벡터란?
벡터는 숫자를 원소로 가지는 리스트로 공간좌표에서 한 점을 의미한다. ← 한 점이라는거 매우매우 중요.. 컴퓨터로 표현할 때 하나의 행 벡터로 표현된다는 것을 알면 좋음
추가) matrix도 벡터이다. MLP에 넣을 때는 벡터(1차원 벡터)에 넣고, CNN에 넣을 때는 2차원 벡터를 이용한다.
norm(노름)
norm은 원점으로부터의 거리를 말한다. 노름은 L1노름과 L2노름으로 나눠진다.
L1 노름: 벡터 성분의 절댓값의 총합
L2 노름: (벡터 성분의 제곱값의 총합)^(1/2)
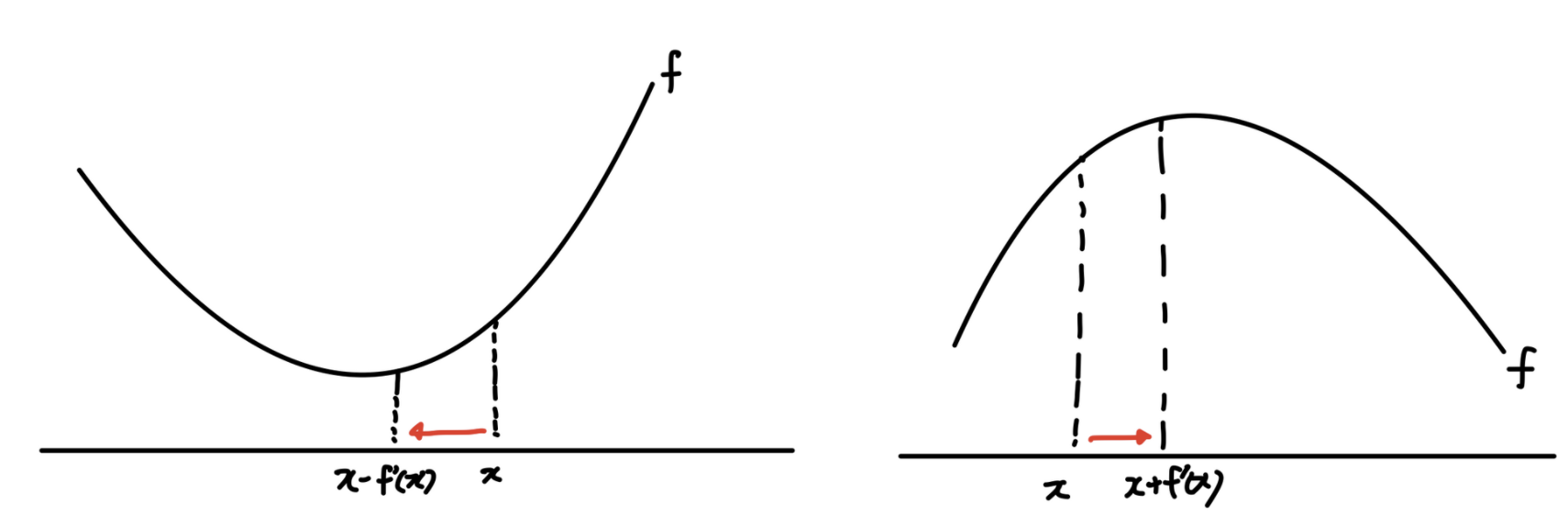
경사 하강법, 경사 상승법
경사 하강법은 미분을 이용하여 함수의 극소값을 찾을 때 이용한다. 이는 목적함수를 최소화 할 때 사용된다.(ex loss function) 예를 들어 함수 f의 주어진 점 (x, f(x))에서 f(x)가 작아지는 방향으로 x를 업데이트 할 때 x ← x - f’(x)를 업데이트 해주면 된다.
마찬가지로 경사 상승법은 미분을 이용하여 함수의 극대값을 찾을 때 이용한다. 경사하강법과 반대로 목적함수를 최소화 할 때 사용한다. 경사하강법과 비슷하게 함수 f에서 주어진 점 (x, f(x))에서 f(x)가 작아지는 방향으로 x를 업데이트 할 때 x ← x + f’(x)를 업데이트 해주면 된다.
모수를 추정하기 위한 개념
통계적 모델링은 적절한 가정이 있을 때 확률 분포를 추정하는 것이 목표다. 하지만 모집단의 분포를 정확하게 알기는 불가능 하므로 근사적으로 확률분포를 추정할 수 밖에 없다.
여기서 분포를 결정하는 모수 라는 개념을 이용하여 데이터가 특정 분포를 따른다 하였을 때 특정 분포를 결정하는 모수(ex: 정규분포에서 평균, 분산)을 추정하는 방법이다. 이는 모수적 방법론이라 한다. 하지만 특정 분포를 가정하지 않고 모수가 개수가 너무 많거나 데이터에 따라 다를 때 비모수 방법론이라 한다.
Likelihood
가능도 함수는 데이터가 주어져 있는 상황에서 θ(모수)를 변형 시킴에 따라 값이 바뀌는 함수이다. 즉 어떤 값이 관측되었을 때, 이것이 어떤 확률 분포에서 왔을지에 대한 확률로 이해하면 된다.
참고: https://jjangjjong.tistory.com/41
최대가능도 추정법(maximum likelihood estimation, MLE)
최대가능도 추정법이란 어떠한 데이터에 대해 분포의 likelihood를 maximize하는 모수 θ를 찾는 방법이다.
보통 컴퓨터상으로 계산을 할 때 log를 씌어 계산에 용이하도록 도와준다.
최대가능도 추정법을 통해 정규분포, 카테고리분포, 베르누이분포…등등의 모수θ를 찾는 방법
참고: https://datascienceschool.net/02 mathematics/09.02 최대가능도 추정법.html
+딥러닝에서 최대가능도 추정법
딥러닝 모델의 가중치를 θ=(W(1),...,W(L)) 라 표기했을 때 분류 문제에서 소프트맥스 벡터는 카테고리 분포의 모수 (p1,...,pk)를 모델링 한다. 정답 레이블 y를 관찰 데이터로 이용하여 확률분포인 소프트맥스 벡터의 로그 가능도를 최적화한다.
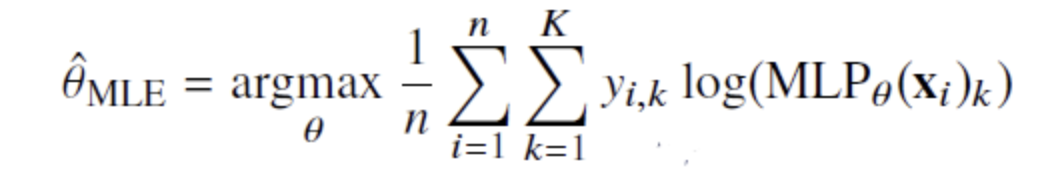
여기서 y(정답분포) MLP(x)(예측한 결과분포)가 있다는 것을 유념해보자. 학습의 목표는 두 분포를 작은쪽으로 해야하기 때문이다.
두 확률분포 사이의 거리를 구할 때
- 총변동거리
- 쿨백 라이블러 발산
- 바슈타인 거리
- 등
을 이용한다. 그 중 쿨백 라이블러 발산에 대해 살펴보자
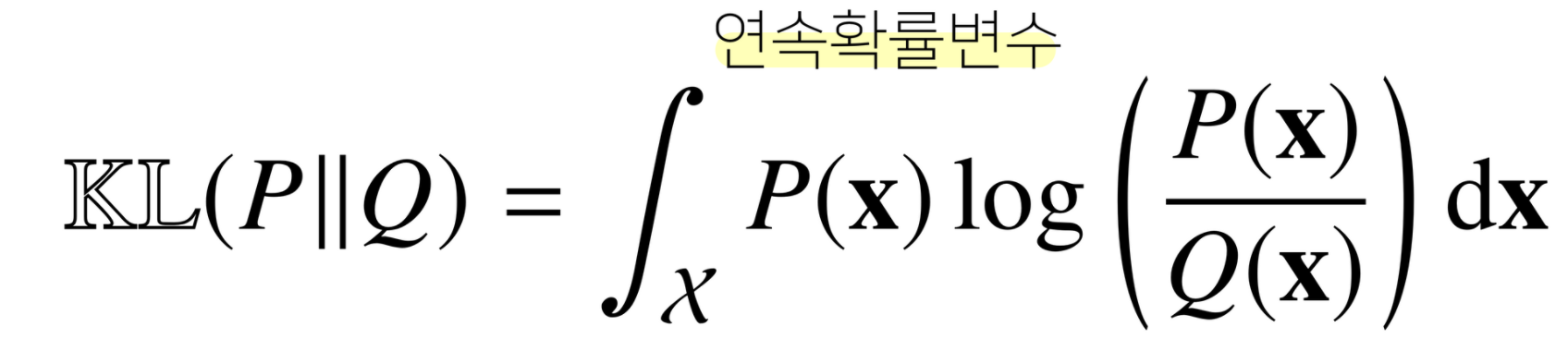
두 분포 p와 q가 있을 때 두 분포의 거리로 이해하면 된다.
이를 분해하면 쿨백 라이블러 함수는 크로스엔트로피 + 엔트로피로 나뉘는 것을 알 수 있다. 즉 정답레이블을 p로하고 모델 예측을 q로 하였을 때 최대 가능도 추정법은 쿨백 라이블러 발산을 최소화하는 것과 같다.
참고: 부스트캠프 AI Tech 4기 AI Math강의 (unist 임성빈 교수님)
