은유적이다.
가시성 역시 메모리 가시성이라고 하면 좀더 쉽게 와닿을 것이고, 원자성 역시 연산의 원자성이라고 하면 좀 더 이해가 쉽다.
관련 도서나 자료에서는 이를 연산의 단일성 혹은 단일 연산이라고 부르기도 한다.
공유되는 변수를 변경할 때, 기존의 값을 기반으로 하여 새로운 값이 결정되는 과정에서 여러 Thread가 이를 동시에 수행할 때 생기는 이슈를 부르는 명칭이기도 하다.
다수의 책이나 자료에서 다루는 예가 i++연산이다.
자연어 입장에서는 하나의 문장이지만, 이를 CPU가 수행하기 위해서는 총 3가지 instruction이 발생한다.
- i의 기존 값을 읽는다. (READ)
- i에 1을 더한다. (MODIFY)
- i의 값을 변수에 할당한다. (WRITE)
이를 두개 Thread가 동시에 100회 수행한다고 했을때, 만약 i++이 원자성을 가지고 있는 연산이라고 하면 결과가 200이어야 하겠지만, 실제로는 200보다 작은 값이 도출된다.
원인은 다시한번 이야기하지만, i++이 3개의 instruction(READ-MODITY-WRITE)로 구성되어있기 때문이다. Thread-1이 값을 읽어 i+1을 하기 직전에 Thread-2가 i를 읽어 i+1을 수행하고 반영하는 동작을 수행한다면 후자의 연산은 무효가 되는 현상이 발생한다.
가시성 문제를 해결하더라도 원자성이 확보되지 못해 원치 않는 결과가 도출
출처: https://rightnowdo.tistory.com/entry/JAVA-concurrent-programming-Overview?category=396739
가시성
프롤로그
가시성과 원자성 두가지를 이해하면 Multi Thread 프로그램을 작성할 때 무엇을 주의해야하는지 명확해진다.
또 다른 표현으로 설명하자면 단일 Thread 프로그램에서는 가시성과 원자성을 고려하지 않아도 프로그램 작성하는데 문제가 없다.
그렇다고 가시성과 원자성이 Multi Thread를 할 때만 나타나는 개념은 아니라는 점은 명확히 밝혀둔다. 이는 원래 하드웨어를 설계한 사람들에 의해 만들어진 컴퓨터 내의 구조에 관한 이야기이다.
비 가시성 (가시성 이슈)
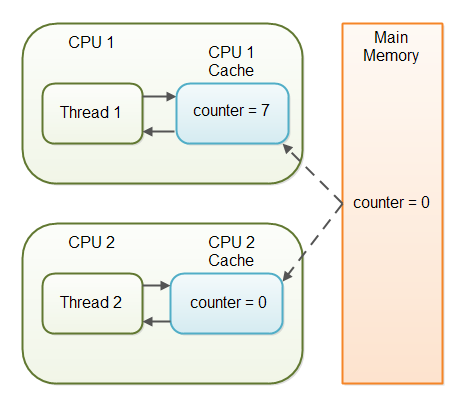
각기 다른 Thread 2개는 CPU1과 CPU2를 할당 받아 공유자원에 해당하는 변수를 연산한다. 이때 메인 메모리에서 값을 읽어들여서 연산에 사용하는 것이 아니라, CPU에 존재하는 Cache에 옮겨놓고 연산을 한다.
그 사이에 다른 쓰레드에서 같은 변수를 대상으로 연산을 한다. 이때 Thread는 타 Thread가 사용하고 있는 CPU의 Cache값을 알지 못한다. 언제 Cache의 값이 메인 메모리로 쓰여질지도 모른다. 그래서 아래 코드를 돌려보면 각각의 Thread가 100회씩 변수를 증가연산을 실시했는데, 200에 훨씬 못미치는 103~105쯤이 나타난다. (이 실험 결과는 하드웨어 성능에 따라 상이할 수 있다.)
만약 동시에 시작하는 Thread가 아닌 순차처리라면 200이 나와야하는 현상이다.
Cache에 담아서 연산을 하더라도 바로바로 메모리에 적용했으면 200이 아니더라도 180~190 정도는 나올 것 같은데 너무나도 100에 가까운 결과에 놀라는 독자도 있을 것이다.

Volatile을 이용한 가시성 확보
visibility(가시성)에 이어 volatile(변덕스러운) 용어가 나왔다.
가시성은 이제 좀 와닿는데 아직도 왜 volatile이라는 단어를 사용하는지 이해를 못한다고 원글 쓰신분은 말씀하신다.
암튼 Java에서 위에서 설명한 비 가시성 이슈를 해결하기 위해 Java 1.4부터 volatile을 지원하기 시작했다.
변수를 선언할 때 해당 단어를 앞에 써주기만 하면 된다. 이렇게만해도 테스트 코드가 "거의" 200을 반환한다. (사실 이 결과는 미신같은 이야기다. 정확히 이야기하면 200이거나 200보다 작은 값을 반환한다.)
원리는 이렇다. volatile로 선언된 변수를 CPU에서 연산을 하면 바로 메모리에 쓴다. (Cache에서 메모리로 값이 이동하는 것을 다른 책이나 문서에서는 flush라고 표현한다.)
그러니 운이 좋게 Thread 두개가 주거니 받거니 하면서 증가를 시키면 200에 가까운 결과를 얻어내는 것이다.
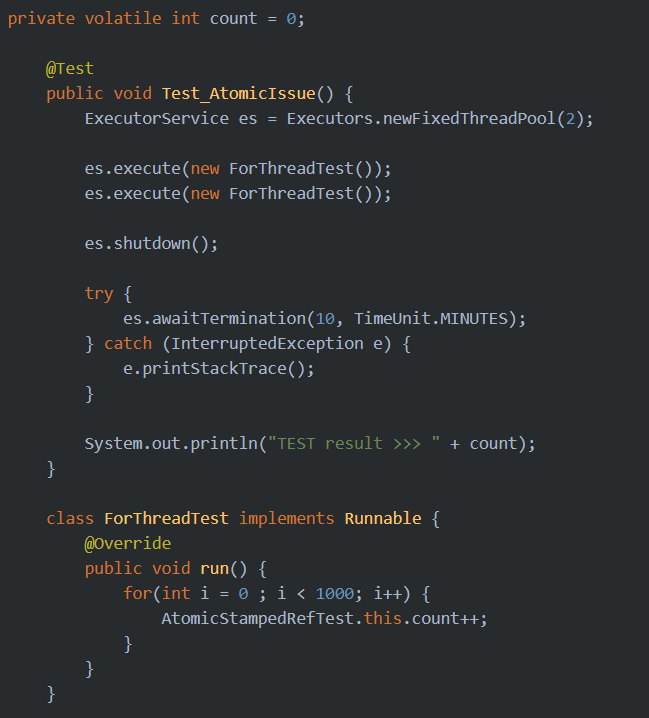
하지만 개발자라면 이 미신같은 결과에 흡족해하면 안된다.
원글 작성자의 컴퓨터 기준으로 각 Thread당 100회가 아닌 1000회 정도 연산을 시키면 2000이 아닌 1998같은 결과를 얻어낸다.
이 이야기인 즉, 가시성이 확보되더라도 원자성 문제 (동시에 같은 값을 읽어다 증가시키고 flush하는...)로 인해 이와 같은 문제가 생긴다.
가시성을 확보하더라도 원자성이 문제되는 경우
Volatile로도 충분한 경우
원글 작성자가 가시성과 원자성을 구분하여 글을 쓰는 이유기도하다.
나중에 다룰 이야기이긴 하지만, Multi Thread의 안정성(데이터 무결성)을 확보한다고 여기저기 synchronized 혹은 lock을 남발한다면 Multi Thread 로직으로 인해 코드 복잡도만 높아지고, 실제 성능에 대한 효과는 크게 누리지 못할 것이다.
필자도 lock과 unlock과정이 내부적으로 어떻게 구현되어있는지 모르지만, 이 과정속에 프로그램 statement context의 switch가 일어나면서 성능이 떨어진다고 한다.
해서 어떤 형태던 lock을 최소화하는 것이 좋은데 volatile도 그 방법중 하나이다. 단 제약조건이 깔린다. 하나의 Thread만이 연산(modify)을 해야한다. 만약 이 전제가 확실한 경우라면 변수에 volatile로만 lock 없이도 문제 없는 데이터를 사용할 수 있다.
아래 코드는 이런 상황을 가정하여 하나의 Thread가 Count를 생산하고 한쪽 Thread는 반대로 읽기만 하는 구조를 갖는 예시이다.
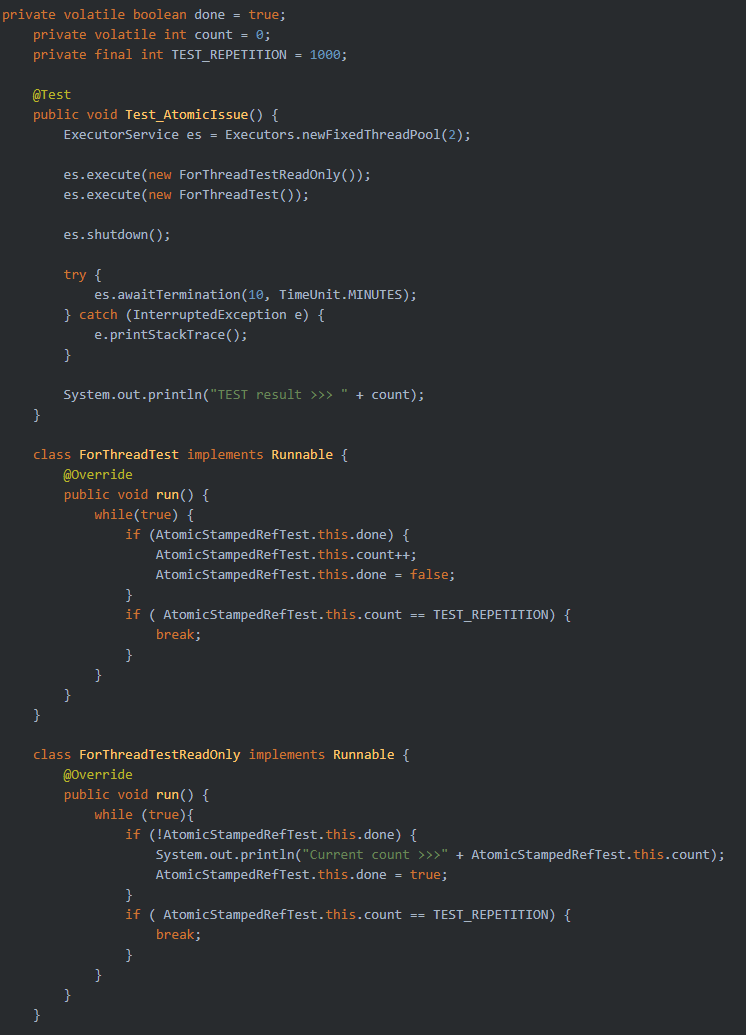
원자성
프롤로그
가시성과 이번에 다루려는 원자성은 Multi Thread 환경에서 Thread간 공유 메모리 이슈를 발생시킨다는 점에서 공통분모를 가지고 있고, 서로간의 상호작용을 잘 염두에 두어야 한다는 것은 사실이다.
하지만 시스템 관점에서 보면 이 두 개념은 조금 다른 곳에 존재한다.
- 가시성 : CPU - Cache - Memory 관계상의 개념.
- 원자성 : 한줄의 프로그램 statement(문장)가 컴파일러에 의해 기계어로 변경되면서, 이를 기계가 순차적으로 처리하기 위한 여러 개의 machine instruction이 만들어져 실행되기 때문에 일어나는 현상을 설명하는 용어.
원자단위 연산의 이해
원자성 즉, 연산의 원자 단위를 이해하기 위해, 이전에 다루었던 i++를 원자 연산으로 분해해보도록 하겠다.
프로그램 언어 문장 -> machine instruction 변환
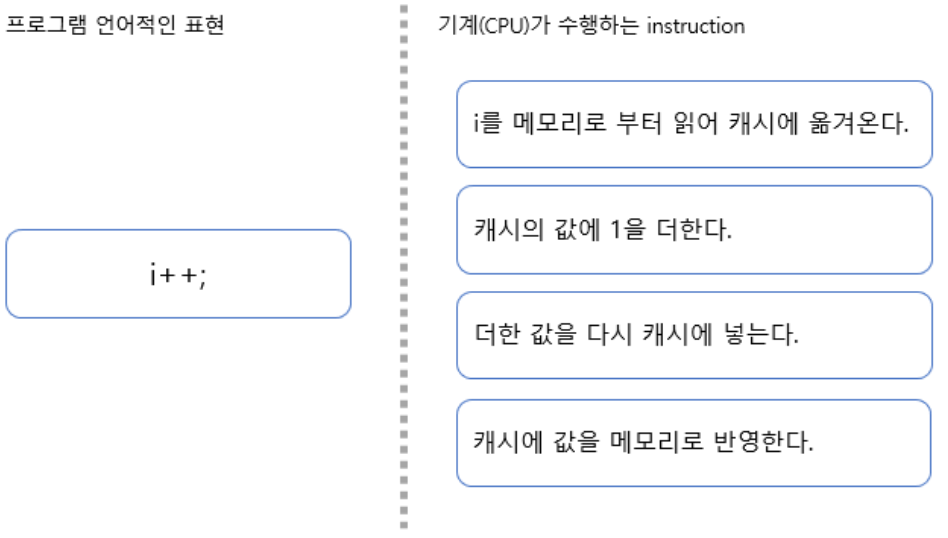
i++이 위 그림과 같이 캐싱을 배제하더라도 읽고(READ) > 연산하고(MODIFY) > 저장(WRITE)하는 총 3가지의 instruction이 수행된다.
이 원자단위의 연산을, 수행중에는 다른 Thread에 의해서 컨트롤되는 타 CPU의 개입이 있을 수 없는 최소 단위의 연산이라고 이해하면 된다.
여기에 Multi Thread를 개입시켜보자. 각 instruction이 수행되는 사이에는 다른 Thread가 공유 메모리(변수)에 접근이 가능하여, 소위 값이 꼬이는 현상이 생기게 된다. 이러한 점을 예방하는 방법을 알아보자.
동기화 처리를 통한 Thread 안정성 확보
하나의 원자 연산이 이루어지는 동안, 이 연산은 다른 Thread - CPU에 의해 간섭받을 수 없다. 이것은 시스템이 이렇게 구현되어있는 것이다.
헌데, 우리가 다루고자하는 연산은 원자단위로 하기에는 너무 복잡하다. 각종 조건, 반복, 보조장치로부터의 데이터 읽기와 쓰기 등이 복합적으로 이루어지는 연산이 섞여있다. 이러한 복잡한 연산을 i++도 한번에 못하는 시스템한테 한번에 시킨다는 것은 불가능하다. (시스템의 발달로 i++를 원자단위로 할 방법은 있다.)
개발자가 이를 쉽게 해결할 수 있는 방법이 바로 임계영역(Critical Section) 지정이다. 동시에 처리되면 문제가 되어 상호 배타적인(Mutual Exclusion) 영역을 설정하는 것이다. 여기서 말하는 영역은 공간적인 영역이 아닌 statement(명령문)의 블럭이다.
임계영역 설정
Synchronized 블럭
코드의 가독성 측면에서 봤을 때 가장 좋은 방법이다.
단, 가독성이 좋다고 성능도 좋은 것은 아니다.
이 블럭을 설정해놓으면 그 구간에는 Thread 하나만 접근 가능하다. 다른 Thread가 접근하려고 하면 기다려야한다. 이를 Lock이라고 한다. 문법은 아래와 같다.
synchronized(락 객체) {
//임계 영역 (Thread 동시접근이 불가능)
}여기서 "락 객체"에 대한 이해가 필요하다. 여기에 지정된 객체는 synchronized 블럭, 즉 임계영역의 공유를 지정하는 변수 또는 타입(클래스)이다.
즉, 같은 lock객체를 사용하는 여러 synchronized 블럭은 한곳만 Thread가 진입해도 다른 Thread가 다른 synchronized 블럭을 진입하지 못한다는 말이다. 자물쇠로 잠겨있는 화장실이 여러개라도, 열쇠가 하나의 열쇠뭉치에 묶여있다면 설령 다른 화장실이라도 들어갈 수 없는 것이다.
Synchronized 함수
이 방법은 함수가 통채로 임계영역으로 구성되어야할 때 사용하는 방법이다.
public synchronized void method() {
// 자원 경합 (race condition)이 일어나는 코드
}처음 보는 분들은 락-객체의 부재에 의문점을 가질 수도 있다. 하지만 답은 의외로 간단하다. this가 생략되었다고 보면 된다. 해당 class의 모든 synchronized 함수 그리고 this를 사용하는 블럭의 lock이 공유되는 것이다. 하나만 Thread가 점유해도 모두 못들어간다.
지금까지 설명한 두 가지 동기화 블럭 설정을 통한 Thread 안정성 확보 방법 외에도, 명시적으로 임계영역의 시작을 lock하고, 끝나면 unlock하는 방법도 있다.
뭐가 되었든 지금까지 설명한 동기화 처리 방법은 여러 Thread를 그야말로 동기처리하는 것이다. 회사일을 여러 사람이 나누어 할 때 개수가 한정되어있는, 또는 하나밖에 없는 도구를 사용해야할 때, 다른 사람이 다 사용할 때까지 기다려야하는 이치와 같다. 이를 책이나 여러 자료에서는 Blocking 동기화라고 한다.
단일연산(atomic) 변수를 이용한 None Blocking 동기화
Blocking 동기화는 여러가지 단점이 존재한다. 그중에서도 손꼽는 것이 성능이슈이다.
어떤 Thread는 Lock을 확보하느라, 또 다른 Thread는 Lock을 확보하지 못해 Blocking 상태로 들어가느라, 그리고 이 상태가 변경되는 동안 많은 시스템 자원이 쓰인다고 한다. (Context Switching 비용) 결국 이 문제는 성능문제로 이어진다.
최근의 CPU는 이러한 문제를 해결하기 위해 Atomic Hardware Primitives를 제공한다. 예를들어 i++를 단일연산으로 처리할 수 있는 방법을 제시하는 것이다. 이 instruction의 동작원리는 다음과 같다.
- 인자로 기존 값과 변경할 값을 전달한다.
- 기존값으로 던진 값이 현재 시스템이 가지고있는 값과 같다면 변경할 값을 반영해준다. 반환값으로 true를 리턴한다.
- 반대로 기존값으로 던진 값이 현재 시스템이 가지고있는 값과 다르다면 값을 반영하지 않고 false를 리턴한다.
기존값과 다른경우는 무엇일까? 바로 그 사이에 다른 Thread가 들어가서 값을 바꿔놨다는 말이다. 그러니 이런 경우에는 false를 리턴한다. 그 이후는 개발자보고 알아서 하라는 말이다.
일반적으로는 loop를 구성하여 다시 기존값을 읽고 같은 시도를 한다. 만약 뭐 바쁜일이 있으면 다른 일을 해도된다. 개발자 마음이다. 다른사람이 하나밖에없는 도구를 쓰고있다고 계속 기다리는 것도 (Blocking) 미련한 짓 아닌가? 다른 일이 없어서 loop를 계속 돌면서 계속 내 값을 반영해주겠니를 물어본다고 해도(Busy waiting) Blocking이 일어나는 것보다는 성능적으로 우수하다.
이와 같은 연산방식을 CAS(Compare and Swap)이라고한다. 모든 단일연산(atomic) 변수의 핵심은 이부분이다. 이를 이용하여 자료구조를 안전하게 구현하는 것을 lock free 알고리즘이라고 부른다.
다음은 단일 연산 변수중 하나인 AtomicInteger를 이용하여 Thread에 안전한 카운터를 구현하여 Test한 예제이다. 두 개의 Thread는 동시에 시작하여 0~ 10만회 카운트를 증가시킨다. 결과는 20만이 나온다.
만약 Thread 안정성에 문제가 있다면 20만 이하의 숫자가 반환될 것이고, Lock을 이용한다면 Thread간의 경합으로 인해 상대적으로 성능이 저하될 것이다.
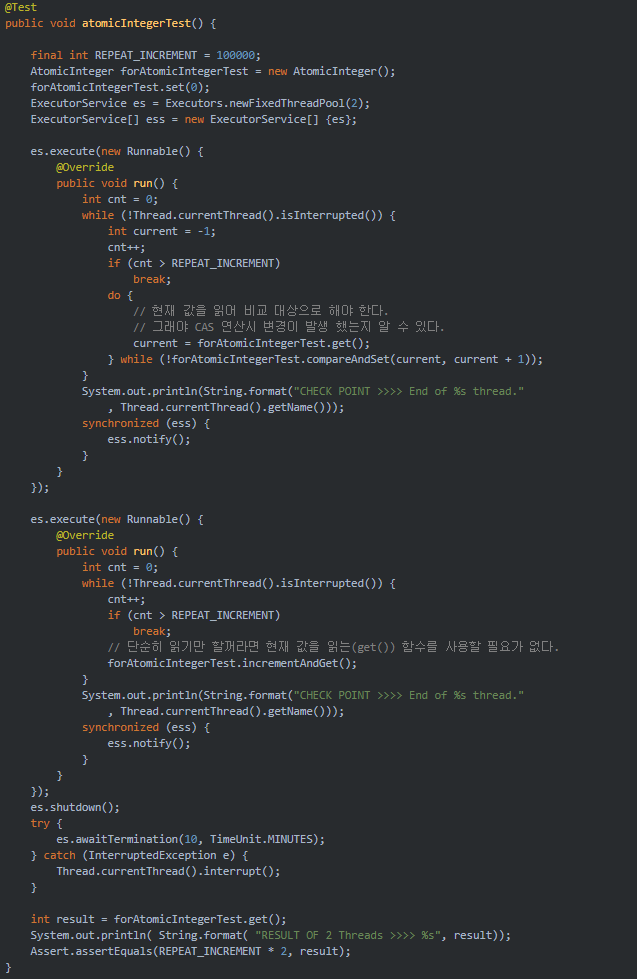
다음 코드는 AtomicReferenc<>를 이용한 간단한 Stack이다.
class ConcurrentStack<E> {
AtomicInteger size = new AtomicInteger(0);
AtomicReference<Node<E>> head = new AtomicReference<Node<E>>();
public void push(E item) {
Node<E> newHead = new Node<E>(item);
Node<E> oldHead;
do {
oldHead = head.get();
newHead.next = oldHead;
} while (!head.compareAndSet(oldHead, newHead));
size.incrementAndGet();
}
public E pop() {
Node<E> oldHead;
Node<E> newHead;
do {
oldHead = head.get();
if (oldHead == null) {
return null;
}
newHead = oldHead.next;
} while (!head.compareAndSet(oldHead, newHead));
size.decrementAndGet();
return oldHead.item;
}
public int size() {
return size.get();
}
static class Node<E> {
final E item;
Node<E> next;
public Node(E item) {
this.item = item;
}
}
}
// 아래는 Test Class의 일부
@Test
public void atomicReferenceTest_Stack() {
final int REPEAT_INCREMENT = 100000;
ConcurrentStack<Integer> stack = new ConcurrentStack<Integer>();
ExecutorService es = Executors.newFixedThreadPool(2);
ExecutorService[] ess = new ExecutorService[]{es};
es.execute(new Runnable() {
@Override
public void run() {
int cnt = 0;
while (!Thread.currentThread().isInterrupted()) {
cnt++;
if (cnt > REPEAT_INCREMENT) break;
stack.push(cnt);
}
System.out.println(String.format("CHECK POINT >>>> End of %s thread.", Thread.currentThread().getName()));
synchronized (ess) {
ess.notify();
}
}
});
es.execute(new Runnable() {
@Override
public void run() {
int cnt = 0;
while (!Thread.currentThread().isInterrupted()) {
cnt++;
if (cnt > REPEAT_INCREMENT) break;
stack.push(cnt);
}
System.out.println(String.format("CHECK POINT >>>> End of %s thread.", Thread.currentThread().getName()));
synchronized (ess) {
ess.notify();
}
}
});
es.shutdown();
try {
es.awaitTermination(10, TimeUnit.MINUTES);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
int result = stack.size();
System.out.println(String.format("RESULT OF 2 Threads >>>> %s", result));
Assert.assertEquals(REPEAT_INCREMENT * 2, result);
int topOfStack = stack.pop();
System.out.println(String.format("TOP OF STACK VALUE >>>> %s", topOfStack));
Assert.assertEquals(REPEAT_INCREMENT, topOfStack);
}에필로그
가시성과 더불어 원자성을 이해하고 이로 인해 발생할 수 있는 Thread 안정성 문제와 이를 해결하기 위한 기법에 대해 정리해보았다.
실제 병렬처리를 수행하는 프로그램을 작성해보면 정말 고민해야할 부분이 많다. 그러다보면 코드가 복잡해진다.
더욱이 성능문제 때문에 Lock-Free로 구현하고자 한다면 코드는 한층 더 복잡해질 것이다.


좋은 글 감사합니다~
멀티 쓰레딩에 대한 이해를 하는데 많은 도움이 되었습니다!