
들어가며
면접 때 요청에 따른 Spring과 Node.js의 응답 처리 방식의 차이에 관한 질문이 있었는데, 일단 아는대로 설명하다 깊숙하게 들어가니 정말 영혼까지 털렸다. 마지막에 결국 정답에 도달하긴 했지만, 어느정도 안다고 생각한 나의 착각에 대한 부끄러움을 좀 더 간직하기 위해 글을 남기고자 한다.
요청과 응답
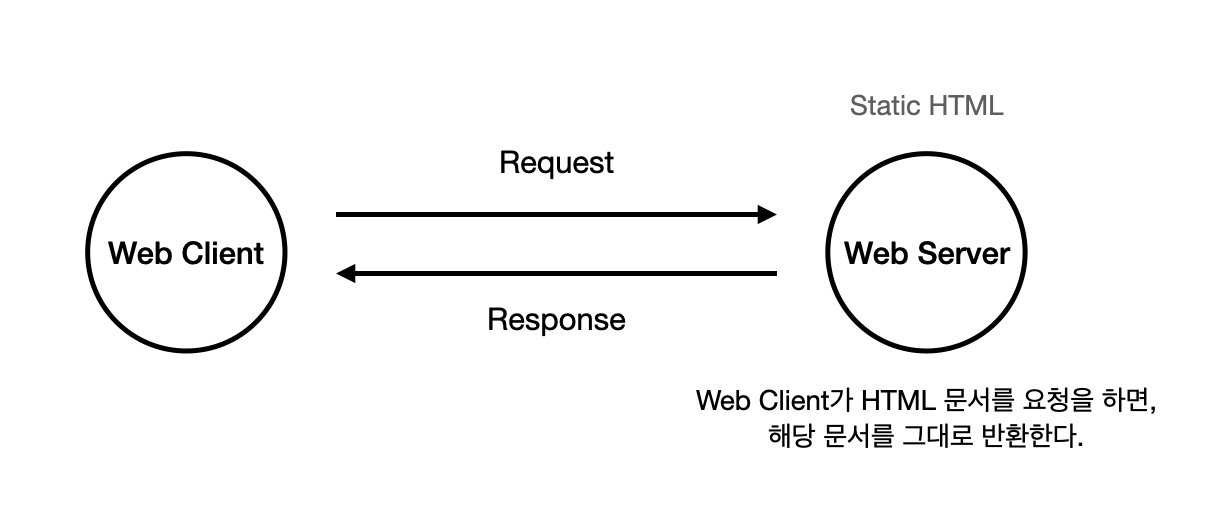
일반적으로 사용하고자 하는 프레임워크가 Spring이든, Node.js 든 무엇이든 간에 요청에 대한 응답은 다음과 같다.
사용자가 요청한 페이지가 딱히 어떤 처리를 한 후에 반환할 필요없이, 그냥 있는 HTML 문서를 반환하기만 하면 굳이 Web Component를 거쳐 응답을 할 필요가 없다. 웹 서버 (Web server)가 이 역할을 대신하기 때문이다. 즉, 서버에 있는 정적인 HTML 문서 만을 반환하는 것이 목적이라면 비즈니스 로직이 딱히 필요가 없다.
그러나, 예를 들어 사용자가 로그인을 한 후라고 가정해보자. 서버 입장에서는 로그인한 사람이 누구인지를 표시해야 하는데, 정적인 페이지만을 반환하는 웹서버에서는 HTML문서를 수정할 수가 없다.
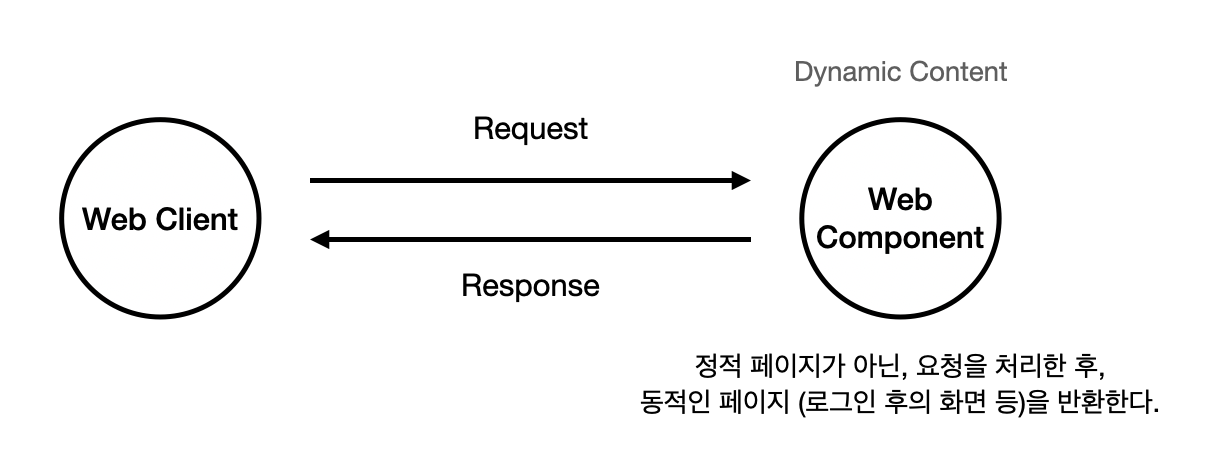 이 때, 이런 로직을 처리하는 방법은 프레임워크마다 다르다. 가장 대표적인 프레임워크 Spring과, Node.js 런타임에서 이를 처리하는 방법을 비교해보자.
이 때, 이런 로직을 처리하는 방법은 프레임워크마다 다르다. 가장 대표적인 프레임워크 Spring과, Node.js 런타임에서 이를 처리하는 방법을 비교해보자.
Spring
Spring에 대해 얘기하기 전, 이 Web Component가 작동하기 위해서는 이를 관리해주는 또 다른 구성요소가 있어야 한다. 이를 Web Container이라고 한다.
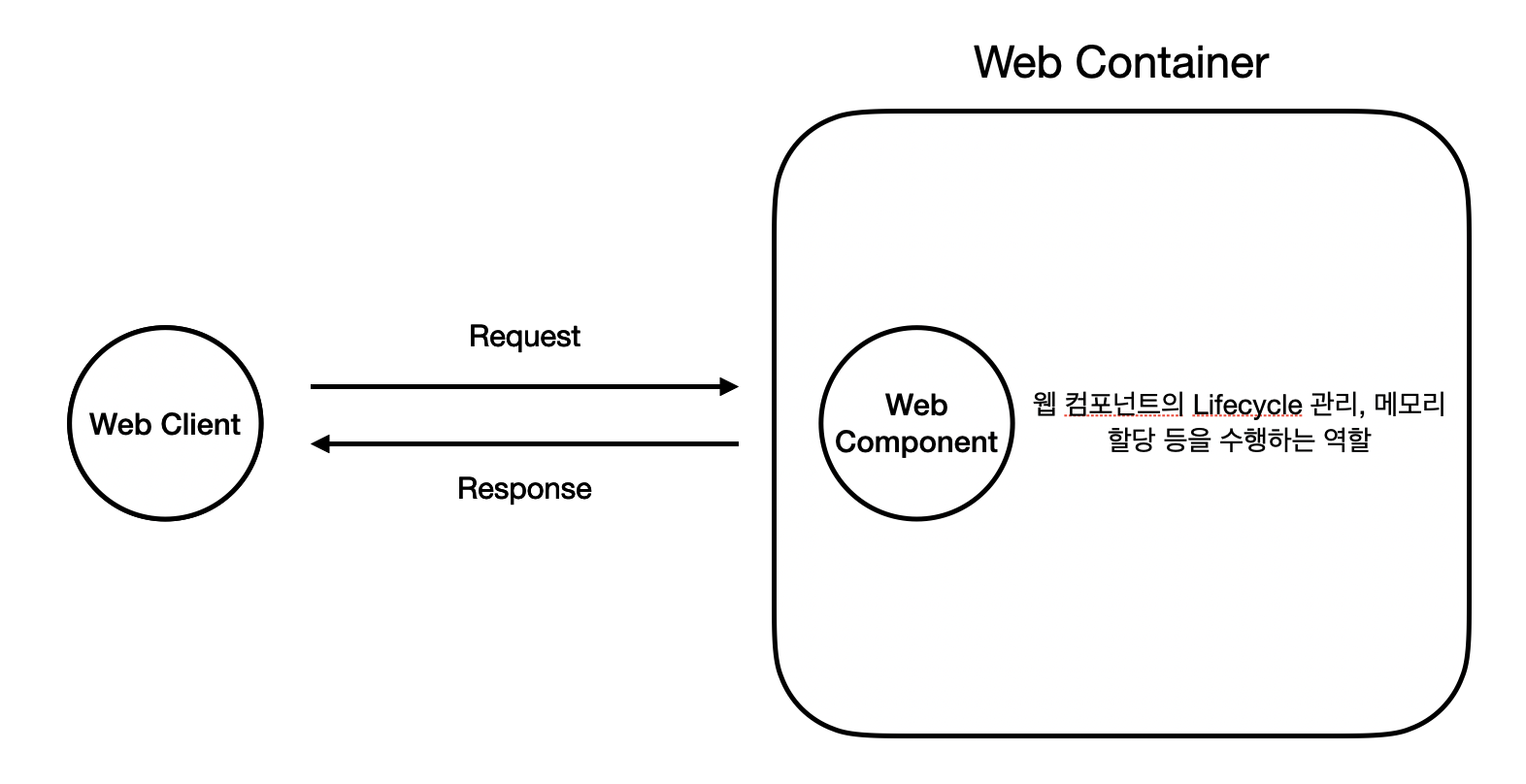 Web Container의 역할은 다음과 같다.
Web Container의 역할은 다음과 같다.
- Web Component의 생명 주기 (생성, 삭제 등 ) 를 관리한다.
- Web Client가 보낸 요청에 따라 알맞은 Web Component에게 할당 (Handling)을 한다.
- 흔히 이를 라우팅 (Routing) 이라고 한다.
자, 이 그림을 글자만 바꿔서, Spring을 좀 해본 사람들에게 익숙한 그림으로 바꿔보겠다.
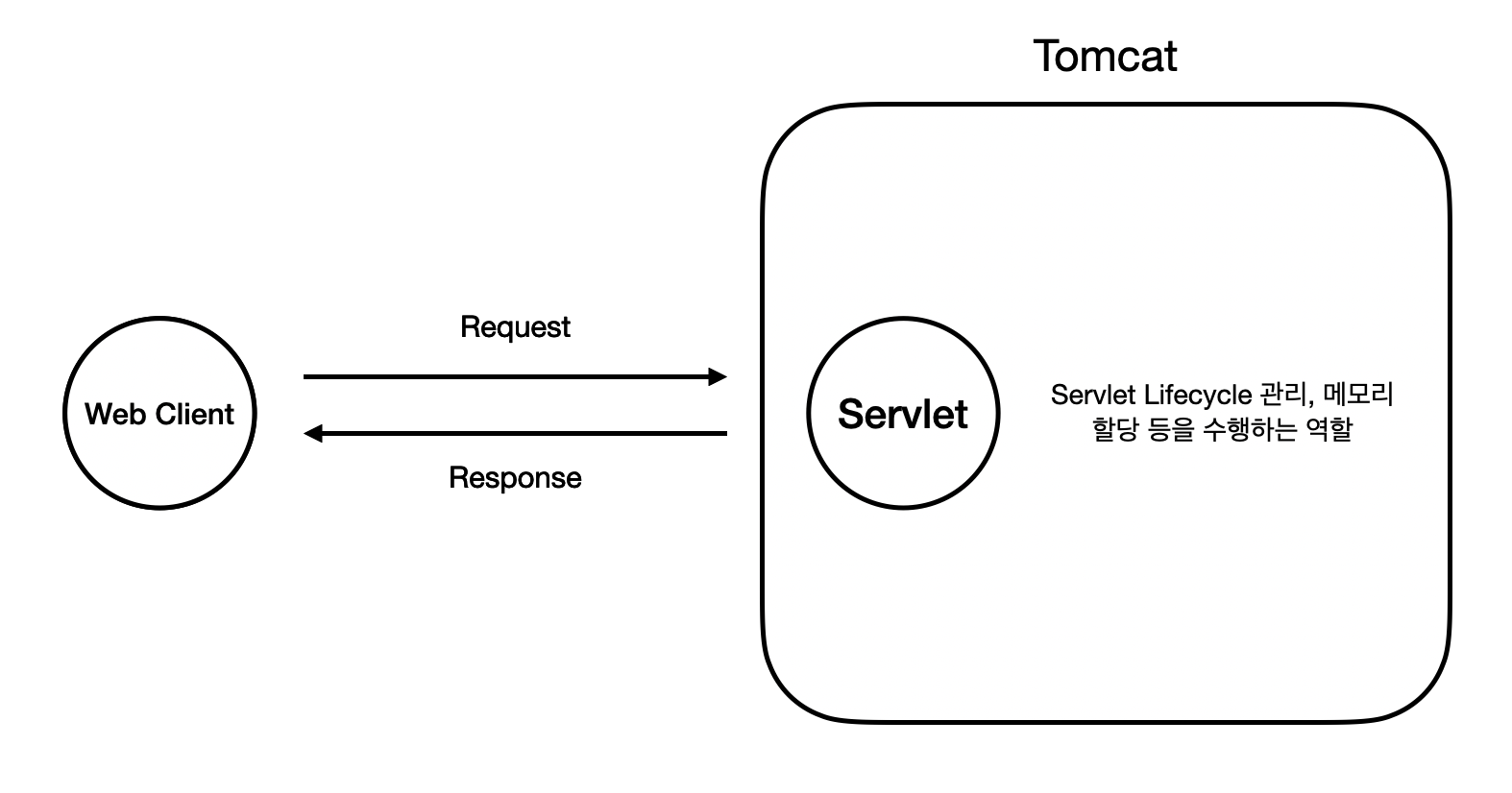 이제 좀 익숙하지 않은가?
이제 좀 익숙하지 않은가?
Spring은 이렇게 요청에 따른 동적 처리를 해주는 Web Component를 "Servlet" 이라고 칭했다. 그리고 이런 Web Container를 "Servlet Container"라고 이름을 지었다.
그리고 이 Servlet Container를 구현하는 가장 대표적인 구현체가 바로 "Tomcat" 이다. (물론 Tomcat 말고도 다른 Servlet Container의 구현체들이 있다.) Tomcat은 이렇게 동적인 처리를 해주는 Servlet들을 전체적으로 관리하는 역할을 수행한다. 즉, 일반적인 서비스의 Tomcat과 Servlet은 다음과 같이 생겼다.
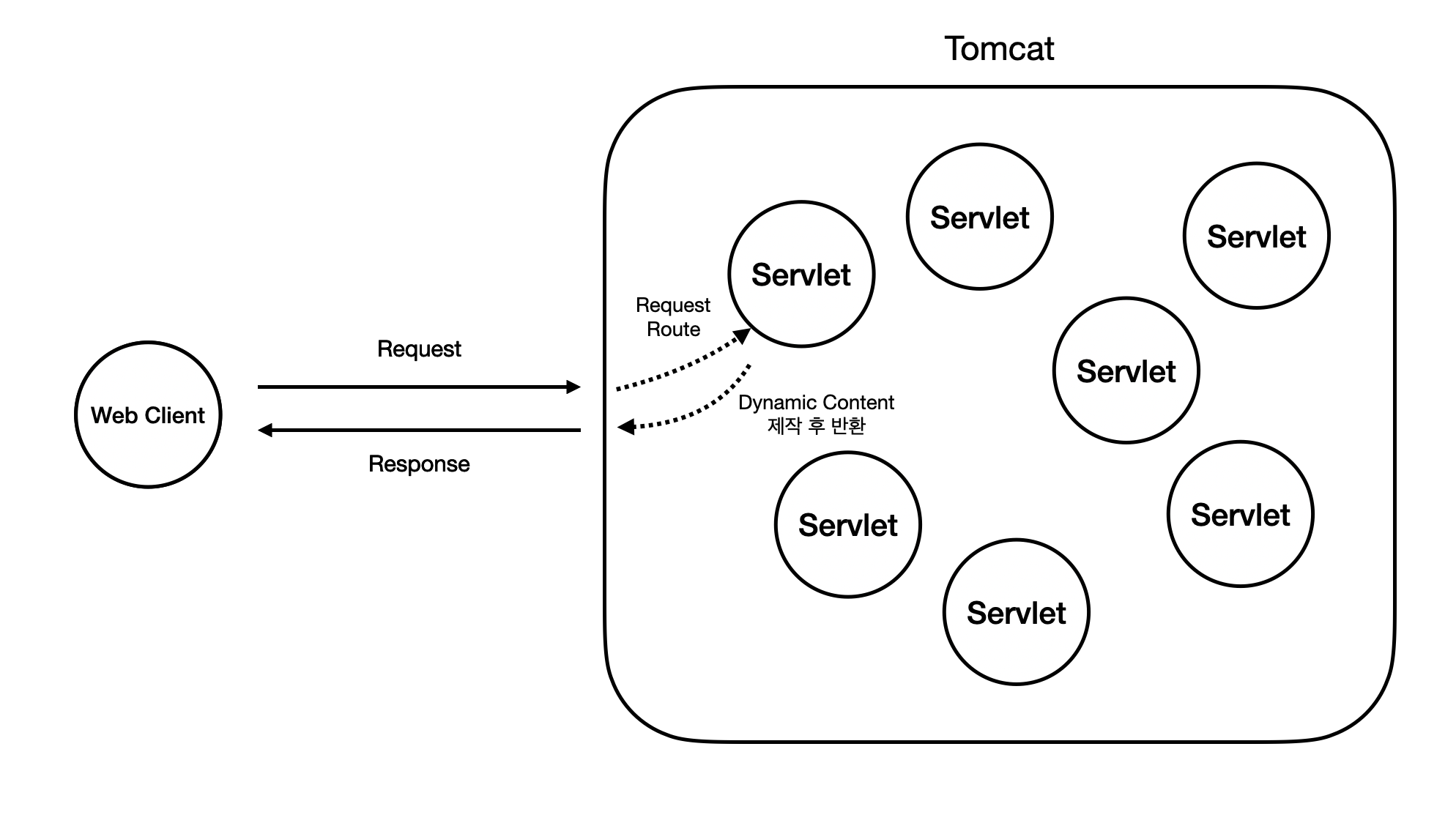 그럼 여기서 의문점이 생긴다. Servlet은 동적인 컨텐츠를 반환하는 역할을 한다고 했는데, 그럼 어떤 것을 이용해서 동적인 컨텐츠를 만들까? 어떤 소프트웨어적인 로직을 사용해야 하지 않을까?
그럼 여기서 의문점이 생긴다. Servlet은 동적인 컨텐츠를 반환하는 역할을 한다고 했는데, 그럼 어떤 것을 이용해서 동적인 컨텐츠를 만들까? 어떤 소프트웨어적인 로직을 사용해야 하지 않을까?
예를 들어 Login() 이라는 요청이 들어오면, 먼저 그 요청이 유효한지 검증을 하고, 요청에 대한 ID와 비밀번호가 일치한지 데이터베이스에 접근을 해야 한다. 그런 로직은 누가 처리할까?
하나를 더 추가해보자. 이번엔 여러분들에게 더더욱 익숙한 용어가 등장한다.
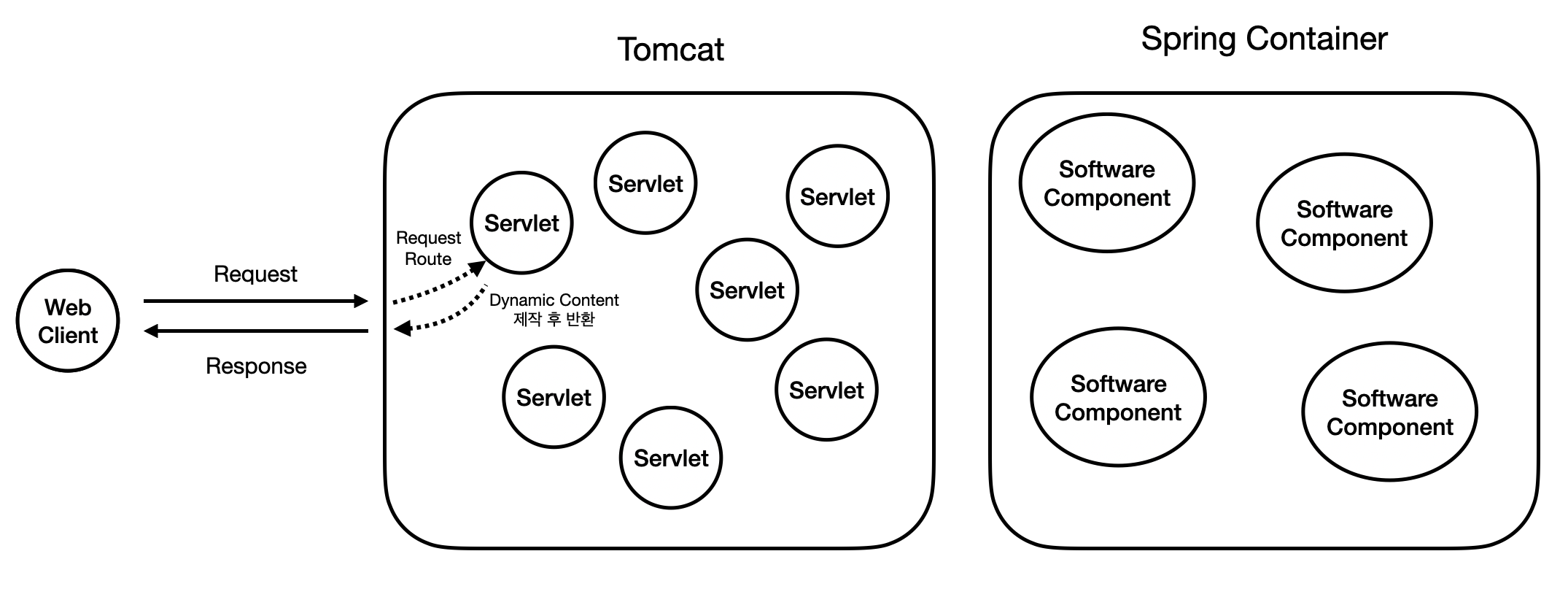 Tomcat의 뒤에는 바로 Servlet이 동적 컨텐츠를 만들기 위해 로직을 사용할 때, 그 로직을 담당하는 객체, 또는 컴포넌트를 관리하는 Spring Container가 있다.
Tomcat의 뒤에는 바로 Servlet이 동적 컨텐츠를 만들기 위해 로직을 사용할 때, 그 로직을 담당하는 객체, 또는 컴포넌트를 관리하는 Spring Container가 있다.
Servlet은 이 Software Component들을 호출하여, 그 Software Component가 담당하는 로직 또는 메서드를 사용하여 동적인 컨텐츠를 제작한다.
어라? 익숙하지 않은가? 그럼 용어만 또 바꾸어보겠다.
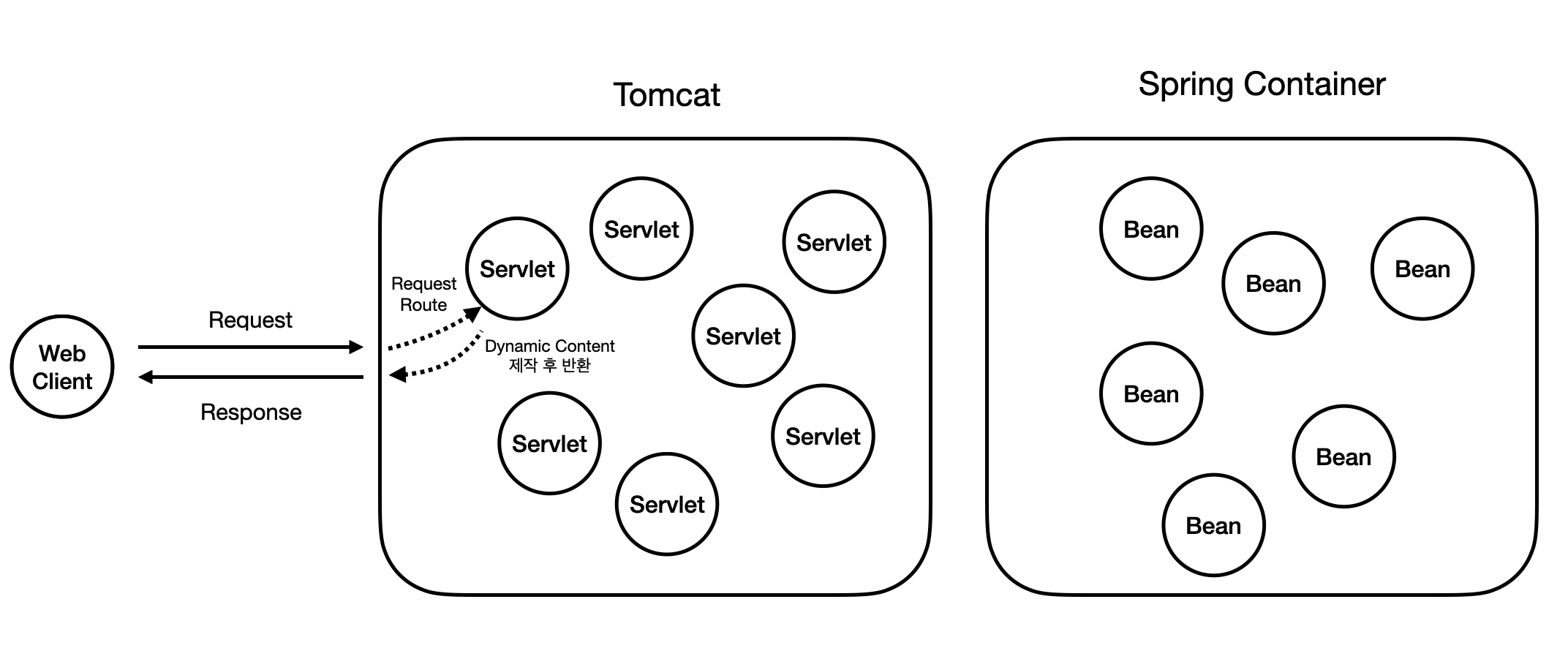 이제 좀 익숙한가? 우리가 제일 흔하게 접하는 이 "Bean"이 바로 아까 위에서 설명했던 Software Component다.
이제 좀 익숙한가? 우리가 제일 흔하게 접하는 이 "Bean"이 바로 아까 위에서 설명했던 Software Component다.
@Bean
public CacheManager diareatCacheManager(RedisConnectionFactory cf) {
RedisCacheConfiguration redisCacheConfiguration = RedisCacheConfiguration.defaultCacheConfig()
.serializeKeysWith(RedisSerializationContext.SerializationPair.fromSerializer(new StringRedisSerializer()))
.serializeValuesWith(RedisSerializationContext.SerializationPair.fromSerializer(new GenericJackson2JsonRedisSerializer()))
.entryTtl(Duration.ofMinutes(3L)); // 캐시 만료 시간 3분
return RedisCacheManager.RedisCacheManagerBuilder.fromConnectionFactory(cf).cacheDefaults(redisCacheConfiguration).build();
}이렇게 @Bean 어노테이션을 붙는 순간, 해당 로직은 하나의 Bean이 되어 Spring Container에 등록되고, Servlet은 이 등록된 Bean을 사용하여 동적인 컨텐츠를 만드는 데 사용할 수 있다.
하지만 문제가 있다. 그림만 보면 단순하지만, 사실 이 Container들은 관리가 매우 복잡하다. Tomcat을 정의하려면 Web.xml 부터 시작해서, war, config 등, 세부적으로 설정을 개발자가 직접 해줘야 한다.
개발자 입장에서는 그냥 단순히 비즈니스 로직만 구현하길 원하는데, 그걸 구현하기 위해 사전에 미리 Container을 정의해주어야 하는게 매우 불편하다는 것이다.
<?xml version="1.0" encoding="UTF-8"?>
<web-app version="2.5" xmlns="http://java.sun.com/xml/ns/javaee"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/javaee https://java.sun.com/xml/ns/javaee/web-app_2_5.xsd">
<!-- Dispatcher Servlet 생성 -->
<servlet>
<servlet-name>myDispatcherServlet</servlet-name>
<servlet-class>org.springframework.web.servlet.DispatcherServlet</servlet-class>
<init-param>
<param-name>contextConfigLocation</param-name>
<param-value>classpath:/config/servlet-config.xml</param-value>
</init-param>
<load-on-startup>1</load-on-startup>
</servlet>
<servlet-mapping>
...이걸 Spring 프로젝트를 생성할 때 마다 일일이 설정을 해줘야 한다는 것이다.
Springboot의 등장
2012년 10월 18일, 한 개발자가 위의 불편함을 Spring의 공식 Github의 Issue에 게시한다.
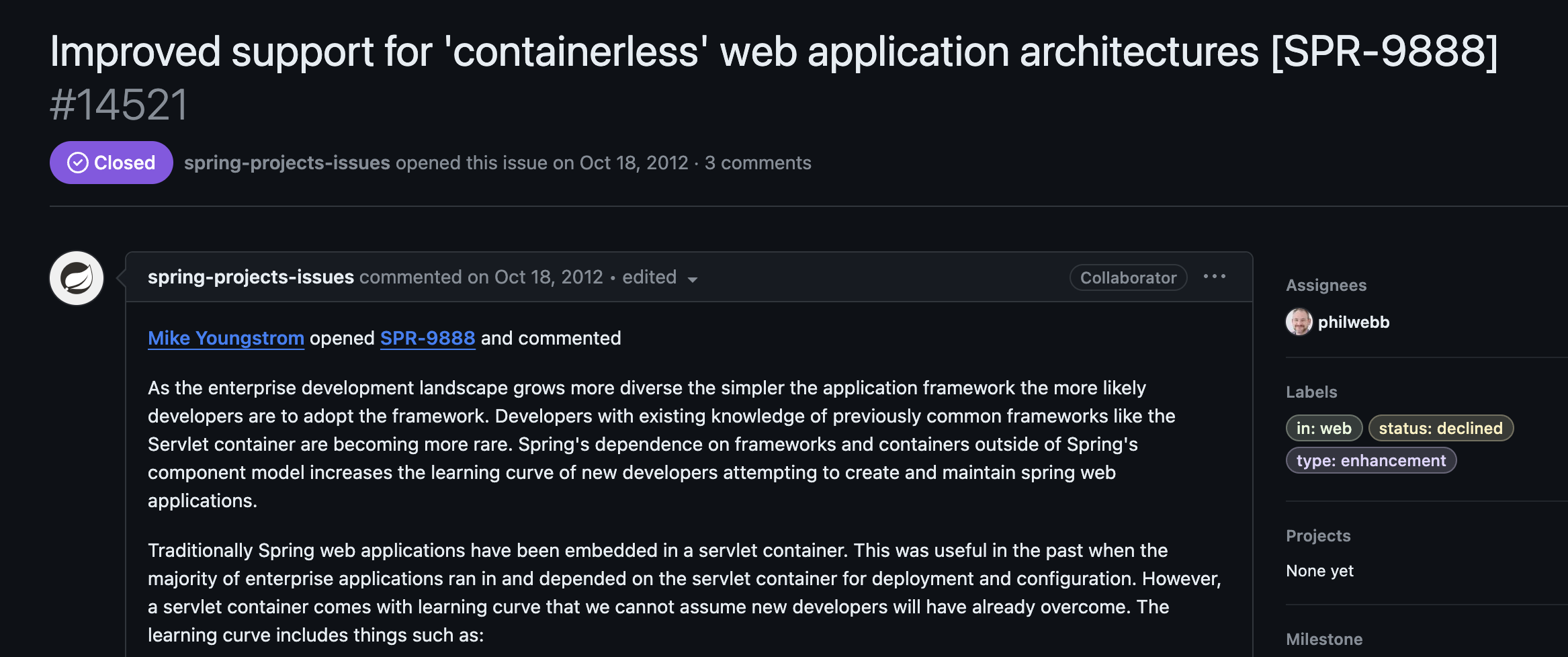
https://github.com/spring-projects/spring-framework/issues/14521
위 글을 요약하면 다음과 같다.
-
개발 세계가 점점 커지면서, 프레임워크가 단순해질 수록 개발자들이 이에 적응하기 쉬워진다.
-
이에 따라 Spring의 Servlet 컨테이너와 관련된 충분한 배경지식을 가진 개발자들은 점점 줄어들고 있다.
-
물론 Servlet 컨테이너는 기업들이 배포와 개별 설정을 할 때 유용했지만, 몇가지 단점으로 인해 러닝 커브가 매우 가파르다. (Web.xml, war, logging 등)...
-
게다가, 각 개발 팀마다 Servlet 컨테이너를 설정하는 방법이 다르니, 신규 개발자들은 이에 따라 계속 적응을 해야 한다.
-
Dropwizard 같이 컨테이너가 없는 프레임워크들을 참고하면, 결국 이러한 Servlet 컨테이너 또한 설정할 필요없이 Spring 컨테이너에 내장된 상태로 있는 것이 더 적절할 것 같다.
-
이렇게 되면, 굳이 개발환경을 세팅할 때마다 Servlet 컨테이너를 설정하지 않고 훨씬 쉽게 개발자들이 Spring을 통해 개발할 수 있을 것이다.
Spring 팀은 이 아이디어를 참고하여 새로운 프로젝트를 진행했으니, 그것이 오늘날 Springboot가 되겠다.
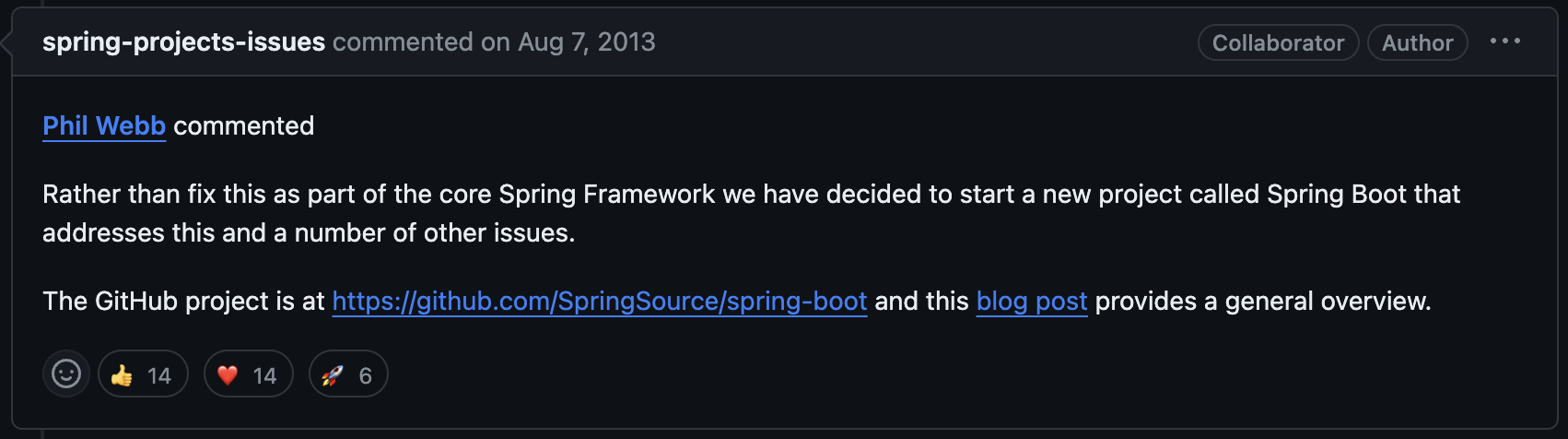
Springboot는 Spring 프로젝트를 진행하기 위해 일일이 Servlet Container를 설정할 필요없이 미리 Servlet Container을 포함한 다양한 환경설정을 사전에 해준다. 즉, DI 구성, Bean 구성 등, Springboot로 프로젝트를 시작하면 개발자가 바로 비즈니스 로직을 구현할 수 있는 환경을 구성해준다.
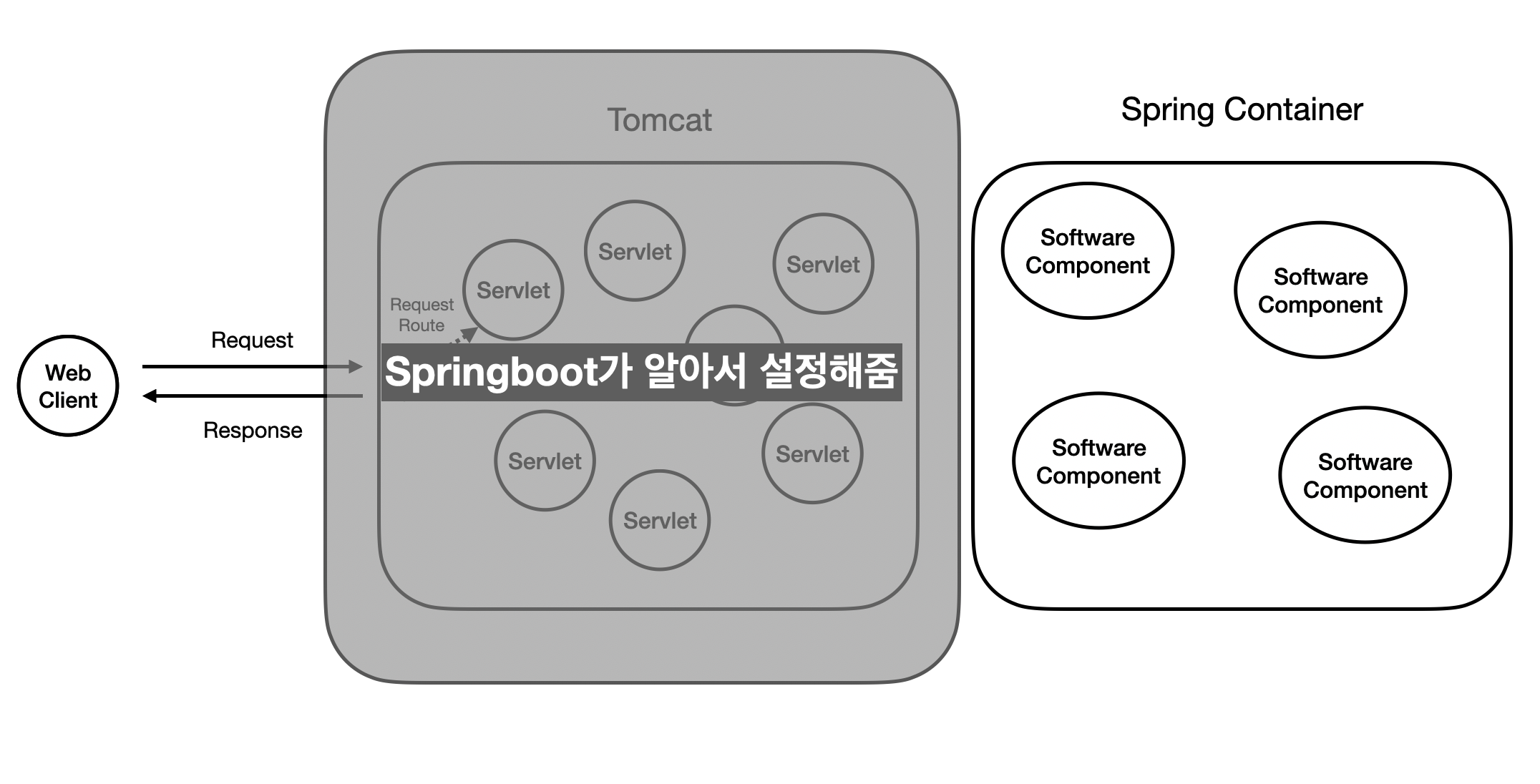
이처럼 Spring 런타임을 Containerless하게 간편하게 애플리케이션을 만들도록 한 것이 바로 Springboot다!
그래서 요청은 어떻게 처리해?
검색창에 나오는 Spring의 Request를 검색해보면 수도 없이 많은 블로그에서 DispatcherServlet, handlerMapping...이 나올 것이다.
하지만 이번에는 저기 위에 그린 컨테이너와 그 안의 컴포넌트를 기준으로 한번 해보겠다. 저기 그림에서 그린 수많은 Servlet이 왜 지금의 DispatcherServlet으로 되었는지, 그 과정을 한번 보자.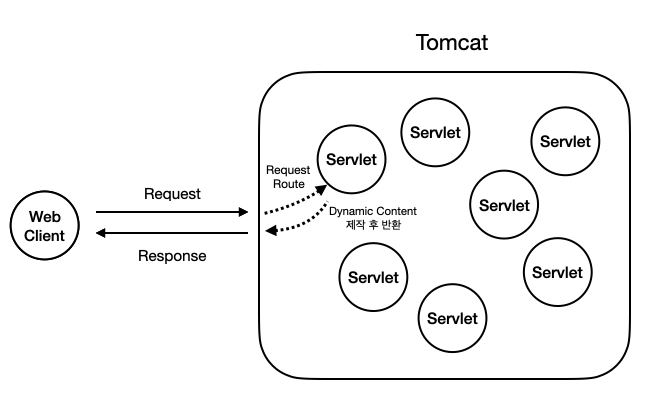 다음과 같이 매번 request가 도달할 때마다 이에 해당하는 서블렛에 매핑을 하는 작업은 굉장히 번거롭다. 로직을 구현해도 서블렛을 하나하나 다루어야 하는 등, 개발자가 신경써야 할 점이 많았다. 이런 모든 서블렛들을 Tomcat에서 다 관리하는 것이 아니라, 하나의 서블렛이 대표로 이 요청을 받으면 어떨까?
다음과 같이 매번 request가 도달할 때마다 이에 해당하는 서블렛에 매핑을 하는 작업은 굉장히 번거롭다. 로직을 구현해도 서블렛을 하나하나 다루어야 하는 등, 개발자가 신경써야 할 점이 많았다. 이런 모든 서블렛들을 Tomcat에서 다 관리하는 것이 아니라, 하나의 서블렛이 대표로 이 요청을 받으면 어떨까?
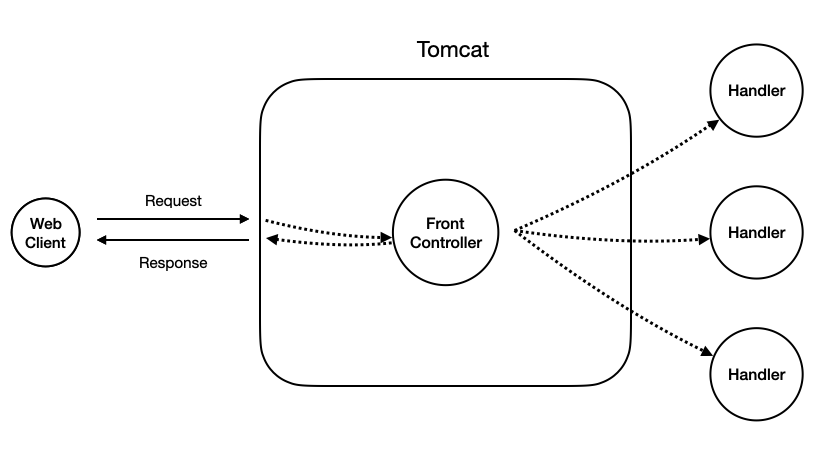 그래서 나온 개념이 바로 Front Controller다. 즉, Web Client에서 받은 Request는 이 Front Controller가 대표로 수신하고, 이를 담당 Handler에게 인계하는 방식으로 한다는 것이다.
그래서 나온 개념이 바로 Front Controller다. 즉, Web Client에서 받은 Request는 이 Front Controller가 대표로 수신하고, 이를 담당 Handler에게 인계하는 방식으로 한다는 것이다.
모든 Request를 각각의 Servlet에게 라우팅 하는 것이 아닌, Servlet Container, 즉, Tomcat은 이 Front Controller 하나만을 관리하면 되기 때문에 개발자는 Tomcat 설정이 굉장히 편해진다.
그러나 코드 구현으로 넘어가면 얘기가 다르다. 즉, Front Controller가 제대로 Handler에게 mapping 하기 위해서는 Request마다 분기점을 두고 Handler를 호출하도록 해야 하는데, 문제는 여기서 끝나는 것이 아니다.
GenericApplicationContext applicationContext = new GenericApplicationContext();
applicationContext.registerBean(UserController.class);
applicationContext.registerBean(UserService.class);
applicationContext.refresh();
ServletWebServerFactory serverFactory = new TomcatServletWebServerFactory();
WebServer webServer = serverFactory.getWebServer(servletContext -> {
servletContext.addServlet("hello", new HttpServlet() {
@Override
protected void service(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
if (req.getRequestURI().equals('/user') && req.getMethod().equals(HttpMethod.GET.name())){
String name = req.getParameter("name");
UserController userController = applicationContext.getBean(UserController.class);
String ret = userController.user(name);
resp.setContentType(MediaType.TEXT_PLAIN_VALUE);
resp.getWriter().println(ret);
}else{
resp.setStatus(HttpStatus.NOT_FOUND.value());
}
).addMapping("/*")지금 이 코드는 딱 하나의 url Path에 대해서 매핑을 하는 코드다. 심지어 Bean을 통해 간소화 시킨 코드이기도 하다. 무슨 일이 일어나고 있는지 조금 해석해주겠다.
GenericApplicationContext를 통해Spring Container를 생성한다.- 그 후,
.registerBean()을 통해Spring Container내부에UserController와UserService를Bean형태로 등록한다. addServlet을 통해 "hello"라는 이름의Servlet을Tomcat에 등록한다.- 그 후, request에서 URI에 따라
.getBean()을 통해 위에서 등록한Bean을 가져온다. - 응답에 ContentType과 writer을 기입하여 응답을 보낸다.
즉, 어떤 요청에 대해서 적절한 Servlet에 Mapping을 하고, 내부에서 이 Servlet이 Bean을 통해 비즈니스 로직을 수행하는 것을 볼 수 있다. 그러나, 애플리케이션 규모가 커질 수록, 이 모든 분기점을 하나하나 관리하는 것은 어렵다.
이 내부적인 구현사항을 추상화한 Component가 어디 없을까?
DispatcherServlet의 등장
Servlet을 하나하나 명시적으로 생성해야 하고, 이를 Mapping하는 것은 로직 외적으로 번거로운 작업이기 때문에 맨 위에서 말했듯, 이를 위한 컴포넌트 역시 등장했는데 DispatcherServlet이 이 Containerless개발의 심장격이 되는 요소다.
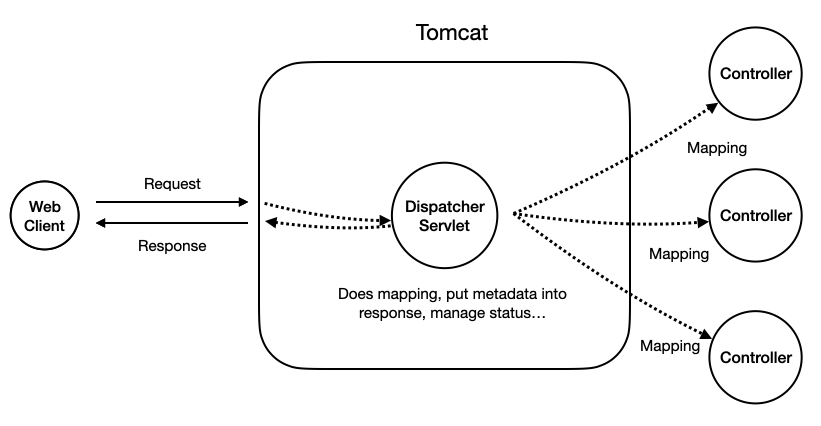 사실,
사실, DispatcherServlet은 Springboot 등장 이전에도 이미 존재했던 Servlet이다. 다만 중요한 건, 예전처럼 각각의 요청을 도맡는 Servlet을 일일이 관리할 필요 없이, 요청과 Controller을 Mapping하고, 응답 형식에 필요한 메타데이터들을 자동으로 기입을 해주는 역할을 대신 해준다는 것이다.
이 방식은 오늘날 우리가 Spring으로 애플리케이션을 개발했을 때, 요청을 처리하는 가장 일반적인 방식이 되었다.
스레드 풀
Tomcat, 즉 Servlet Container에 조금 생략된 것이 있는데, 바로 스레드 풀이다. Spring 뿐만 아니라 모든 애플리케이션에서 어떤 작업을 수행할 때는 반드시 스레드라는 하나의 작업 단위로 실행이 된다. 즉, 어떤 특정 객체라고 하는 것 보다는, 동작을 수행하는 일종의 "수행자"라고 하면 된다.
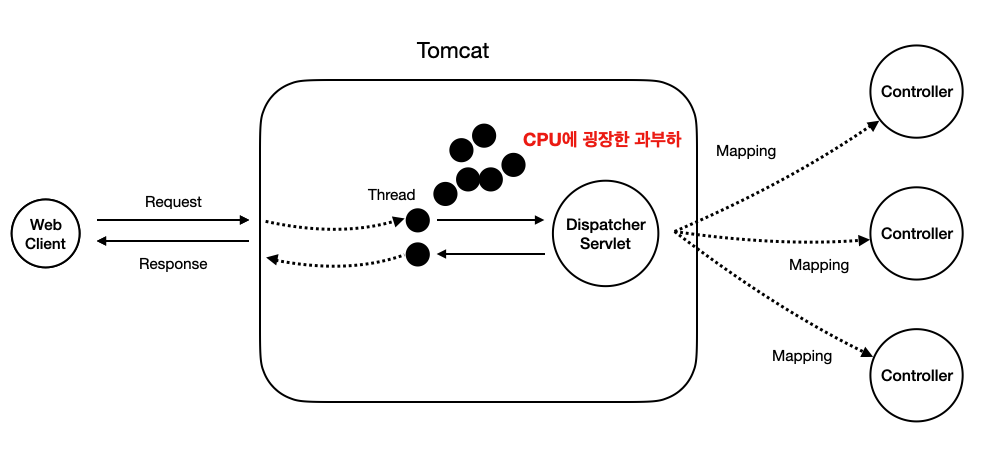
만약 1000개의 요청이 한번에 들어왔다고 가정해보자. 그럼 1000개의 요청에 대응하여 1000명의 수행자를 생성하는 것은 과연 효율적일까? 애초에 컴퓨터가 이를 못 버틴다.
우리가 말하는 흔히 "멀티태스킹"은 "동시에" 여러 작업을 수행하는 것을 의미하지만, 사실 컴퓨터에게 "동시"란 존재하지 않는다. 단지, 동시에 하는 것처럼 보이는 것이지, 실제로 컴퓨터는 굉장히 빠른 속도로 두 작업을 번갈아가면서 수행을 한다.
그럼 1000개의 스레드가 1000개의 요청에 대한 작업을 처리하면, 컴퓨터는 말 그대로 아주 짧은 시간에 1000번 번갈아 가며 작업을 해야 겨우 감당을 할 수가 있다. 스레드 컨텍스트 스위칭이 비교적 가벼운 작업은 맞지만, 1000개의 스레드에 대한 컨텍스트 스위칭은 여전히 버겁다.
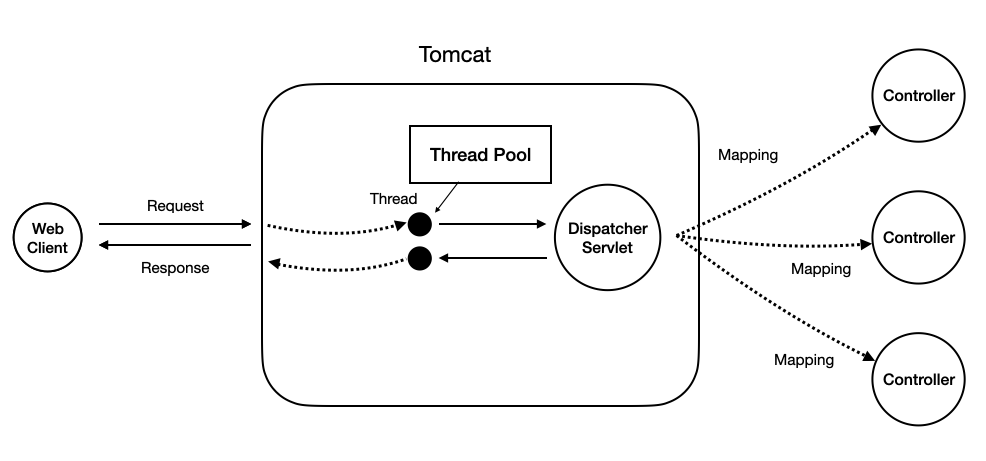 그래서 Spring은 최대 가용 스레드의 수를 제한을 두었는데, 바로 스레드 풀에 미리 스레드를 생성한 후, 요청이 올 떄마다 스레드 풀 내부의 스레드가 이를 처리하는 방식을 사용했다. 즉, 스레드를 생성할 필요없이 이미 존재하는 스레드를 꺼내어 사용하는 방식이다.
그래서 Spring은 최대 가용 스레드의 수를 제한을 두었는데, 바로 스레드 풀에 미리 스레드를 생성한 후, 요청이 올 떄마다 스레드 풀 내부의 스레드가 이를 처리하는 방식을 사용했다. 즉, 스레드를 생성할 필요없이 이미 존재하는 스레드를 꺼내어 사용하는 방식이다.
결론
지금까지 Spring에서 요청을 처리하는 방식에 대해 알아보았다. 거의 모든 개발자 또는 개발 지망생들이 Spring에서 대충 DispatcherServlet이 요청을 처리하고, 이게 Mapping이 되고...이정도의 MVC의 구조는 알지만, 구체적으로 이것들이 왜 생겨났는지는 모르는 분들이 있는 것 같다.
이를 위해서 어떤 역사를 거쳐 탄생을 하게 되었고, 오늘날 요청을 어떻게 처리하는지에 대해 좀 자세하게 알아보았다. 참고로, 지금 이 글에서 그린 그림들을 이해하기 쉽게 몇가지 요소들을 생략한 그림임을 참고하길 바란다 (Handler Adapter 등...)
다음 글에서는 Node.js 에서의 요청 처리 방식에 대해 알아보겠다.
