임시

확률분포
Probability Distribution
확률변수 가 갖는 값과 가 이 값을 가질 확률의 대응 관계를 의 확률분포라 한다.
확률변수 가 취할 수 있는 모든 값과 그 값을 나타날 확률을 표현한 함수이다.
<이산형 확률분포>
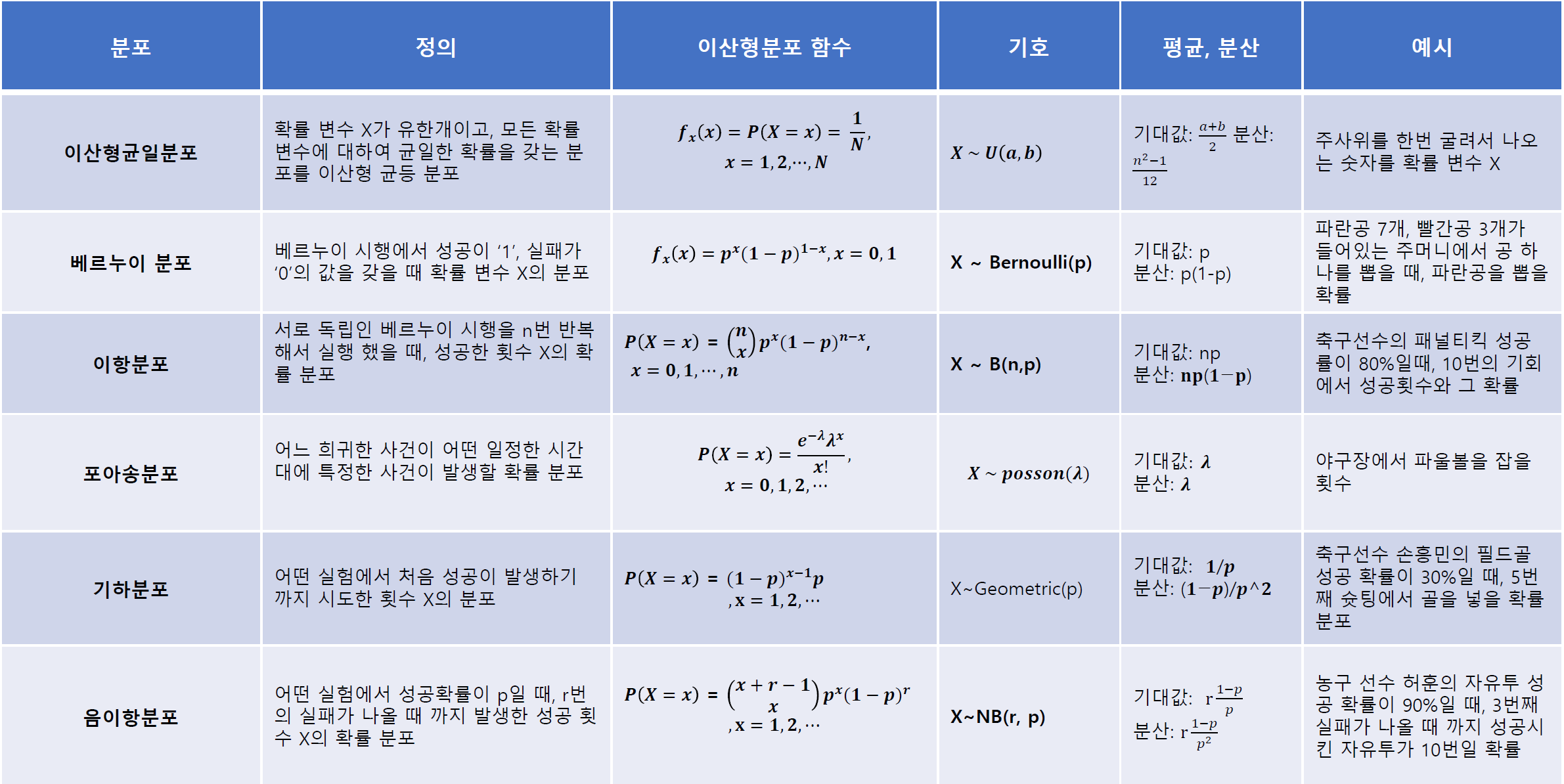
🔰 이산형균등분포

🔰 베르누이분포

🔰 이항분포
-
Binomial Distribution
연속적인 베르누이 시행을 거쳐 나타나는 확률 분포이다.
베르누이 시행(Bernoulli trial)은 각 시행의 결과가 성공, 실패 두가지 결과만 존재하는 시행을 의미한다. -
한 번의 시행에서 사건 가 일어날 확률이 로 일정할 때, 번의 독립시행에서 사건 가 일어나는 횟수를 라 하면 확률변수 가 가질 수 있는 값은 이며, 그 확률질량함수는 다음과 같다.
- 는 번 시행에서 사건 가 번 일어나는 경우의 수이다.
- 은 각 경우의 확률이다.
- 동일한 시행을 반복하는 경우에 각 시행에서 일어나는 사건이 서로 독립일 때, 이것을 독립시행이라고 한다.
-
서로 독립인 베르누이 시행을 번 반복해서 실행했을 때, 성공한 횟수 의 확률분포를 이항분포, 라 한다.
-
ex.
-
완치율이 80%인 약을 100명의 환자에게 투약했을 때 완치되는 환자의 수를 확률변수 라 하면 는 이항분포 을 따르고 의 확률질량함수는
-
축구선수의 패널티킥 성공률이 80%일 때, 10번의 기회에서 성공 횟수와 그 확률을 구하면

-
-
이항분포의 기대값(평균), 분산, 표준편차
확률변수 가 이항분포 를 따를 때, 의 평균, 분산 표준편차는
( 단, )-
- 증명
- 증명
-
-
증명
-
-
-
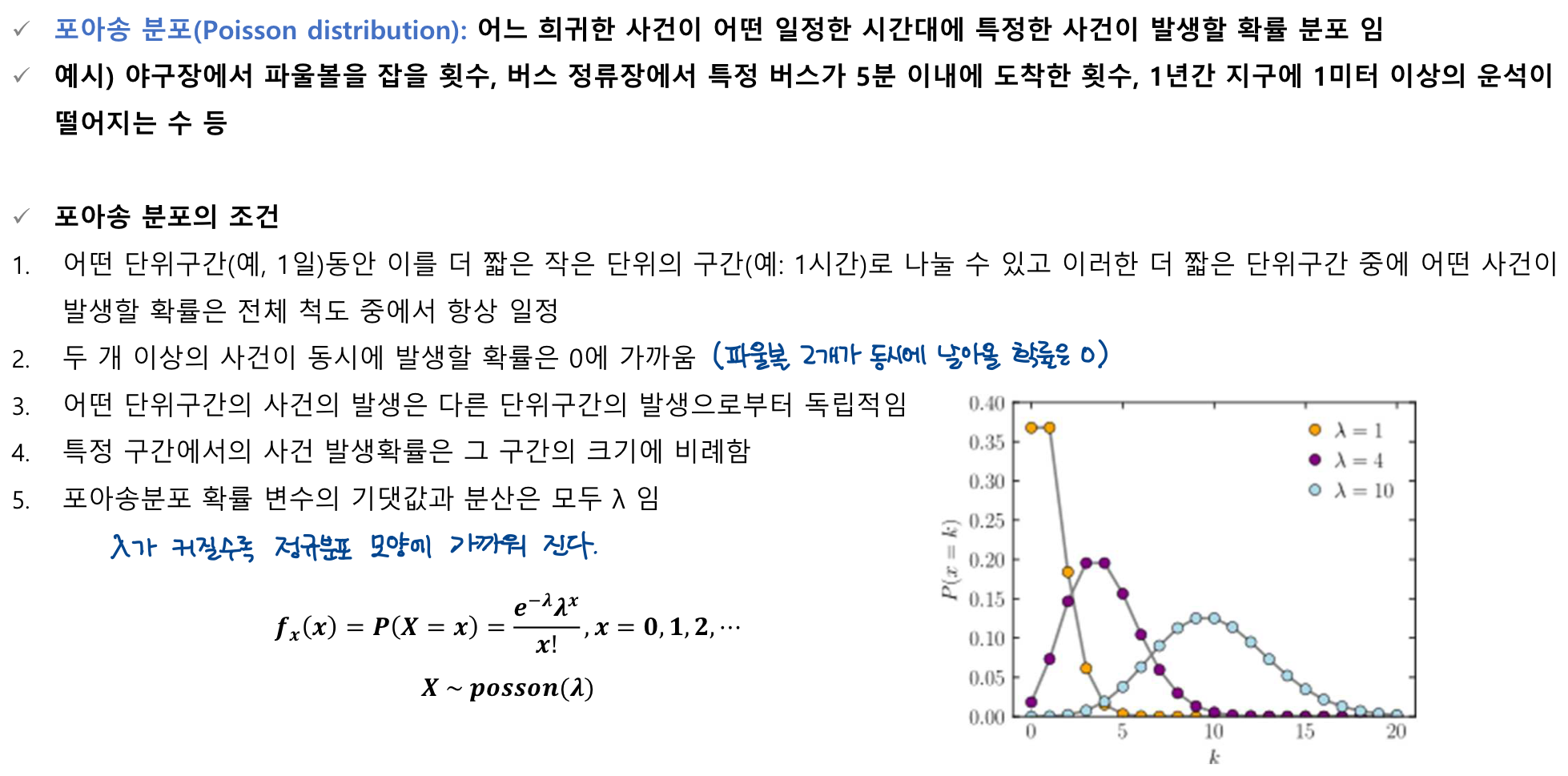
🔰 포아송분포

🔰 기하분포
-
Geometric Distribution
-
어떤 실험에서 처음 성공이 발생하기까지 시도한 횟수 의 확률분포이다.
이때 각 시도는 베르누이 시행을 따른다.
- ex.
축구선수 손흥민의 필드골 성공 확률이 30%일 때, 5번째 슛팅에서 골을 넣을 확률분포는?
- ex.
- 기하분포의 기대값, 분산,
🔰 음이항분포
-
Negative Binomial Distribution
-
어떤 실험에서 성공 확률이 일 때, 번의 실패가 나올 때까지 발생한 성공 횟수 의 확률분포이다.
- ex.
농구 선수 허훈의 자유투 성공 확률이 90%일 때, 3번의 실패가 나올 때까지 성공시킨 자유투가 10번일 확률은?
- ex.
- 음이항분포의 기대값, 분산,
<연속형 확률분포>
🔸 확률밀도함수
-
probability density function(pdf)
연속형 확률변수 에 대해서 함수 가 아래의 조건을 만족하면 확률밀도함수라고 한다.-
모든 에 대해서
-
-
-
-
확률밀도함수의 성질
-
-
확률밀도함수의 평균(기대값)과 분산
-
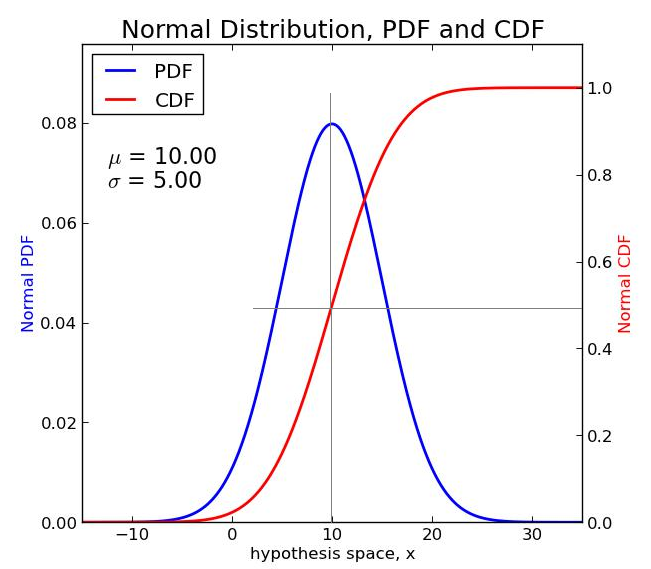
🔸 누적분포함수
-
Cumulative Density Function
-
확률밀도함수를 적분하면 누적분포함수가 된다.
-
누적분포함수의 성질
-
🔰 균일분포

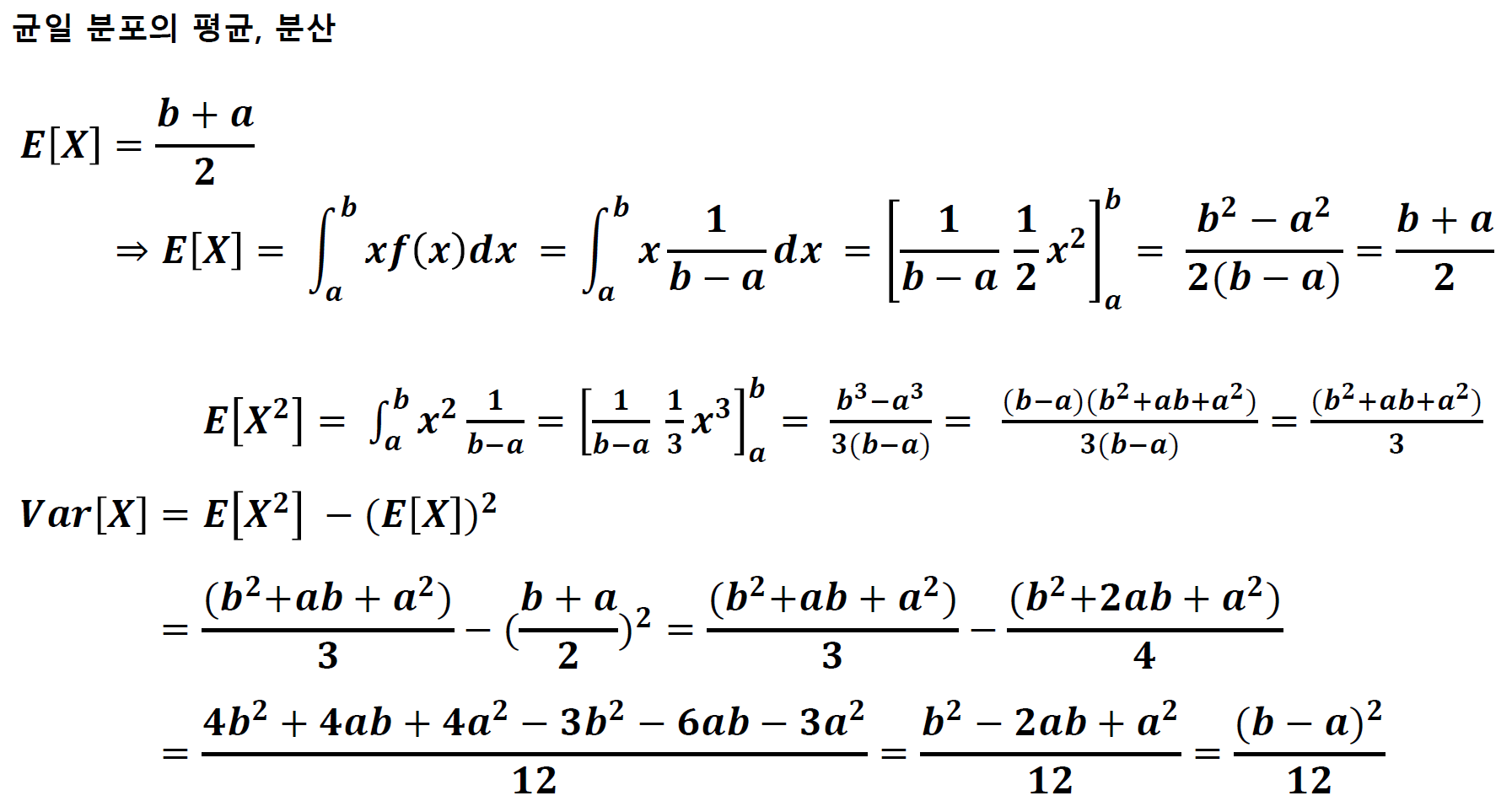
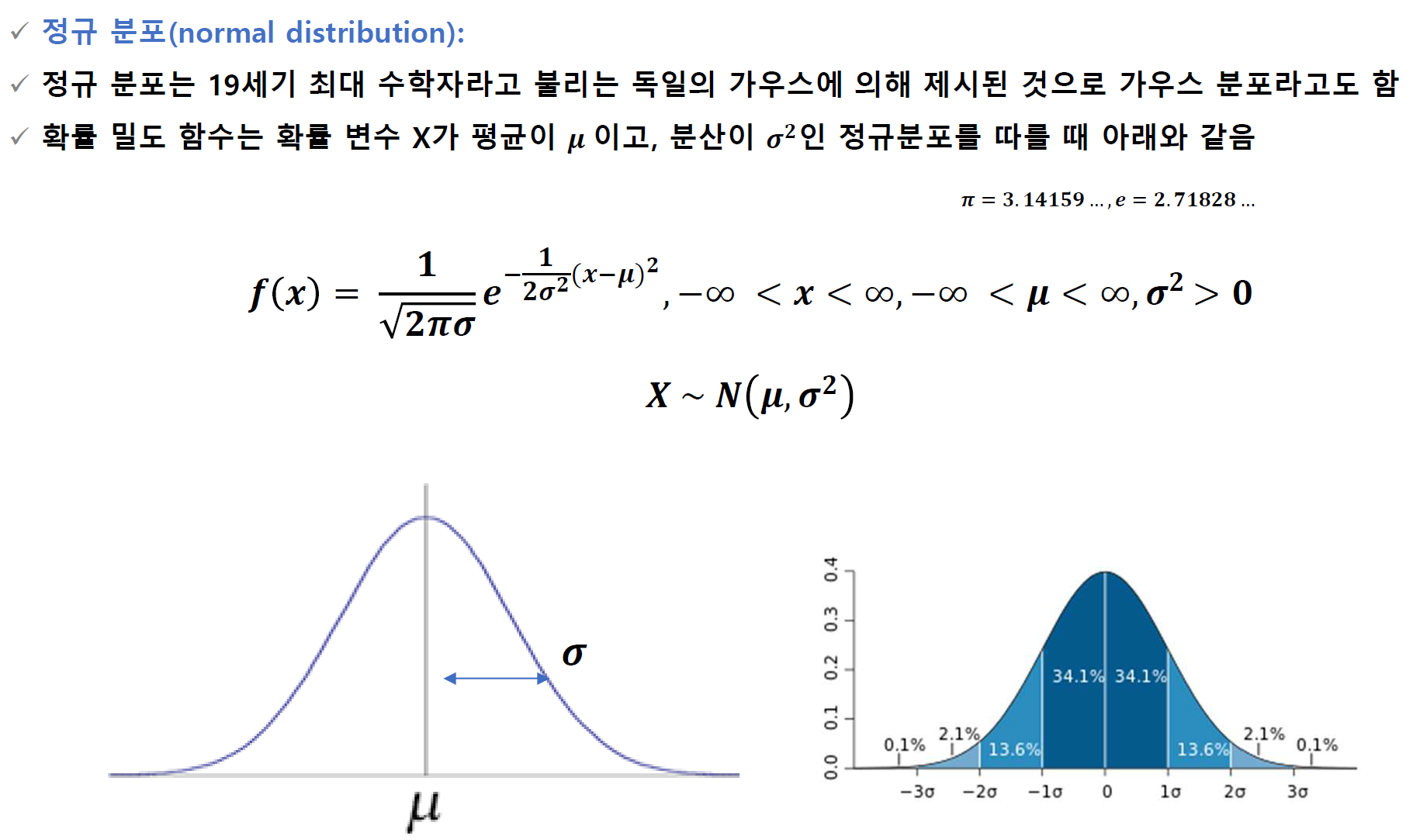
🔰 정규분포

🔰 표준정규분포
-
Standard Normal Distribution
-
평균이 0이고 분산이 1인 정규분포 을 표준정규분포라고 한다.
-
확률변수 가 표준정규분포 을 따를 때, 의 확률밀도함수는
-
정규분포의 표준화
확률변수 가 정규분포 을 따를 때,
확률변수 은 표준정규분포 을 따른다.
이와 같이 정규분포 을 따르는 확률변수 를
표준정규분포 을 따르는 확률변수 으로 바꾸는 것을 표준화라고 한다. -
확률변수 가 정규분포 을 따른다면
으로 표준화한 후, 표준정규분포표를 이용한다.-
ex.
-
-
-
-
일 때, 을 구하시오
-
-
-
표준정규분포표
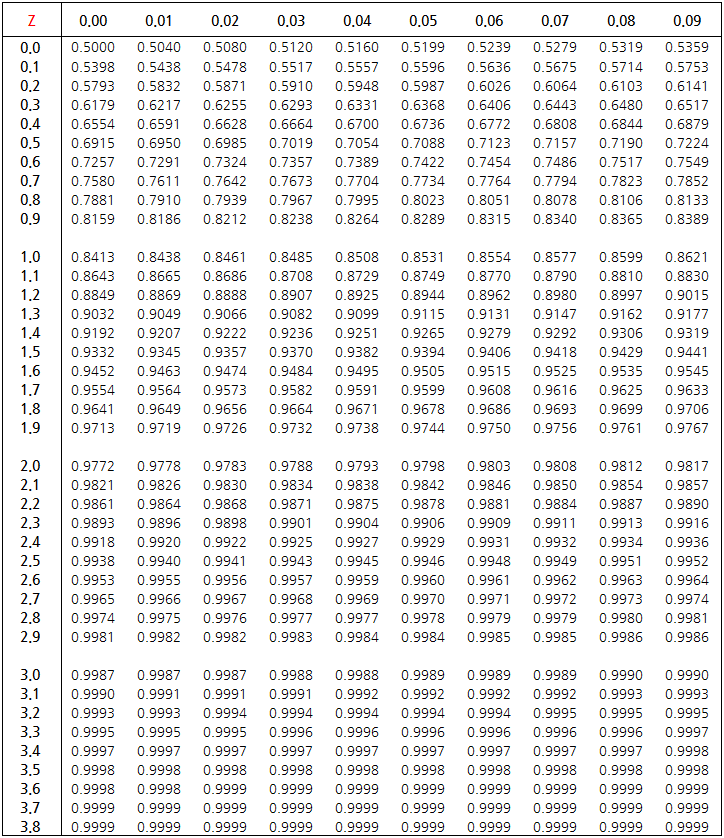
🔰 지수분포
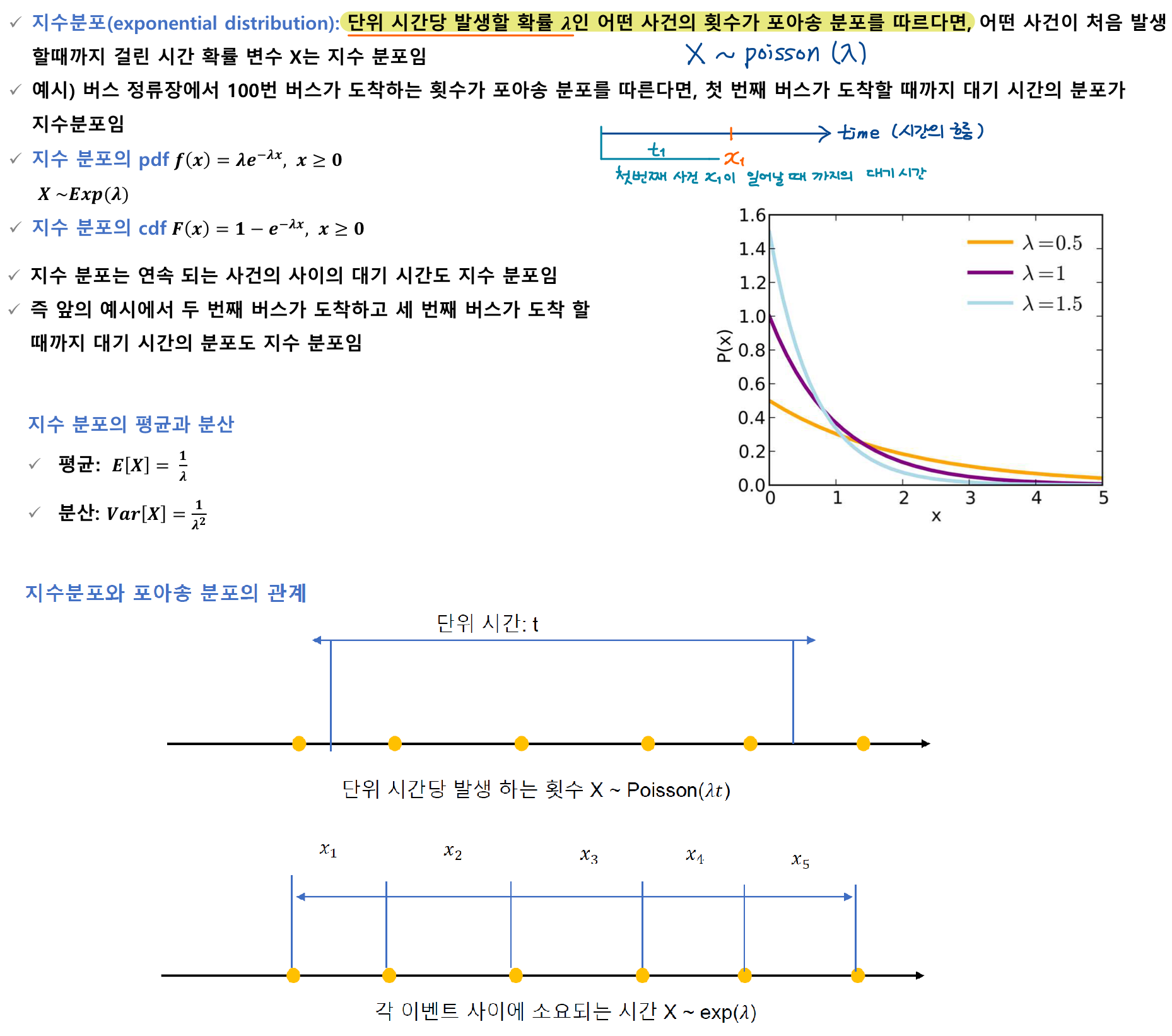

<확률분포 관계도>
표본분포
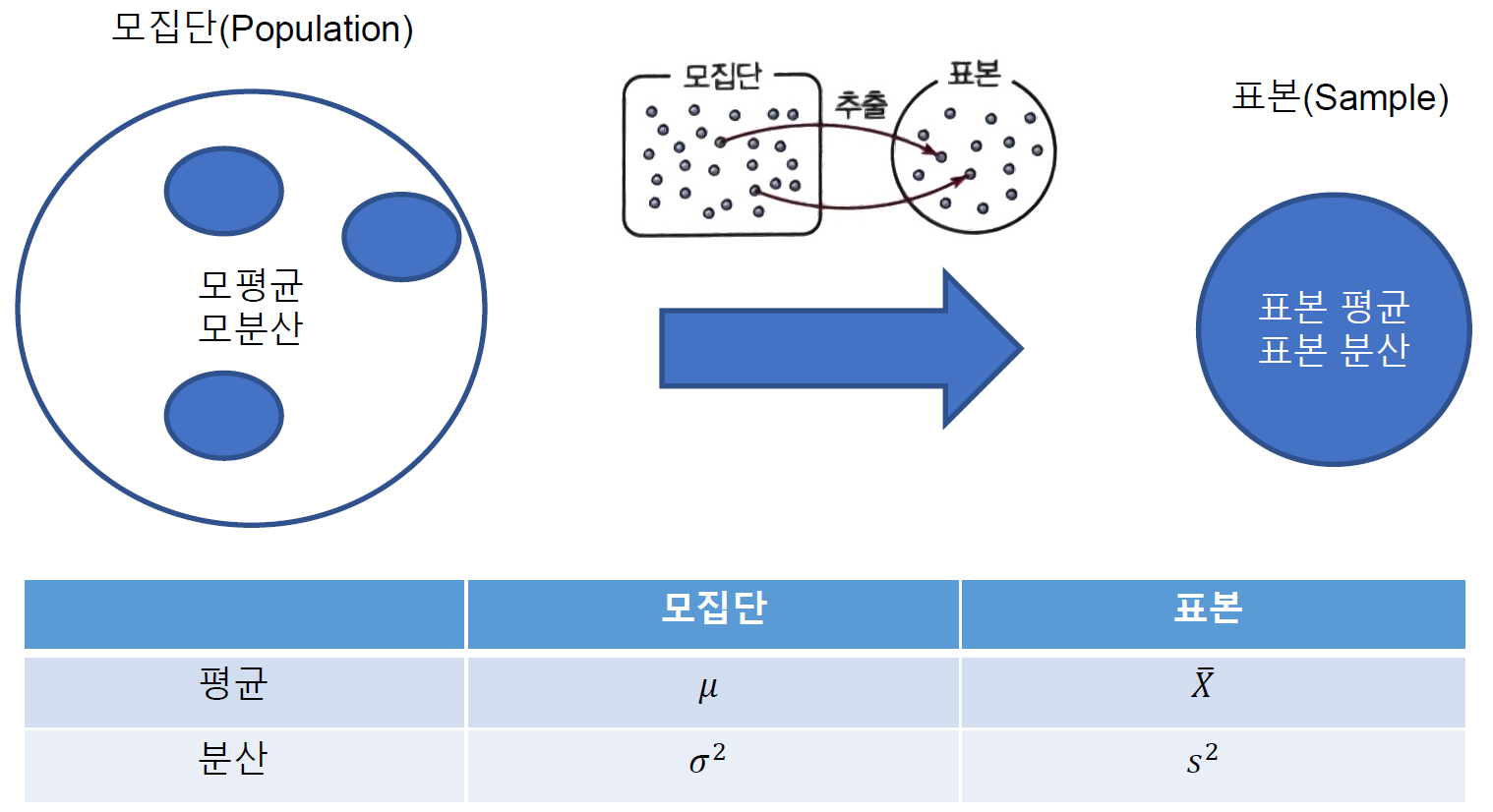
모집단(Population)
통계 조사에서 조사하고자 하는 대상 전체를 모집단이라고 한다.
어느 모집단에서 조사하고자 하는 특성을 나타내는 확률변수를 라 할 때,
의 평균, 분산, 표준편차를 각각 모평균모분산모표준편차 라 한다.
표본(Sample)
통계 조사를 위해 뽑은 모집단의 일부분을 표본이라고 한다.
표본조사에서 뽑은 표본의 개수를 표본의 크기라고 한다.
-
모집단으로 부터 표본을 추출 하는 것을 Sampling이라고 하며, 표본으로부터 그 특성을 찾아내고 모집단의 특성을 추론하고자 하는 것이다.
-
모집단에서 표본을 추출하는 방법에는 여러 가지가 있다.
-
복원추출(Sampling with replacement)
모집단에서 데이터를 추출 할 때 하나를 추출하고 다시 넣고 추출하는 방법으로 동일한 표본이 추출 될 수 있다. -
비복원추출(Sampling without replacement)
모집단에서 데이터를 추출 할 때 하나를 추출하고 다시 넣지 않고 추출하는 방법이다. -
Random Sampling
모집단에서 데이터를 추출할 때 주의할 점은 편향되지 않아야 함, 각 개체가 모두 동일한 확률로 추출하는 방법이다.
-
통계량(Statistic)
표본에 기초하여 계산되는 수치 함수를 통계량이라고 한다.
-
모집단에서 임의추출한 크기가 인 표본에서 각 대상을 이라 할 때,
-
표본평균(Sample mean)
-
표본분산(Sample variance)
-
표본표준편차(Sample standard deviation)
-
-
모평균이 모표준편차가 인 모집단에서 임의추출한 크기가 인 표본의 표본평균 에 대하여
-
표본평균 의 기대값
-
표본평균 의 분산
-
표본평균 의 표준편차
-
ex.
모평균이 20, 모표준편차가 4인 모집단에서 임의 추출한 크기가 4인 표본의 표본평균을 라 하면
-
-
표본평균의 분포
정규분포 을 따르는 모집단에서 임의추출한 크기가 인 표본의 표본평균을 라 할 때, 는 정규분포 을 따른다.
- ex.
정규분포 을 따르는 모집단에서 크기가 9인 표본을 임의추출할 때, 표본평균을 라하면 는 정규분포 즉 을 따른다.
- ex.
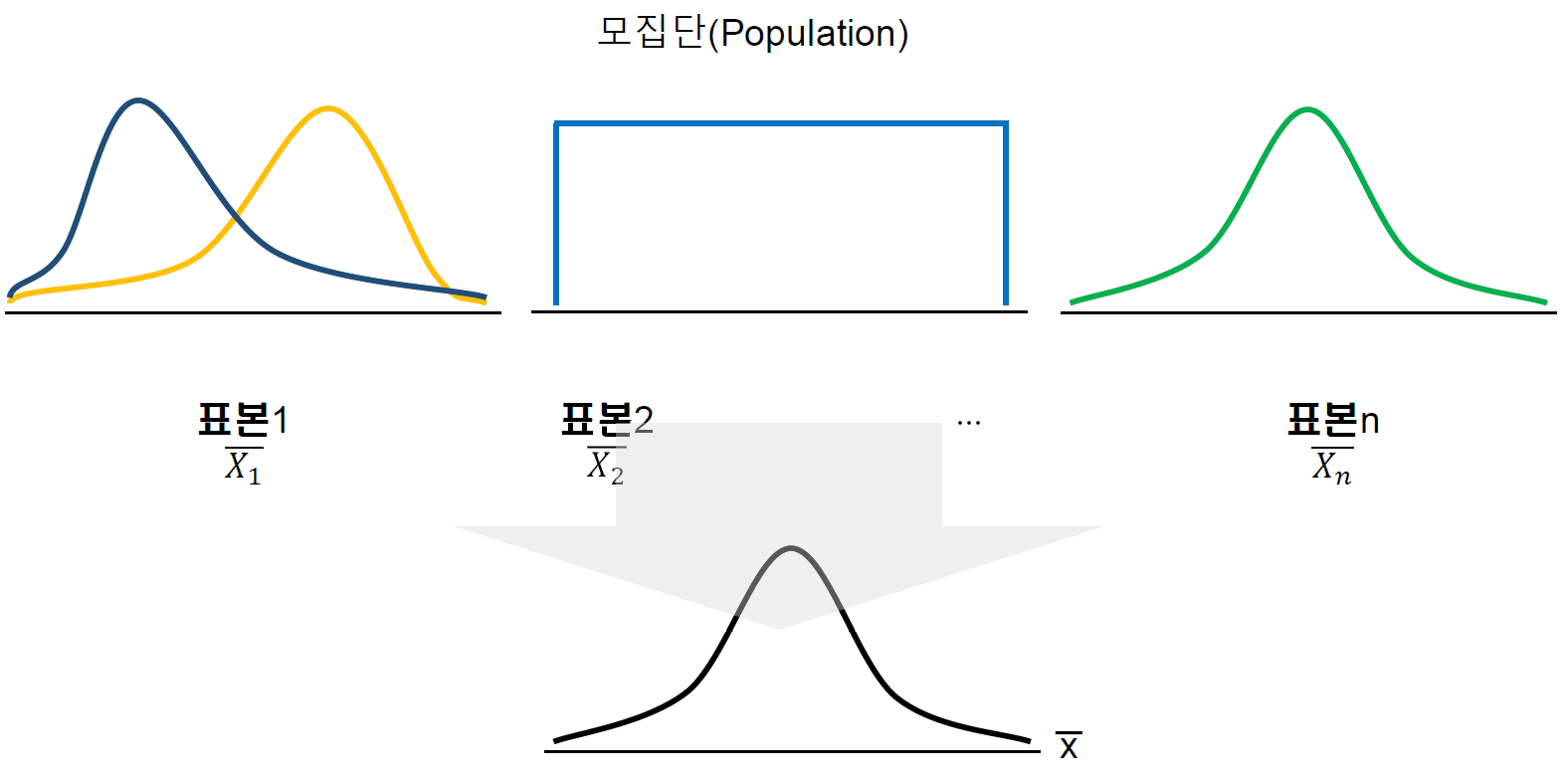
🔰 중심극한정리
-
Central Limit Theorem
-
평균이 이고 분산이 인 임의의 모집단에서 랜덤 표본 을 추출할 때 표본의 크기 이 충분히 크면 표본 평균 은 근사적으로 정규분포 을 따른다.
-
ex.

-
모집단의 분포가 정규분포가 아닐 때라도 이 충분히 크다면 는 근사적으로 정규분포 을 따른다.
🔰 카이제곱분포
🔰 T분포
🔰 F분포
