< 스프링 DB 1편 - 데이터 접근 핵심 원리> 강의를 보고 이해한 내용을 바탕으로 합니다.
JDBC 등장 이유
애플리케이션을 개발할 때 중요한 데이터는 대부분 데이터베이스에 보관한다.
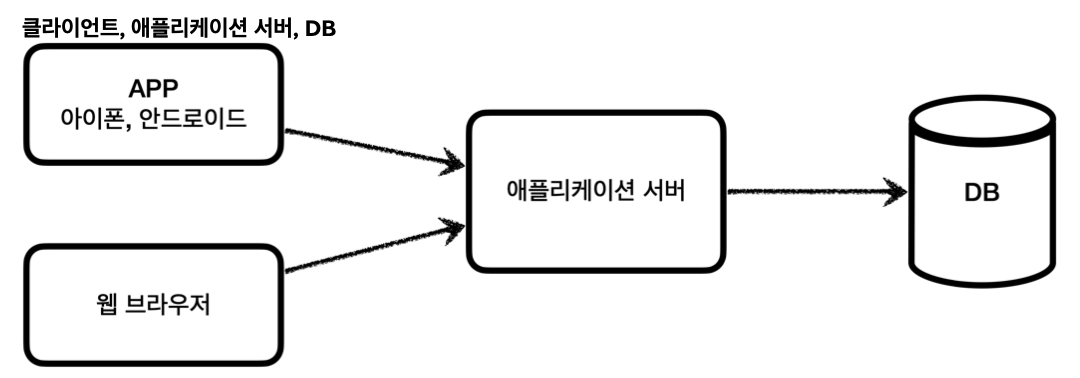
클라이언트가 애플리케이션 서버를 통해 데이터를 저장하거나 조회하면, 애플리케이션 서버는 다음 과정을 통해 데이터베이스를 사용한다.
- 커넥션 연결
주로 TCP/IP를 사용해서 커넥션을 연결 - SQL 전달
애플리케이션 서버는 DB가 이해할 수 있는 SQL을 연결된 커넥션을 통해 DB에 전달 - 결과 응답
DB는 SQL을 수행하고 그 결과를 응답. (애플리케이션 서버는 응답 결과를 활용)
문제는 각각의 데이터베이스마다 1.커넥션을 연결하는 방법, 2.SQL을 전달하는 방법, 그리고 3.결과를 응답 받는 방법이 모두 달랐다는 점이다.
따라서 아래와 같은 문제가 발생한다.
- 데이터베이스를 변경하면 애플리케이션 서버에 개발된 데이터베이스 사용 코드도 함께 변경해야 한다.
- 데이터베이스마다 커넥션 연결, SQL 전달, 결과를 응답 받는 방법을 새로 학습해야 한다.
=> 위 문제들을 해결하기 위해 JDBC라는 자바 표준이 등장했다.
JDBC 표준 인터페이스
JDBC (Java DataBase Connectivity) : 자바에서 데이터베이스에 접속할 수 있도록 하는 자바 API. JDBC는 데이터베이스에서 자료를 질의하거나 업데이트하는 방법을 제공한다.
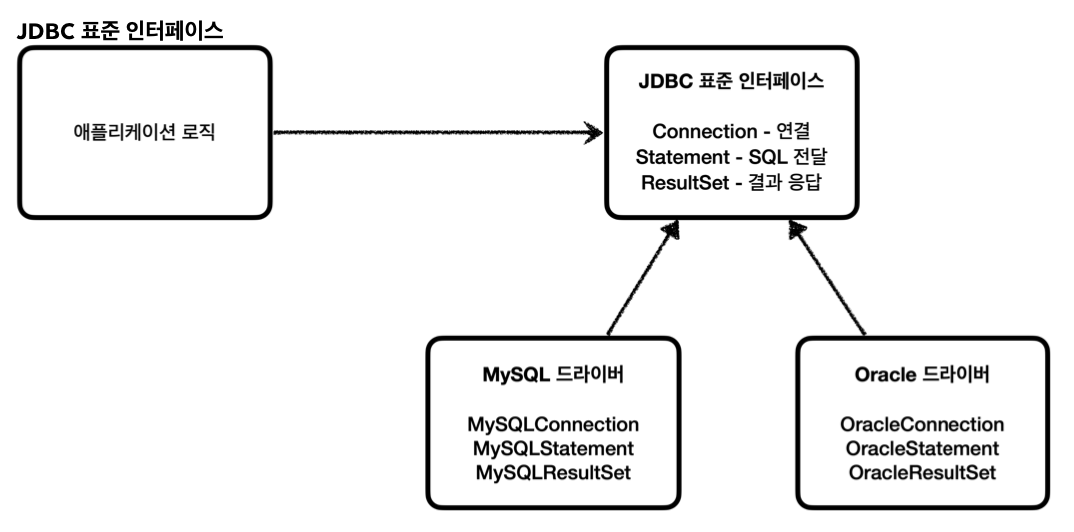
대표적으로 다음 세가지 기능을 표준 인터페이스로 정의해서 제공한다.
java.sql.Connection: 연결java.sql.Statement: SQL을 담은 내용java.sql.ResultSet: SQL 요청 응답
각각의 DB회사에서 이 JDBC 인터페이스를 구현해서 라이브러리로 제공한다.
이를 JDBC 드라이버라 한다.
- MySQL JDBC 드라이버 - MySQL DB에 접근
- Oracle JDBC 드라이버 - Oracle DB에 접근
JDBC의 등장으로 다음 두가지 문제가 해결되었다.
-
데이터베이스를 변경하면 애플리케이션 서버에 개발된 데이터베이스 사용 코드도 함께 변경해야 한다.
--> 애플리케이션 로직은 이제 JDBC 표준 인터페이스에만 의존하므로, 다른 데이터베이스로 변경하고 싶으면 JDBC 구현 라이브러리만 변경하면 된다.
=> 데이터베이스를 변경해도 애플리케이션 서버의 코드 그대로 유지 가능. -
데이터베이스마다 커넥션 연결, SQL 전달, 결과를 응답 받는 방법을 새로 학습해야 한다.
--> JDBC 표준 인터페이스 사용법만 학습하면 된다. (한번 배워두면 수십개의 데이터베이스에 모두 동일하게 적용할 수 있다.)
표준화의 한계
JDBC의 등장으로 많은 것이 편리해졌지만 각각의 데이터베이스마다 SQL, 데이터 타입 등의 일부 사용법이 다르다. 결국 데이터베이스를 변경하면 JDBC 코드는 변경하지 않아도 되지만 SQL은 해당 데이터베이스에 맞도록 변경해야한다.
(참고로 JPA를 사용하면 이렇게 각각의 데이터베이스마다 다른 SQL을 정의해야하는 문제도 많은 부분 해결할 수 있다.)
JDBC와 최신 데이터 접근 기술
JDBC는 1997년에 출시될 정도로 오래된 기술이고 사용하는 방법도 복잡하다.
따라서 JDBC를 직접 사용하기보다는 JDBC를 편리하게 사용하는 SQL Mapper와 ORM과 같은 기술들을 사용한다.
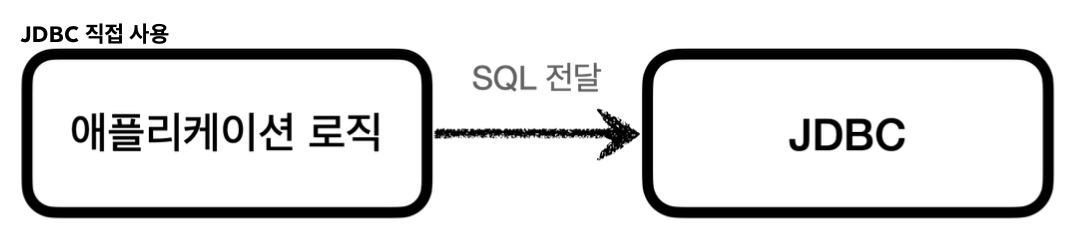

SQL Mapper
(스프링 JdbcTemplate, MyBatis..)
장점 : JDBC를 편리하게 사용하도록 도와준다.
- SQL 응답 결과를 객체로 편리하게 변환해준다.
- JDBC의 반복 코드를 제거해준다.
단점 : 개발자가 SQL을 직접 작성해야한다.
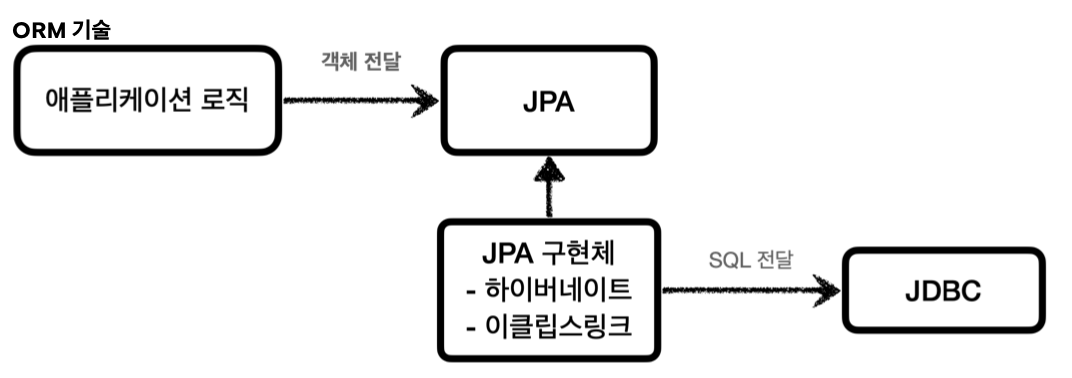
ORM 기술
- 객체를 관계형 데이터베이스 테이블과 매핑해주는 기술. 개발자는 반복적인 SQL을 직접 작성하지 않고, ORM이 SQL을 동적으로 만들어 실행해준다. 데이터베이스마다 다른 SQL을 사용하는 문제도 중간에서 해결해준다.
- JPA, 하이버네이트, 이클립스링크
- JPA는 자바 진영의 ORM 표준 인터페이스이고, 이것을 구현한 것으로 하이버네이트와 이클립스링크 등의 구현 기술이 있다.
SQL Mapper vs ORM
각각 장단점이 있다.
SQL Mapper는 SQL만 직접 작성하면 나머지 번거로운 일은 SQL Mapper가 대신 해결해준다. SQL만 작성할 줄 알면 금방 배워서 사용할 수 있다.
ORM 기술은 SQL 자체를 작성하지 않아도 되므로 개발 생산성이 매우 높아진다. 편리한 반면에 쉬운 기술은 아니므로 실무에서 사용하려면 깊이있게 학습해야 한다.
이런 기술들도 내부에서는 모두 JDBC를 사용한다. 따라서 JDBC를 직접 사용하지는 않더라도 JDBC가 어떻게 동작하는지 기본 원리를 알아두어야한다. 그래야 해당 기술들을 더 깊이있게 이해할 수 있고, 문제가 발생했을 때 근본적인 문제를 찾아서 해결할 수 있다. (JDBC는 자바 개발자라면 꼭 알아두어야하는 필수 기본 기술이다!!)
데이터베이스 연결
H2 DB에 연결해보기.
public abstract class ConnectionConst {
public static final String URL = "jdbc:h2:tcp://localhost/~/test";
public static final String USERNAME = "sa";
public static final String PASSWORD = "";
}@Slf4j
public class DBConnectionUtil {
public static Connection getConnection(){
try{
Connection connection = DriverManager.getConnection(URL, USERNAME, PASSWORD);
log.info("get connection={}, class={}", connection, connection.getClass());
return connection;
} catch (SQLException e) {
throw new IllegalStateException(e);
}
}
}JDBC가 제공하는 DriverManager.getConnection(...)으로 데이터베이스에 연결할 수 있다. 라이브러리에 있는 데이터베이스 드라이버를 찾아서 해당 드라이버가 제공하는 커넥션을 반환해준다.
@Slf4j
public class DBConnectionUtillTest {
@Test
void connection(){
Connection connection = DBConnectionUtil.getConnection();
Assertions.assertThat(connection).isNotNull();
}
}테스트 코드로 결과를 확인해보니 다음과 같았다.
get connection=conn0: url=jdbc:h2:tcp://localhost/~/test user=SA, class=class org.h2.jdbc.JdbcConnectionclass=class org.h2.jdbc.JdbcConnection : H2 데이터베이스 드라이버가 제공하는 H2 전용 커넥션. (JDBC 표준 커넥션 인터페이스인 java.sql.Connection 인터페이스를 구현)
JDBC DriverManager 연결

- JDBC는
java.sql.Connection표준 커넥션 인터페이스를 정의한다. - H2 데이터베이스 드라이버는 JDBC Connection 인터페이스를 구현한
org.h2.jdbc.JdbcConnection구현체를 제공한다.
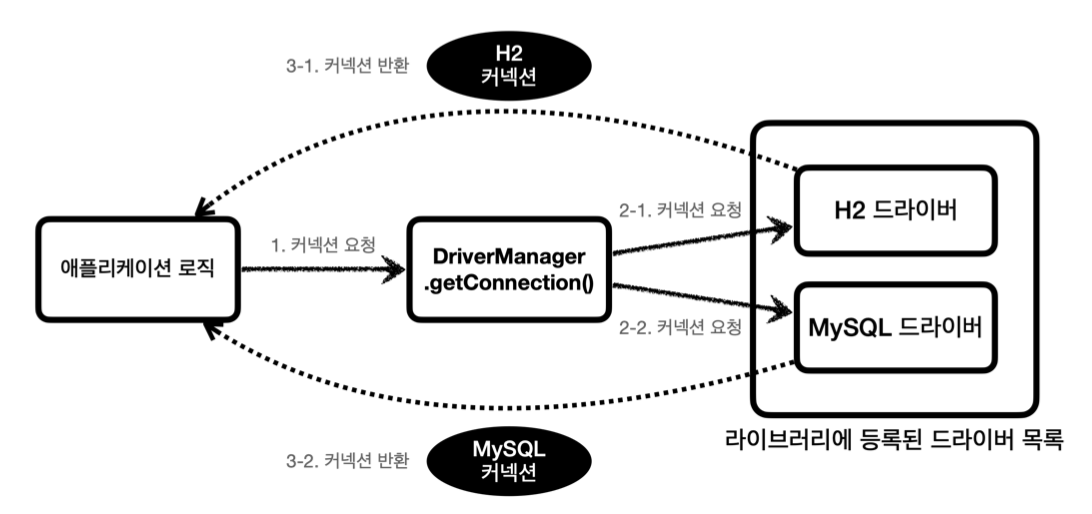
JDBC가 제공하는 DriverManager는 DB 드라이버들을 관리하고 커넥션을 획득하는 기능을 제공한다.
- 커넥션이 필요하면
DriverManager.getConnection()을 호출한다. DriverManager는 라이브러리에 등록된 드라이버 목록을 자동으로 인식한다. 이 드라이버들에게 순서대로 다음 정보를 넘겨서 커넥션을 획득할 수 있는지 확인한다.- URL :
jdbc:h2:tcp://localhost/~/test - 이름, 비밀번호 등 접속에 필요한 추가 정보
- 여기서 각각의 드라이버는 URL 정보를 체크해서 본인이 처리할 수 있는 요청인지 확인한다.
- 예를들어 URL이
jdbc:h2로 시작하면 이것은 h2 데이터베이스에 접근하기 위한 규칙이다. 따라서 H2 드라이버는 본인이 처리할 수 있으므로 실제 데이터베이스에 연결해서 커넥션을 획득하고 이 커넥션을 클라이언트에 반환한다. 반면에 URL이jdbc:h2로 시작했는데 MySQL 드라이버가 먼저 실행되면 이 경우 본인이 처리할 수 없다는 결과를 반환하게 되고 다음 드라이버에게 순서가 넘어간다.
- 예를들어 URL이
- URL :
- 이렇게 찾은 커넥션 구현체가 클라이언트에 반환된다.
JDBC 개발
1) 등록
/**
* JDBC - DriverManager 사용
*/
@Slf4j
public class MemberRepositoryV0 {
public Member save(Member member) throws SQLException {
String sql = "insert into member(member_id, money) values (?, ?)";
Connection con = null;
PreparedStatement pstmt = null;
try{
con = getConnection();
pstmt = con.prepareStatement(sql);
pstmt.setString(1, member.getMemberId()); //파라미터 바인딩
pstmt.setInt(2, member.getMoney()); //파라미터 바인딩
pstmt.executeUpdate();
return member;
} catch(SQLException e) {
log.error("db error", e);
throw e;
} finally {
close(con, pstmt, null);
}
}
private void close(Connection con, Statement stmt, ResultSet rs){ //Statement : sql 그대로 넣기, PreparedStatement: 파라미터 바인딩 Statement 상속ㅂㄷ음
if (rs != null){
try {
rs.close();
} catch (SQLException e) {
log.info("error", e);
}
}
if (stmt != null){
try {
stmt.close(); //Exception이 나면 밑에 코드 실행 안되면서 커넥션이 종료가 안됨. 그래서 try catch 필요
} catch (SQLException e) {
log.info("error", e);
}
}
if (con != null){
try {
con.close();
} catch (SQLException e) {
log.info("error", e);
}
}
}
private Connection getConnection(){
return DBConnectionUtil.getConnection();
}
}1. 커넥션 획득
getConnection() : 이전에 만들어둔 DBConnectionUtil을 통해서 데이터베이스 커넥션을 획득한다.
2. save() - SQL 전달
sql: 데이터베이스에 전달할 SQL을 정의한다. 여기서는 데이터를 등록해야 하므로insert sql준비.con.prepareStatement(sql): 데이터베이스에 전달할 SQL과 파라미터로 전달할 데이터들을 준비한다.sql:insert into member(member_id, money) values(?, ?)"pstmt.setString(1, member.getMemberId()): SQL의 첫번째?에 값을 지정한다. 문자이므로setString을 사용한다.pstmt.setInt(2, member.getMoney()): SQL의 두번째?에 값을 지정한다.Int형 숫자이므로setInt를 지정한다.
pstmt.executeUpdate():Statement를 통해 준비된 SQL을 커넥션을 통해 실제 데이터베이스에 전달한다. 참고로executeUpdate()은int를 반환하는데 영향받은 DB row 수를 반환한다. 여기서는 하나의 row 를 등록했으므로 1을 반환한다.
3. 리소스 정리
쿼리를 실행하고 나면 리소스를 정리해야 한다. 여기서는 Connection, PreparedStatement를 사용했다. 리소스를 정리할 때는 항상 역순으로 해야한다. Connection을 먼저 획득하고 Connection을 통해 PreparedStatement를 만들었기 때문에 리소스를 반환할 때는 PreparedStatement을 먼저 종료하고 그 다음에 Connection을 종료하면 된다.
리소스 정리는 꼭!! 해주어야 한다. 예외가 발생하든 하지 않든 항상 수행되어야 하므로
finally구문에 주의해서 작성해야한다. 만약 이 부분을 놓치게 되면 커넥션이 끊어지지 않고 계속 유지되는 문제가 발생할 수 있다. 이런 것을 리소스 누수라고 하는데 결과적으로 커넥션 부족으로 장애가 발생할 수 있다.
PreparedStatement는Statement의 자식 타입인데?를 통한 파라미터 바인딩을 가능하게 해준다. 참고로 SQL Injection공격을 예방하려면PreparedStatement를 통한 파라미터 바인딩 방식을 사용해야 한다.
2) 조회
public Member findById(String memberId) throws SQLException {
String sql = "select * from member where member_id = ?";
Connection con = null;
PreparedStatement pstmt = null;
ResultSet rs = null;
try {
con = getConnection();
pstmt = con.prepareStatement(sql);
pstmt.setString(1, memberId);
rs= pstmt.executeQuery();//select
if(rs.next()){
Member member = new Member();
member.setMemberId(rs.getString("member_id"));
member.setMoney(rs.getInt("money"));
return member;
} else{
throw new NoSuchElementException("member not found memberId=" + memberId);
}
} catch (SQLException e) {
log.error("db error", e);
throw e;
} finally {
close(con, pstmt, rs);
}
}findById 쿼리 실행
sql: 데이터 조회를 위한 select SQL을 준비한다.rs = pstmt.executeQuery(): 데이터 조회 (데이터를 변경할 때는executeUpdate())executeQuery()는 결과를ResultSet에 담아서 반환한다.
executeQuery()
select 쿼리 시 사용. ResultSet을 반환.
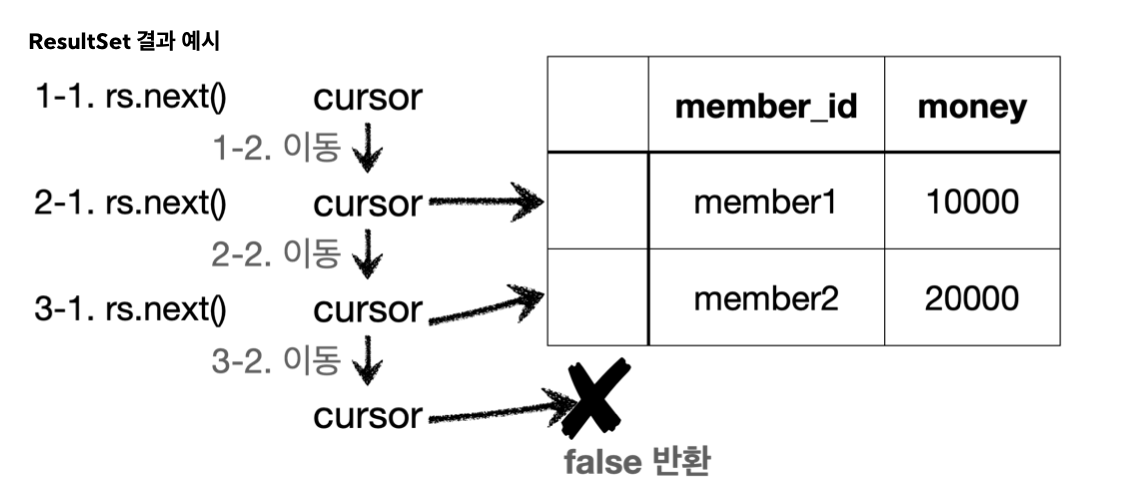
ResultSet
ResultSet은 다음과 같이 생긴 데이터 구조이다. 보통 select 쿼리의 결과가 순서대로 들어간다.- 예를 들어서
select member_id, money라고 지정하면member_id,money라는 이름으로 데이터가 저장된다.
- 예를 들어서
ResultSet내부에 있는 커서(cursor)를 이동해서 다음 데이터를 조회할 수 있다.rs.next(): 이것을 호출하면 커서가 다음으로 이동한다. 참고로 최초의 커서는 데이터를 가리키고 있지 않기 때문에rs.next()를 최초 한번은 호출해야 데이터를 조회할 수 있다.rs.next()의 결과가true면 커서의 이동 결과 데이터가 있다는 뜻이다.rs.next()의 결과가false면 더이상 커서가 가리키는 데이터가 없다는 뜻이다.
rs.getString("member_id"): 현재 커서가 가리키고 있는 위치의member_id데이터를String타입으로 반환한다.rs.getInt("money"): 현재 커서가 가리키고 있는 위치의money데이터를int타입으로 반환한다.
3) 수정, 삭제
public void update(String memberId, int money) throws SQLException {
String sql = "update member set money=? where member_id=? ";
Connection con = null;
PreparedStatement pstmt = null;
try{
con = getConnection();
pstmt = con.prepareStatement(sql);
pstmt.setInt(1, money); //파라미터 바인딩
pstmt.setString(2, memberId); //파라미터 바인딩
int resultSize = pstmt.executeUpdate();
log.info("resultSize={}", resultSize);
} catch(SQLException e) {
log.error("db error", e);
throw e;
} finally {
close(con, pstmt, null);
}
}public void delete(String memberId) throws SQLException {
String sql = "delete from member where member_id=?";
Connection con = null;
PreparedStatement pstmt = null;
try{
con = getConnection();
pstmt = con.prepareStatement(sql);
pstmt.setString(1, memberId); //파라미터 바인딩
int resultSize = pstmt.executeUpdate();
} catch(SQLException e) {
log.error("db error", e);
throw e;
} finally {
close(con, pstmt, null);
}
}- 회원을 삭제한 다음
findById()를 통해서 조회한다. 회원이 없기 때문에NoSuchElementException이 발생한다.
전체 테스트 코드
@Slf4j
class MemberRepositoryV0Test {
MemberRepositoryV0 repositoryV0 = new MemberRepositoryV0();
@Test
void crud() throws SQLException {
//save
Member memberV0 = new Member("memberV100", 10000);
repositoryV0.save(memberV0);
//findById
Member findMember = repositoryV0.findById(memberV0.getMemberId());
log.info("findMember={}", findMember);
Assertions.assertThat(findMember).isEqualTo(memberV0);
//update : money 10000 -> 20000
repositoryV0.update(memberV0.getMemberId(), 20000);
Member updatedMember = repositoryV0.findById(memberV0.getMemberId());
Assertions.assertThat(updatedMember.getMoney()).isEqualTo(20000);
//delete
repositoryV0.delete(memberV0.getMemberId());
Assertions.assertThatThrownBy(() -> repositoryV0.findById(memberV0.getMemberId()))
.isInstanceOf(NoSuchElementException.class);
}
}assertThatThrownBy는 해당 예외가 발생해야 검증에 성공한다.
