[ALBEF paper 리뷰] Align before Fuse: Vision and Language Representation Learning with Momentum Distillation
이 글을 읽는 사람이라면 아마도 CLIP[1]에 대해서는 알고 있을 가능성이 높다. 나도 CLIP을 먼저 읽고 다른 방법론으로는 어떻게 visual token과 language token을 align하는지 방법이 궁금하여 이 paper를 읽게 되었다. ALBEF를 읽으면서 다시 VLM에 대한 기초를 쌓고자 한다.
Abstract
본 논문에서는 다음과 같은 화두를 던지고 있다.
- 이 당시 논문에서 CLIP과 같은 논문들은 visual token과 word token을 align하려고 했음.
- 그래서 이 논문에서도 어떻게 visual token과 word token을 align을 잘 할 수 있을지에 대한 설명을 진행함. 물론 방법은 contrastive loss방식으로 한다고 함.
- 그런데 이제 CLIP과의 차이는 Fusing 하기 전에 align을 한다인 것 같은데, 이게 어떤 의미인가?
- Noisy한 web data를 통해 학습하는 것의 효율성을 높이기 위해, momentum distillation 방식을 사용했다고 한다. 그리고 이 방식은 self-training method 방식으로 momentum model로부터 생산된 pseudo-targets을 통해 학습을 진행한다.
-> momentum은 무엇이고, pseudo-target은 무엇인가? 그리고 momentum distillation은 기존의 distillation과 무슨 차이가 있을까?
-> momentum model이란 무엇인가?
- momentum model이란 학습 중 시간이 지남에 따라 업데이트 되는 지속적이고 안정적인 모델을 의미한다.
-> pseudo-target이란 무엇인가?
- pseudo-target이란 교사 모델이 생성한 적당히 신뢰할만한 레이블이다.
- 정확한 레이블까지는 아니지만 그래도 꽤 신뢰할만한 레이블이라고 생각하면 된다.
-> 그렇다면 momentum distillation과 일반 distillation의 차이는 무엇일까?
- 일반적인 distillation은 대표적으로 GPT와 같은 프론티어 모델을 가지고 sLLM을 학습시키는 방식으로 생각하면 좋을 것 같다. GPT가 생성한 라벨을 가지고 sLLM을 학습하는 방식이다. 즉, teacher model은 고정이 된다.
- 그러나 momentum distillation은 teacher model이 고정이 아니다. teacher model의 가중치를 student model의 방향으로 아주 조금씩 업데이트를 진행한다. 이를 통해 student model이 너무 과도하게 업데이트되는 것을 막고자 한다고 한다.
일단은 배경 지식은 이 정도로 가져간다면, 다음 논문에서 teacher model은 어떤 것을 사용했는지, pseudo-target은 어떻게 했는지, 그리고 이러한 것들을 바탕으로 momentum distillation을 어떻게 했는지 알아보면 좋을 것 같다.
그리고 자꾸 Abstract만 해도 너무 길어지는데, 본 논문은 mutual information을 최대화하기 위한 과점에서의 분석 내용을 제공한다고 한다.
-> Mutual Information이란?
- visual token과 text token의 관계에 대한 것이다.
Illustration of ALBEF
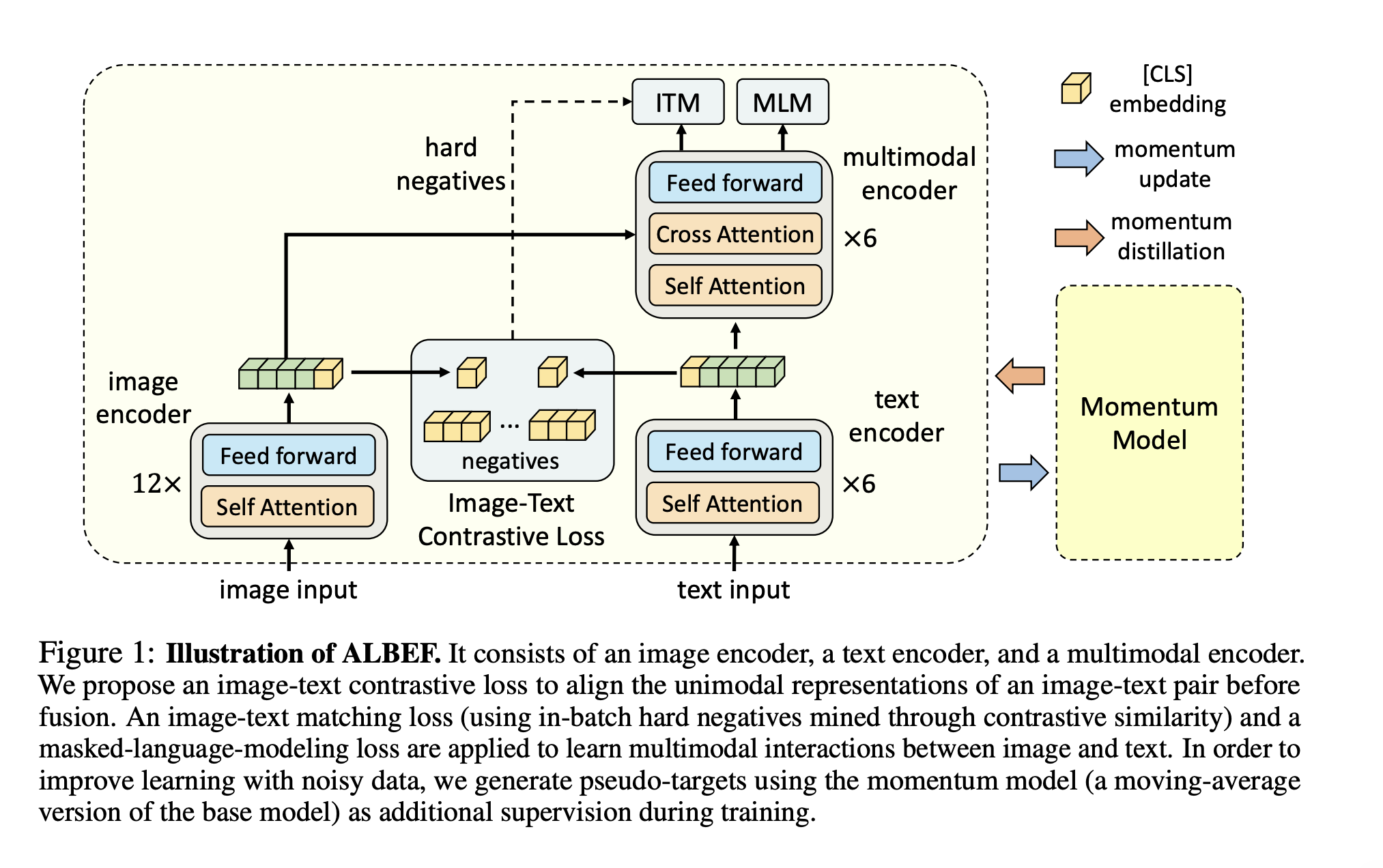
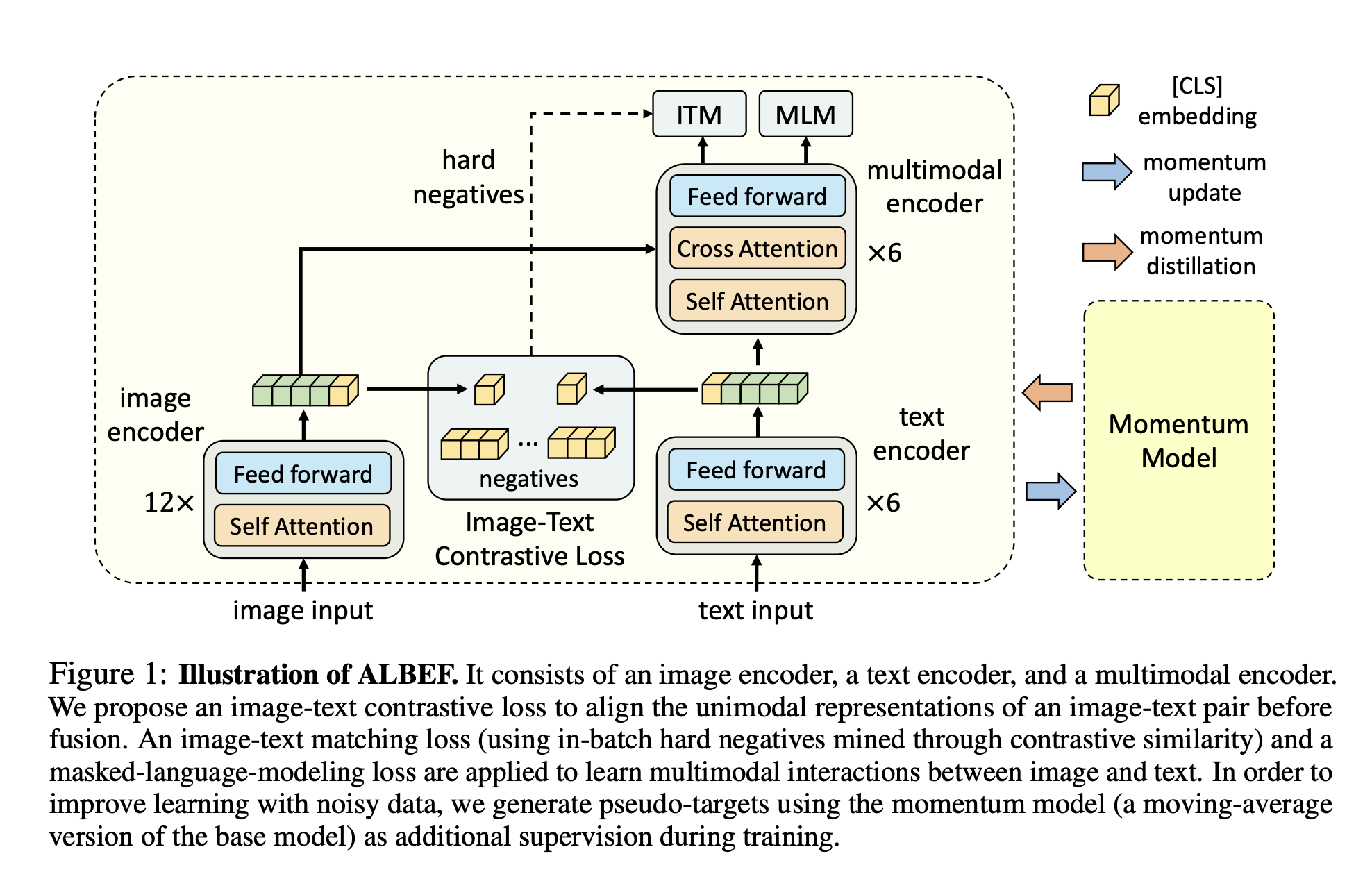
일단 기본적으로 위 그림을 살펴보게 되면 image input과 text input 2가지를 받는다. 그리고 각각의 modal의 인코더로 들어가게 된다. 이는 각각의 representation으로 변환되게 되고, 이는 하나의 (1, hidden_embed) 사이즈의 벡터로 변환되게 된다.(아마도 CLIP과 비슷한 구조면 그렇지 않을까...)
각 modal의 vector representation에서 임베딩 벡터를 추출하고 나면 이를 통해 ITM(Image-Text Matching Loss)를 학습하게 된다.
- 그런데 그림을 보게 되면 negatives라는 말이 적혀져 있다. 이건 무슨 의미일까?
- batch 내에서 hard negative들을 활용해서 학습을 진행한다는 얘기이다.
- 그렇다면 hard negative는 무엇이고, ALBEF와 같은 멀티모달 모델에서는 어떻게 사용되는 것인가?
- 일반적인 CLIP과 같은 모델에서는 Image-Text pair로 학습을 진행하게 된다. 그러면 이 pair들 중에 positive인 경우가 있고, negative인 경우가 있다.
- Positive pair -> 텍스트가 "빨간 스피커"이면서 이미지도 "빨간 스피커"일 때
- Negative pair -> 텍스트가 "빨간 스피커"이면서 이미지는 "검은색 자전거"일 때
- 그렇다면 Hard Negative란 뭘까?
- Hard Negative란 Positive pair로 착각하기 쉬우면서도 Negative인 경우이다.
- 그러니까 텍스트는 "빨간 스피커"이면서 이미지는 "갈색 스피커"인 경우인 것이다.
- 이렇게 의도적으로 hard negative pair를 집어넣어 학습을 진행한 것으로 보인다.
- 그리고 Loss는 contrastive loss방식을 사용한 것으로 보인다.
- 일반적인 CLIP과 같은 모델에서는 Image-Text pair로 학습을 진행하게 된다. 그러면 이 pair들 중에 positive인 경우가 있고, negative인 경우가 있다.
그리고 각 모달의 vectore representation은 다시 multimodal encoder의 입력으로 넣게 된다. 그리고 visual token의 representation과 text token의 representation의 interaction에 대해 학습하기 위해 loss함수는 MLM(Masked Language Modeling)방식으로 설계를 하였다.(그런데 MLM이 무슨 의미일까? 이따 알아보도록 하자
Introduction
Why did they even do this research?
이 당시의 일반적인 VLP(Vision-and-Language Pre-training) 방식의 문제점은 몇 가지 문제가 있었다.
- image feature와 word token embedding이 각자의 space에 위치하는 문제가 있었다. -> 이를 비슷한 space에 위치하게 시켜줘야 한다.
- 일반적으로 pretrained object detector 모델을 사용하는데, bounding box들을 찾아서 라벨링을 해줘야 하다보니 object detector를 구축하기에는 많은 비용이 든다. 또한 고해상도 이미지를 요구한다.
- 이렇게 데이터셋을 구축하기에는 많은 비용이 들다보니 데이터셋 구축 비용을 줄이기 위해 web에서 수집된 image-text 데이터셋을 사용하는데, 이는 현재의 pre-training objective(MLM etc.)로는 오버피팅의 위험이 있다.
그래서 ALBEF라는 논문을 작성하고 아이디어를 냈으니, 아마도 다음과 같은 문제를 해결하고자 할 것이다.
- image feature와 word token embedding을 어떻게 동일한 vector space에 위치시켜줄지
- bounding box없이도 object detector를 구축할 수 있게 하거나, pretrained된 이미지 인코더를 어떻게 만든다든지
- 고해상도 이미지도 필요없게 한다든지
- objective function을 조정해서 web에서 수집된 raw한 데이터셋에도 robust하게 학습되게 한다든지
일단 Introduction에서는 다음과 같이 말한다.
- object detector를 만들기 위해서는 데이터셋 구축 비용이 너무 많이 들어~ -> 그럼 object detector 없이 image를 인코딩하자. 그리고 text는 따로 인코딩하자.
- image feature와 word token embedding을 align해야 해~ -> 그럼 ITC(Image-Text Contrastive Loss)를 사용하자. -> ITM이랑 뭐가 다른데? 그건 이따 알아보자...
- 그리고 위의 illustration을 보게 되면 (1, hidden_embed_size) 느낌으로 CLS 토큰만 쓰는 느낌인데, 이 방식처럼 (seq_len, hidden_embedd_size)가 아닌 방식으로 하게 되면 Hard Negative Mining하는데 도움이 된다고 한다.
- Web에서 수집된 raw한 데이터셋에도 robust하게 학습되어야 해~ -> Momentum Distillation방식을 사용하자. 이 방식을 활용하면 uncurated web dataset에 대해서도 학습이 가능하다. 왜 가능한지는 따로 목차를 나눠서 설명하도록 하겠다.
- 부가적으로...ITC와 MLM이 Mutual Information의 lower bound를 최대화시켜준다고 하는데, lower bound를 최대화한다는 것이 무엇일까?
- 우리는 mutual information을 visual token과 word token의 관계라고 정의했다.
- 그리고 visual token과 word token은 비유하자면 상대의 어느 정도의 정보는 가지고 있다(lower bound)고 가정하면, 이 정보의 lower bound를 높여준다. 즉, 상대의 정보를 더 많이 가질 수 있게, 관계를 강화한다라고 보면 된다.
Experiments and Conclusion
Experiments #1(four downstream V+L tasks)
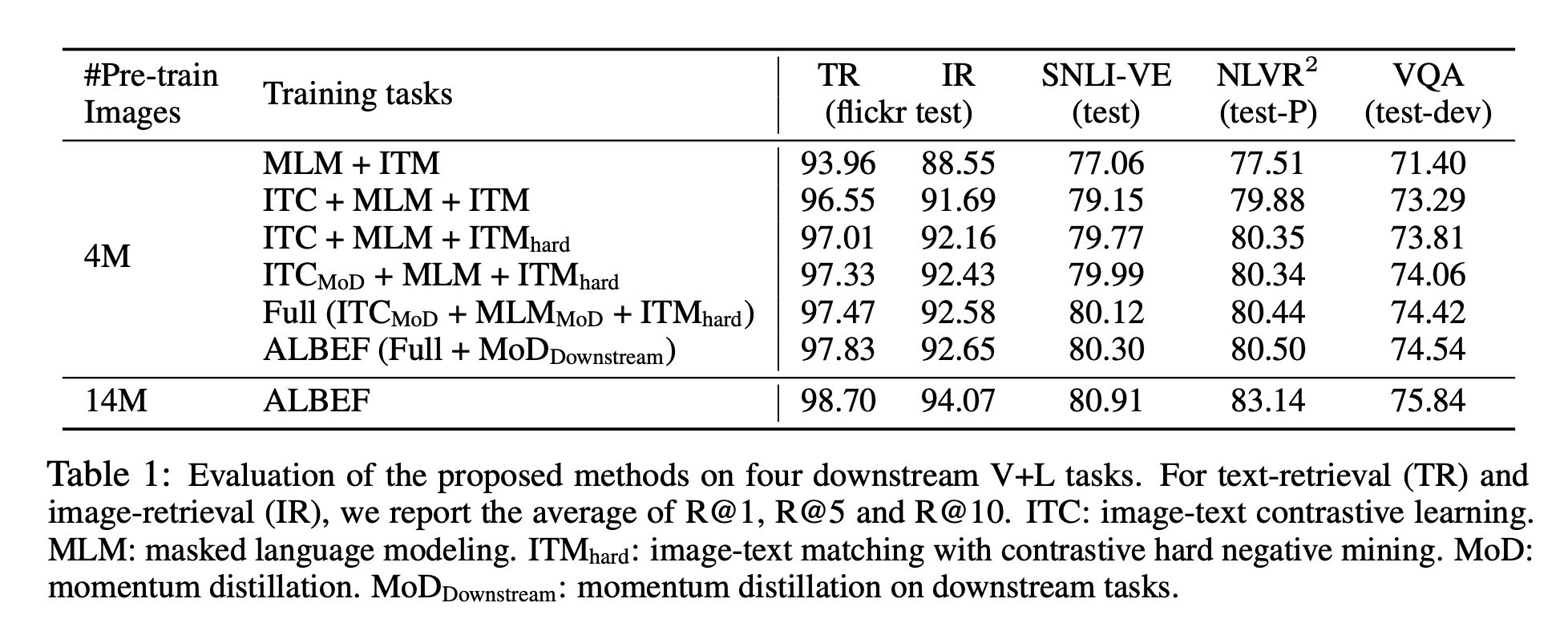
Analysis of experiments#1
- ITC를 하게 되면 전반적으로 성능이 꽤나 증가하는 것으로 보인다.
- Hard negative mining을 하여 학습을 진행하니 전반적으로 성능이 조금씩 올라갔으나 사실 production 레벨에서는 미미한 것 같기는 하다.
- Momentum Distillation을 하게 되면 역시나 전반적으로 성능이 조금씩 올라가긴 하나 production 레벨에서는 큰 차이를 못 보일 것으로 보인다.
- 또한 실험 결과만 보면 학습 데이터가 많을 수록 성능이 올라가는 것처럼 보이기도 한다.
Experiments #2(Fine-tuned image-text retrieval & Zero-shot image-text retrieval)
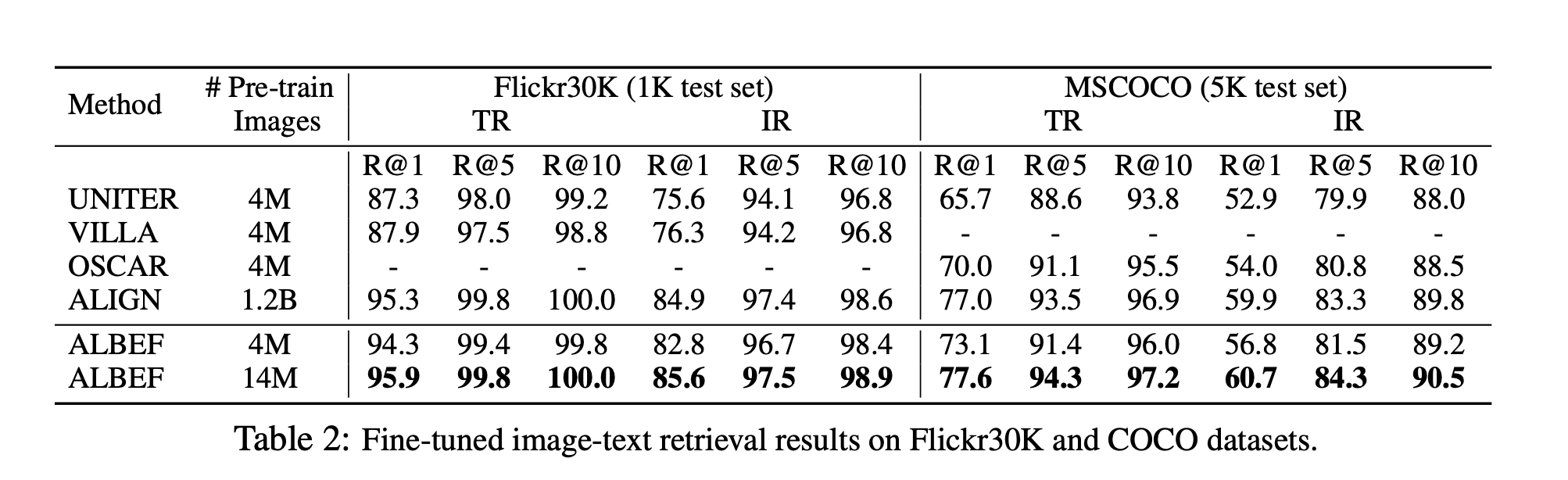
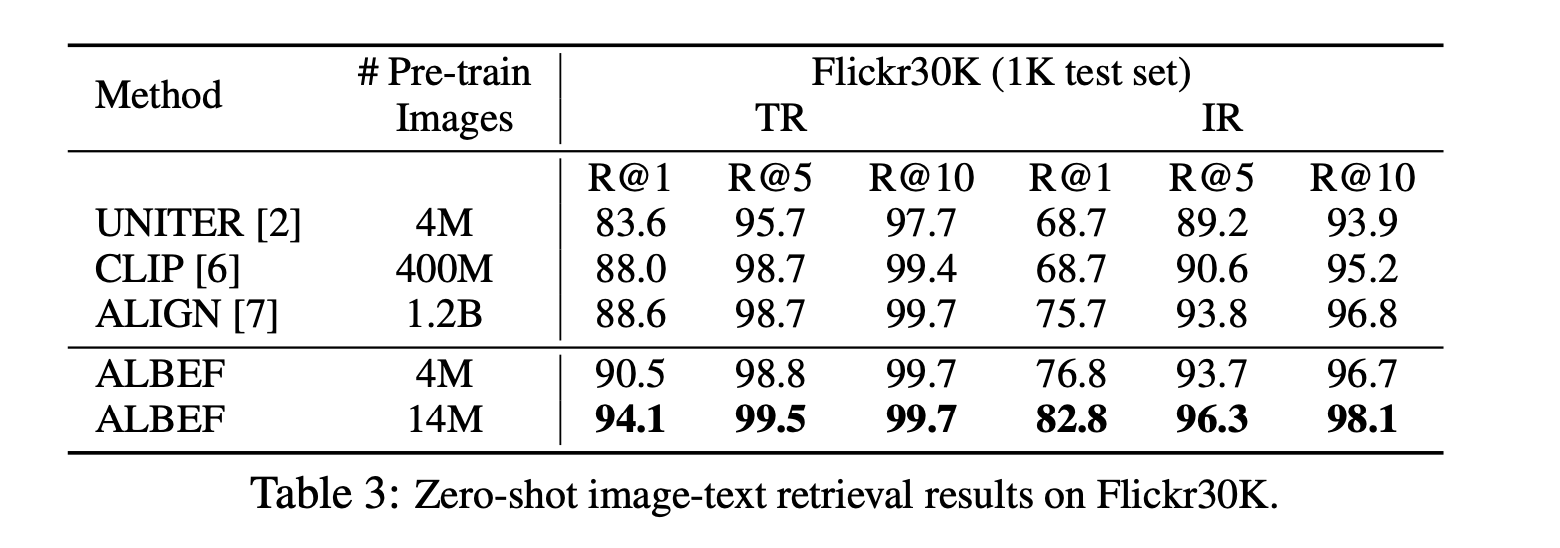
Analysis of experiments#2
- 기존의 방법론들보다 tuning 했을 때 Text Retrieval과 Image Retrieval에서 높은 성능을 보임.
- CLIP에 비해서 적은 데이터를 사용했음에도 불구하고 Text Retrieval과 Image Retrieval에서 높은 성능을 보이고 있음.
- CLIP도 ALBEF와 동일하게 ITC는 있는데 차이가 나는 것을 보면 Fuse가 성능 향상에 큰 역할을 하지 않았는가라는 생각이 듦.
So what kind of help did it even give?
바쁜 사람들을 위해 어떤 결론에 도달했고, 어떤 contribution이 있었는지 먼저 알아보자.
ALBEF는 처음으로 multimodal encoder에 집어넣기 전에 fuse했다고 한다. (그렇다면 이전에는 align을 먼저 하고 multimodal encoder에 넣은 것이 아닌 direct로 multimodal encoder에 집어넣는 것으로 보인다. 이 부분에 대해서 조금 더 찾아봐야 할 듯. (LMXMERT[2], UNITER[3], OSCAR[4])
여기서부터는 조금 더 구체적으로 알고 싶은 사람만 읽으면 될 것 같다.
Model Architecture
는 사실 크게 특별한 것은 없으니 논문을 참고하는 것이 좋을 것 같다.
Pre-training Objectives
ALBEF는 위와 같은 Loss함수로 설계되어 있다. 그렇다면 각각의 부분을 한 번 알아보자.
ITC(Image-Text Contrastive Loss)
- ITC는 CLIP을 읽고 난 뒤라고 생각하여 생략하도록 하겠다.
- 기본적으로 InfoNCE Loss를 생각해보면 좋을 것 같다.

MLM(Masked-Language Modeling Loss)
- BERT에서 사용되는 방식의 mask 기법이 사용되는 것으로 보임.(기억이 가물가물하긴 하다.)
- key vector로 image vector가 들어오게 되고, query vector로 text vector가 들어오게 되니까, 이를 해석해보면 image ground된 text 정보를 학습하기 위한 objective function이라고 볼 수 있을 것 같음.
ITM(Image-Text Matching Loss)
- ITC와 무슨 차이가 있을까?
- ITC는 기본적으로 목적이 Image와 Text의 Vector Space 상에서의 align을 하기 위한 것이라고 생각하면 된다.
- Pair인 것끼리의 임베딩은 더 가깝도록, pair가 아닌 것끼리의 임베딩은 더 멀도록 하는 것이다.
- 그러나 배치 내에서 softmax 함수를 통해 비교한다.
- 그러나 ITM은 pair가 맞는지 안 맞는지에 대한 binary classification이라 개별적으로 비교한다.
A Mutual Information Maximization Perspective
InfoNCE loss와 ITC
- InfoNCE loss를 최소화함으로써 Mutual Information의 lower bound가 최대화되고 있다고 한다.
- 이게 무슨 말일까?
- lower bound를 높힌다는 것은 결국 쉽게 말하면 visual feature와 text feature를 align한다는 말이고, 사실 CLIP을 읽어온 사람이라면 InfoNCE loss를 통해 2가지 modality를 align 한다는 것을 알 수 있을 것이다.
MLM
- mlm은 BERT와 같은 곳에서 주변 문맥을 바탕으로 그 위치에 있는 단어를 맞추는 형태로 학습을 하면서 문맥을 이해해간다. 마찬가지로 Image 정보 + 주변 문맥을 바탕으로 그 위치에 있는 단어를 맞추다 보니, Image ground가 된다고 생각할 수 있다.
References
(1) Learning Transferable Visual Models From Natural Language Supervision
(2) LXMERT: Learning Cross-Modality Encoder Representations from Transformers
(3) UNITER: UNiversal Image-TExt Representation Learning
(4) Oscar: Object-semantics aligned pre-training for vision-language tasks
