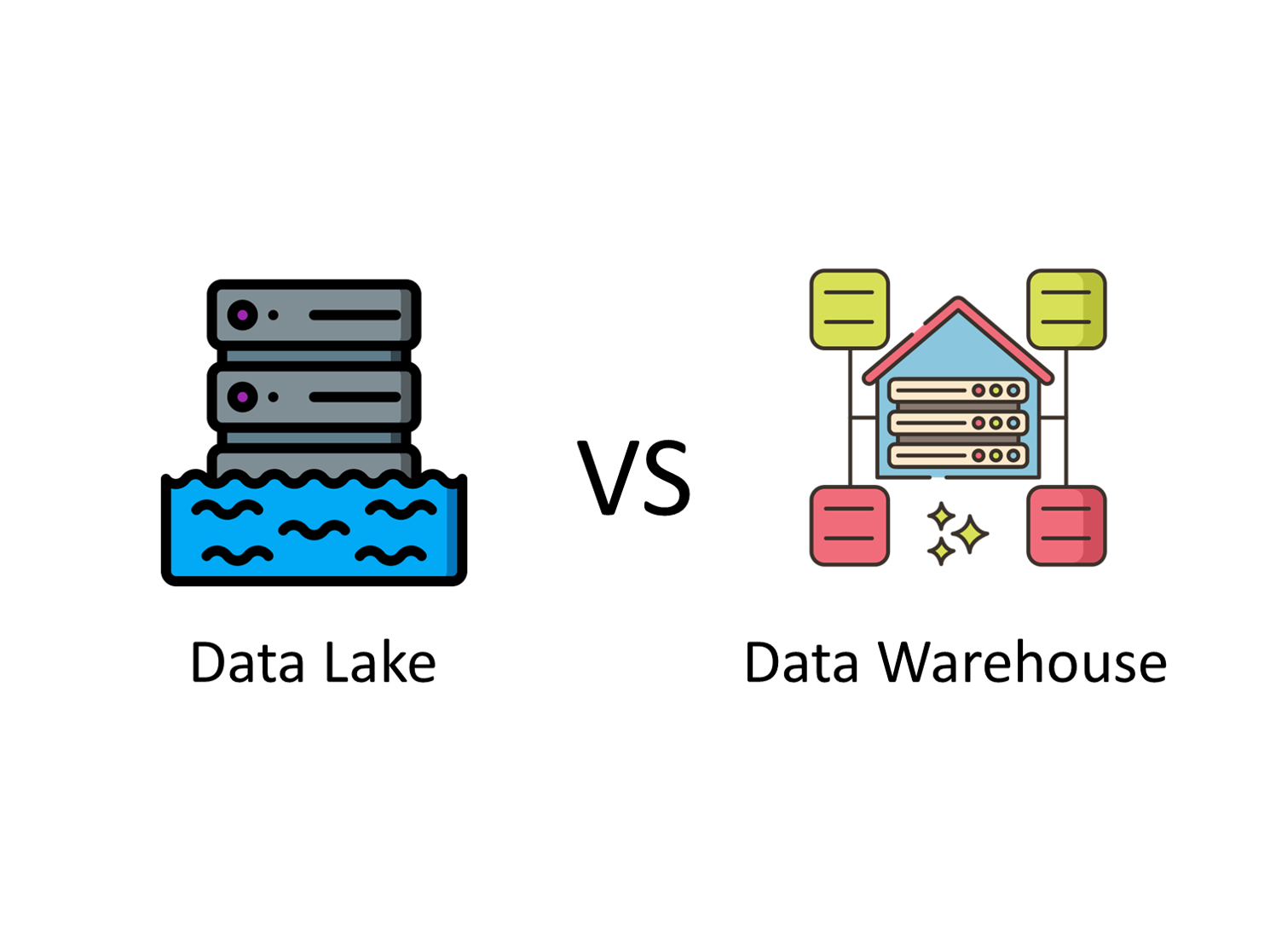
호수에 데이터가 둥둥 아무렇게나 띄워지느냐 vs 우리집 마냥 정리가 잘되어 있느냐
데이터 파이프라인이란?
데이터 파이프라인 : 다양한 소스에서 새로운 가치를 얻을 수 있는 대상으로 데이터를 옮기고 변환하는 일련의 과정
- 복잡성 : 데이터의 복잡성과 크기, 상태에 따라 파이프라인의 복잡성이 결정됨
- 가장 단순한 파이프라인 : RESTful API에서 그대로 데이터를 불러와 SQL 등에 로드
cf) Amazon S3 (Simple Storage Service) : 객체에 대한 컨테이너 서비스 (버킷 : S3에 저장된 객체 컨테이너)
- 대규모의 비정형 데이터를 비용 효율적으로 안전하게 저장 할 때
- 라이프사이클 관리, 권한 관리, 백업 및 배포, 대규모 배포 등의 다양한 기능이 필요할 때
⇒ 빅 데이터 분석, 데이터 백업, 대규모 배포 시 사용된다.
데이터 파이프라인은 왜 필요한가?
- 모든 정제되고 깔끔한 대시보드 등의 뒤에는 데이터 파이프라인이 존재
- 정제되지 않은 지저분한 데이터를 가공하는 것이 데이터 파이프라인
데이터 레이크 VS 데이터 웨어하우스
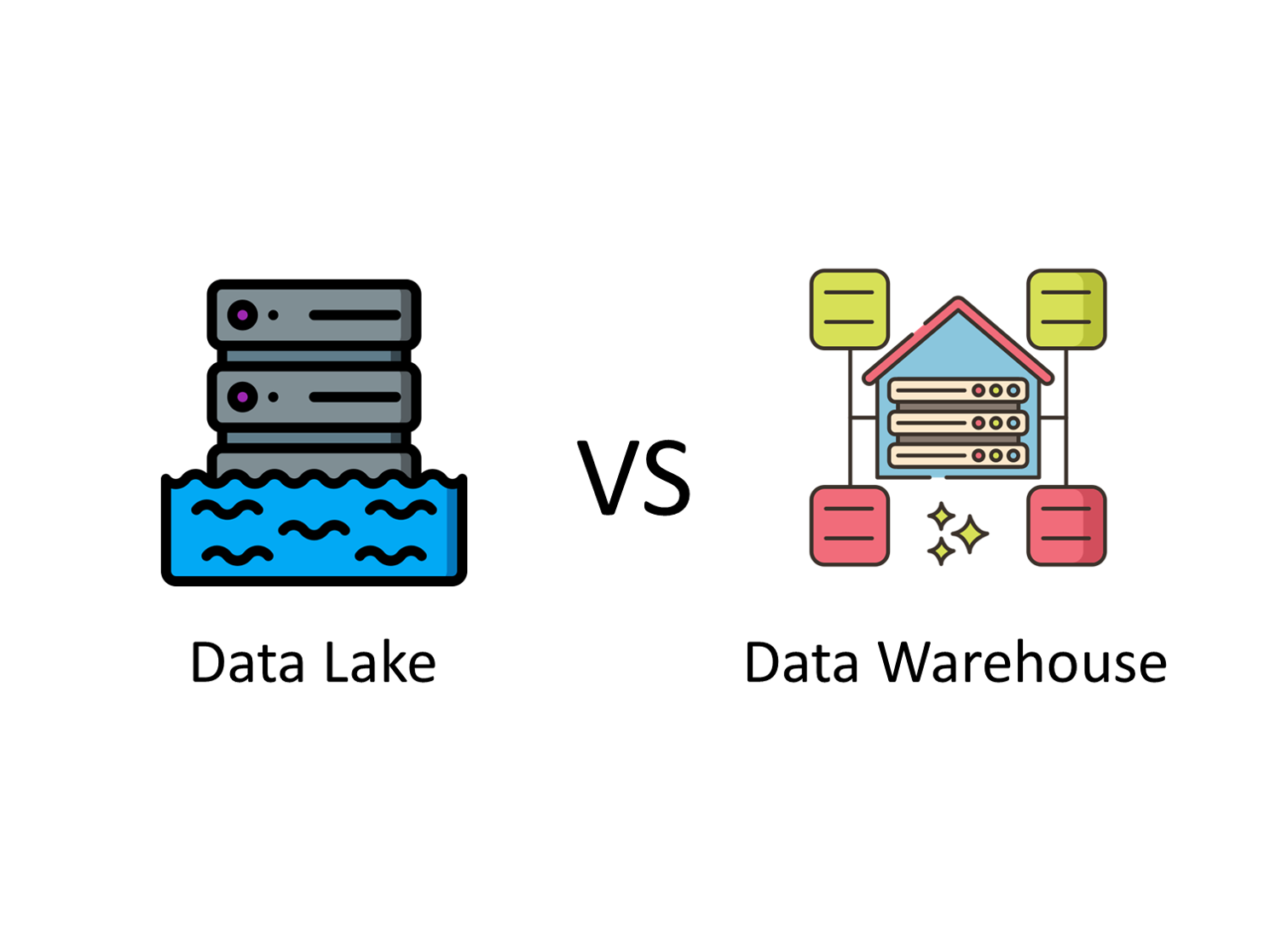
데이터 웨어하우스 : 사용자가 원하는 질문에 대답할 수 있는 데이터 분석 활동을 지원하기 위해 서로 다른 시스템의 데이터가 모델링되어 저장되는 DB
데이터 레이크 : 웨어하우스와 달리 데이터가 정제될 필요가 없는 곳.
워크플로우 오케스트레이션 플랫폼
: 파이프라인에서 작업의 스케줄링 및 흐름을 관리해줌. 이 때 주로 사용하는 구조가 방향 비순환 그래프 (DAG).
DAG (Directed Acyclic Graph) : 방향성 비순환 그래프
- 파이프라인은 항상 작업의 순서가 존재하기 때문에 각 단계는 방향성을 지님
- 비순환 그래프. 이전에 완료된 작업을 다음 작업이 가리킬 수 없다.
ETL, ELT
: 데이터 웨어하우징 및 비즈니스 인텔리전스에서 널리 사용되는 패턴
기본적인 패턴
- 추출 (Extract) : 다양한 소스에서 데이터 수집
- 로드 (Load) : 원본 데이터(ELT) 또는 완전히 변환된 데이터(ETL)을 최종 대상으로 가져옴
- 변환 (Transform) : 모든 사례에 유용하게 쓸 수 있도록 데이터를 결합하고 형식을 지정
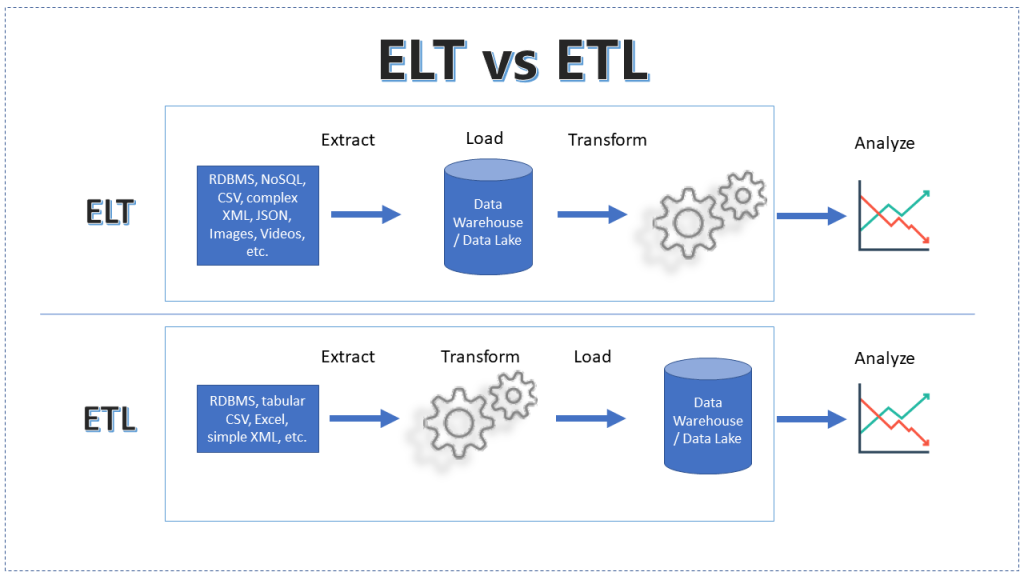
행 기반 데이터 웨어하우스 VS 열 기반 데이터 웨어하우스
- 행 기반 : 소규모 데이터 처리 (온라인 트랜잭션 처리 등의 속도가 매우 중요한 작업)
- 열 기반 : 대규모 데이터 처리 (데이터 대규모 분석)
⇒ 블럭 단위로 처리할 때 행 기반 DB는 한 객체의 모든 정보가 다 담겨있는 반면, 열 기반 DB는 각 속성에 대한 객체들의 속성 값들이 모두 담겨 있다.
ELT의 등장
- ETL은 데이터가 추출되고 변환을 하고, 그 변환된 데이터를 적재하는 모든 과정에 엔지니어가 필요
- ELT는 엔지니어가 데이터를 추출하고 적재하는 과정에만 집중하면 됨. 해당 데이터는 분석가가 분석 용도로 데이터를 변환할 수 있기 때문.
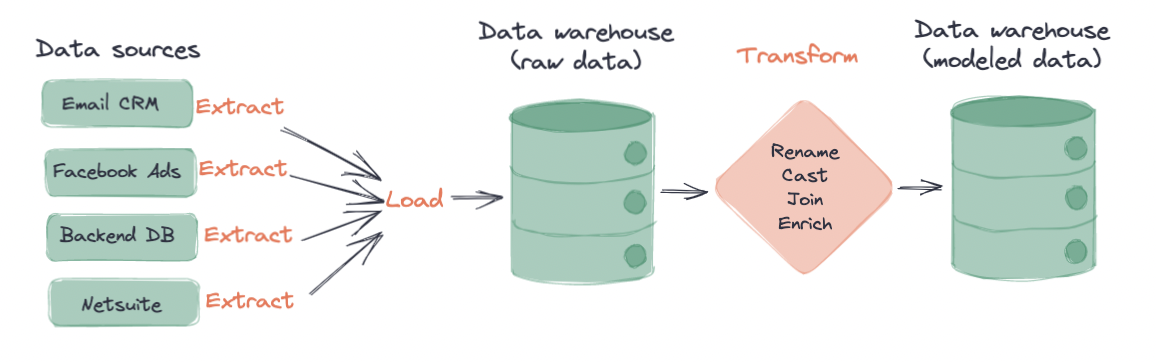
ELT 기반 파이프라인은 Transform (변환) 단계가 마지막에 있으므로, 적재된 데이터를 다양한 용도에 따라 자유롭게 변환이 가능하다.
- 데이터 분석을 위한 ELT
- 데이터 과학을 위한 ELT
- 머신러닝을 위한 ELT
- 분석 Pipeline VS 머신러닝 Pipeline
- 분석 Pipeline은 변환 단계에서 데이터 모델을 변환하는 데에 중점을 둠
- 머신러닝 Pipeline은 데이터들을 웨어하우스 또는 레이크에 적재하면 머신러닝 모델을 빌드하고 업데이트하는 것과 관련된 여러 단계가 존재
- ML Pipeline 단계
- 데이터 수집
- 데이터 전처리 : 데이터를 정리하고 모델에 사용할 준비를 함 (텍스트 토큰화, 기능 숫자값 변환)
- 모델 교육
- 모델 배포 : 배포된 모델의 쿼리를 허용할 때 REST API 사용 등 배포는 많이 까다로운 작업
- 분석 Pipeline VS 머신러닝 Pipeline

Engineer, to be a Pioneer.