배민 MSA 여행기
출처 : https://www.youtube.com/watch?v=BnS6343GTkY
서비스 성장폭
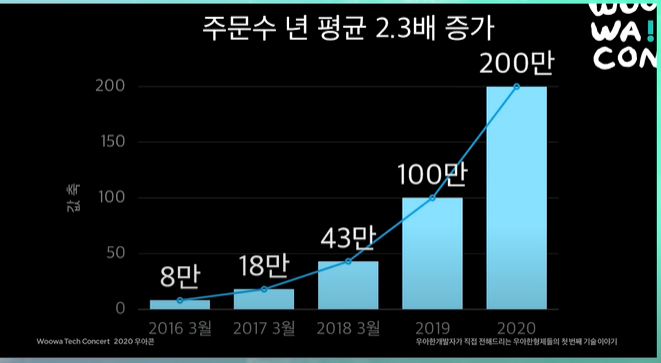
배달의 민족은 매년 주문수가 평균 2.3배 증가할 정도로 굉장히 급성장하는 서비스 (이런 수준의 성장은 과거의 비트코인 거래소 정도가 있음)
역사
2015년도
- 하루 주문수 5만건 이하
- MS SQL + PHP,ASP
- 대부분 루비DB(MS SQL) 스토어드 프로시저 방식 사용
- 그냥 레거시 같은거 새로 만들면 되지 않을까 했는데,
- 테이블이 700개, 스토어드 프로시저가 4000개정도 있었음 입사당시.
- 굉장히 거대한 모놀리틱 시스템이었다.
- 루비 DB 장애시 전체 서비스 장애
단일 서비스
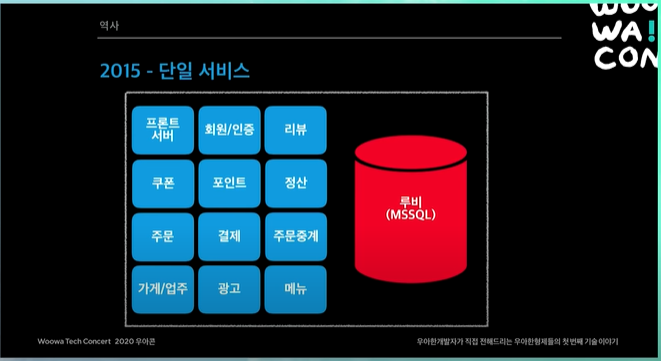
- 주요 서비스들만 명시 (굉장히 많은 서비스들이 존재)
- 이러한 서비스들이 배포 같은 것은 애플리케이션은 따로있어도, DB는 하나 루비라는 MS SQL DB를 사용
- 문제는 루비 DB가 죽는 순간, 전체 서비스가 마비가 된다!!
- 루비 DB는 여러분 상상을 초월하는 고스펙
- 어느정도냐면 CPU 모니터링 화면을 열어도 모니터링 화면이 안죽을정도로 굉장히 고스펙
- 단적인 예로 리뷰테이블에 뭔가 문제가 있어서 데이터베이스 리소스 전체에 자꾸 영향을 주었음
- 그래서 리뷰에 관련한 DB 테이블들이 밀리면서 결국 루비 DB(MS SQL)자체가 밀림 ➡ 전체 서비스 시스템이 다 밀리면서 장애가 나게됨
- 사실 리뷰에 문제가 있더라도 고객의 주문에는 영향이 없어야한다.
2016년도
- 하루 주문수 10만건 돌파
- 계속해서 늘어나는 트래픽에 대응하기위한 도전 시도
- PHP ➡ Java 언어
- 대용량 트래픽에 안정적으로 대응할 수 있는 여러 기술들 제공
- 우리나라에서 개발자 수급에 용이
- 마이크로 서비스 도전 시작
- 위에서 든 예시처럼 리뷰시스템에 문제가 있으면, 리뷰만 죽고 끝나야지, 전체 서비스가 죽어버리면 안된다.
- 결제, 주문 중계 독립
- IDC ➡ AWS 클라우드 인프라로 이전 시작
첫 자바 마이크로 서비스 등장 (결제)
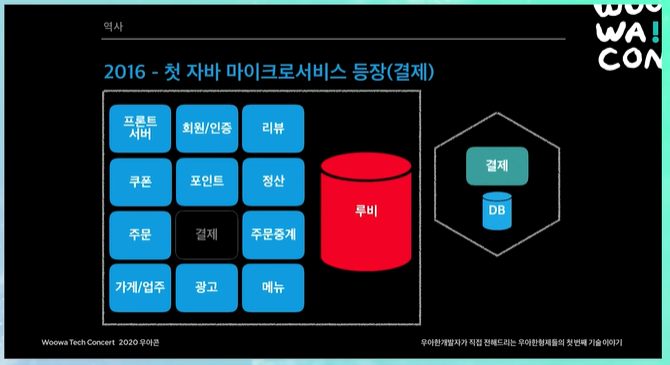
여기서 말하는 마이크로 서비스는 완전히 DB까지 분리된 것을 말한다. 이당시에 DB는 Maria DB 사용
위처럼 결제를 마이크로 서비스로 분리하면 얻는 장점
➡ 결제가 장애가 나도, 최소한 전화주문이라도 할 수 있다.
주문 중계 Node JS
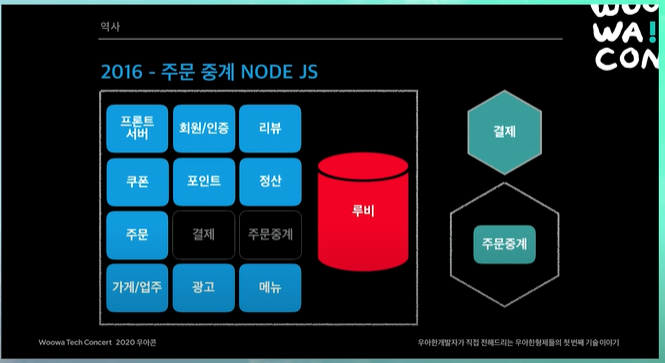
주문 중계 서비스라 함은, 고객들이 치킨 주문을 했을 때, 사장님들이 이 주문을 App으로 받을 수도 있고, PC로 받을 수도 있고, 단말기로도 받을 수도 있다.
즉 중간에서 이 주문을 fowarding 해주는 게이트웨이 서비스였다. (게이트 웨이는 라우터처럼 목적지로 패킷(혹은 데이터) 보내주는 역할)
게이트웨이 서비스는 Node JS처럼 가벼운 기술을 사용하는 것이 좋다고 생각해서, 메인 기술은 Java지만 다른 기술들도 비즈니스 상황이 맞으면 사용할 수 있다고 생각해서 사용. (물론 지금은 서비스가 굉장히 복잡해지면서 다 Java로 바꾼 상황)
치킨 디도스
- 선착순 결제 할인 이벤트 ➡ 치도스 🤣
- 선착순 1000명 치킨 7000원 할인!
- 오후 5시 시작!
특정시간대에 트래픽이 확 몰리니까 준비할게 많음
치킨 디도스 DAY1
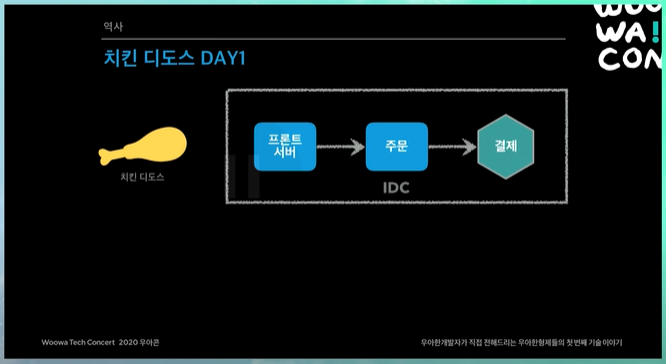
해당 이벤트가 성공하려면 앞단에 메인화면, 상세 리스트를 통과해서 주문 결제까지 성공해야함.
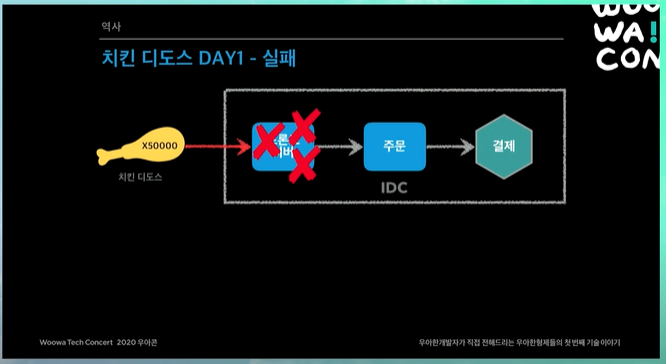
나름 준비는 했지만, 생각했던 것보다 훨씬 많은 사람들이 들어옴.
그당시에 너무 많은 트래픽을 받고, 프론트 서버 자체가 죽어버림. 메인 리스트 상세쪽이 죽어버리니까 주문까지 트래픽이 들어오지도 않음.
치킨 디도스 DAY2 - AWS 긴급 이전
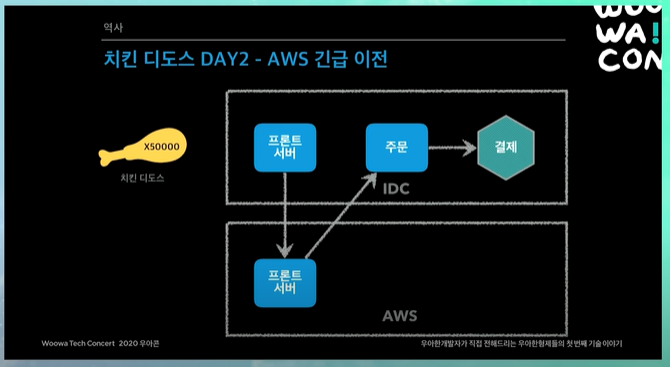
첫날 실패하니까, 다음날에도 해야하니까 골치임
사실 원래 IDC에서 AWS로 이전해야하는 한달 플랜을 잡아놨었는데, 한달에 할거를 하루만에 하는 기적이 일어남 🤣
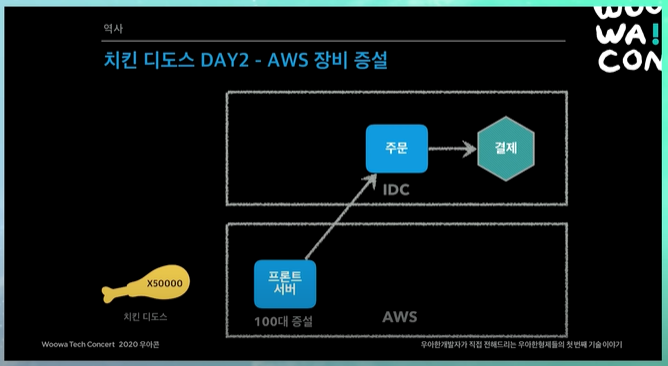
개발자분들의 고생으로 프론트 서버 시스템을 AWS로 이전, 서버 100대 증설! (AWS를 사용하니까 abusing이 됨, 장비 100대 증설)
장비가 늘어나있으니까 트래픽을 받을 수 있음!!
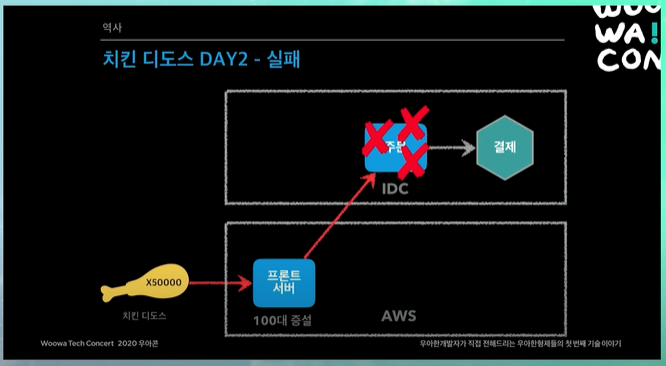
그런데 바로 주문서버가 죽어버림 ㅋㅋㅋㅋㅋㅋㅋㅋㅋ
주문서버도 하루만에 기적이 일어남 ㅋㅋㅋㅋㅋㅋ 서버대수 확 늘려서 100대 증설
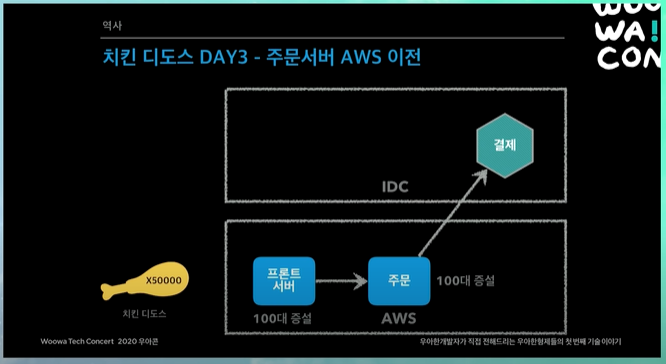
치킨 디도스 DAY3 - 이벤트 시작
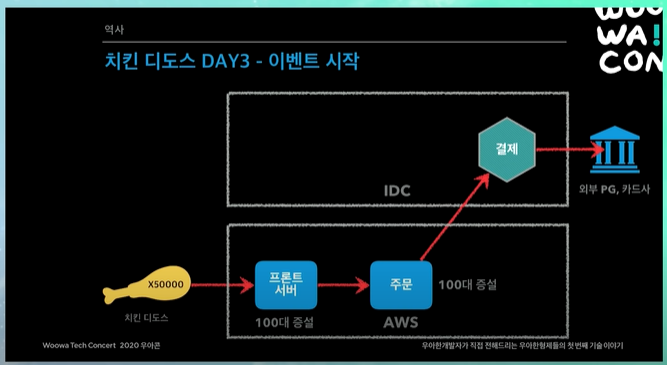
기도 메타로 모니터링 화면앞에서 상태를 같이 보고있었음.
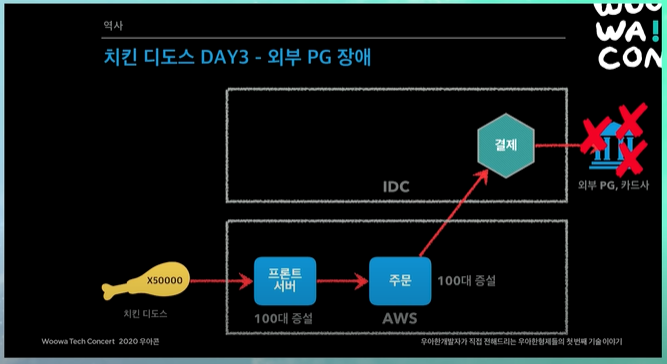
성공했나? 했는데 결제까지 완료가 되었는데, 외부 PG사에서 장애가 나버림 😱
치킨 디도스 DAY4 - 이벤트 성공
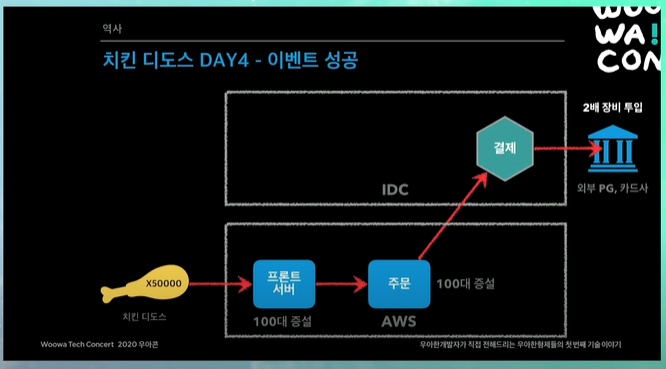
그날 새벽 PG사랑 카드사에서 별도로 장비를 늘려서 이를 해결함
2017년도
- 하루 주문수 20만 돌파
- 대 장애의 시대!!!
- AWS로 조금씩 장비를 이전하긴 했지만, 이제 겨우 시작하는 단계
- 비즈니스 적으로 처리해야하는 요구사항들이 너무 많았음 (기술적인 부분은 많이 챙기지 못함)
- 트래픽은 계속 늘어나는데, 시스템은 레거시
- 스케일할 수 있는 구조가 아님
- 당시에 주말 오후 5시쯤 될때마다 긴장했음 ㅋㅋㅋㅋ 장애가 나면 모니터링하고 해결해야되니까 ㅜㅜ
- 메뉴, 정산, 가게 목록 시스템 독립
가게목록 + 검색, 메뉴, 정산
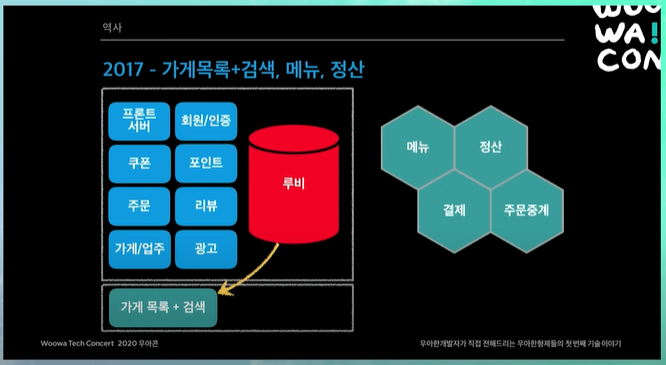
당시에 광고와 검색이 하나의 프로젝트로 되어있었음
해당 기능을 루비 DB에서 떼어내서 엘라스틱 서치로 이전함. 이렇게하면 루비 DB에 가는 부하가 좀 줄어듦
2018 상반기
- 전사 1순위 과제 : 시스템 안전성
- 배달의 민족은 시스템 안전성이 가장 중요하다고 전사적 의사결정함
- 회사입장에서 고민 (같은 3개월 기간 프로젝트일때)
- 매출이 100억, 200억 오르는 프로젝트
- 장애가 줄어드는 프로젝트
- 당연히 돈을 버는 과제가 우선순위가 되고, 레거시 시스템을 새로운 시스템으로 바꾸는 과제는 우선순위가 떨어짐
- 일이 들어오면 계속해서 비즈니스 요구사항이 들어오기 때문에, 이것들을 같이 해야함 (달리는 마차의 바퀴를 바꿔라 😅)
- N 광고 폭파 ➡ 장애대응 TF 창설
- 가게 상세 재개발 (주요 장애 포인트)
- 당시 배달의 민족은 하나의 가게가 하나의 광고만 할 수 있었음
- 사장님이 특정 아파트 단지에 우선순위를 가져야하지 하고, 그 아파트 단지에 광고를 냄 (그 아파트 단지에 매출이 올라옴)
- 갑자기 새 아파트 단지가 올라옴, 기존에는 사장님이 광고를 하나만 할 수 밖에 없었음
- 똑같은 이름으로 가게를 하나 파서 새로운 아파트 단지에 광고 팜
- 그냥 여러개 광고 할 수 있게 하면 안돼? ➡ 레거시 시스템을 아예 다 갈아엎어야함
- 당시에 이러한 프로젝트가 수익이 굉장히 잘나올 프로젝트기 때문에 진행중이었는데, 해당 프로젝트를 폭파시키고, 장애대응 부터 진행함
- 쿠폰, 포인트 탈루비 (레거시 MS SQL에서 빠져나옴)
- 오프라인 모드 적용
기존 가게 상세
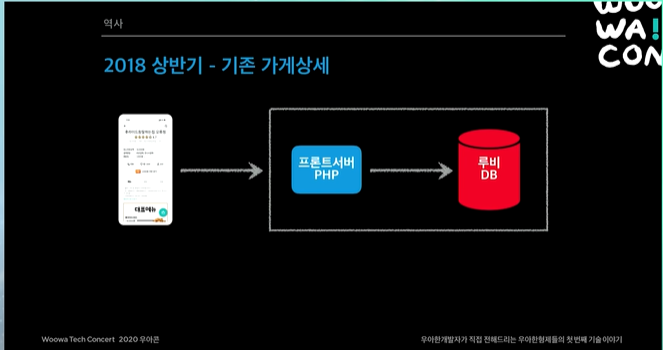
당시에 PHP 매우 잘아는 분도, 이정도 트래픽이면 무조건 자바로 가야한다고 조언
신규 가게 상세
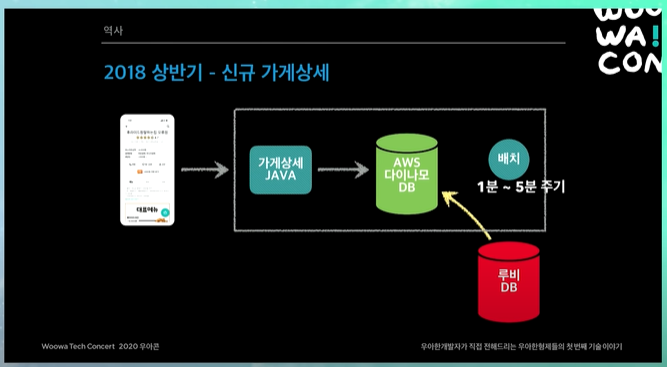
루비 DB에 있는 것을 1분 ~ 5분 주기 배치로 AWS 다이나모 DB (일종의 NoSQL) 에 퍼부음 ㅋㅋㅋ (일단 살고보자)
이렇게 해놓으면 어쨌든 루비 DB에 가는 트래픽이 많이 줄어듬, AWS 다이나모 DB가 해결하니까.
루비 DB가 일반 승용차라고 하면, AWS 다이나모 DB는 고급 스포츠카라고 할 수 있음. 트래픽 굉장히 잘받고 잘 안죽음. 대신 쓸 수 있는 기능이 작음.
단점은 데이터 Sync가 조금 늦는다는 것 (1~5분 주기로 배치처리하니까)
또 요구사항 변경되면 수천라인의 SQL쿼리를 수정해야함. 뒤(벡엔드)에서 뭔가 가게나 광고쪽이 바뀌면 데이터 퍼올리는 쿼리 자체도 굉장히 많이 수정해야함
가게 상세
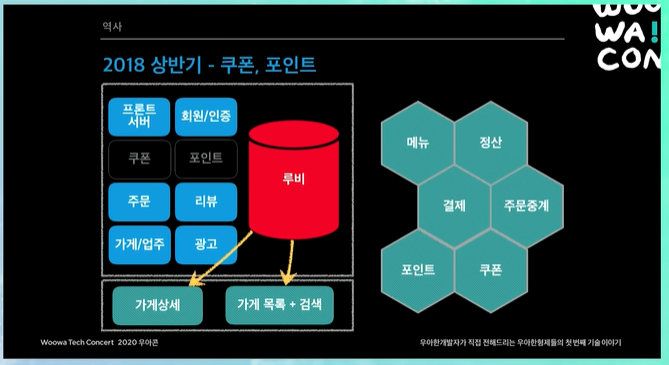
가게상세랑 가게목록+검색 빠져나오고, 쿠폰과 포인트도 빠져나옴
2018년도 하반기
- 주문 탈루비
- 리뷰 탈루비
주문 탈루비
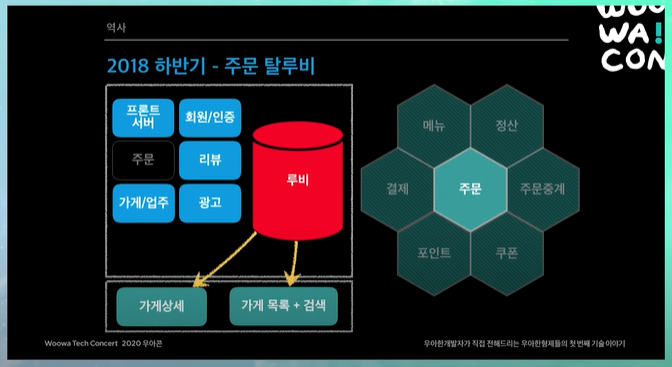
주문이 가운데에 있다.
커버스 도메인을 해본 사람은 알겠지만, 주문이 제일 복잡함. 주문을 모으는 시스템은 다 엮인다. 결제, 포인트, 쿠폰, 주문중계, 정산, 메뉴 등등 다 엮임. 여기다가 돈까지 왔다갔다 하기 때문에.
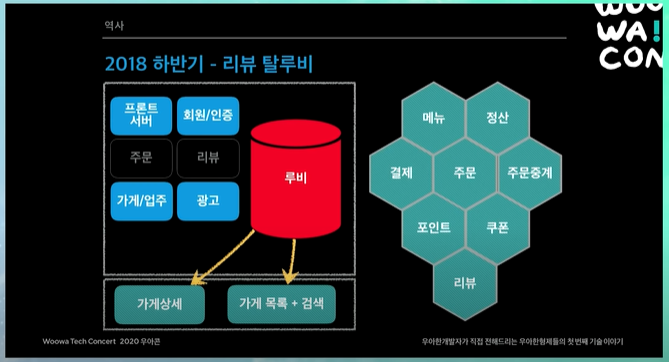
리뷰까지 뽑아냄
레거시 3대장

주문은 지금까지 온 데이터 트랜잭션이 다 쌓임. 데이터 지분률 1위고, 비즈니스가 연관도가 되게 높음. 당시 하루 100만인데, 지금은 하루 수백만건의 데이터가 쌓이고 있음.
가게 업주데이터는 모든 시스템에 다 필요하기 때문에, 시스템 연관도 1위
광고같은 경우 당시에 스토어드 프로시저 사용률이 1위였어서 걷어내기 쉽지 않음. 또 돈을 다루다보니 삐끗하면 문제생김. 어쨌든 회사의 메인 비즈니스 모델이니.
다시 주문 탈루비로
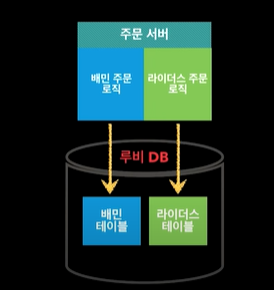
콘웨이의 법칙 : 시스템의 구조가 조직의 구조를 따라간다.
배달의 민족이라는 서비스가 있고, 배민 라이더스 서비스가 있다.
배민 라이더스 서비스는 배달의 민족이 전용 라이더들을 수급을해서 배달을 해주는 서비스다.
배달의 민족은 배민에서 직접 배달해주는 것이 아니고, 일반적인 가게들, 배달하던 가게들이 배달해주는 것. 배민 라이더스는 배달하지 않던 가게들을 배민이 직접 배달의 민족 라이더스를 통해 배달해주는 것.
이게 조직이 아예 다르다보니까, 만들 당시에 배민 라이더스를 아예 별도로 만듦. 배달의 민족 시스템이랑 비슷하게.
완전히 똑같으면 상관이 없는데, 똑같은 듯 싶으면서도 몇개 다름. 그런 경우 참 합치기도 어렵고 분리하기도 애매함.
그런데 나중에 보니 배민 라이더스 시스템이 기존의 것이랑 비슷해서 시스템을 통합하기로 결정. 그래서 조직도 주문 관련된 부분이랑 합쳐지고 그럼. 시스템 통합을 하는데 통합이 잘 되나? 잘 안되지 당연히.
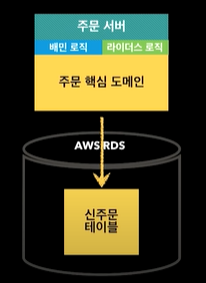
그래서 원래 아예 다른 테이블로 운영하고 있었는데, 새로 테이블을 설계를 하고, 이 두가지를 포함할 수 있게 만들기로함.
상위 애플리케이션 레벨이랑, 데이터베이스 시스템 일부만 좀 바꿔서 어쨌든 시스템 통합하고, 애플리케이션 레벨에서 분리함. 어쨌든 도메인은 하나로 정리
주문 이벤트 기반 아키텍처 구성
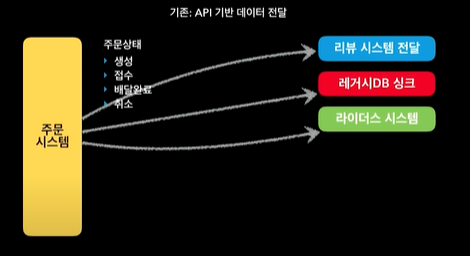
주문이 생성 접수 배달 취소 하는 동안 수많은 라이프사이클이 있음. 그동안 수많은 외부 API를 호출했음.
단적으로 배달의 민족 주문이 되고 나면 사장님이 접수하는 곳으로 넘어가야함. 또 배민 라이더스 시스템에도 넘어가야하고. 또 새로운 시스템을 만들면서 과거 DB도 싱크해주어야하고. 또 이건 약간 애매하긴 한데, 주문 완료하고 나면 리뷰 써달라고 푸쉬해주는 기능 있음. 리뷰 시스템 입장에서는 푸쉬 날릴려면 해당 주문이 배달 완료되었는지 알아야함. 이런 것들이 기존 시스템에서는 다 API로 되어있었음
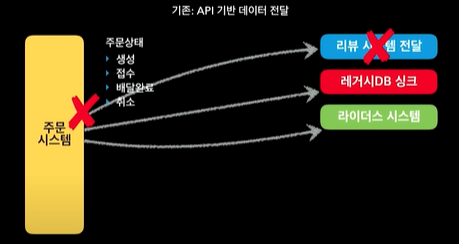
따라서 기존 아키텍처같은 경우 리뷰 시스템에 장애가 나면, 주문 시스템도 영향을 받음. 되게 애매함.
생각해보면, API가 딱 끊기면 주문 시스템에서 미는 시스템에서 타임아웃 나거나, 에러가 날 것임.
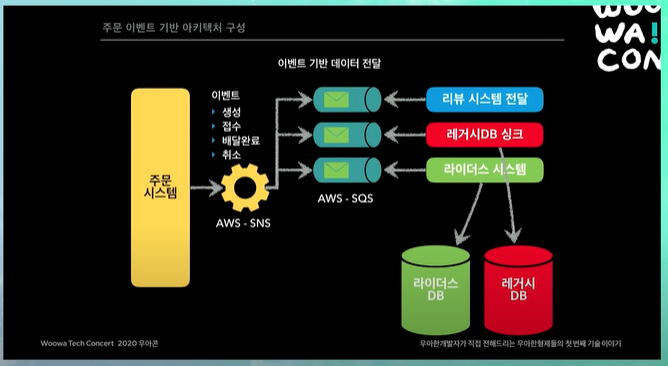
따라서 아키텍처를 위와 같이 구성하기로 결정.
주문은 명확한 이벤트기반으로 주문의 라이프 사이클을 정의하자!!
그래서 이벤트 기반의 마이크로 서비스 아키텍처를 고민하자! 그래서 전사에서 이해할 수 있는 명확한 주문 이벤트를 정리함. 주문 생성, 접수, 배달완료, 취소 (이외에도 몇가지 더 있긴 함)
그래서 앞으로 주문 시스템에선 이벤트만 발행할거야. 그러니까 이제는 너희 시스템들이 원하면 이 이벤트를 가져가서, 서브스크립션(?)해서 너희들이 원하는 비즈니스 로직을 작성해!
이런식으로 완전히 비즈니스 로직을 분리함.
당시에는 AWS SQS나 SNS에 대한 노하우가 좀 있어서 이렇게 했음.
주문 시스템은 AWS SNS에 이벤트를 쏘고, (이벤트 안에 데이터가 있다. 이러한 이벤트 생성되었습니다. 접수되었습니다.) 각 시스템들에서 (리뷰, 레거시, 라이더스 시스템 등) 해당 이벤트들을 consume해서 가져가는 식으로 바꿔감.
이렇게하면, 위에서 든 예시처럼, 리뷰시스템이 죽어도 주문 시스템에선 아무런 문제가 안일어남. 주문 SNS하나 쏘고 끝나는 것이니까.
또 좋은점은, 리뷰 시스템이 죽었다 살아났을 때, 기존 API방식에서는 해당 이벤트가 날라가 버리는데, 이런 이벤트기반 시스템에서는 리뷰 시스템이 살아나는 순간, AWS SQS에 쌓여있는 이벤트들을 다시 consume할 수 있다. 그래서 앱 푸시를 다시 보낼 수 있는 것.
시스템들의 회복력이 굉장히 좋아짐.
또 중요한거 하나있음. 새로운 시스템이 주문 시스템 필요로 한다면, 그 시스템이 AWS SQS를 하나 만들고, 주문 SNS에 연결해서 시스템을 딱 꽂으면 된다. 주문 시스템이 제일 편해짐. 연동해달라고해서 따로 연동 구축할 필요없이 우리 주문 이벤트 이렇게 되어있으니 연결해서 쓰세요 하면 됨.
이렇게해서 2018년도 하반기부터 장애가 급격히 줄어듬. 주문이라는 되게 큰 시스템이 빠져나감.
남은 레거시 2대장(가게/업주, 광고)만 처리하면 됨
해당 기능들은 되게 역사가 오래된 기능. 배민의 처음부터 함께한 시스템들임.
위에서 말했듯이, 가게랑 광고랑 1:1임. 하나의 가게가 하나의 광고만 할 수 있음. 가게 테이블 안에 광고 데이터가 들어가있음. 그래서 1:1이라고함. 하나의 컬럼을 계속 추가한 것임. 그래서 컬럼이 거의 100개 가까이 됐음. 그래서 이걸 떼어내기가 굉장히 어려움.
가게를 손댈라해도, 광고를 멈춰야하고, 광고를 손댈라해도 가게를 멈춰야하고. 전체시스템에 영향있기 때문에 거의 비즈니스를 몇개월 멈춰두고 진행해야하는 작업이었던 것.
이때 회사에서는 이러한 의사결정을 함.
기술적으로 MSA로 가려면 프로젝트를 몇개월 중단시켜야함. 그런데 회사는 비즈니스를 해야하기 때문에 이것을 선택하기 굉장히 어려움. 그런데 이것을 기가막히게 접점을 만들어냄.
하나의 가게가 여러 개의 광고를 하게되면 비즈니스에 굉장히 도움된다. 하지만 이걸 하려면 먼저 시스템 기반이 안정화되어야하고 이걸 이렇게 바꿔야한다. 그래서 우리가 이걸 하기 위해선 앞으로 여기에 집중하고, 앞으로 세네달동안 여기에만 집중하도록 개발팀을 도와주자하고 의사결정을 봄. 이것이 바로 프로젝트 먼데이. 사업도 만족하고 비즈니스 개발팀도 만족하는 그런 프로젝트
먼데이 프로젝트
2018년 12월 - 먼데이 시작 직전
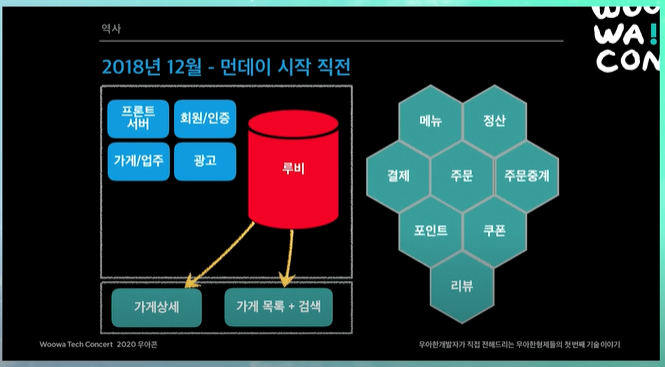
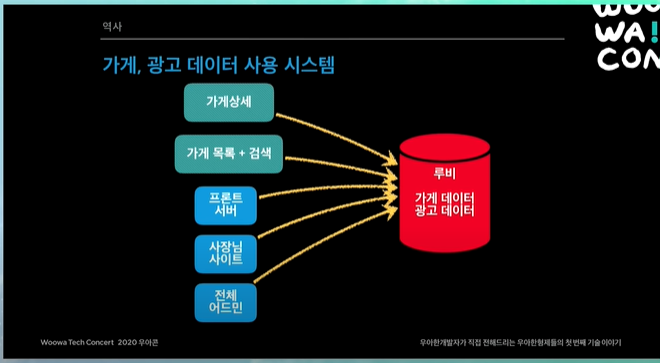
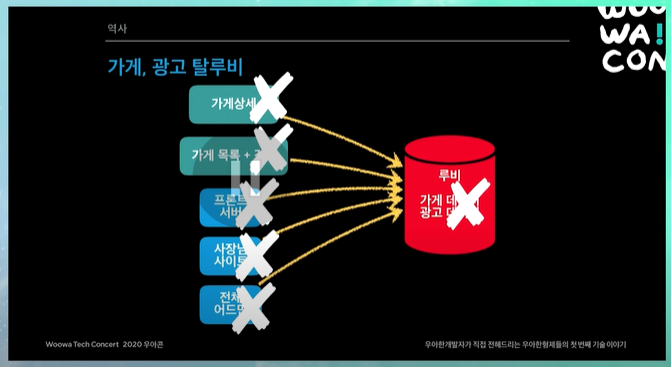
가게상세, 가게목록 검색, 프론트서버, 사장님 사이트, 전체 어드민 모든 시스템들이 루비안의 가게랑 광고 데이터들을 보고있었음. 또 위에서 말했듯이 가게랑 광고 데이터가 막 섞여있었음. 따라서 거의 모든 시스템들이 같이 손을 봤어야 했음.
시스템 전환
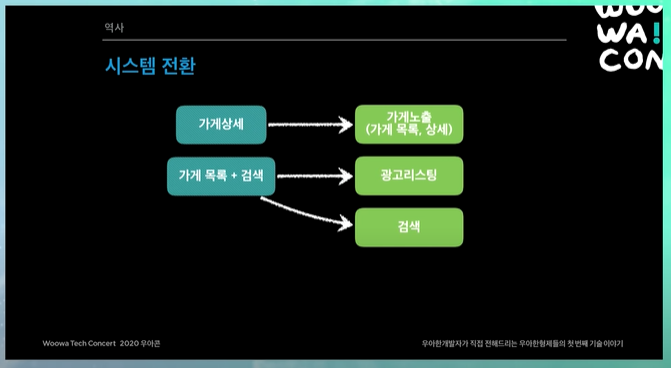
당시 개발 리더들끼리, 어차피 만들거 깔끔하게 가자고 결정함.
당시 가게 상세라는게 있는데, 이것을 가게 노출이라는 시스템으로 만들기로함. 이게 뭐냐면, 마이크로 서비스 공부하다보면 CQRS 모델이라는게 나오면서 쿼리 모델이라는 것이 있다.
서비스 조회용 가게 데이터를 가지고있는, 서비스에 fit하게 맞춘 가게 데이터를 가지고있는 쿼리 모델 만드는데, 그것이 바로 가게 노출 시스템.
또 가게목록이랑 검색 시스템이 하나로되어있었는데, 이거를 광고용 시스템과 검색시스템으로 명확히 분리하기로함.
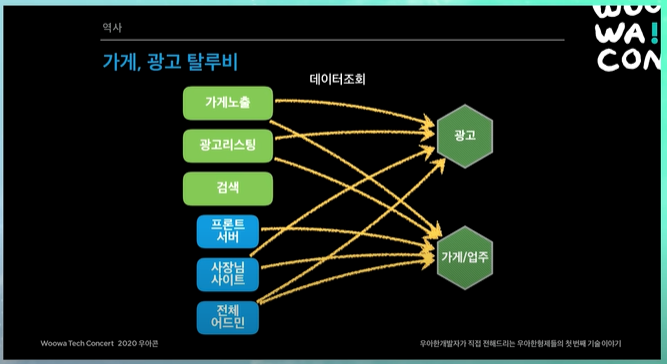
결론적으로 광고용 시스템 마이크로 서비스로 만들고, 가게 업주 시스템 마이크로 서비스로 만든다음에, 필요한 시스템에서 API로 호출해서 사용하면 된다.
하지만 전사적인 레벨에서의 아키텍처를 새로 고민하는 단계였고, 여기서 가장 중요한 것이 장애를 어떻게 대응할 것인가였다.
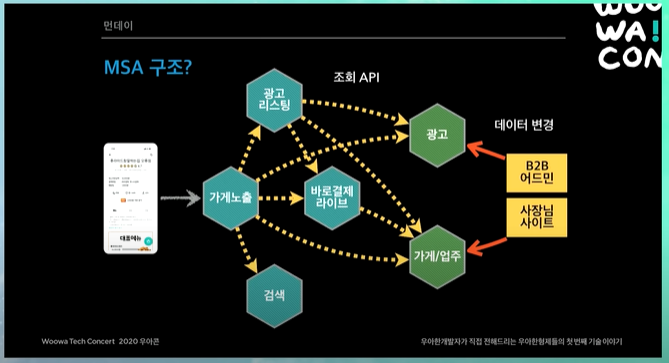
기본적으로 고민했던 첫번째 안같은 경우, API로 개발하고, 단순히 API조회 하는 방식 서비스를 구성하자였다. 이게 가장 단순하고, 데이터 동기화 고민도 할 필요없다.
사장님들이 가게 업주 데이터들을 바꾸면 가게 업주 서비스 내부에 있는 데이터베이스의 데이터들만 바꾸고, 나머지 시스템들은 실시간으로 API를 찌르면된다. 그러면 단순하다.
장애전파
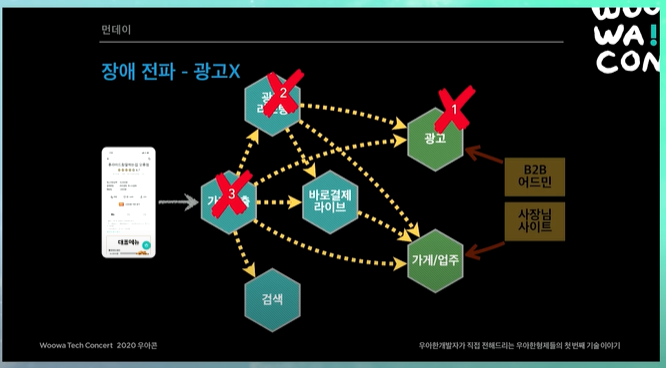
그런데 위와 같은 문제가있다.
예를들어 광고시스템에 장애가 생겼다하면, 광고시스템의 API를 호출하는 모든 시스템에 연쇄적으로 장애가 전파된다.
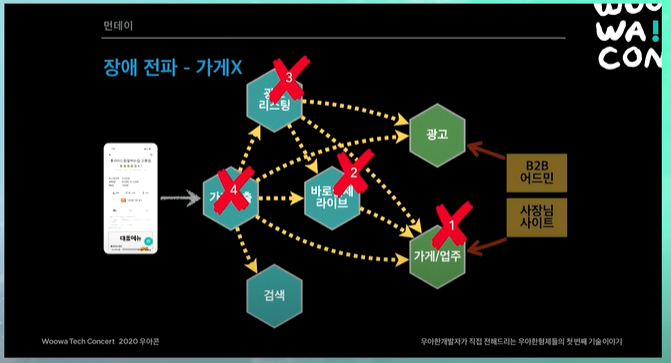
가게 시스템도 마찬가지임. 가게시스템에 문제가있으면, 그 가게시스템의 데이터를 사용하는 모든 시스템들이 연쇄적으로 죽는 것.
고성능 조회
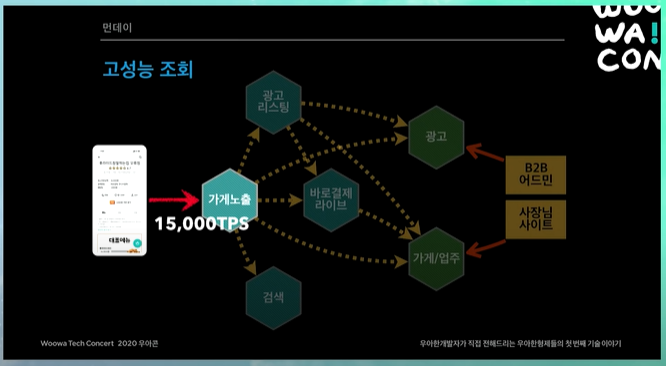
배달의 민족 트래픽이 굉장히 늘어나고있었고, 또 이벤트같은 것을 많이해서 정말 대량의 트래픽이 순간적으로 막 몰려온다.
그러면 모니터링 툴이 순간적으로 피크를 확 친다. 평상시보다 트래픽 100배씩 들어온다. 이렇게 되면 API 호출방식을 사용할 경우 해당 트래픽이 모든 곳에 퍼지게된다.
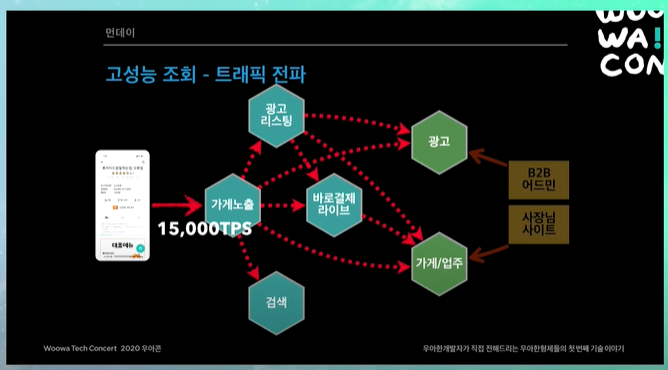
그러면 가게노출, 광고리스팅 이런 것들이 대용량 트래픽을 잘 받을 수 있도록 설계할 수 있지만, 광고나 가게업주 시스템같은 경우 트래픽을 해결하는 것보다는 "정확하고 안정적으로 시스템을 운영하는 것"이 훨씬 중요하다.
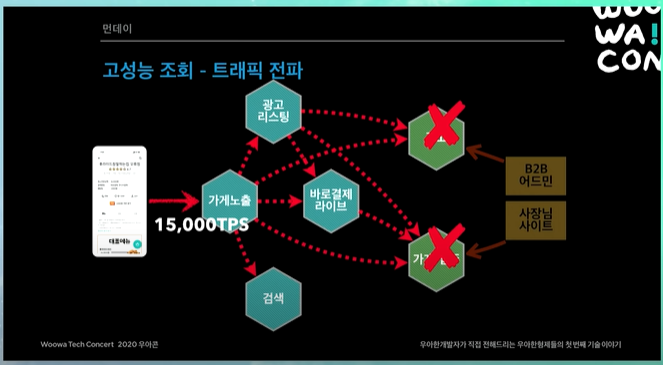
그러므로 대용량 트래픽 들어오면 장애가 날 것이다.
먼데이 아키텍처
고려사항
- 성능
- 장애격리
- 데이터 동기화
성능
- 대용량 트래픽 대응
- 점심, 저녁, 이벤트때 트래픽 급증
- 메인, 가게 리스트, 가게 상세 API는 초당 15000회 호출
- 모든 시스템이 대용량 트래픽을 감당하기는 현실적으로 어려움
장애 격리
- 가게나 광고 같은 "내부 서비스"나 DB에 장애가 발생해도
- "고객 서비스"를 유지하고 주문도 가능 해야함.
가게나 광고같이 사장님이 관리하는 그런 서비스가 죽어도, 고객이 결제까지 해서 주문까지 들어올 수 있어야한다.
데이터 동기화
- 데이터가 분산되어있음
마이크로 서비스를 하게되면 데이터가 분산되게 되는데, 이를 어떻게 Sync 할 것인가.
해결방안
CQRS
CQRS 아키텍처를 선택하기로함
- 핵심 비즈니스 명령(Command) 시스템과
- 조회(Query) 중심의 "사용자" 서비스
- 둘을 철저하게 분리 (심지어 조직도 분리되어있음)
- Command and Query Responsibility Segregation (CQRS)
단순히 한 시스템만 CQRS로 가는게 아니라, 배달의 민족 전 시스템을 CQRS로 가기로 결정함.
CQRS 아키텍처
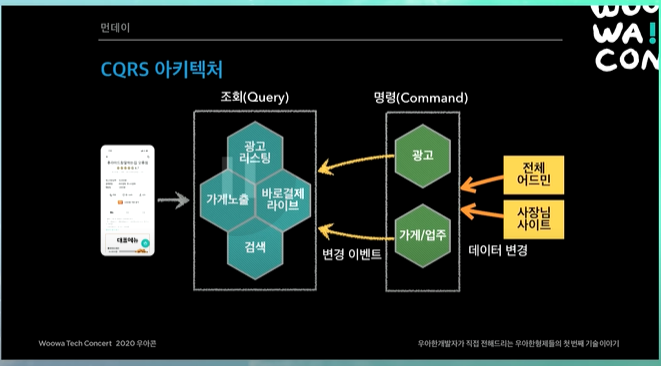
사실 위의 아키텍처보다 시스템이 훨씬 많긴함 ㅎㅎ
광고랑 가게업주 같은 명령형 시스템, 즉 비즈니스 사이드의 시스템을 Command에 놓고, 조회형 시스템 (고객의 트래픽이 앞에서 들어오는 것들)을 Query에 놓음.
사장님 사이트에서 사장님이 가게의 이름이나 데이터를 바꿈. 그러면 가게업주에서 (내부적으로 DB있고) 변경됐다는 이벤트 (SNS, SQS 이벤트)를 쏜다.
이벤트를 쏘면 각 시스템들이 가게 업주의 데이터가 필요하면, 이벤트를 consume해서 조회나 검색에 있는 데이터들을 갱신한다.
이벤트 전파
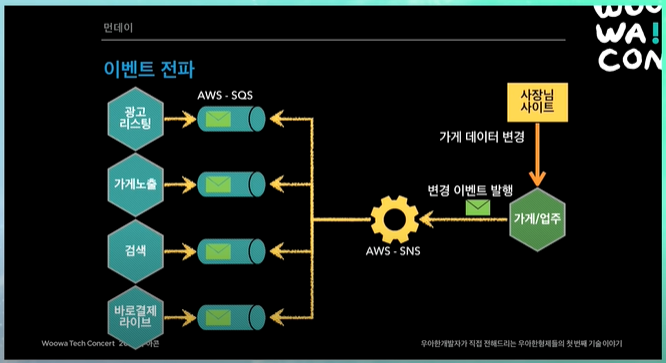
사장님이 가게데이터 변경을 하면, 변경 이벤트를 발행하고, SNS SQS 모델로 이벤트를 싹 전파함.
그러면 해당 시스템에서 "본인의 데이터베이스의" 맞는 곳에 쫙 업데이트를 한다.
그 당시에는 AWS Managed Kafka가 없어서, 그리고 AWS SNS SQS에 대해 노하우가 있어서 이러한 방식을 선택했다.
이벤트 전파와 동기화
- Eventually Consistency (최종적 일관성)
- 이벤트 발행 방식 사용하면, 데이터는 언젠가는 싱크가 다 맞추어진다.
- 데이터 싱크 1초~3초
- 문제 발생시 해당 시스템이 이벤트만 재발행
- 대부분 Zero-Payload 방식 사용
- 이벤트 발행시 이벤트 메시지안에 가게의 모든 데이터를 넣어서 발행하거나, 변경된 데이터들을 다 넣어서 발행할 수도 있음.
- 하지만, 이벤트에 식별자(ex 가게 ID)와 최소한의 정보만 발행
- 이벤트를 받은 시점에 조회 API로 필요한 데이터를 조회해서 저장
Zero-Payload 방식
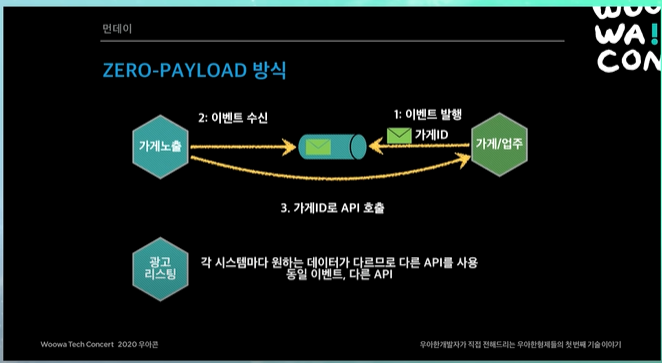
가게에서 이벤트를 발행할 때, 메시지를 다 담아서 보내는 것이 아니라, 딱 가게 ID만 넣어서 보내는 것. 물론 몇가지 정보가 더 들어가기는 함.
이벤트가 발행되었으면, 이벤트를 수신하는 곳에서는, 이벤트안의 가게 ID를 보고, 이 가게의 데이터가 바뀌었구나 하고 위그림의 경우, 가게노출시스템과 가게 업주 시스템에서 서로 합의한 API를 호출한다. 그래서 해당 API의 데이터로 데이터를 채운다.
그러면 왜 변경된 데이터나, 전체 데이터를 채워서 보내지 않음?
-
변경된 데이터만 보내게 되면, 이벤트 순서를 고민해야함.
예를들어, 가게가 연락처를 A라했다가 B로 했다고하자. 그런데 이벤트는 B 다음에 A가 올 수도있다. 이 문제를 해결하려면 할 수는 있는데, 굉장히 많은 고민을 해야한다.
그래서 이걸 고민하지말자, 그냥 이벤트오면 이게 가장 최신이라고 보고, 항상 최신의 데이터를 갱신하자라고 결정.
-
변경된 데이터가 아니라 그냥 전체 데이터를 채워서 보내면 안되나?
각 시스템에서 원하는 데이터가 다 다르다. 가게노출에서 원하는 데이터랑, 광고 리스팅 시스템에서 원하는 데이터가 다르다. 동일 이벤트지만 다른 API를 만들어야한다.
그러면 그냥 모든 데이터 채워서 보내면 되지 않나? ➡ 테이블이 수십갠데 현실적이지 않다.
위의 두가지 문제 해결하기 위해서 딱 가게의 최소정보(거의 가게 ID만 보냄)만 넣어서 이벤트 발행하기로함.
나머지는 보통 common API를 만들어두고, specific한 API를 만든 다음에, 각 시스템들이 회신받은 이벤트면, 항상 API를 호출해서 최신의 데이터를 받아서 각 시스템들(앞단에 있는 시스템들)을 갱신하는 식으로 진행.
데이터 동기화
최소 데이터 보관 원칙
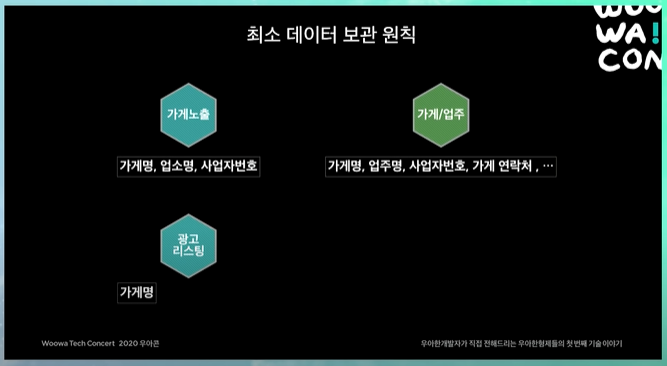
각 시스템들은 모든 데이터들을 보관하면 안되고, 본인에게 꼭 필요한 최소 데이터만 보관한다.
이게 물리적인 의존관계는 없지만, 데이터를 가지고있으면서 논리적인 의존관계가 생김. 그래서 가게 업주에서 무언가 데이터를 바꾸려할 때, 데이터를 다봐야함.
그래서 최소한만 가지고있자 결정을 함.
서비스 자체 데이터 저장소와 동기화
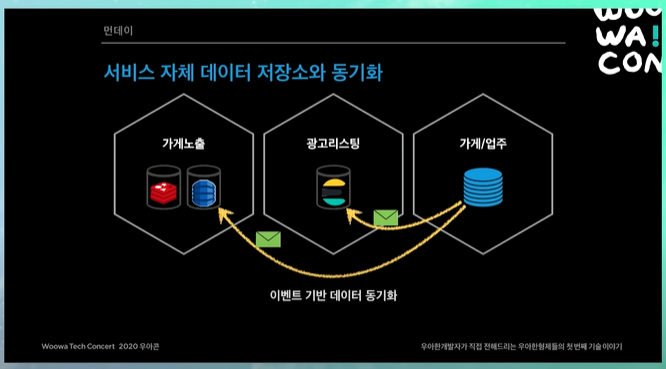
폴리글랏 데이터베이스
각 시스템들은 본인이 최대한 최적화할 수 있는 데이터베이스를 사용할 수 있게 된다.
가게업주는 RDBMS를 쓰고 이벤트를 보내면, 각 시스템들은 성능이 중요한 경우 redis나 dynamoDB를 쓰고, 검색이나 광고리스팅의 경우 ElasticSearch를 쓰는 등 본인의 시스템에 맞는 데이터를 동기화한다.
데이터 저장소
- 조회(고성능)
- 가게노출 : DynamoDB, MongoDB(NoSQL), Redis(Cache)
- 광고리스팅, 검색 : Elasticsearch(검색엔진)
- 바로 결제 라이브 : Redis(Cache)
- 명령(안정성)
- 광고 : 오로라DB(RDB) - 참고로 오로라 DB는 AWS에서 제공되는 MySQL 호환되는 DB
- 가게/업주 : 오로라DB(RDB)
쿼리모델 데이터베이스
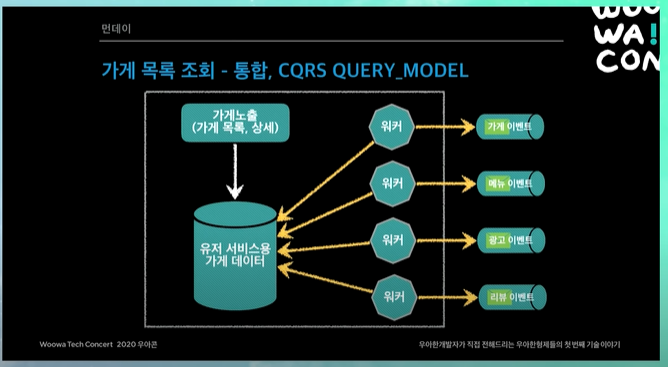
가게 노출 시스템이라는 것이 쿼리 모델로 되어있음.
이벤트들이 배달의 민족 상세화면 보면, 리뷰, 가게 상세, 메뉴 등등 데이터가 엄청 많음. 이것들을 빠르게 조회해야함.
뒷단에서 여러 시스템들로부터 이벤트들이 오면, 그거를 가게노출 시스템에서 키를 가게ID로 하고, 값을 그 데이터들로해서, 한줄로 집어넣음. 그래서 가게 ID만 넣으면 해당 상세 화면에 필요한 데이터들을 fit하게 맞추어 뿌릴 수 있게. (내가 네이버 인턴하면서 봤던 형식처럼 넣어놓는듯)
이런 식으로 데이터를 flat하게 만들어놓음. 이런식으로 가게 데이터를 관리하는 것이 쿼리 모델.
가게 목록 조회 - 통합, CQRS Query Model
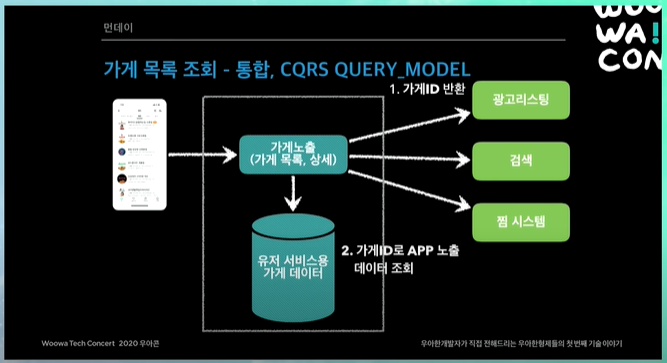
이렇게 해서 얻는 장점?
광고를 보거나, 검색을 하거나, 찜 리스트를 보거나, 이런 뒷단의 시스템들은 단순히 가게 ID만 반환해주면 됨. 물론 몇가지 데이터를 좀더 반환해주기는 함.
그러면 예를들어서 가게 리스트의 검색결과가 25개 정도 나왔다고 하자. 그러면 25개의 가게 ID만 반환해주는 것. 그러면 25개의 가게ID를 가지고 가게 노출시스템은 본인의 데이터베이스를 찔러봄.
그러면 위에서 말했듯이, 데이터가 flat하게 key value로 되어있음. 25개를 key value로 굉장히 빠르게 조회한 다음에 ID에다가 value를 씌움. 그래서 앱에서 렌더링할 수 있게 데이터를 씌운다음에 내보낸다.
가게 상세 조회 - 비동기 (논블러킹)
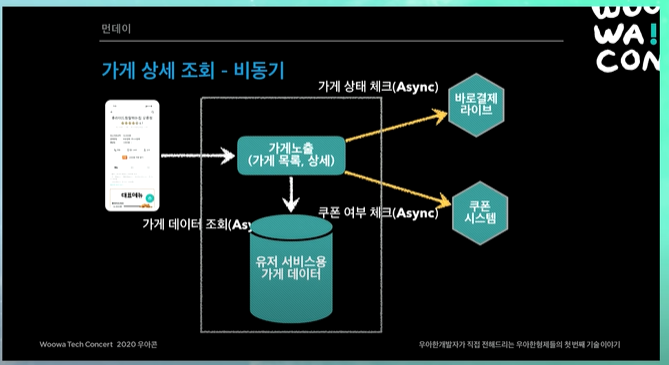
가게 상세의 경우 모두 비동기 넌블로킹으로 되어있음. 따라서 세가지 시스템을 한번에 비동기 넌블로킹으로 조회하게 됨
CQRS 아키텍처 장점
트래픽 처리 (성능)
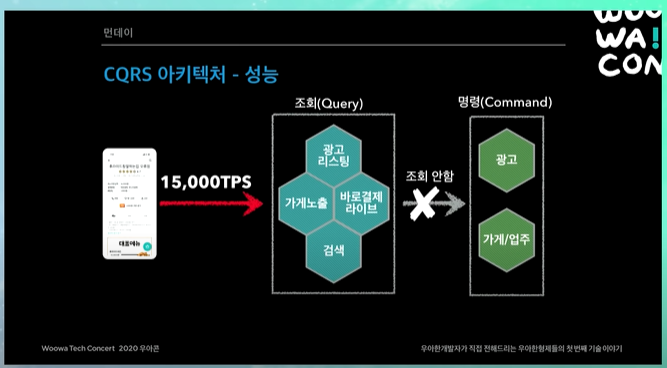
CQRS로 바뀌고 나서는 트래픽이 들어오고 나면 뒷단을 아예 호출하지 않음.
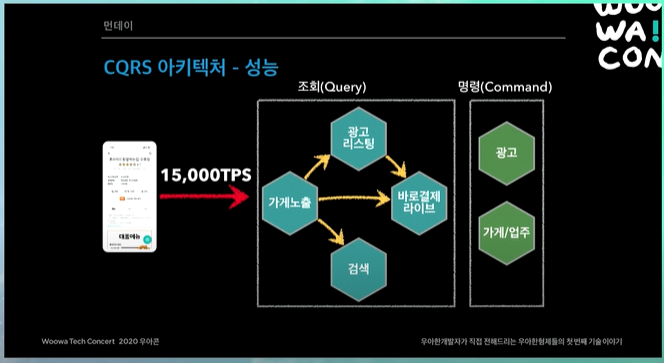
그래서 트래픽이 들어와도, 조회용 쿼리와 관련된 시스템들만 트래픽을 받으면 된다.
장애 격리
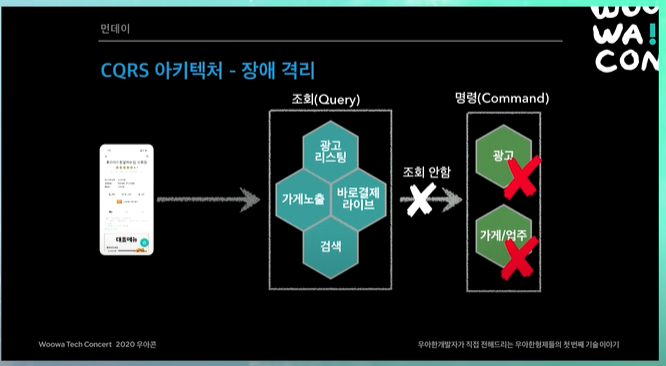
광고나 가게업주 시스템이 죽어도, 장애가 격리되고, 고객은 주문까지 넘어갈 수 있다. 물론 주문이 죽으면 그건 안됨 ㅋㅋ
- 각 시스템이 내부에 필요한 데이터를 보관
- 내부 서비스(광고, 검색)의 모든 변경 내역이 이벤트로 전달
- 장애시 데이터 싱크가 늦어져도 고객 서비스 가능
데이터 싱크 장애 대응
데이터 싱크할 때 장애가 나면 어떡하지?
- 이벤트 재발행
- 큰 문제가 없으면 그냥 이벤트 재발행 하면됨
- 원천데이터를 가지고있는 팀에서 이벤트를 재발행해주면 된다.
- 큐 장애 발생시 (SQS, SNS 자체 장애일시, 가끔 있다.)
- 전체 IMPORT API 제공
- 부분 IMPORT API 제공
- 최근 업데이트 데이터를 분 단위로 부분 제공
기타
- 적극적인 캐시 사용
- 서킷 브레이커
- 비동기 Non-Blocking 시스템 적용
- 스프링 WebFlux, Reactor(RxJava 유사)
- 가게노출, 광고리스팅, 검색
정리
- 배달의 민족 시스템은 거대한 CQRS
- 성능이 중요한 고객 접점의 외부 시스템과
- 비즈니스 명령이 많은 내부 시스템으로 분리
- 이벤트 발행을 통한 Eventually Consistency(최종적 일관성)
- 각 시스템은 API 또는 이벤트 방식으로 연동
- 모든걸 이벤트로하면 좋지않냐?
- 현실적으로 그렇게는 할 수 없음
- 예를들어 사장님이 짜장면을 짬뽕으로 다 바꿈. 메뉴의 이름이 바뀐다.
- 이벤트 발행의 경우 어쨌든 Eventually Consistency 하지만, 싱크가 맞는 시간이 있기 때문에 완벽하게 다 맞을 수 없음.
- 그래서 주문 직전에 이를 validation하는 API 호출함.
- 고객이 짜장면 주문하려했는데 이거 맞나요? 하는 API를 호출해서 검증
- 만약에 그런데 이 검증 API가 타임아웃이 나거나 문제가 생기면? 그럼 어떻게할거야? 아니면 메뉴시스템이 잠깐 죽었다 치면 어떻게 할거야? validation을 못하는데.
- 이때는 데이터를 보고 개발이랑 기획이랑 같이 논의를 한다.
- 이 API가 정말 중요한가. 짜장이 짬뽕으로 들어갈 수 있다. 그런데 이런 경우 거의 없다. 있다하더라도 고객 입장에서 크게 피해가 가지않기 때문에 (사장이 메뉴 이름 바꾸는 경우도 굉장히 적고), 이러한 경우는 그냥 회사에서 비용을 보상을하고, 문제가 생기는 경우에 전체 주문이 안되는 것보다는 API에 대해서 무조건 참이라는 값으로 callback을 하자. 이런식으로 결정.
- 이런식으로 API를 어쩔 수 없이 쓸 데가 있는데 이때는 어떻게 callback을 할 것인지 결정을 한다.
먼데이 이후 (2019년 4월1일 - 위, 11월 1일 -아래)
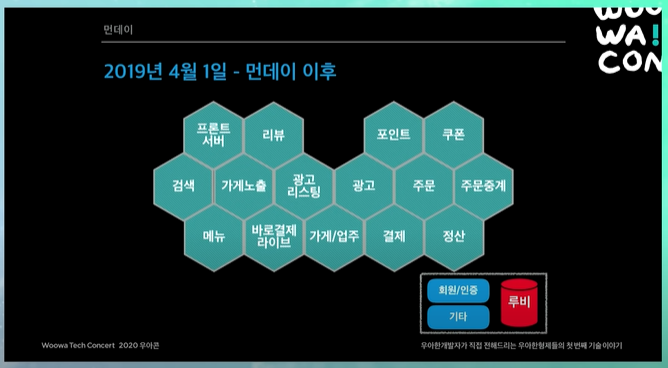

전체 서비스들이 모놀리틱한 레거시 시스템에서 다 떨어져나옴
마지막 한마디
꼭 마이크로 서비스를 해야하나요?
이게 규모의 경제가 되어야 할 수 있다. 시스템 규모도 되야하고, 트래픽도 되야하고, 사람도 많아야한다.
정말 단순하게 생각해보면, 기존에는 테이블 조인하나 하면될 걸, 데이터 싱크 하고 맞추고 하면 비용이 10배정도는 더듦. 그런 것들을 상쇄하고 남을만큼의 가치가 있는경우에 마이크로 서비스로 넘어가는 것이 좋다.

4개의 댓글


Whether you're a fan of old-school arcade games or classic console titles, there's something for everyone. So get ready to take a trip down memory lane and play your favorite retro games online!

잘 읽었습니다. 좋은 글 감사합니다^^