인덱스를 알아보기 전에....
페이지(Page)란?
- 데이터 파일을 구성하는 논리 단위
- SQL Server의 기본 데이터 저장 단위(8KB)
- 데이터를 쓸 때 행을 페이지에 기록됨
- 데이터를 읽을 때 페이지 내의 모든 행이 읽어짐
- 페이지 내의 행이 많을수록 I/O 효율 증가
- 0~N 사이의 순차적인 번호 (페이지 번호)
데이터를 INESERT 하게 된다면, 페이지에 들어가게 되고 테이블에 쿼리를 날려 조회하는 것이 아니라 페이지에서 SELECT 하는 것으로 생각하면 됩니다.
인덱스 장단점
장점
- 빠른 데이터를 검색하기 위해서 입니다. 찾는 데이터를 가조기 있다면 직접 주거나, 없다면 어디 있는지 알려줍니다.
- 데이터 중복을 방지할 수 있습니다. (Pirmary Key, Unique)
- 잠금을 최소화 시켜줍니다. (동시성을 높여줍니다)
단점
- 물리적인 공간을 차지하게 됩니다.(인덱스도 테이블처럼 데이터를 가지므로 물리적인 공간을 차지하게 됩니다.)
- 페이지를 가지고 있는 존재는 데이터와 인덱스 두 가지 입니다. (프로시져/뷰 는 사이즈가 없습니다)
- 인덱스에 대한 유지관리 부담이 존재합니다.
- 데이터가 극히 적다면은 효과보다 유지 관리 부담이 더 클 수 있습니다.
*** 테이블의 존재 형태는 아래 그림처럼 두 가지로 나뉩니다. ( 힙과 클러스터 형 인덱스입니다 )*** 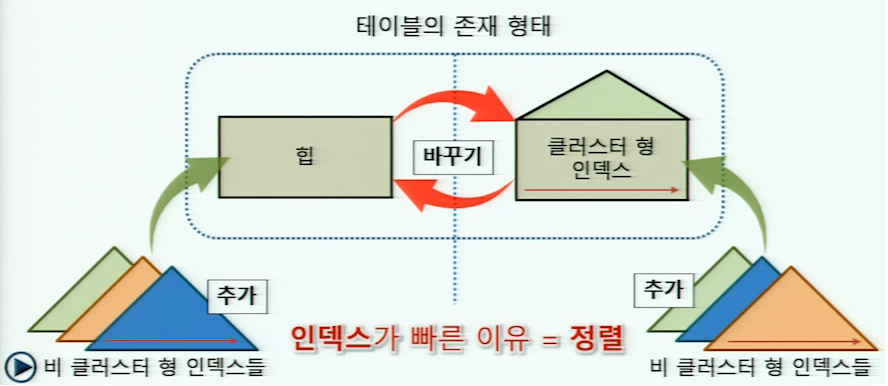
힙(heap)이란?
- 정렬의 기준이 없이 저장된 테이블의 형태를 말합니다.
- 데이터 페이지 내의 행들 간에 순서가 없고, 페이들 간에도 순서가 없습니다.
- 클러스터 형 인덱스가 없는 테이블이라고 생각하시면 쉽습니다.
힙의 장단점?
장점
- INSERT 문이 좋아하는 테이블 형태입니다.
새로운 행을 기존 페이지의 빈 곳에 추가하면 되고, 빈 공간이 없으면, 새로운 페이지에 추가하면 되기 때문이다.
단점
- SELECT문이 싫어하는 테이블 형태입니다.
데이터가 극히 적으면 상관없겠지만, 데이터가 많으면 전체적으로 모든 테이블을 스캔해야하기 때문에 데이터를 찾기가 어렵습니다.
클러스터 형 인덱스란?
- 특정 열(또는 열들)을 기준으로 데이터가 정렬되어 있습니다. (물리적 정렬이 아닌, 논리적 정렬)
- 테이블 당 하나의 클러스터 형 인덱스를 설정 가능합니다.
클러스터 형의 데이터
- Clustered Index Seek : Root 페이지부터 찾아가서, 아주 빠른 성능을 보여줍니다.
- Clustered Index Scan : 모든 데이터 페이지를 읽기 때문에 힙에서 사용했던 방식인 Table Scan과 다를바가 없습니다.

40대에 은퇴해, 제주살이를 꿈꾸는 Fire족