
실습 도구 3️⃣
【웹 데이터 분석】에 사용된 라이브러리
Beautiful Soup 4
HTML 뿐만 아니라 XML과 같이 태그로 구조화된 언어를 파싱하고 해석 및 검색하는 파이썬 라이브러리이다. 이 라이브러리를 사용하면 웹 스크레이핑 및 데이터 추출과 같은 작업을 쉽게 수행할 수 있다.
- 예제: 03. test_first.html
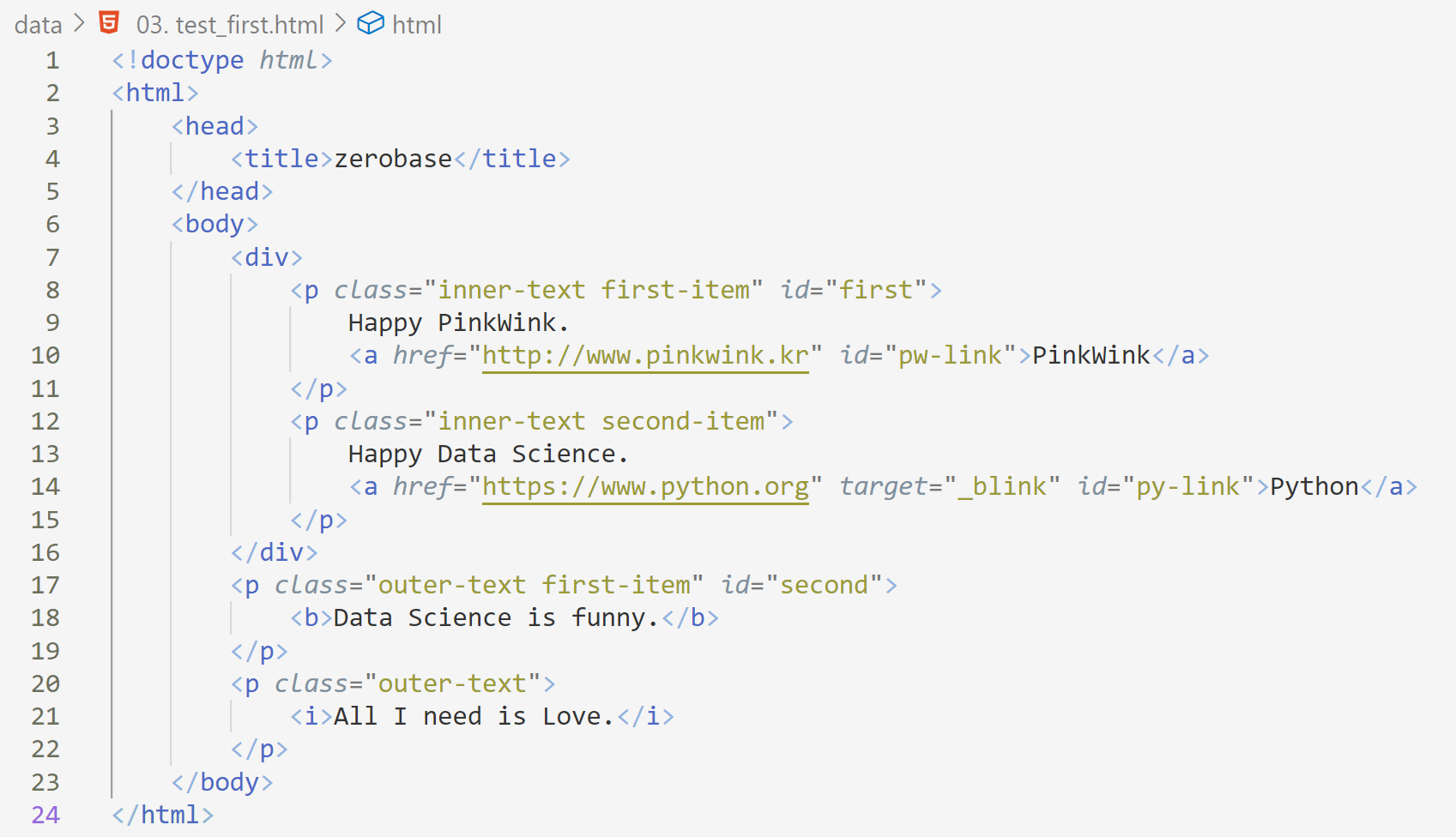
🔰 WebPage에서 HTML가져오기
from bs4 import BeautifulSoup page = open("../data/03. test_first.html", "r").read()
soup = BeautifulSoup(page, "html.parser")"html.parser": Beautiful Soup에서 html을 읽는 엔진 중 하나이다.
🔰 원하는 태그/속성 검색
soup.head # head tag 확인
soup.body # body tag 확인
soup.title # title tag 확인
soup.div # div tag 확인
soup.p # p tag 확인❕ find()
- 원하는 특정 태그를 검색하는 데 사용
- 첫 번째로 일치하는 태그를 찾아 반환한다.
- 사용하는 인자들은 다양하게 조합하여 활용할 수 있다.
soup.find("p")
soup.find("p", class_="inner-text second-item")
soup.find("p", {"class": "outer-text first-item"})
soup.find("p", {"class": "inner-text first-item", "id": "first"})❕ find_all()
- 지정된 모든 태그를 검색하는 데 사용
- 조건에 맞는 모든 태그를 찾아 리스트로 반환한다.
- 반복문을 사용해 각 태그의 텍스트를 추출할 수 있다.
- 클래스, 아이디, 속성 등을 지정하여 좀 더 구체적으로 원하는 태그를 찾을 수 있다.
soup.find_all("p")
soup.find_all("p", class_="inner-text second-item")
soup.find_all(class_="outer-text")
soup.find_all(id="first")
soup.find_all(id="pw-link")[0].text
soup.find_all(id="pw-link")[0].string
soup.find_all(id="pw-link")[0].get_text()❕ select_one()
- 하나의 요소를 선택
- CSS Selectors나 XPath를 사용해 원하는 요소를 선택하는 데 사용
- 지정된 CSS Selectors나 XPath에 맞는 첫 번째 요소를 선택해 단일 형태로 반환한다.
tag_name: 태그 선택.class: 클래스 선택#id: 아이디 선택>: 특정 요소의 자식 요소를 선택(space): 특정 요소의 모든 하위 요소를 선택[attribute]: attribute 속성을 가진 요소 선택[attribute=value]: attribute 속성의 값이 특정 값인 요소 선택selector1, selector2: selector1 또는 selector2 요소 선택selector1 selector2: selector1 내부의 모든 selector2 요소 선택
❕ select()
- 여러 요소를 선택
- CSS Selectors나 XPath를 사용해 원하는 요소를 선택하는 데 사용
- 지정된 CSS Selectors나 XPath에 맞는 모든 요소를 선택해 리스트 형태로 반환한다.
🔰 특정 태그의 내용 추출
soup.find("p", {"class": "outer-text first-item"}).text
soup.find("p", {"class": "outer-text first-item"}).get_text()❕ get()
- 태그 내 해당 속성값을 가져온다.
soup.find_all("a")[0].get("href")
ISTP(정신승리), To Be Data Scientist