데이터 적재
: 원본 데이터 소스에서 데이터를 추출하여 최종 목적지에 데이터를 옮겨 싣는 과정. 이 후, 데이터가 적재되면 본격적으로 분석 작업 등이 일어난다.
널리 알려진 적재 툴 또는 방법:
- Amazon Redshift
- Snowflake
- 데이터 레이크 (비정형화된 데이터)
Amazon Redshift
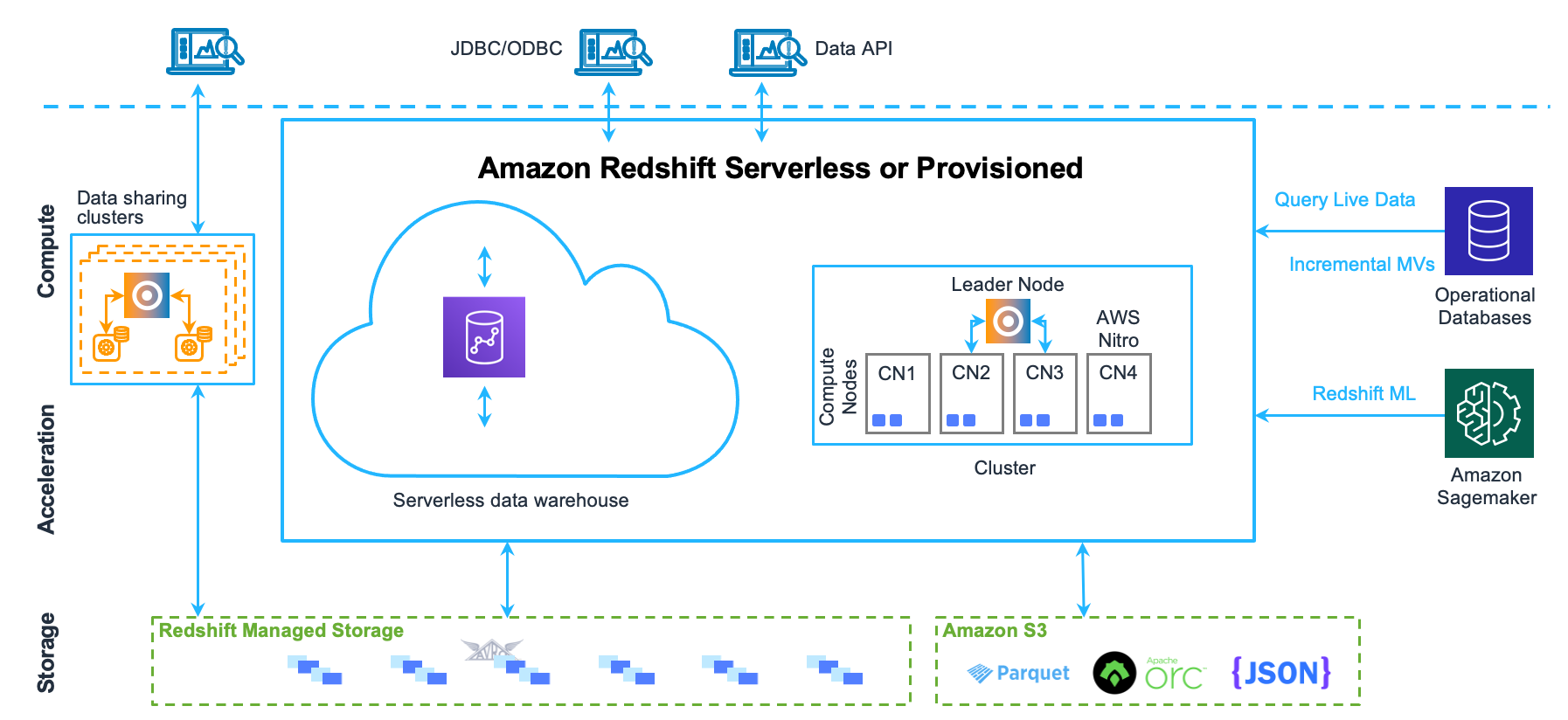
: Amazon에서 관리하는 페타바이트급 데이터 웨어하우스 서비스. 다음과 같은 특징 덕분에 널리 쓰이고 있다.
- 페타바이트급 빅데이터를 관리하고 처리할 수 있는 MPP (Massive Parallel Procssing) 아키텍처 채택
- AWS에서 자체적으로 백업, 패치 관리, 복원 기능 등 제공 (완전 관리형 서비스)
- 칼럼 기반 데이터베이스 (향상된 데이터 압축 비율)
- 다른 AWS 서비스와의 연동성
AWS Redshift에 연결하기:
1. AWS Redshift Serverless 생성 (일반 클러스터는 비용이 무지막지함…)
2. 작업 그룹 생성 후, 퍼블릭 액세스 허용
3. 보안 그룹에서, 규칙 추가 후 인바운드 규칙 유형을 Redshift로 설정 후, 0.0.0.0/0 선택
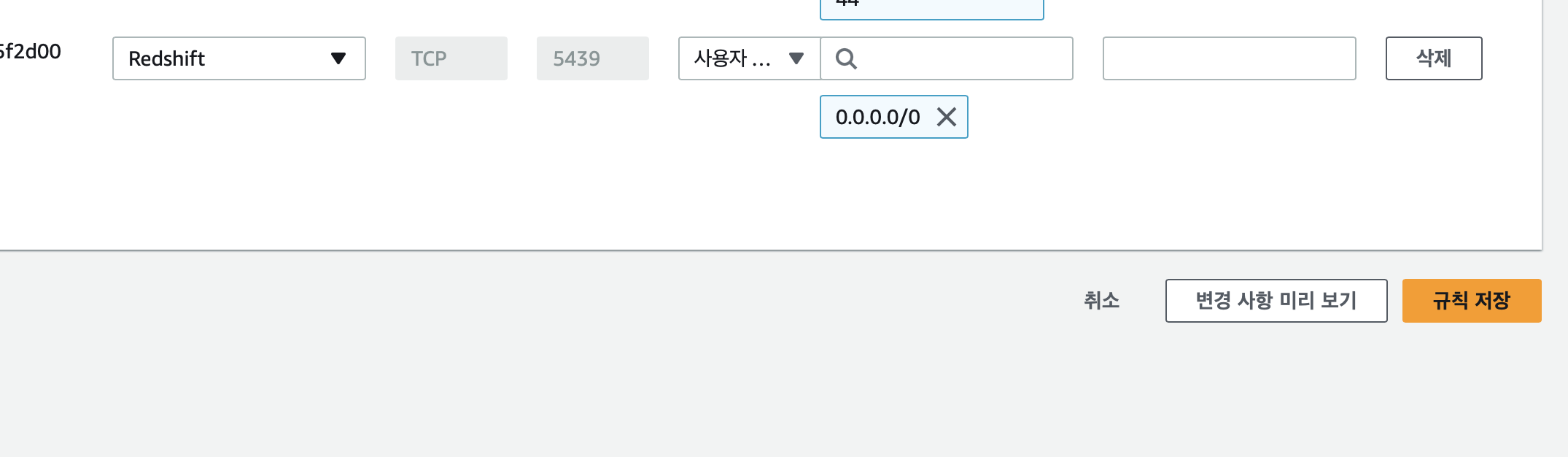
: 이걸 안하면 나중에 Redshift에 연결을 시도할 때 Connection Time out 에러가 발생한다.
4. pipeline.conf에 Redshift 관련 내용 기입
[aws_creds]
database = dev
username = ~~~
password = ~~~
host = ~~~~~.ap-northeast-2.redshift-serverless.amazonaws.com
port = 5439데이터를 원본 데이터 소스로부터 추출되었으면, S3 같은 임시 저장소에 데이터가 저장되어있으므로, 이를 최종 목적지에 실어야 한다. (여기서는 Redshift)
⇒ S3에 쿼리를 실행하여 S3의 데이터를 Redshift에 적재해야 한다.
- 전체 추출: TRUNCATE를 통해 Redshift의 기존 데이터들을 제거하고, 새로운 데이터로 적재
- 중분 추출: 업데이트 된 데이터들을 COPY하여 Redshift에 적재
⇒ 이 경우, 같은 ID지만 다른 내용들이 다르므로 어떤 레코드가 최신인지 파악해야 한다.
5. Redshift Cluster에 연결
parser = configparser.ConfigParser()
parser.read("../pipeline.conf")
dbname = parser.get("aws_creds", "database")
user = parser.get("aws_creds", "username")
password = parser.get("aws_creds", "password")
host = parser.get("aws_creds", "host")
port = parser.get("aws_creds", "port")
rs_conn = psycopg2.connect(
"dbname=" + dbname
+ " user=" + user
+ " password=" + password
+ " host=" + host
+ " port=" + port
)6. S3 → Redshift Cluster에 데이터 복제
file_path = ("s3://"
+ bucket_name
+ "/order_extract.csv")
role_string = ("arn:aws:iam::"
+ account_id
+ ":role/" + iam_role)
sql = "COPY public.Orders"
sql = sql + " from %s "
sql = sql + " iam_role %s;"
cur = rs_conn.cursor() # Redshift Cluster용 Cursor
cur.execute(sql,(file_path, role_string)) # Redshift Cluster 내에서 명령을 실행하여
# S3 버킷에 임시 적재된 데이터를 Redshift Cluster에 최종 적재한다.
cur.close()
rs_conn.commit() #트랜잭션 커밋
rs_conn.close(): S3 버킷의 정보를 기입한 다음, Redshift Cluster에 연결된 cursor을 통해 쿼리를 실행한다.
데이터 증분 및 전체 로드
: 데이터가 변경되어 해당 레코드를 업데이트해야 해야할 경우, 이전의 추출 처럼 전체 또는 증분 로드하는 방법이 있다.
데이터가 어떻게 추출되었느냐에 따라 전체 로드 또는 증분 로드를 택해야 한다.
전체 로드
: 만일 데이터가 전체 추출되었을 경우, 기존 데이터 웨어하우스의 데이터를 삭제한 후 새로운 데이터를 적재한다. 이 경우, TRUNCATE를 통해 데이터 형식은 유지하면서 내용은 제거한다.
...
sql = "TRUNCATE public.Orders"
cur = rs_conn.cursor()
cur.execute(sql)
cur.close()
rs_conn.commit()
file_path = ("s3://"
+ bucket_name
+ "/order_extract.csv")
...
⇒ 위의 추가된 명령어는 새로운 데이터로 대체 하기 전, 기존의 내용을 제거하고 새로운 내용으로 대체한다. 데이터를 덮어씌우는 과정은 매우 복잡하기 때문에, 새롭게 제거 후 대체하는 것이다.
증분 로드
: 데이터가 증분 추출 되었을 경우, 만일 위의 TRUNCATE 명령어를 그대로 사용한다면 기존의 과거 내용은 모두 사라지고 변경사항만 남게 된다.
따라서, COPY 명령어를 사용하여 증분 추출된 레코드를 적재한다.
sql = "COPY public.Orders"
sql = sql + " from %s "
sql = sql + " iam_role %s;"
cur = rs_conn.cursor() # Redshift Cluster용 Cursor
cur.execute(sql,(file_path, role_string)) # Redshift Cluster 내에서 명령을 실행하여
# S3 버킷에 임시 적재된 데이터를 Redshift Cluster에 최종 적재한다.
cur.close()
rs_conn.commit() #트랜잭션 커밋
rs_conn.close()증분 추출된 데이터를 중분 로드할 경우, 다음과 같이 레코드가 업데이트 된다.
| OrderId | OrderStatus | LastUpdated |
|---|---|---|
| 1 | Backordered | 2020-06-01 12:00:00 |
| 1 | Shipped | 2020-06-09 12:00:25 |
⇒ 파이프라인의 변환 단계에서 각 레코드의 변화 기록들을 알 수 있으므로, 이렇게 모두 가지는 것이 매우 이상적인 상황이다.
CDC 로그에서 추출한 데이터 로드
: CDC 로그의 경우, 트랜잭션 로그에 해당하므로 데이터의 삽입 및 수정, 그리고 삭제된 로그 까지 포함하고 있다.
insert|1|Backordered|2020-06-01 12:00:00
update|1|Shipped|2020-06-09 12:00:25
delete|1|Shipped|2020-06-10 09:05:12⇒ delete의 경우 레코드가 업데이트 되고 다음 날에 삭제되었음을 보여준다.
이렇게 insert, update, delete 등, 레코드의 이벤트 유형은 CDC로그에는 있으나, 전체 또는 증분 추출의 경우 이 항목이 존재하지 않는다.
따라서, 열 기반 데이터 웨어하우스 (Redshift 등) 의 경우, 이 항목을 추가해야 한다.
| EventType | OrderId | OrderStatus | LastUpdated |
|---|---|---|---|
| insert | 1 | Backordered | 2020-06-01 12:00:00 |
| update | 1 | Shipped | 2020-06-09 12:00:25 |
| delete | 1 | Shipped | 2020-06-10 09:05:12 |
데이터 레이크를 파일 스토리지로 사용
: Redshift 등의 정형화된 데이터 웨어하우스를 사용하는 것이 아닌, 데이터 레이크를 최종 파일 스토리지로 사용할 수 있다.
이점:
- 비정형화된 데이터 저장이므로 비용 절감
- 최근 들어 데이터 레이크의 데이터 쿼리에 더 쉽게 접근할 수 있고 분석을 도와주는 도구 등장
- Amazon Athena: S3에 저장된 데이터를 쿼리할 수 있는 AWS 서비스
- Amazon Redshift Spectrum: Redshift가 S3에 외부 테이블로 엑세스하고 이를 참조할 수 있록 하는 서비스
- 미리 정의된 스키마가 없어 저장된 데이터의 유형이나 속성을 변경하는데 용이함.

좋은 글이네요. 공유해주셔서 감사합니다.