Team Project
1.팀플 깃 전략 (git Organizations)
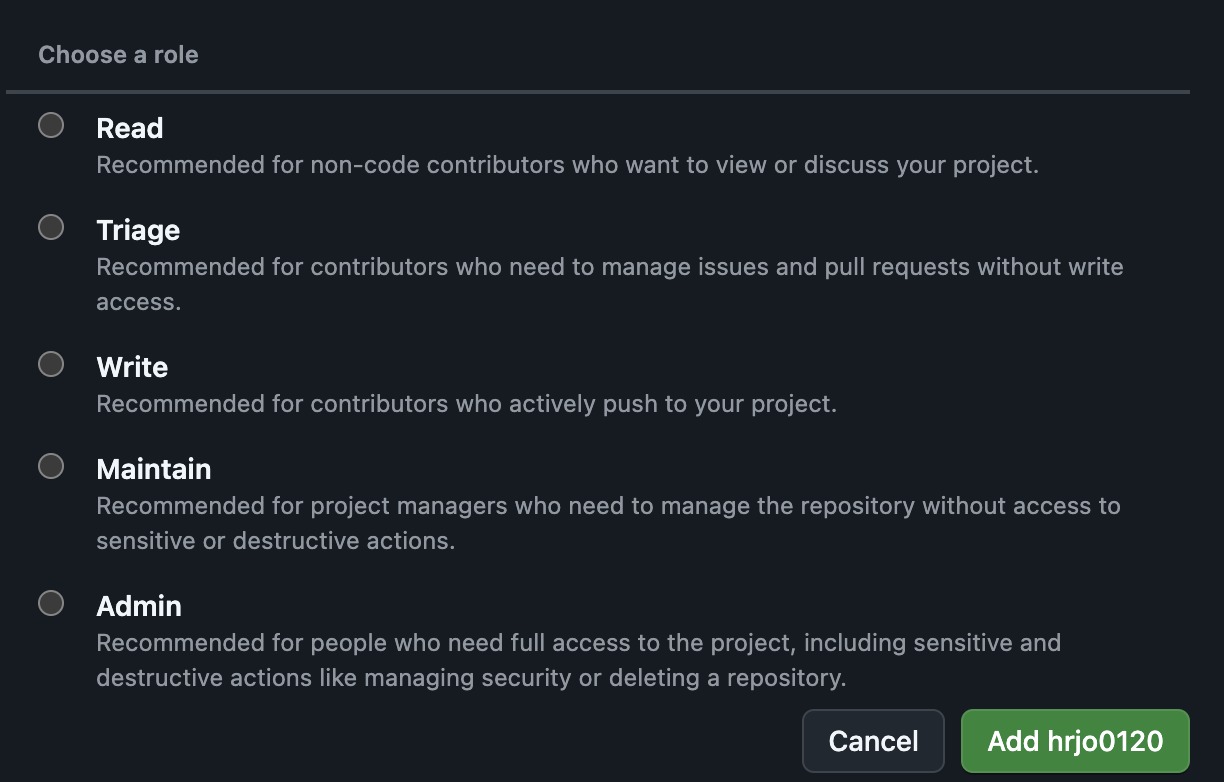
우선 팀의 책임자가 Organizations을 생성한다.팀원을 초대한 이후, new Organizations을 클릭하면 기존 우리가 사용하던 것 처럼 리포지토리를 만드는 창이 뜨는데 여기서 프로젝트 이름이나 ReadMe같은 선택을 할 수 있다. 여기서 public으로
2.팀플 ERD 설계. (추후 변경될 수 있음)
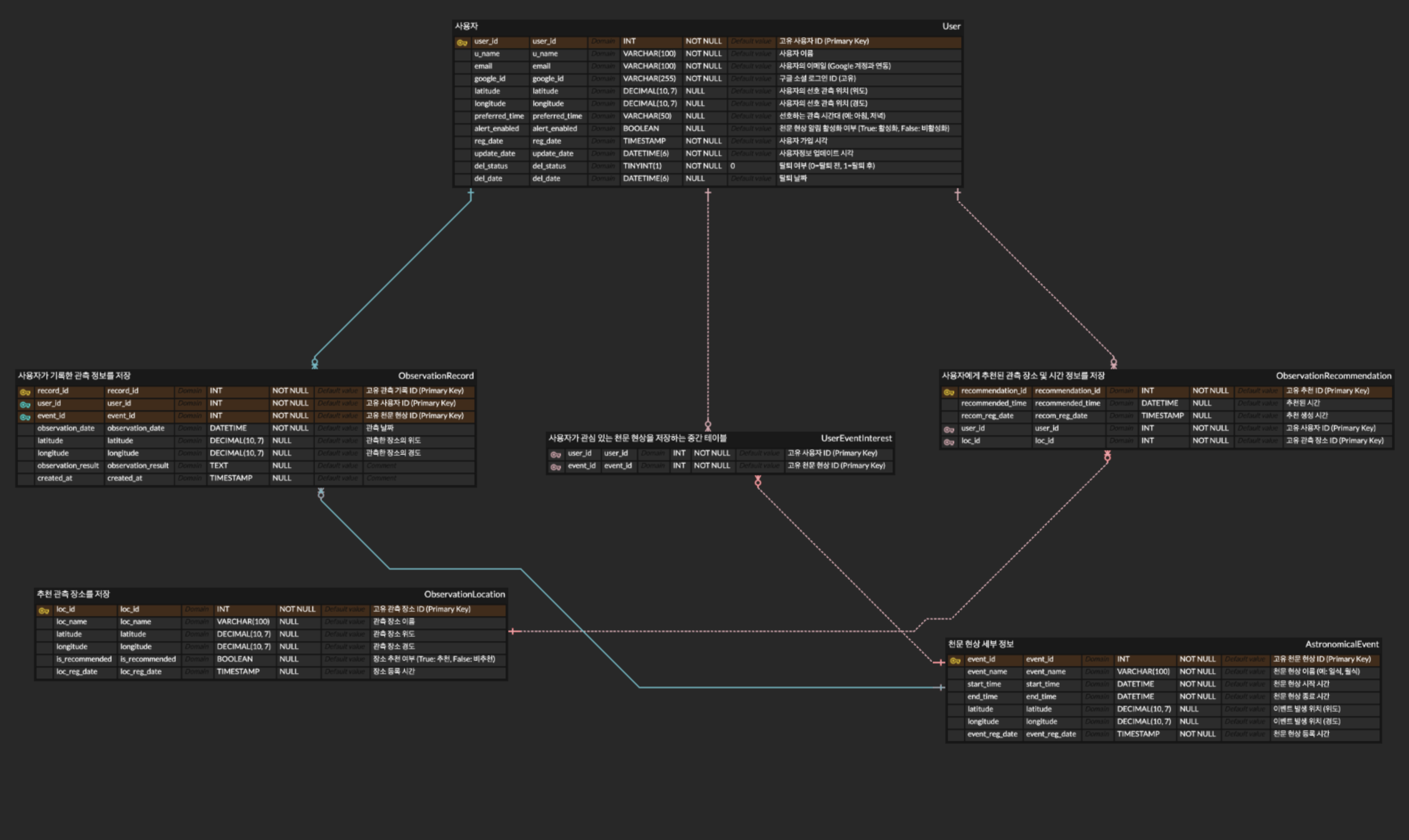
이번 ERD는 천문 현상 관측 서비스를 구축하기 위한 데이터베이스 구조를 설계. 이 시스템은 사용자 데이터를 기반으로 맞춤형 관측 장소와 천문 현상 이벤트를 추천하며, 사용자는 개인 기록을 남길 수 있다.설명: 사용자의 정보를 저장하는 테이블로, Google 소셜 로그
3.팀플 프로젝트에 DB 추가.
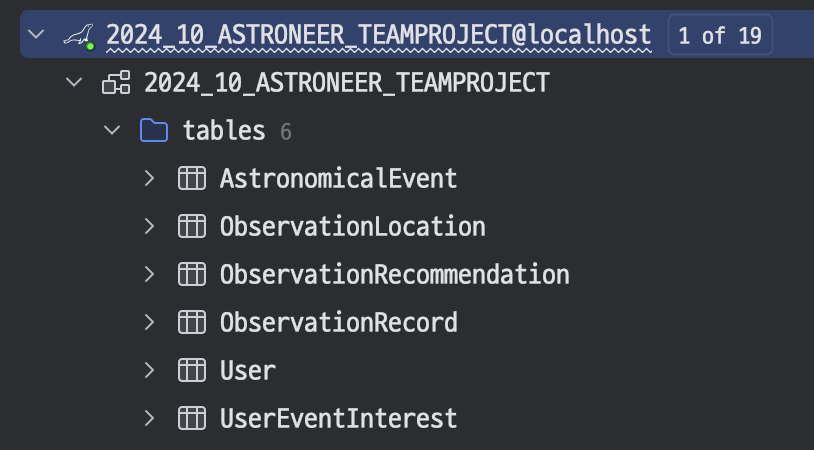
내 개인프로젝트때 처럼 JPA 사용 예정이다.일단 DB를 프로젝트에 연결하자.프로젝트 단계에서 연결 완료했고,DB파일도 생성 했다.깃도 올리고, develop에도 병합해서 팀원들이 확인할 수 있게 해야된다.develop에 푸쉬했다.확인.깃에서도 정상적으로 받아온 것을
4.팀플 소셜(구글)로그인 구현 시작. (Firebase 프로젝트 생성)
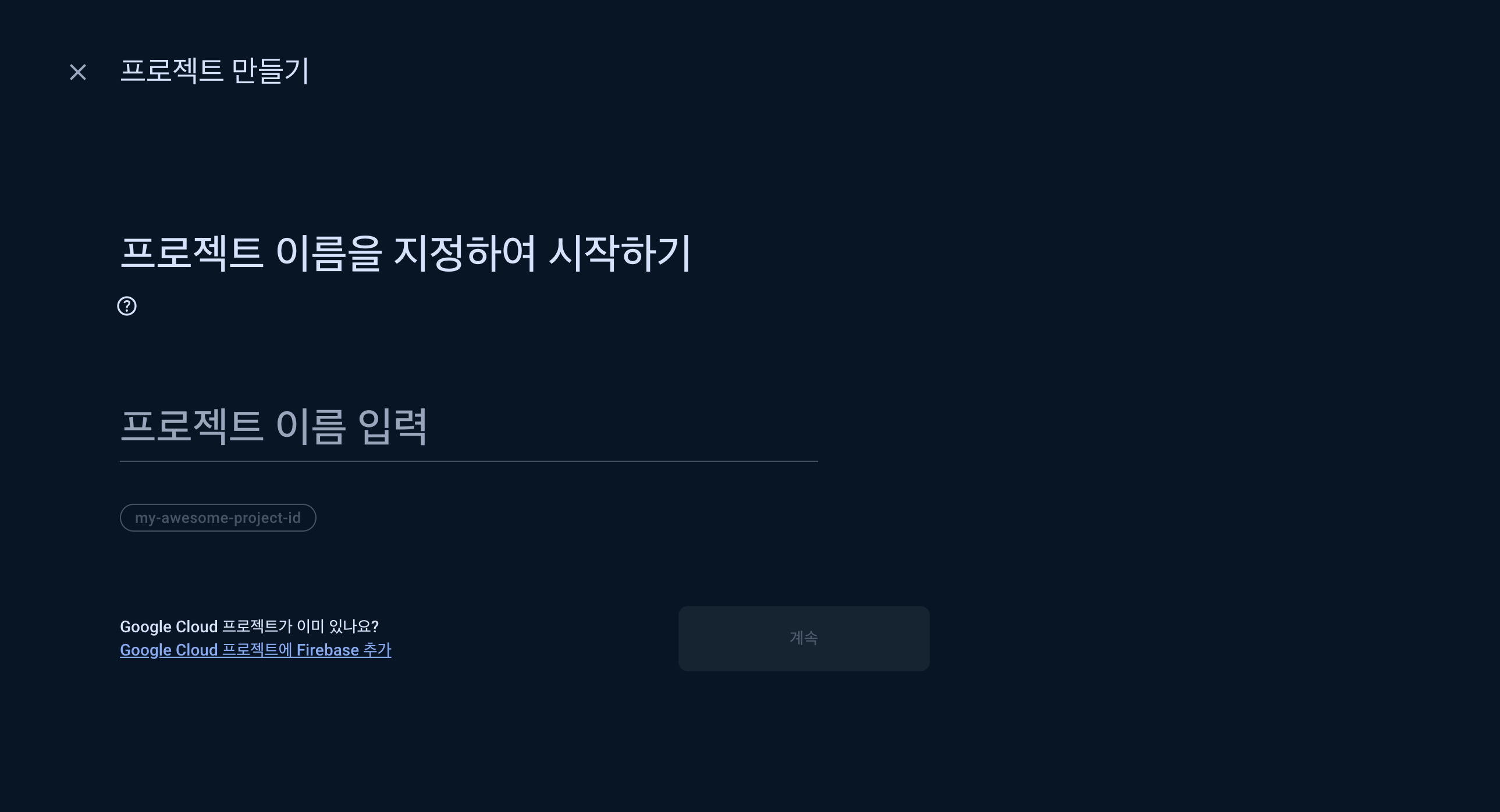
자 이제 구글 로그인 구현을 시작해보자.지금 전반적으로 대강 계획이 잡혀서 시작은 하는데, 팀원들 상태가 메롱이다. 두명은 해외에 있고, 한명은 연락이 안된다..나 혼자 일단 해야한다.서론은 뒤로하고, 나의 개인 프로젝트의 순서 처럼 소셜 로그인 구현부터 시작하려고 한
5.팀플 소셜(구글)로그인 구현중. (완료)
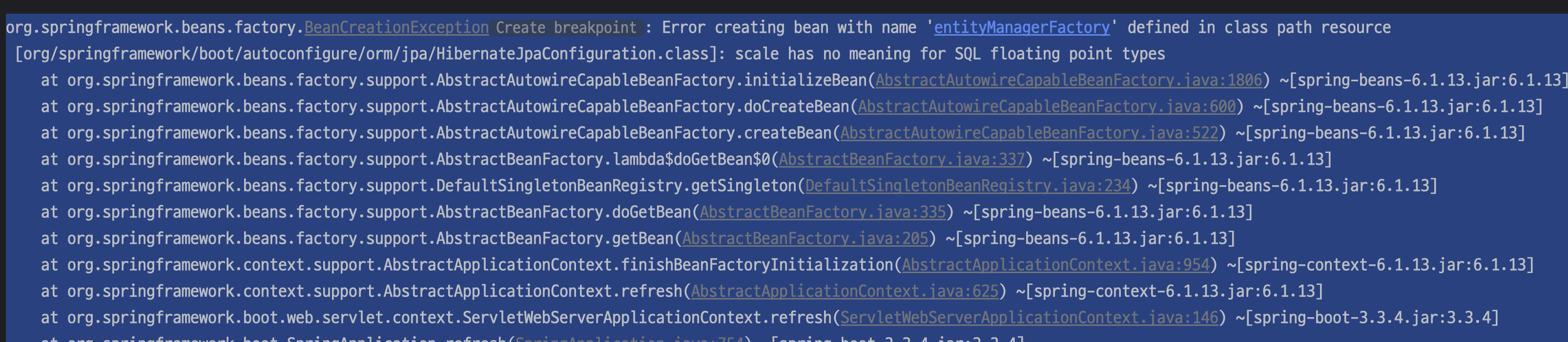
개인 프로젝트에서 구현했던 로그인과 회원가입 로직을 죄다 끌어와서 팀프로젝트에서 사용할 수 있게 하나하나 다 수정을 했다. 기존 스포티파이 로직 삭제나, 비번 관련 로직 삭제, 그리고 엔티티가 db와 매칭되게 수정 정도가 할 일이였고 그렇게 크게 오래 걸리지는 않았다.
6.팀플) 관측 장소(ObservationLocation), 천문 이벤트(AstronomicalEvent) API 구현
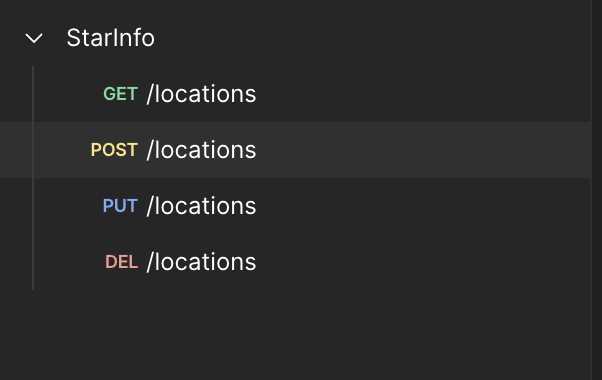
엔드포인트 구조:GET /locations: 모든 관측 장소 리스트 가져오기POST /locations: 새로운 관측 장소 추가하기PUT /locations/{id}: 특정 관측 장소 업데이트DELETE /locations/{id}: 특정 관측 장소 삭제하기해야 할 작
7.팀플) Gradle 이슈

난 정상 작동해서 의존성 주입이 잘 되는데 팀원은 Gradle의존성 주입이 제대로 되지 않는 이슈가 발생함.윈도우 환경에서의 JAVA가 1.8 버전을 가르키고 있었음.그래서 프로젝트 환경에 맞는 Corrento 17을 가르키게 바꿈.이게 1차적 해결 방법이였는데 팀원
8.팀플) DB 연결 이슈
DB의 환경은 제각각 다를 수 있다. 우선 나의 경우엔 맥북환경이라서 DB에 무조건 비밀번호를 입력을 해야되는 상황이고 팀원은 윈도우 환경이고, 또 약간의 차이가 있을 수 있다는 것을 간과했다.때문에 이 문제를 해결하기 위해서 properties파일을 분리, 임포트 하
9.팀플) 타임리프 폐기, React로 전환.
이걸 진행중에 깨달은게 있는데 우리 웹사이트가 제대로 동적처리가 되려면 리액트를 쓰는게 더욱 유리하다는 것을 알게되어서 구조를 전면 수정할 필요가 생겼다.그래서 이 포스트는 프로젝트 구조 수정이 될 것.우선은 여기에 세개의 js파일을 생성한 리액트로 옮겨줘야함.아! R
10.팀플) AstronomyAPI 연결 시작 (폐기)
이제는 Astronomy API를 연결해보자.여기서 앱 생성해주면 API Key를 주겠지. 나도 처음해봐서 잘 모른다.이렇게 생성.음 주는군 이제 이걸 사용하면 된다.만들었으니 .env에 KEY값을 환경변수로 저장해주고AstronomyApiService 클래스 생성.환
11.팀플) Python 설치 및 Skyfield 설치 적용. REST API 설계 시작.
우선 AstromyAPI 폐기를 결정했고 차선책으로 Python 라이브러리 Skyfield를 사용하자고 결정했다.Skyfield를 사용해서 데이터를 직접 계산, 가공해서 천문 데이터를 만들고, 이를 배포할 생각이다.Python 설치Skyfield 라이브러리 설치Skyf
12.팀플) REST API 설계 시작.
git을 보니까 \_\_main\_\_, \_\_init\_\_이나 다양한 폴더들이 보였다.그래서 이런 구조를 따라가는 것 부터 시작.내 프로젝트는 현재덩그러니.. 하다.해당 명령어로 다 처리할 수 있었네. 손으로 다 했다.여튼 이렇게 만들었다.정상 구동까지 확인 완료
13.팀플) REST API 별자리 정보데이터 생성.
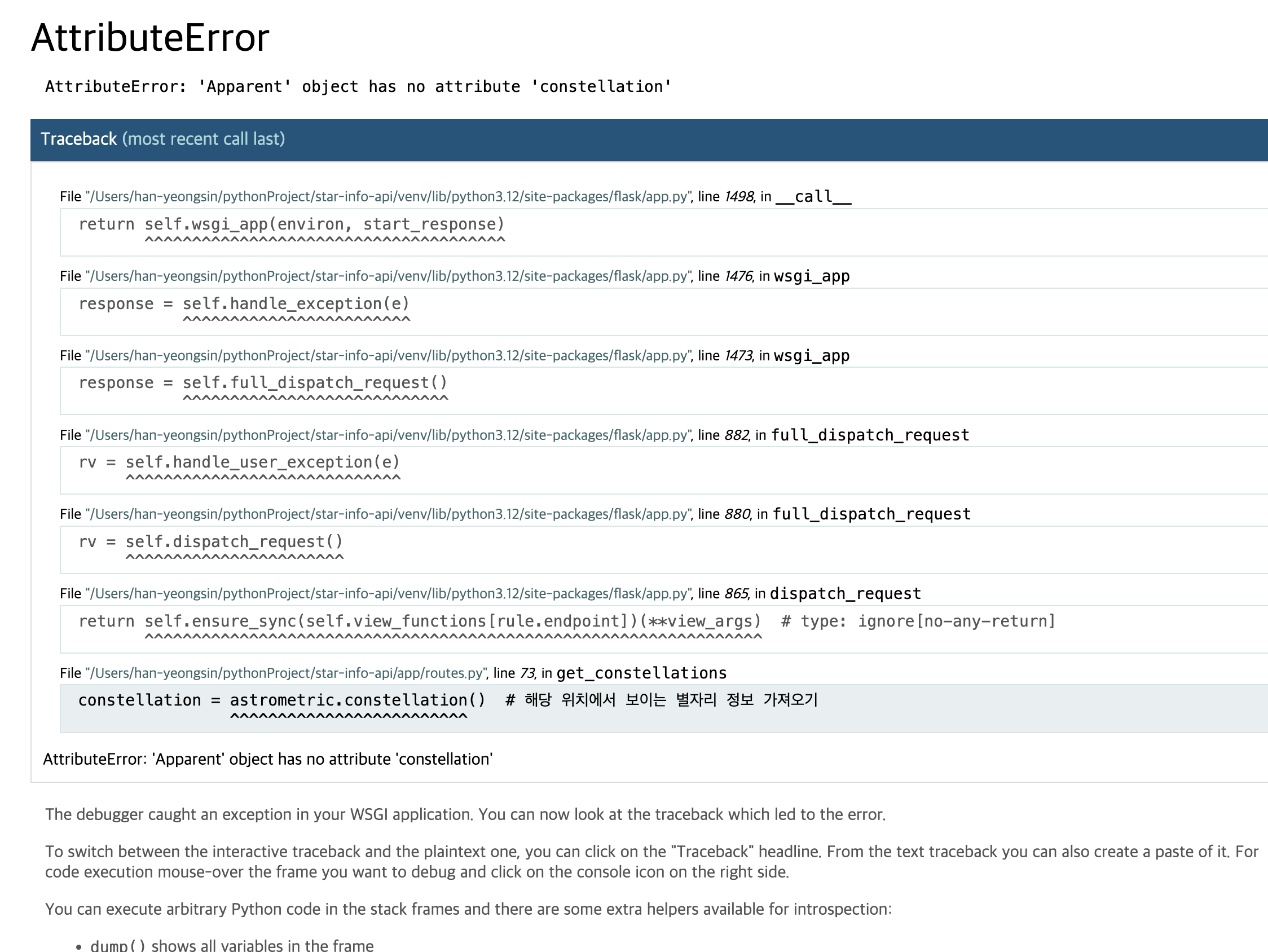
흠.. 쉽지 않네?계속 고치다보니까 에러가 바뀜.일단 에러가 좀 계속해서 많았는데 그래서 skyfield에 대한 정보 수집부터 했다.skyfield 1.49 버전을 사용중이였는데, 그야 install을 그냥 진행해서 제일 최신 버전을 다운 받았으니까.제일 정보가 많고
14.팀플) REST API 일몰 일출 정보 데이터
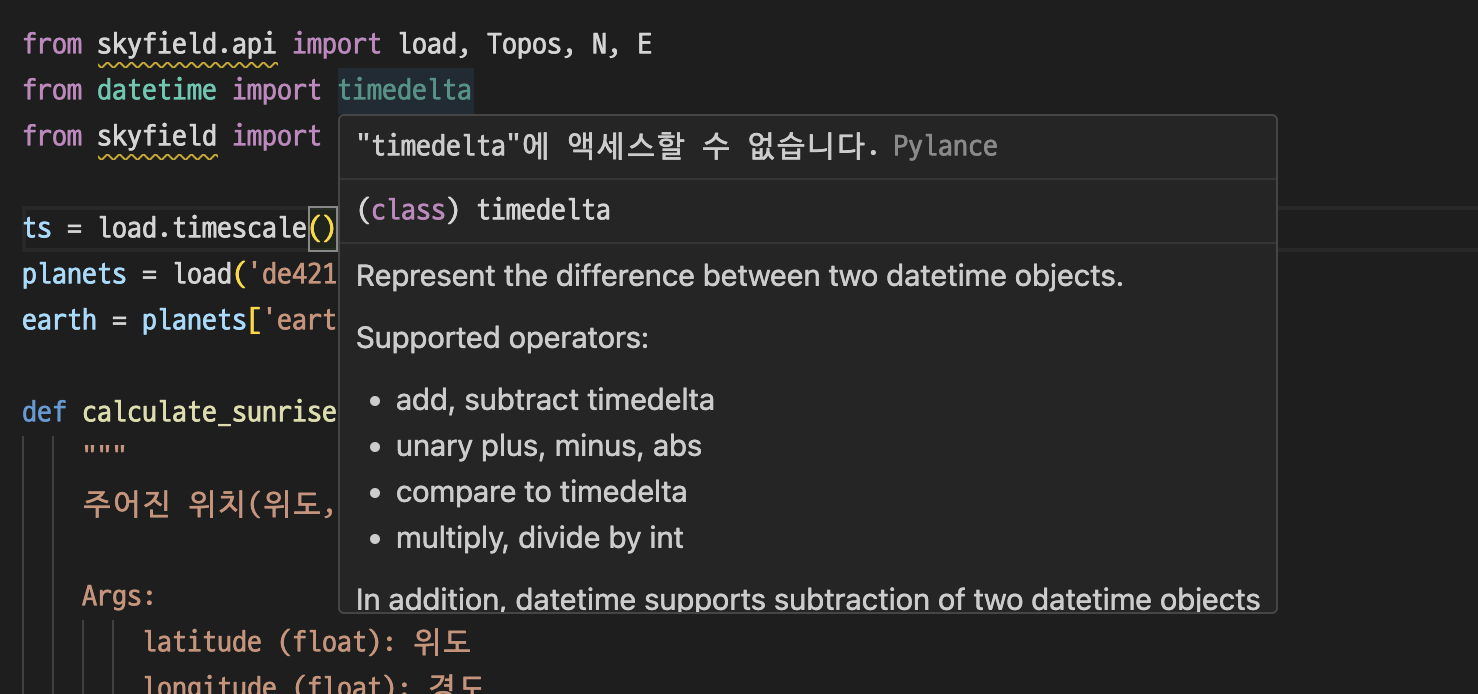
일단 구현중 큰 문제에 직면함..datetime이라는 파이썬에서 기본으로 제공하는 라이브러리가 있는데, timedelta를 엑세스 할 수 없는 문제에 직면했다.venv(가상환경)을 지웠다가 다시 생성하고 라이브러리를 받아도 해결이 되지 않았다.구글링 해보니까 datet
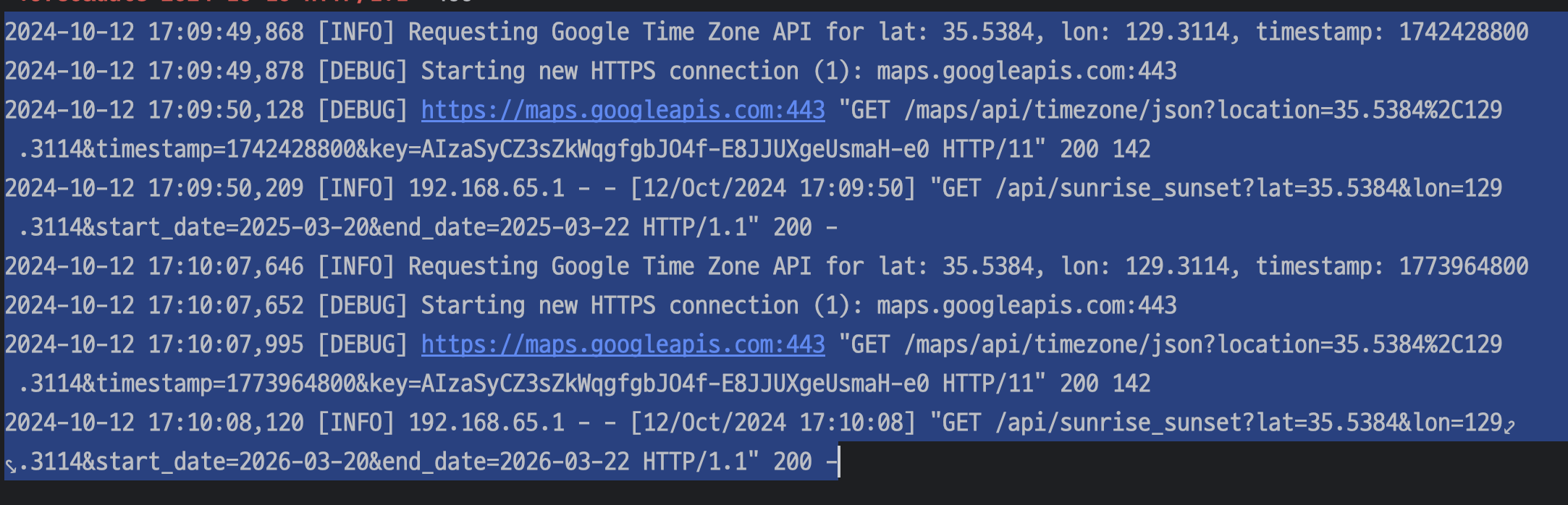
15.팀플) REST API 일몰 일출 정보 데이터 시간의 정확성 올리기. (Google Time Zone API)
시간의 정확성 올리기 를 하기위해서 google time zone api를 python프로젝트에 도입할 생각이다.구글로그인을 이미 Spring에서 구현을 해서 구글 클라우드 콘솔에 API KEY는 있다. 여기서 끌어오면 될듯!그래서 이걸 검색해서 추가해주자.추가하면 거
16.팀플) REST API 일몰 일출 정보 데이터 한국시간 반환 검증

검증을 위해서 23년도의 랜덤한 날짜로 데이터를 요청해서 구글링한 결과와 같은지 대조한다. 한국의 값만 오차가 크지 않으면 된다.위치는 광역시가 기준이다.부산 (부산광역시): 대구 (대구광역시): 인천 (인천광역시): 광주 (광주광역시): 대전 (대전광역시):울
17.팀플) REST API 행성 데이터
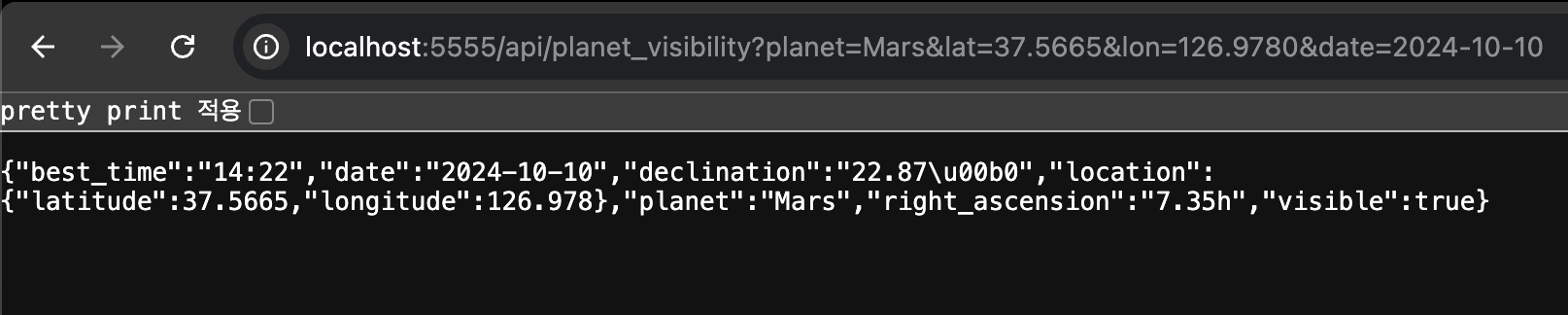
일단은 행성 데이터를 대충 뽑아오는 로직을 썼고, 반환받아보자고.결과다.그래서 코드를 고쳤고.원하는 결과값을 받아냈다.그런데 여기서 고민해볼 것이 있다.일단 생각을 해봤는데 만약 best_time이 낮시간대면? best하지 않은 것 아닌가? 그럼 다시 현지 시각으로 변
18.팀플) REST API 별자리 데이터 구체화중 (api 호출 효율적으로 설계)
이건 전의 포스트를 봤다면 대충은 구현해 놓았다는 것을 알 것이다.우선 UTC 시간을 현지시각으로 변환하는 것이 필요했었으니 별자리를 만들 땐 몰랐던 사실이 있다.유저가 시간 정보를 입력해 요청하면 그 시간 또한 UTC로 변환해야한다는 사실이..그렇다면 api요청이 호
19.팀플) REST API 별자리 데이터 구체화 일단 완료.

별자리 정보 요청시 더이상 시간정보 입력 하지 않음.이제는 sunset정보 활용해서 시간 넘김get_best_visibility_time_for_constellation 메서드 활용해서 best_time 추출 로직 구현고도의 처리가 힘들어서 일단은 한국 평균 고도를 고
20.팀플) 유성우 정보 추출 전략. (MIT에서 제공하는 gmn-python-api 사용!)

데이터에 공신력을 갖기 위해, NASA API 연결을 결정했다.여기서 제일 적절한 것 같은 api는 EONET가 가장 적절해 보인다. 지구에서 관측한다. 자연적인 이벤트를 트랙킹. 이라고 써져 있으니까.그럼 일단 고민하지말고 바로 연결부터 해보자.일단 .env 변수로
21.팀플) 유성우 데이터 정제하기 (유성우 폐기 정밀 예측 현실적으로 불가능, 새로운 우주 이벤트 고민, 행성의 가시성 공신력 더하기)
우선 전의 포스팅에 어떻게 정제할지는 생각을 해뒀고, 이제 천천히 구현을 해보면 된다.그렇게 거름망을 만들어서 여러번 테스트를 해봤는데 아무런 데이터도 나오지 않는게 이상해서 공식문서를 좀 더 자세하게 읽어보니까 예측보다는 기록에 중점을 둔 api였다. 이거 지워야겠네
22.팀플) 행성의 가시성 검증중 문제발견.
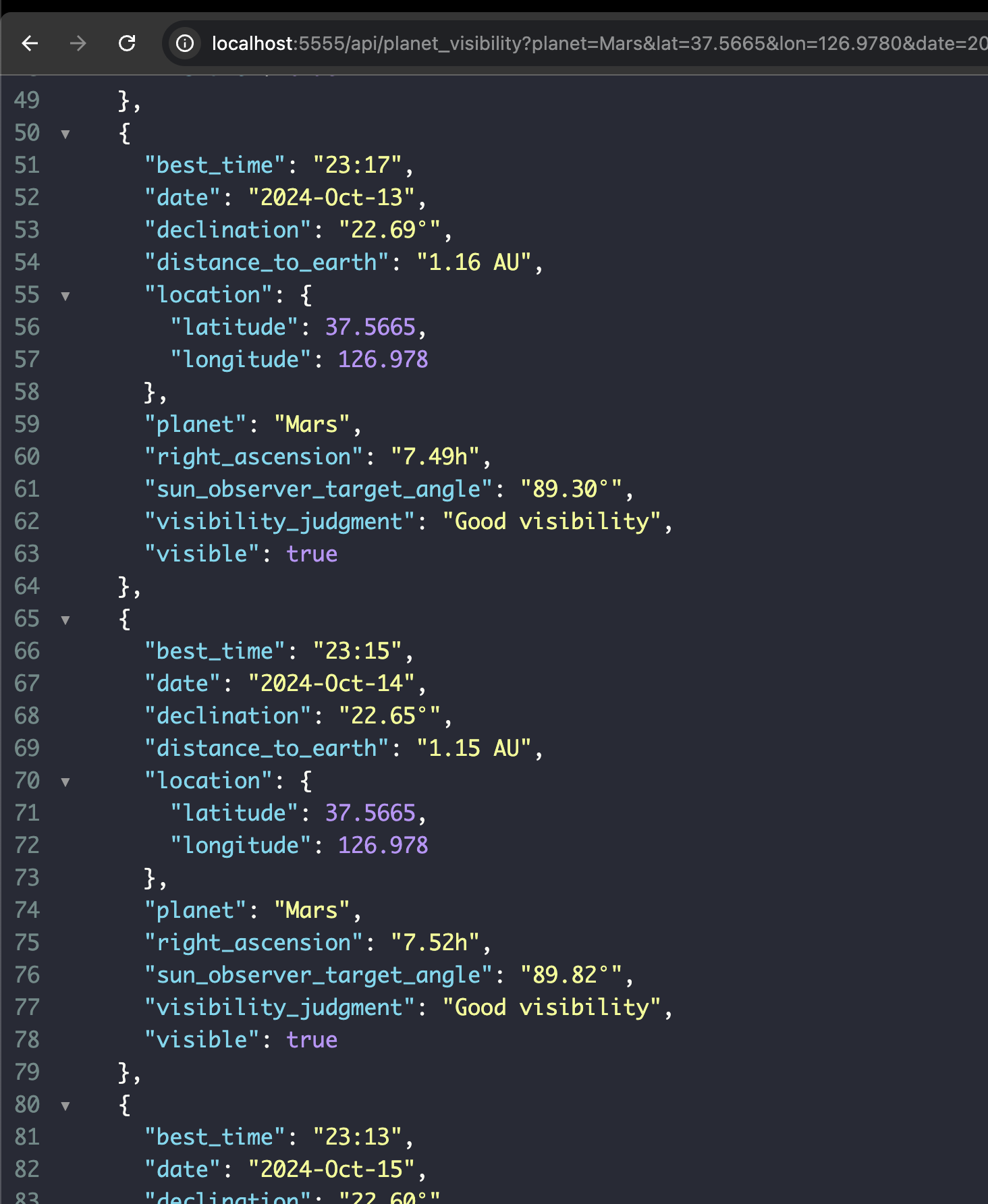
지금 난 행성에 위치를 계산하기 위해서 planets = load('de421.bsp')이렇게 행성 정보들을 로드했었다.문제는 목성부터 결과가 나오지 않아서 보니까 de421.bsp에서 화성까지 밖에 행성 정보를 지원하지 않는다는 사실을 알았다. 타행성은 이제 중력 중
23.팀플) 행성의 가시성 정보 API와 엮어서 상세하게 한 것 검증.
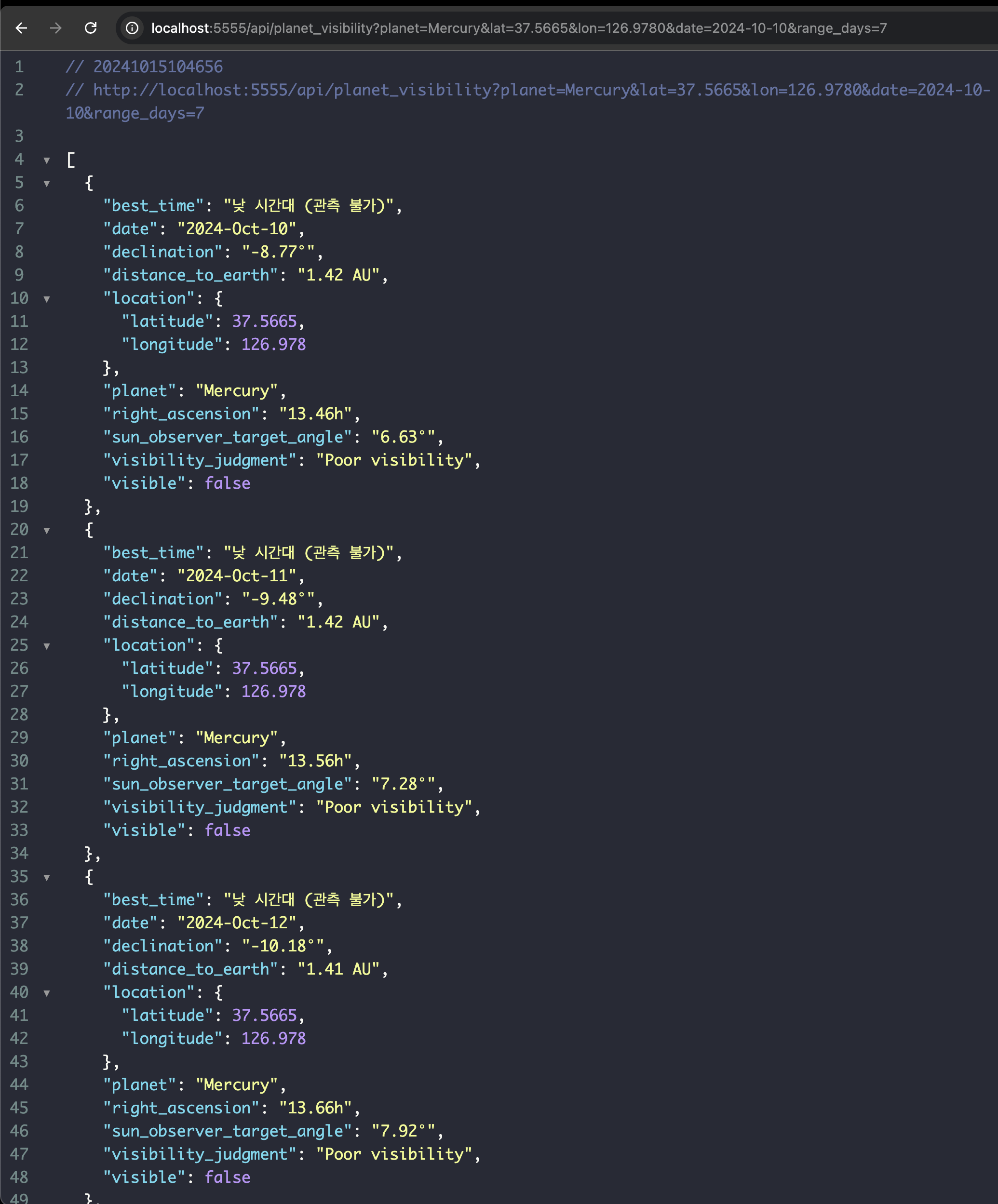
우선 나중에 화면에 보여줄 것을 생각해 요청 일자를 로직에 추가했다.다음은 검증해볼시간.지금 해당 값을 결과 값에 추가했는데 이게 제대로 작동하는가 검증해보는 것.Mercury (수성):Venus (금성):Mars (화성):Jupiter (목성):Saturn (토성):
24.팀플) 행성 대접근 이벤트 만들기. (도커에서의 DB 포트와 서버 이해)
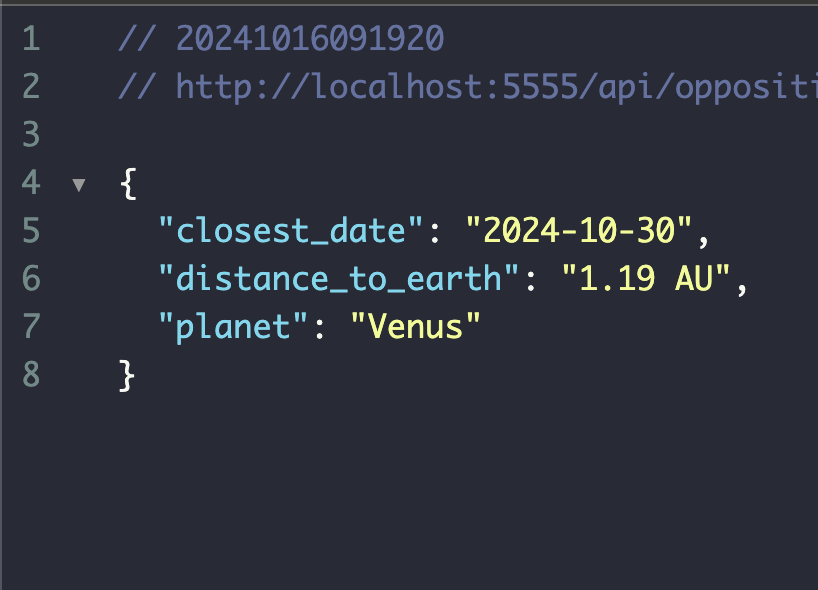
행성의 가시성의 대한 정보는 업데이트 되었다. 이제 행성 대접근을 계산하면 되고, 내 계획은 이렇다.행성 대접근은 따로 만들고, 지구와의 거리가 가장 가까운 시기를 알아낸다.이게 끝이다.그리고 이걸 알아내려면 6개월이나 1년치를 한꺼번에 가져와야되는데 지금 2주치만 요
25.팀플) 로우데이터 저장 전략.

일단 DB연결 문제를 겪으면서 계속 들었던 생각이 테이블을 행성별로 나눠야할 것 같다는 생각이 들었다.1년이 365일이니까 행성 8개를 저장하면 365 \* 8 = 2920 즉, 칼럼이 2920개나 된다.그래서 년도 별로 나누고 행성별로 나눠서 관리하는 편이 용이할 것
26.팀플) 행성 대접근 로직 수정. (LIST 반환.. xxx 데이터 간략화 하기, 행성별로 나누자는 생각 도달.)
지금은 년도중 제일 가까운 날 하루만 반환하는데 이러면 프론트에서 써먹을 소스가 좀 부족할 것 같아서 로직 수정하기로 결정했다.우선은이런 느낌으로 로직을 짰는데, 반환은 잘 된다.근데 문제가 가시성 정보에서 1년을 죄다 조회하고 비교 대조를 해서 좀 오래걸린다.그럼 어
27.팀플) 대행성 로직 간단화와 행성별로 나누기

행성별로 대접근 이벤트의 주기가 존재한다. 내가 보여주려던 데이터는 틀린 데이터다. 빨리 알아채서 다행..수성 (Mercury): 약 116일수성은 지구와 매우 빠른 공전 주기를 가지고 있어 자주 대접근합니다.금성 (Venus): 약 584일금성은 약 1년 반마다 지구
28.팀플) 행성의 가시성 -> DB 생성 로직 삭제, DB 조회만. (가시성 판단 로직 정교화)

이제 로우데이터는 자동생성하게끔 로직을 만들었으니까. 기존의 행성의 가시성에 접근했을 때 DB 테이블 생성과 데이터를 삽입하는 로직은 지우고 데이터 조회만 하면 된다. 기존의 DB 테이블 생성, 삽입 로직은 지웠고, 데이터 조회만 남겼다. 확인만 해보면 됨. 금
29.팀플) 별자리 데이터 수정.
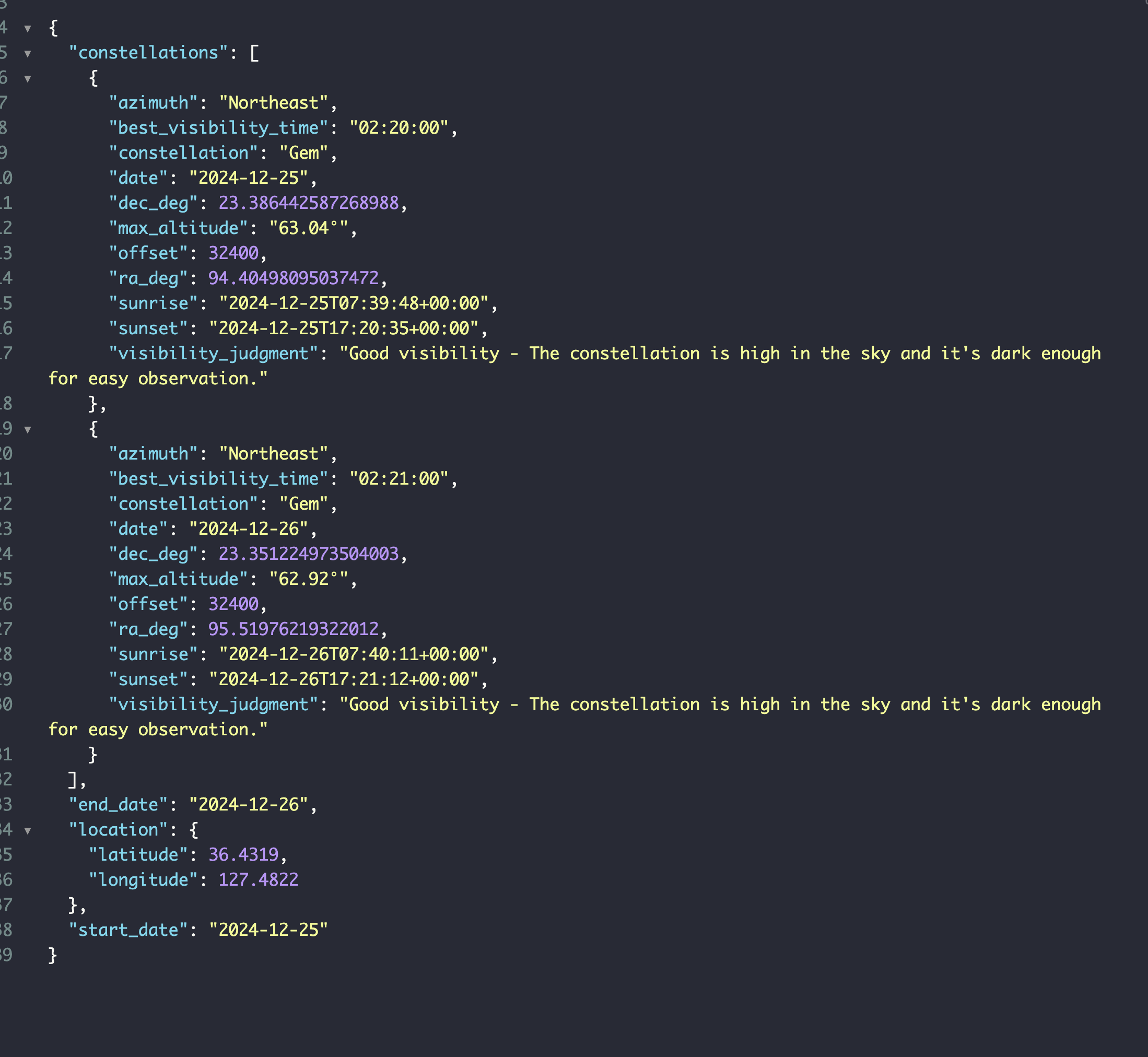
행성 데이터를 좀 잘 만들었으니까 별자리 데이터도 좀 더 수정하고 싶었다.결과부터 보면 이렇게 표기되게끔 바꿨다.대충 뭘 했냐면 관측자가 바라보는 곳을 애매하게 지정해서 계산중이였는데 constellation_service에서 가져온 별자리 이름과 적경과 적위를 사용해
30.팀플) 혜성 이벤트 시작! (데이터 접근, 파싱, 추출)
이젠 혜성 이벤트로직을 만들면 된다. 해당 정보도 이제 호라이즌 API 에서 반환 받고, 계산을 하면 된다.우선은 행성에 대한 로직을 짤 때 사용했던 파일에서 혜성에 대한 정보를 가져오기로 헀다.어떤 데이터가 넘어올지는 모르지만 일단은 그래도 가져와서 (어차피 url이
31.팀플) 혜성 예측 로직 구상.
뭐 코드를 작성하고 그런게 아니고 계획을 좀 제대로 짜고 데이터의 흐름이나 계산 로직의 계획? 같은거다.데이터 요청 및 계산: 혜성의 예측 데이터를 계산하기 위해 필요한 모든 데이터를 특정 기간 동안 요청하고, 필요한 모든 요소(혜성의 궤도 요소, 접근 거리, S-O-
32.팀플) 혜성 로직 짜기.
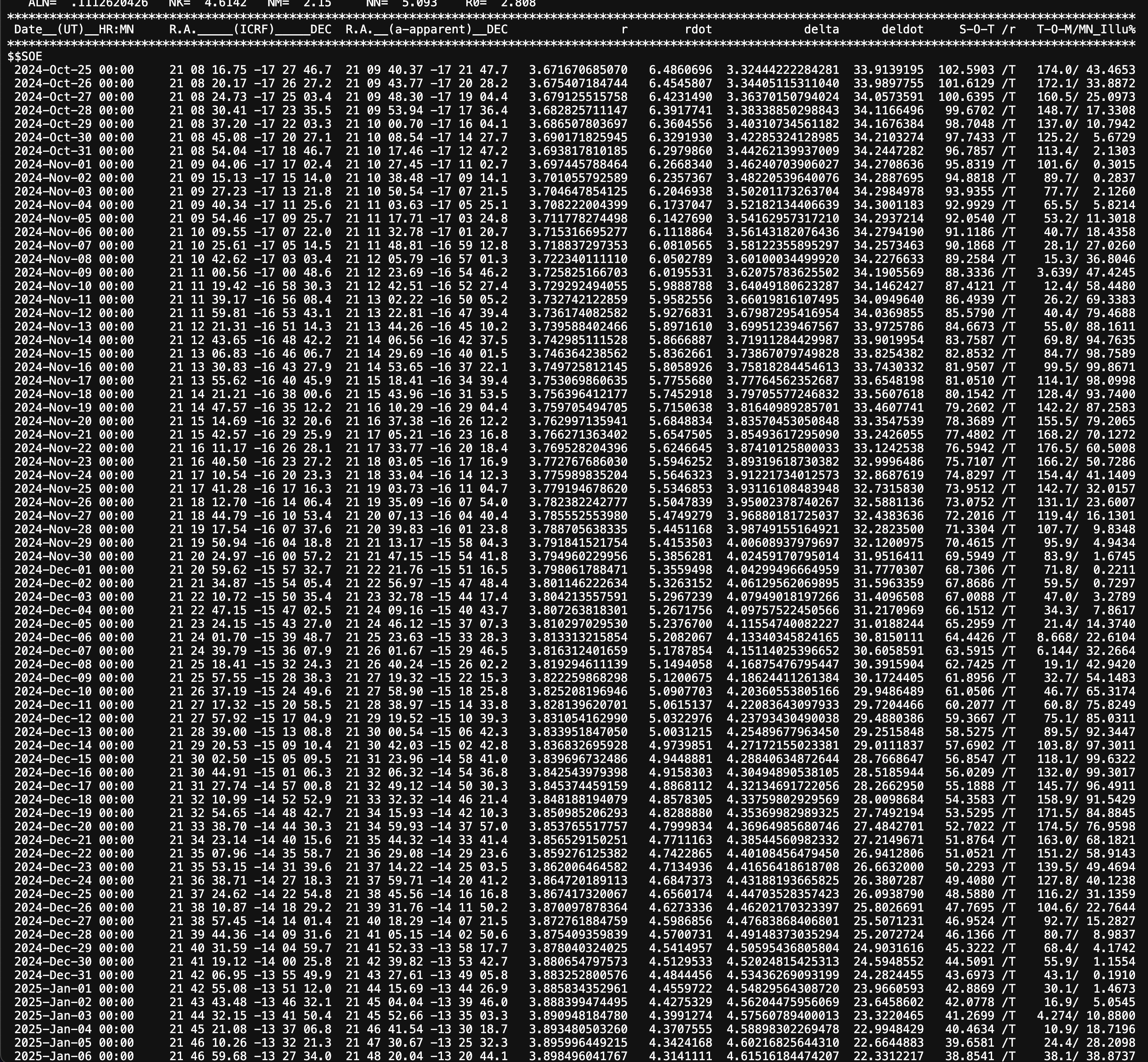
Encke의 혜성 주기가 3.3년으로 제일 짧다.이걸로 계산을 해서 실제 다른 데이터와 검증해가면서 정확도를 올리고 다른 혜성들도 테스트 해보면 될듯.우선은 API 측에서 3년치의 요청을 못받아드릴 수도 있으니까 요청을 해보고 시작하자.음 아무 문제 없군.가져온 데이터
33.팀플) 혜성 데이터의 사용 고민.
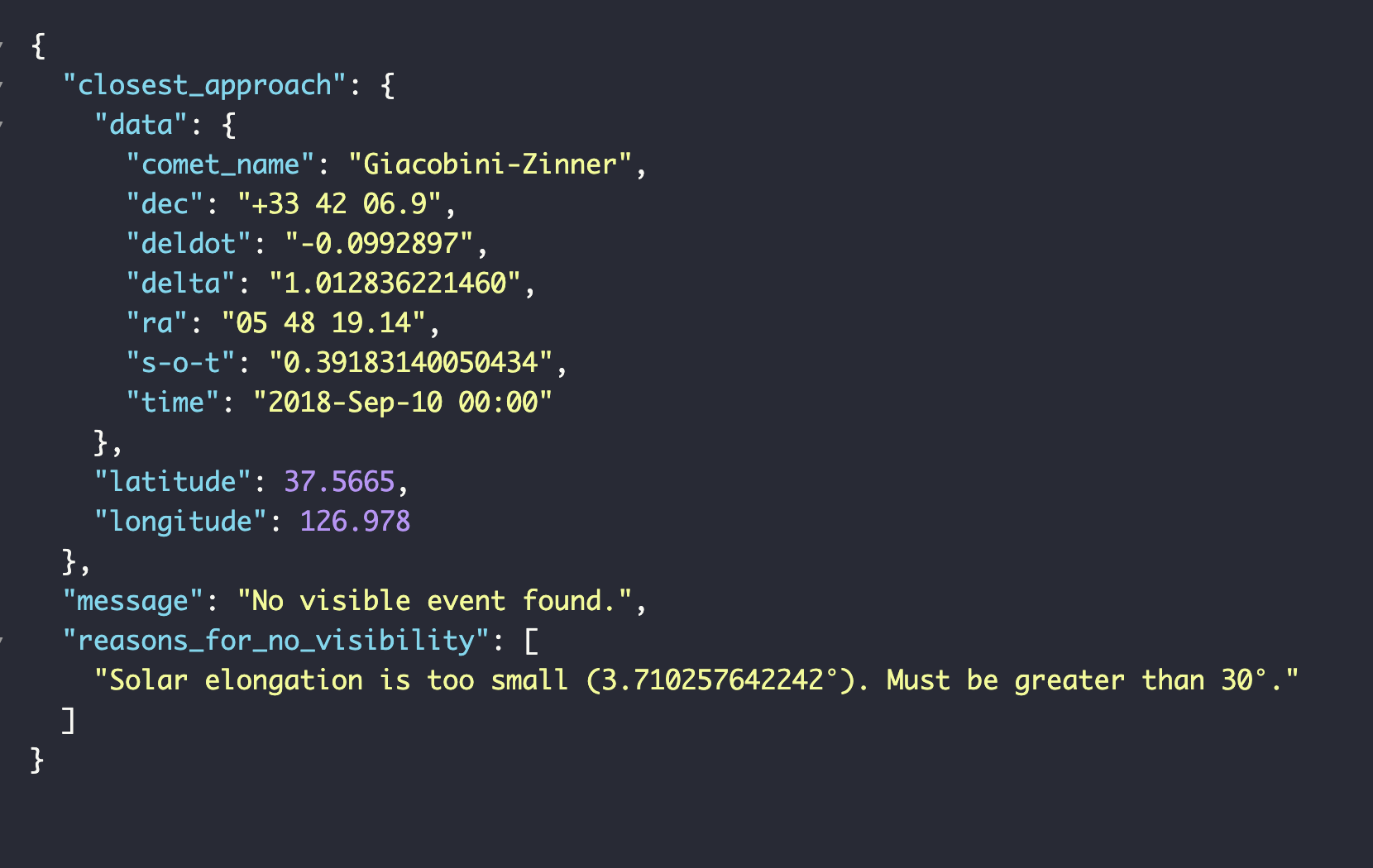
지금 뽑아놓은 데이터는 나름 의미가 있다. 21P/Giacobini-Zinner (드라코니드 유성우) - 매년 10월 초.109P/Swift-Tuttle (페르세우스 유성우) - 매년 8월 중순.1P/Halley (오리온자리 유성우) - 매년 10월 중순.1P/Hall
34.팀플) 혜성데이터를 활용해 유성우를 정밀하게 계산하기 위한 전략. (긴 주기의 혜성의 멀어짐과 가까워짐을 판단.)
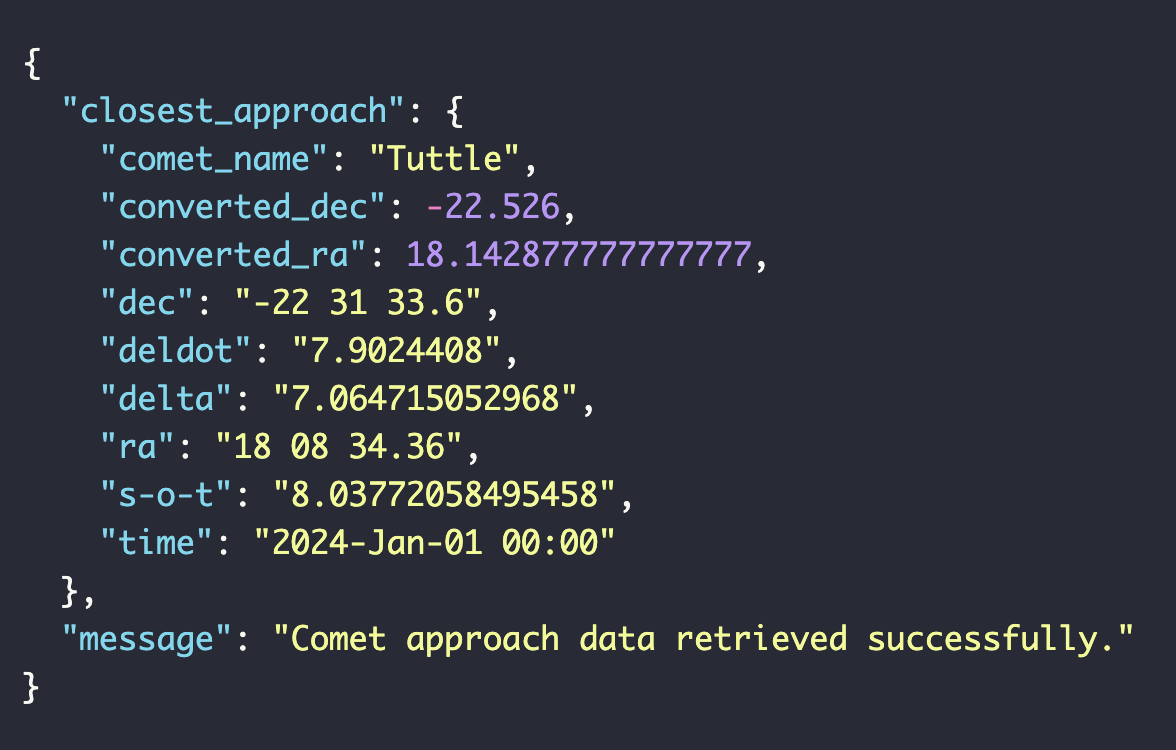
혜성 접근 데이터 저장:각 혜성의 접근 데이터를 1년 단위로 요청하고, 이를 최대 50년~100년로 DB에 저장할 계획.이렇게 하면 각 혜성별로 50~100개의 접근 데이터가 저장되게 된다. 지금 다루고 있는 혜성이 총 8개이기 때문에 총 400~800개의 접근 데이터
35.팀플) 기존 행성 데이터 DB 저장, 조회기능 SQLAlchemy로 적용해보기.

이게 생각보다 요청이 오래 걸려서 DB에 저장하고 꺼내와서 위치데이터 기반으로 가시성에 대한 계산 로직을 짜야할 것 같았다.그래서 유성우 요청시에 혜성의 데이터까지 표시하도록 한 이유가 바로 DB에 저장하기 위해서 일부러 그렇게 한 것이다.암튼! 이번에는 수동으로 DB
36.팀플) 유성우데이터 DB 저장, 조회기능 SQLAlchemy
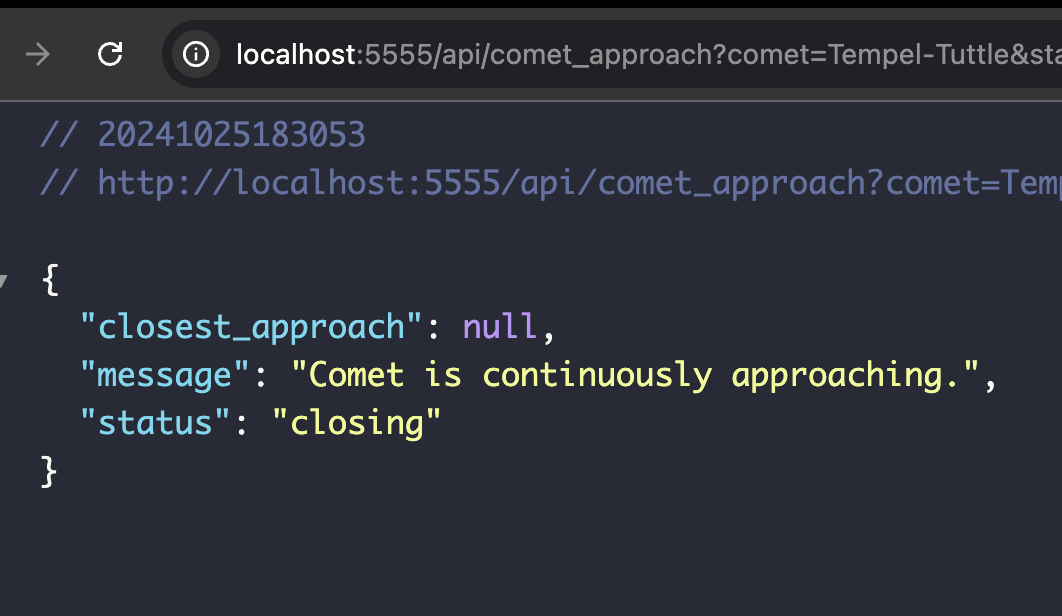
이제는 유성우 데이터 DB 저장과 조회가 될 수 있게 만들면 된다.지금까지 만들어둔 로직은 이제 로우데이터를 생성만 하는 것이고. 메서드를 분리해서 자동으로 로우데이터를 저장하게끔 설계할 생각이다.우선 성공 시켰고 그렇게 큰 문제는 있지 않았다. 문제가 있다면 난 3년
37.팀플) 유성우 가시성 판단 로직 -> 달의 위상구하기까지

을 하기 전에 방위는 계속 해서 쓸 것 같아서 util로 빼서 새로 만들어서 갖다 쓸 수 있게 했다.뭐 이렇게 갖다 쓸 수 있게.. 아니면 8방위에 대한 코드가 별자리에도 행성에도 유성우에도 있을테니까 로직을 짜는 와중에 빼는게 좋겠다고 판단해서 빼줬다.당연히 기능이
38.팀플) 별자리 데이터 검증.

검증하겠다고 전부터 말을 해놨는데 계속 못갔던게 대전이 그 때 부터 쭉 흐렸다. 이번주 수목이 맑길래..새벽 1시 35분에 나왔다. 이제 성차산을 찍어두고,,갔다왔다.사진이 흔들리긴 했는데 2시 20분 언저리에 도착했고,차안에 노트북으로 2시 35분인 것 확인.남서쪽에
39.팀플) API 서버 배포 (Oracle Cloud 무료 서버 사용)
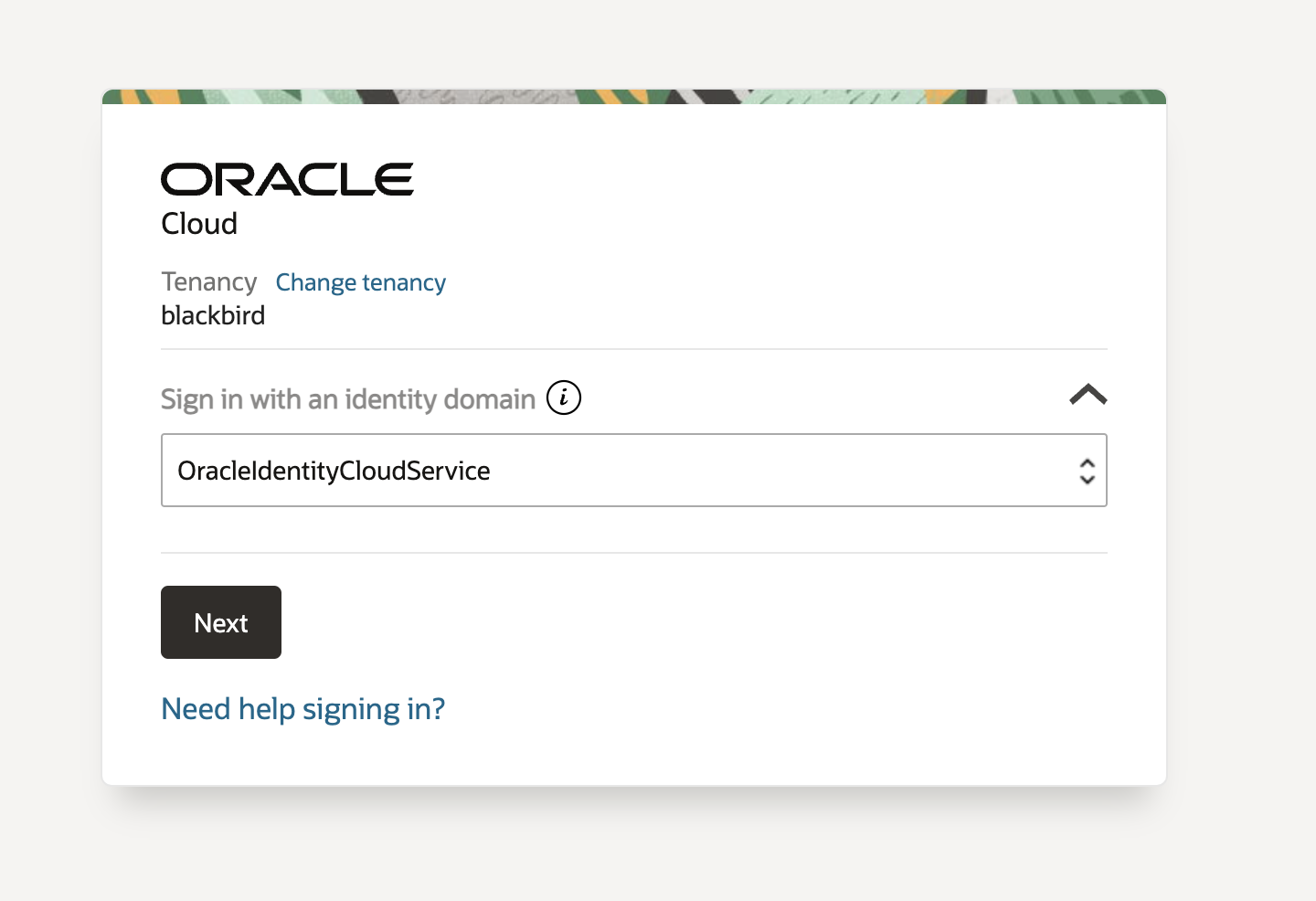
컴퓨터로 서버를 지정할까 했는데 아무래도 괜히 또 문제 생길까 무서워서 그냥 Oracle Cloud로 무료로 할 수 있다고 해서 해보려고 한다.계정도 다 만들었고, 신용카드 등록가지 하고 로그인하니까 이런 창이 떴다. 서버는 일본의 오사카에 있는 서버를 골랐다.이런게
40.팀플) Star Info API 요청 방식 설명.
요청 방식: GET필요한 파라미터:lat (필수, float): 위도lon (필수, float): 경도start_date (선택, str, YYYY-MM-DD): 시작 날짜end_date (선택, str, YYYY-MM-DD): 종료 날짜설명: 사용자가 요청한 위도,
41.팀플) Merge 기록

이제 나도 본격적으로 프로젝트에 다시 투입되었기 때문에 (지금 구글 맵 API 연결중이였다.) 병합을 한번 진행하고 개발하는 것이 좋다고 판단했다.나는 프론트에 손을 대지 않을 것이라고 호언장담하였지만, 구글 맵 API 연결 도중 프론트로 접근해야된 다는 것을 깨닫고.
42.팀플) Spring CRUD와 API 데이터 엮기 (Google Maps API)
이제 기존에 만들어둔 Spring에서의 API와 천문 데이터 API 와 엮어주면 된다.그럼 엮기 전에 생각해볼 것이 있는데, 내가 만든 API 대부분이 위도 경도가 거의 필수로 필요하다. 그렇다면? 일단 요청에 위도 경도를 태워 보내야한다. 그래서 사용자가 주로 관측하
43.팀플) Google Maps API 백엔드 통신 및 react-toastify 로 자연스러운 UI/UX 구현

이제 대충 구색은 맞춰놨으니까, 백엔드로 위도 경도를 전송할 수 있게 하면 된다. 근데 그전에 시큐리티 설정부터 만져야될듯? 그리고 또 그전에는 확인 버튼이랑 저장 버튼도 만들었다. 대충 일케 만들어두고 함수는 깡통이다.
44.팀플) API 오류 해결, 서버 재배포
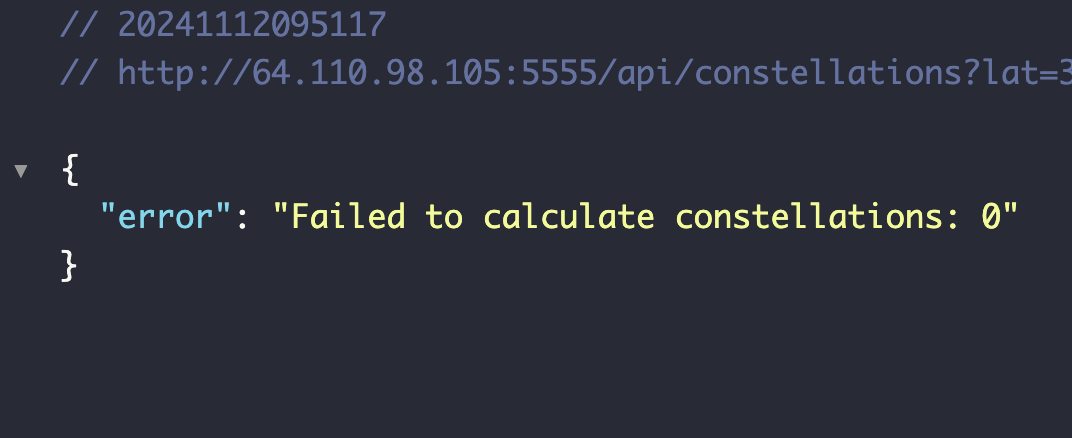
위 이미지와 같이 갑자기 API 요청들이 먹통이 됐는데, 처음엔 왜이러지 싶어서 파이썬 서버를 열어서 다시 확인해봤다.똑같다.곰곰이 생각해보니까 아마 MAP API를 지금 스프링에서도 연결하면서 문제가 된 것 같다는 생각이 들었다.그래서 설정을 추가함.위가 내 원래 서
45.팀플) API 연결 비회원 별자리 데이터 처리, 유저 상세보기 페이지

어제 이제 각 팀원들 브랜치까지 머지 완료했고, 또 뭐 오류가 있었어서 그거 해결한다고 조금 오래 걸렸다. 지금 브랜치는 master, develop, develop2, feature \* 4, 이렇게 7개 있음..여튼 이제 내가 만든 API를 연결해야되는데 이걸 어떻
46.팀플) 회원의 별자리 데이터 요청 로직
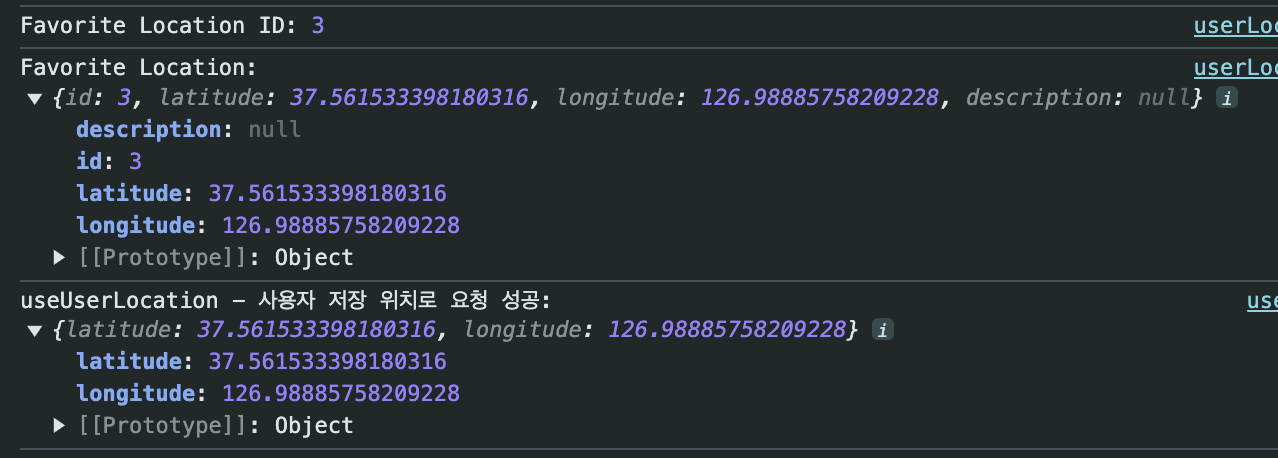
이제 즐겨찾기 기능을 완성했으니까, 별자리 데이터 요청을 회원도 할 수 있게 됨. (자동으로 되는거긴 하지만) 그에 대한 하드코딩을 지우고 이제 제대로 백엔드와 통신후에 요청이 되도록 수정하면 될듯. 삼항연산자로 로그인 하지 않은 유저에 대한 처리했고 유저 상세보기
47.팀플) 달의 위상 로직수정 및 오라클 서버 재배포
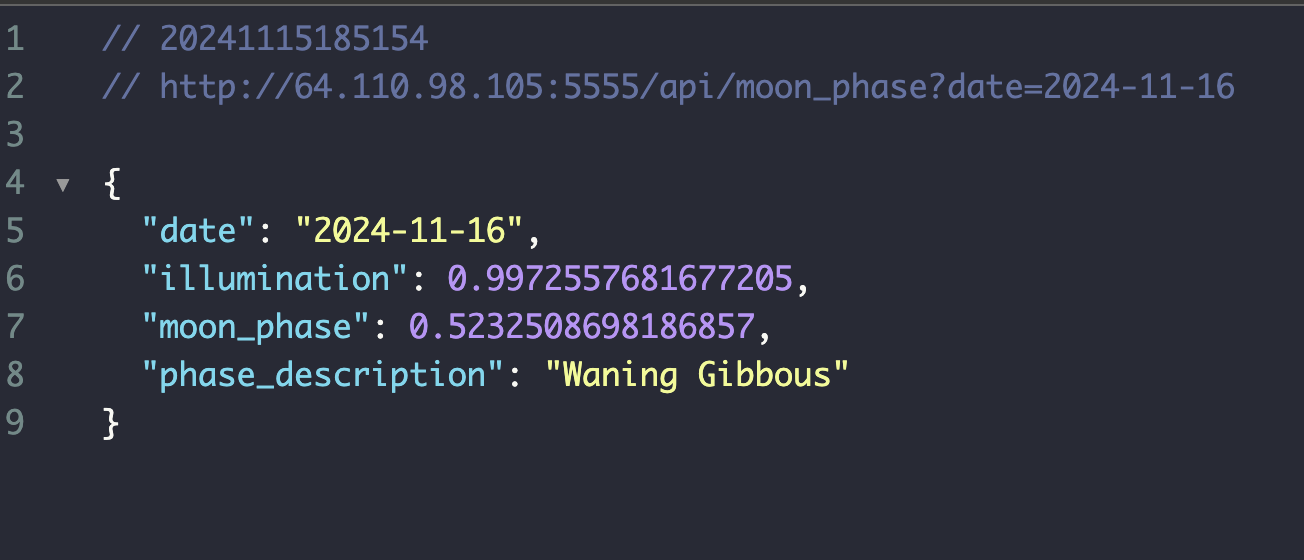
오늘 집 가다가 하늘을 보니까 겁나 땡그란 보름달이였다.이건 못참지 하고 지금 레슨 잠깐 비는 시간동안 API 요청을 오늘 날짜로 해봤는데,고쳐야겠지? 아 ㅋㅋ조명률은 거의 근접한 결과인데 위상이 엉망이다.뭐 고쳐야지 어떡하냐,,그래서 다시 코드를 좀 살펴보니까illu
48.팀플) Api요청시 로딩 처리
지금은 하루치만 요청해서 데이터가 빨리 나오지만 나중에 한달치를 만약에 요청한다고 할시에는 api에 직접 요청해도 시간이 꽤나 걸림.그럼 뭐다? 로딩 페이지가 따로 필요할 것 같다~컴포넌트 디렉토리에 간단하게 생성해놨다.코드를 이제 집어넣고 빌드중에 React Hook
49.팀플) 별자리 데이터 캐싱 구현 (Redis)
지금 어느정도 설계는 다 완료 되었는데 캐싱 시스템이 있으면 좋을 것 같음.과도한 요청이 사용자 경험에 영향을 끼치니까 만약 사용자가 자주 요청하는 것들은 기억해두고 처리하면 아주 좋을 것 같으니까 구현해두면 경험적으로도 비용적으로도 유리하다는 생각.그래서 이걸 Red
50.팀플) 행성데이터 연결 및 로그인 로그아웃 UI 처리
이거 컨트롤러랑 서비스 준비는 해둠 사실.근데 캐싱은 안만져놔서 해놓자고캐싱 설정도 했고, @Retryable은 재시도 로직인데 Spring Retry의존성 주입해서 사용함. 이런게 있길래 넣어둠.여튼 백엔드 준비는 끝남.그래서 이제 프론트 작성하고 요청 해봤는데이게
51.팀플) OpenWeather API 연결

처음 계획은 백엔드로 통신하고 값까지 검증해서 관측 가능한 상태랑 불가능한 상태로 나눌까 했었는데, 가만 생각해보니까 비효율적이라는 것을 깨닫고 오직 프론트에서만 돌아가도 된다고 결론이 났음.왜? 데이터는 데이터대로 보여주고 마지막에 요청 위치의 날씨를 확인하고 그날
52.팀플) SQLAlchemy 세션 트랜잭션 관리 오류로 인해 다중 요청 환경에서 발생하는 충돌 문제 (오라클 서버 재배포)

나는 몰랐는데 팀원들이 내 코드를 받아서 요청보낼 때 행성 하나씩 오류가 나는걸 발견함.지금 문제는 ->동시에 다수의 행성 데이터를 요청할 때, SQLAlchemy 세션이 동일 트랜잭션 상태를 공유하거나 적절히 초기화되지 않아 Can't reconnect until i
53.팀플) 유성우 데이터 통신 로직
이제 유성우 데이터 통신 로직을 짜면 됨. 뭐 기존에 했던 별자리, 행성과 같음. MeteorShowerController와 MeteorShowerService생성하고 기반 다져놓고.. 이제 또 다 프론트에서 처리해야됨. 그전에 시큐리티에 등록해두자. 징글징글
54.팀플) 유성우 가시성 데이터 로직 수정 및 API 재배포
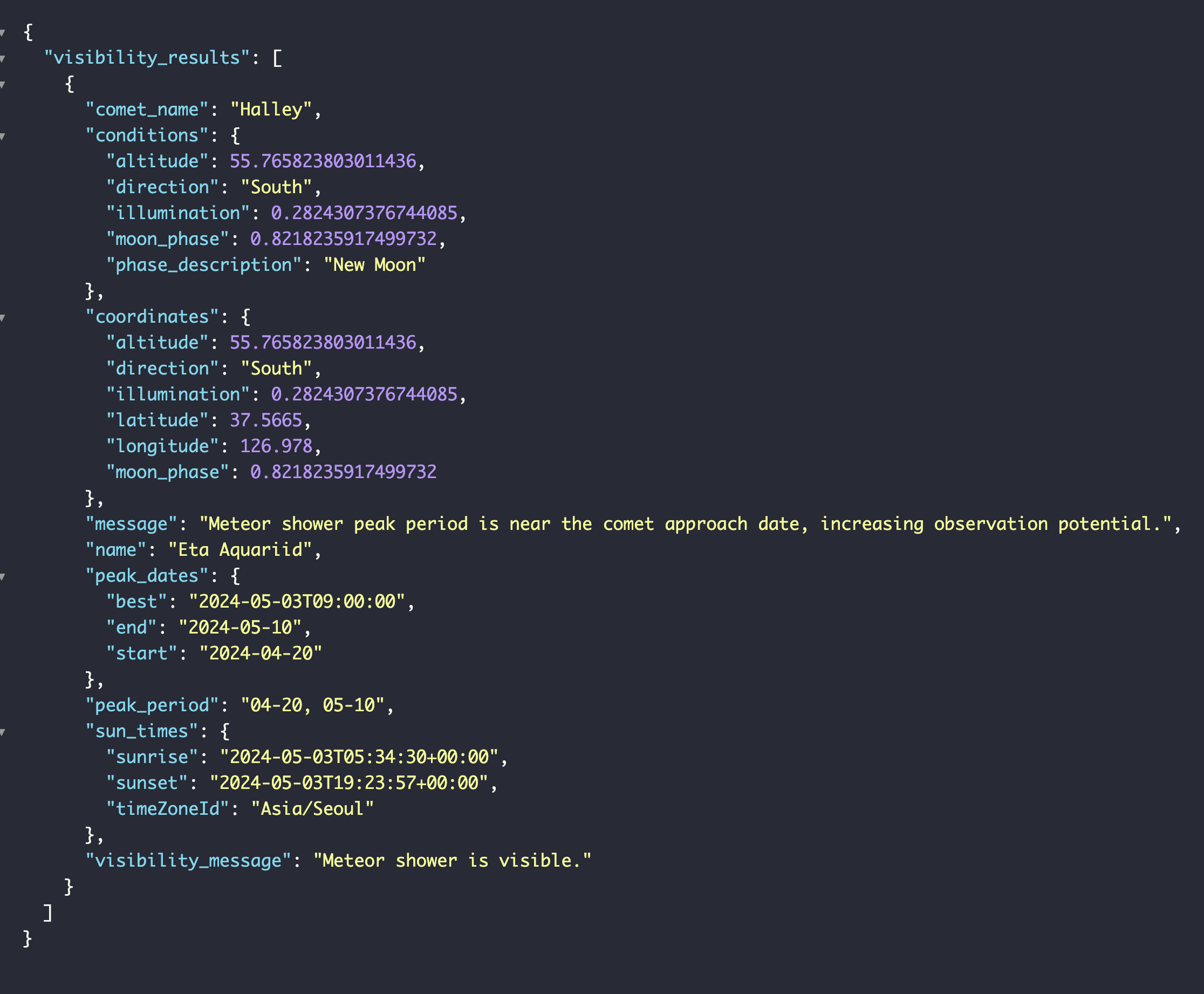
그니까 뭐가 맘에 안들었냐 하면 지금 로직은 UTC 시각 기준으로 하루만 요청을 하는데 이러면 24시간중 UTC 시간 기준으로 0시만 요청하게 되어서 데이터의 의미가 없어짐.이게 이유를 설명하자면지구는 자전중임. -> UTC기준 0시만 검증함. -> 위도 경도 값을 받
55.팀플) 유성우 데이터 백엔드 전략

유성우 데이터도 API 수정이 들어가면서 꽤나 요청 시간이 오래걸리게 되었다.그래서 우선은 요청을 날릴 때, 해당 코드로 1도 간격으로 반올림 처리를 함.어차피 국내 아니면 사용할 일이 없을 것 같다는 판단으로 이렇게 처리하고 이제 고민인데 여기 데이터에 영속성을 더할
56.팀플) Google Calendar API 연결

우선 API 연결을 위해서 다시 구글 콘솔로 진입.추가해줬음.우선 약간의 문제가 있다면 나는 데이터를 보여줄 캘린더 하나, 그리고 사용자가 천체 관측 일정을 관리할 수 있는 캘린더 하나를 이 구글 캘린더로 제공을 하고 싶었는데, 이게 내 공용 캘린더를 읽기전용으로 전환
57.팀플) 캘린더 DB 저장.

우선은 리포지토리와 엔티티를 생성하고 그에 맞게끔 연결은 했는데.DB를 추가 한 이유가 사용자 UI 개선의 목적도 있지만 결국 결론은이제 DB저장을 하면 고유한 ID 번호가 생김 -> 복잡한 형태의 고유 ID를 입력하기 싫음.이거임.그래서 지금 작성한 로직을 DB ID
58.팀플) 캘린더에 유성우 일정 업데이트.

일단 유성우든 대접근이든 한번에 요청해야하는 데이터량이 적지는 않을 것이라 판단한다.그럼 API 호출을 여러번 하게 되고, 그건 성능과 비용문제로 직결됨.그래서 이번에 도입해놓을 것은 Betch임.대량의 이벤트 추가/수정/삭제:유성우나 행성 대접근 데이터처럼 수십 개,
59.팀플) JWT 인증 방식 도입
지금 로그인 상태를 확인하는 방법이 꽤나 괴랄하다.세션 유지 방식sessionManagement.sessionCreationPolicy(SessionCreationPolicy.IF_REQUIRED)이 설정은 인증된 사용자가 있을 경우 세션을 생성해서 인증 상태를 유지하
60.팀플) 오늘 한 것.. (JWT 완전 도입 완료, 세세한 수정, 상세 페이지 CRUD)
일단 develop으로 머지 시키고 개꿀잠을 자버림. (학원 못감, 사실 너무 늦게 잔 것도 있고 무조건 해결하고 자야겠다 싶어서 감기기운도 좀 있고 머리도 아픈데 끝까지 붙들고 JWT 모든 문제 해결 이후, 기존 로직들이 유지되게끔 수정하고 잠.) 근데 이제 팀원들
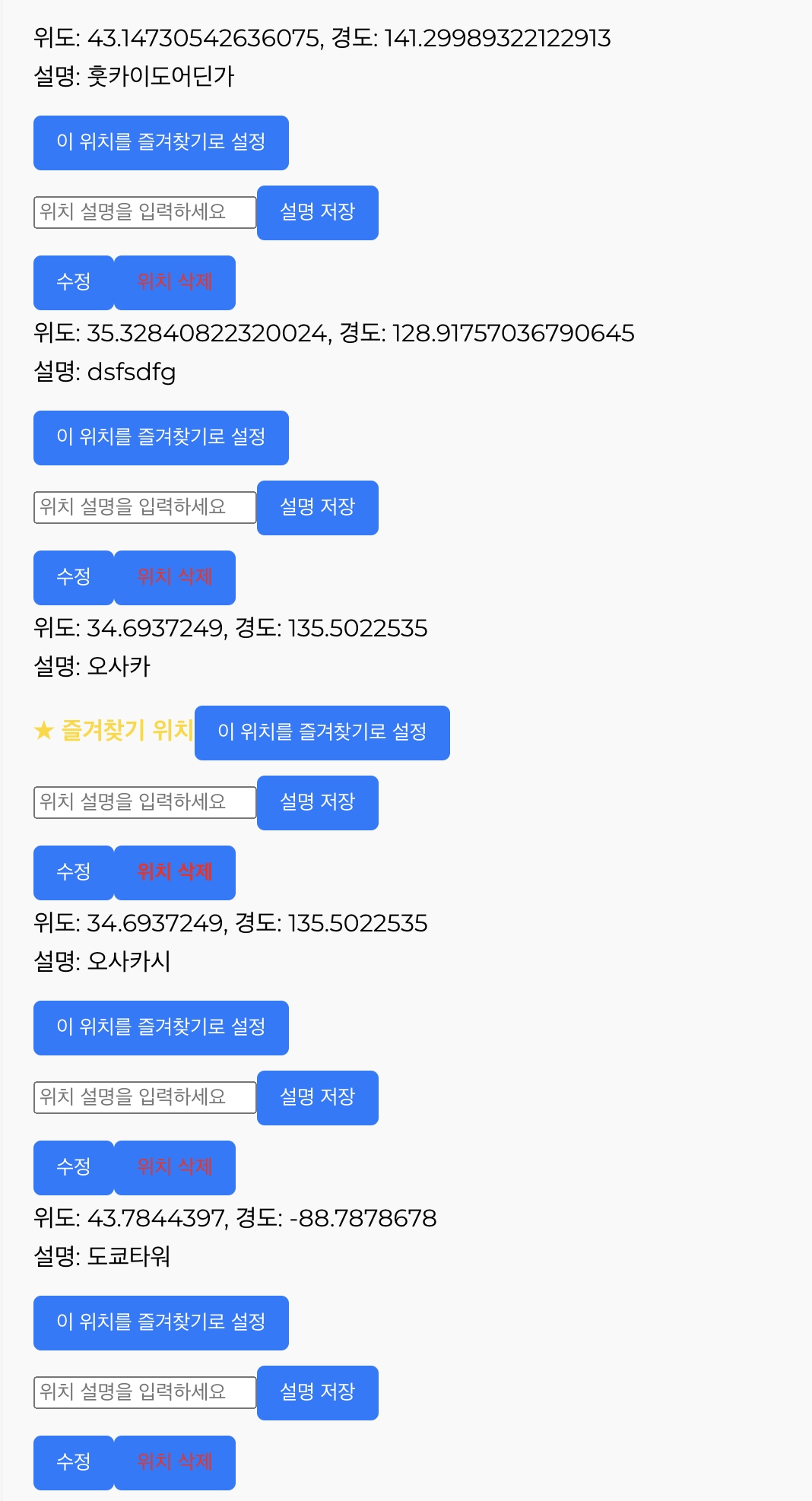
61.팀플) 디테일 수정 사항
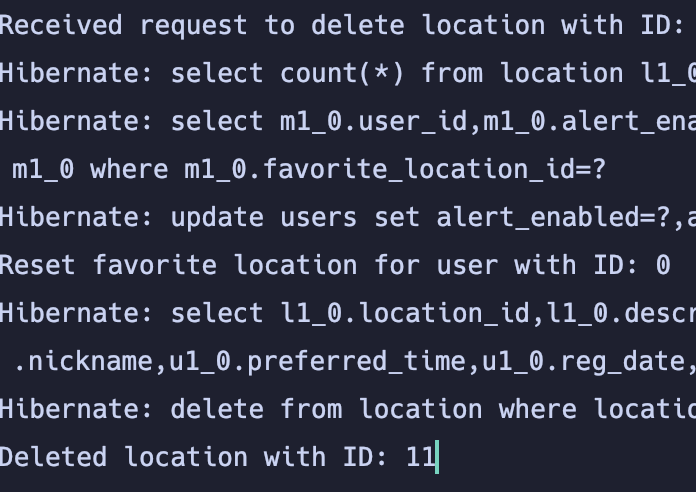
useUserLoction 함수 수정날씨 데이터 새로고침 문제 해결유저 위치 저장, 수정 로직 이슈 해결위치 삭제시 만약 즐겨찾기라면 초기화 로직 구현자잘한 문제가 발견될 때 마다 재깍재깍 수정중.아 그리고 첫 로그인 사용자에 대한 처리가 있으면 좋겠다는 생각이 들어서
62.팀플) JWT 엑세스 토큰 쿠키로 관리.
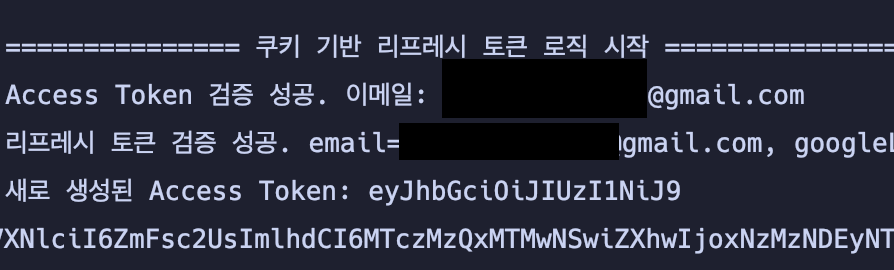
리프레시 토큰은 Redis에서 중앙화 해서 관리하고, 엑세스 토큰은 지금 브라우저 스토리지로 관리중임.허나, 스토리지는 XSS공격에 굉장히 취약함. 사실 소셜 로그인이고 빼갈 정보가 이메일정도 밖에 없어서 대충이렇게 하려고 했는데 그래도 이왕하는거 완벽하게 하고 싶다는
63.팀플) 배포 준비. 도메인 -> 자동배포 구현
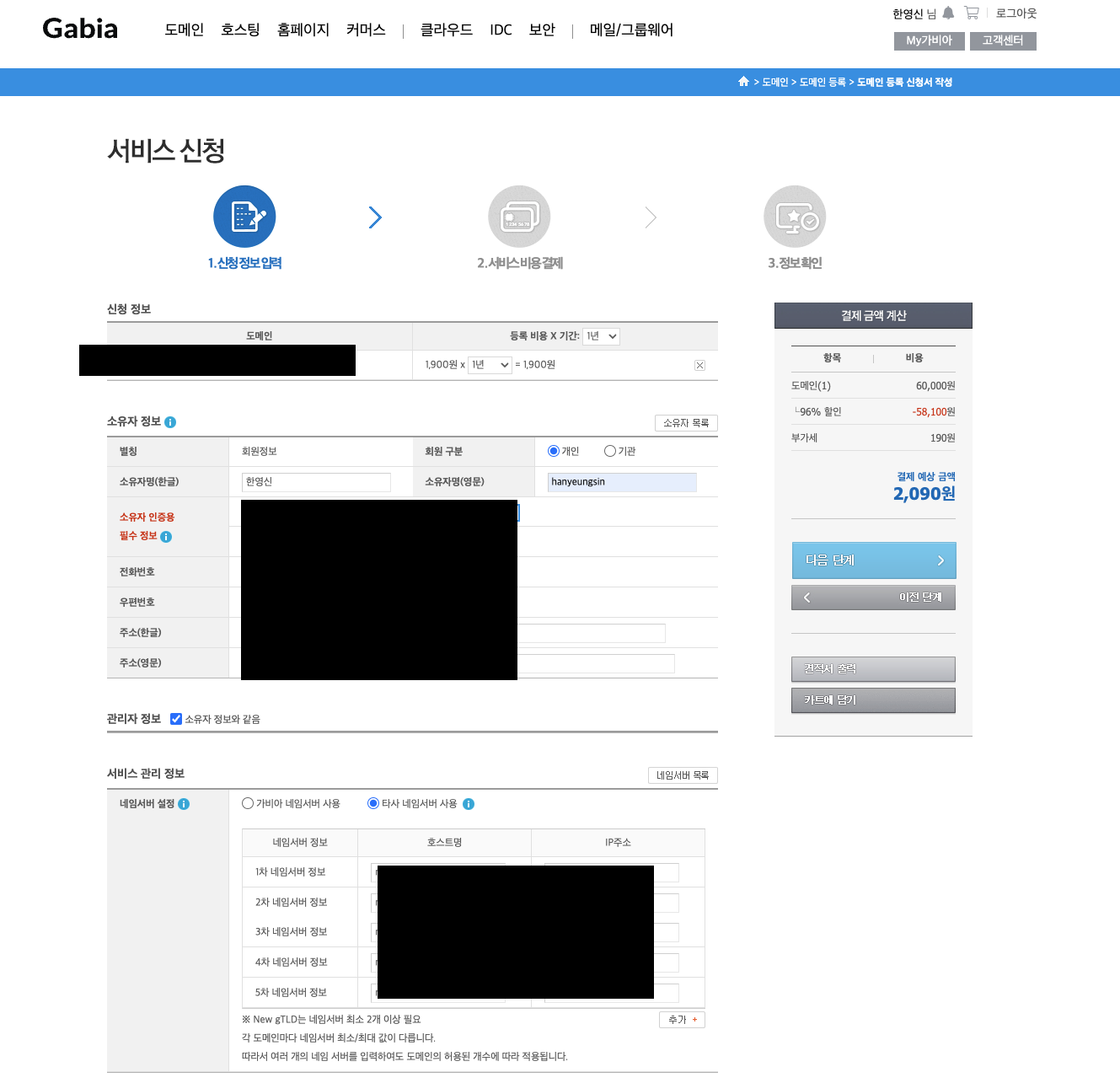
가비아에서 도메인 구입, 이번엔 안까먹고 타사 네임서버 작성함. (dnszi.com 네임서버 작성)오케이 구매 완료함.그니까 도메인 관리는 dnszi에서 할거임.여튼 구매 했으니까 다음으로는 배포 테스트에 대한 전략이 필요함.내가 배운대로 보자면 main이나 maste
64.팀플) 자동배포, 무중단 배포 구현
사실 컨테이너로 해보고 싶어서 어제 하루종일 붙들고 있다가 포기하고 서버 컴퓨터 다시 생성해서 다시 처음부터 했다.괜히 일 벌려서 일 다시 하게 생겼네.우선 컨테이너로 왜 하려고 했냐면 나는 모든게 다 한 네트워크 안에서 돌아가게 하는게 지금의 배포 구성보다 더 효율적
65.팀플) 자동배포 이후 구글 로그인 정상화
결론부터 말하자면 고쳤다.그래서 원인이 뭐였냐?백엔드가 https를 못알아먹는다. -> 이에 대한 설정을 추가함.그래도 안된다. -> 강제로 설정할 수 있게끔함.간단하게 말하면 이렇게 고쳤음.제일 처음엔 구글콘솔에 등록 하지 않은 줄 알았다. 그래서 가보니까 되어있네?
66.내 소개 사이트 제작중 생긴 문제 해결. nginx 도메인 설정, https 적용 후 재배포

아 지금 한참 만들고 있는데 이왕하는거 내가 만든 API 연결해서 뭐 하면 좋겠다 싶어서 달의 위상 요청 후에 반환하고 그 정보를 띄우기로 했음.그래서 로컬 환경에서는 잘 되는데,이게 배포 환경애서는 안되길래 어? 왜지? 싶어서 보니까.https랑 http랑 통신이 금