우선 QGIS는 일단 내려놓기로 했고,
면접에서 요구하는 것에 집중해서 완성 시켜보기로 했음.
일단 데이터 두가지는 확실하게 가공과 시각화가 가능하다는 것을 확인했으니 발표 시점에는 이 두개를 주로 다루긴 할테지만 어찌 됐던간게 제대로 된 발표를 위해서는 더욱 확실한 지표가 여러개가 더 있었으면 좋겠다고 생각을 해서 다른 일 하면서 이래저래 고민을 조금 해봤는데 그에 대한 결과로 나온게,
GDRP -> 지역내 총 생산량과 상권 데이터, 그리고 나는 아무리 생각해도 국회의사당 이전이라는게 사회적 정치적 해석이 들어가지 않을 수 없다고 판단했기 때문에 크롤링을 기반한 여론 데이터 또한 필수라고 생각을 함.
그래서 총 정리를 하자면 내가 만약 국회의사당 이전에 따른 영향 분석을 실제로 하게 된다면 분석에 사용할 데이터는 네가지.
- 부동산 변동률 데이터
- 인구 이동률 데이터
- GRDP와 상권 데이터
- 소셜미디어 크롤링(해시태그 등)을 통한 긍정/부정 여론
이렇게 네가지다.
그럼 데이터를 제대로 사용할 수 있는가를 확인을 하고 넘어가야되니까.
부동산 변동률 데이터와 인구 이동률은 내가 이미 가공도, 시각화도 해 봤으니 출처는 이전 포스팅에 나와있고, 확인할 것은 GDRP의 데이터가 통계청에 존재하는지와 상권 데이터를 구할 수 있는지, 그리고 소셜미디어 크롤링을 어떻게 진행할 것인지에 대한 계획과 실현 가능성에 대해서 조사를 해보면 된다.
순차적으로 가자고.
우선 GRDP에 관한 것부터 찾기 시작했는데 비교적 찾기 쉬울 것 같다.
보자보자..
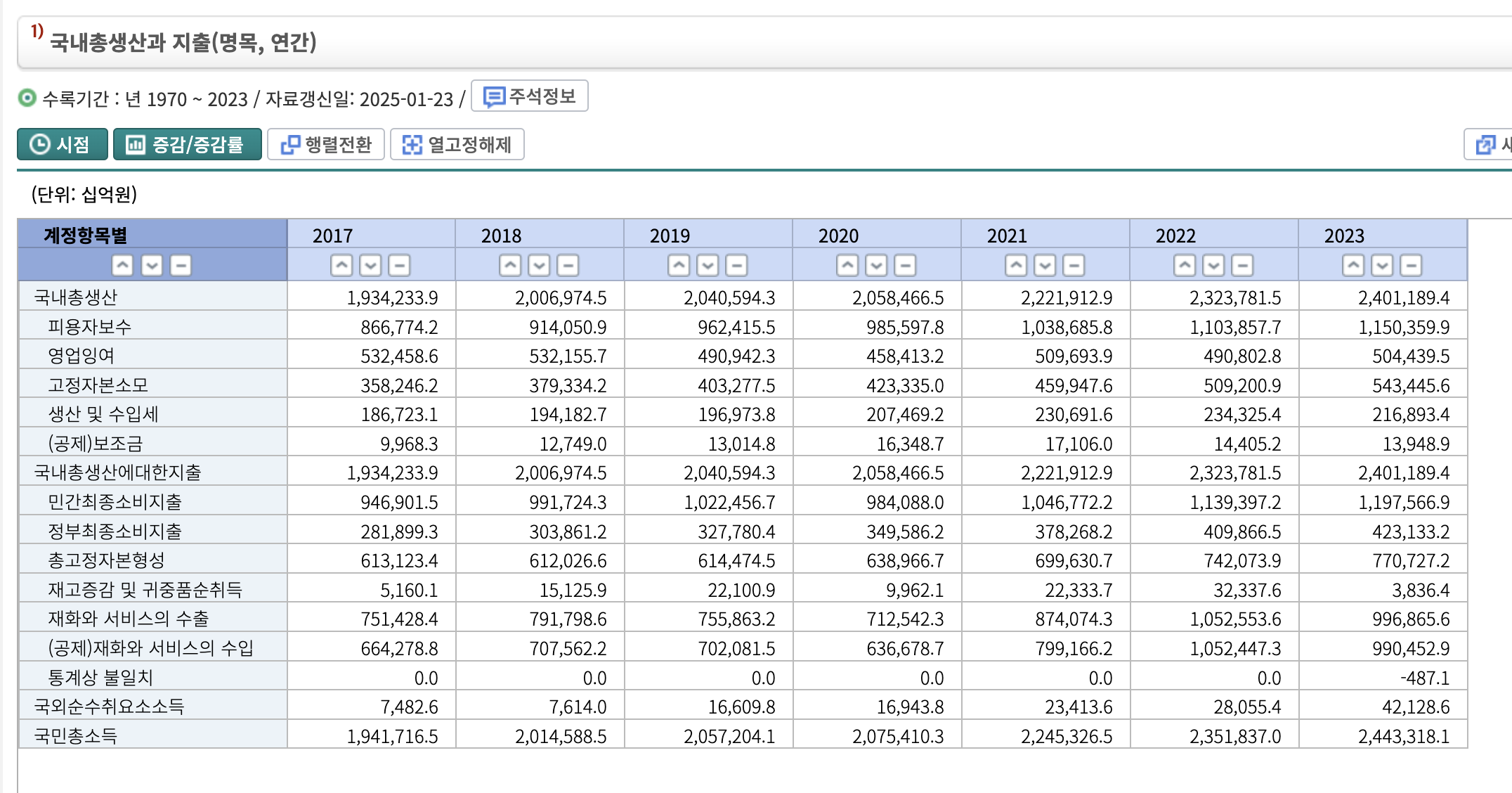
이런 것도 찾긴 했는데 지역별 비교가 어려워서 어떤 영향을 미쳤는지는 알 수 없으니 패스.
엑셀 파일도 찾았는데 이것도 년도가 너무 과거라 패스
GRDP로 검색시에 아무것도 안떠서 '지역내총생산'이라고 검색하니 쓸만한 것들이 보인다.
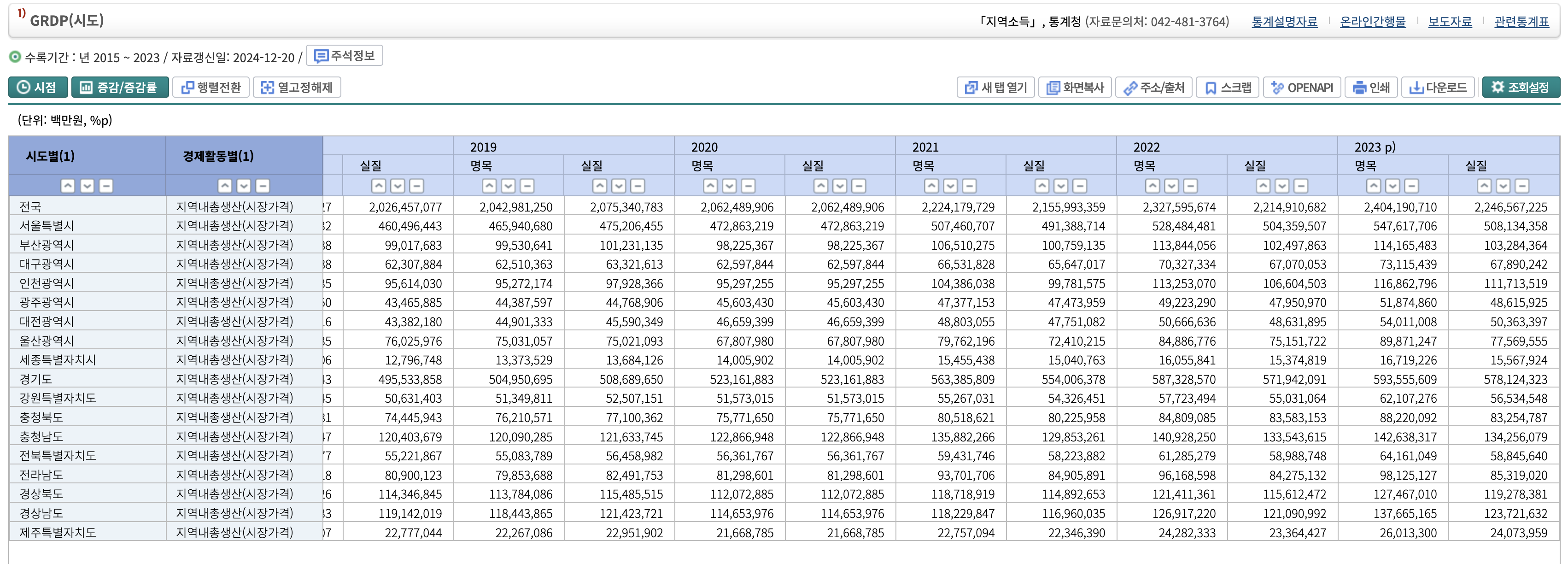
음 이 데이터라면 쓸 수 있을 것 같다. 가공하고 그래프 그려보는 것 까지 해보고 싶지만 일단 참자..
그럼 다음으로는 상권 데이터다.
지금 좀 살펴보니까 상권보다는 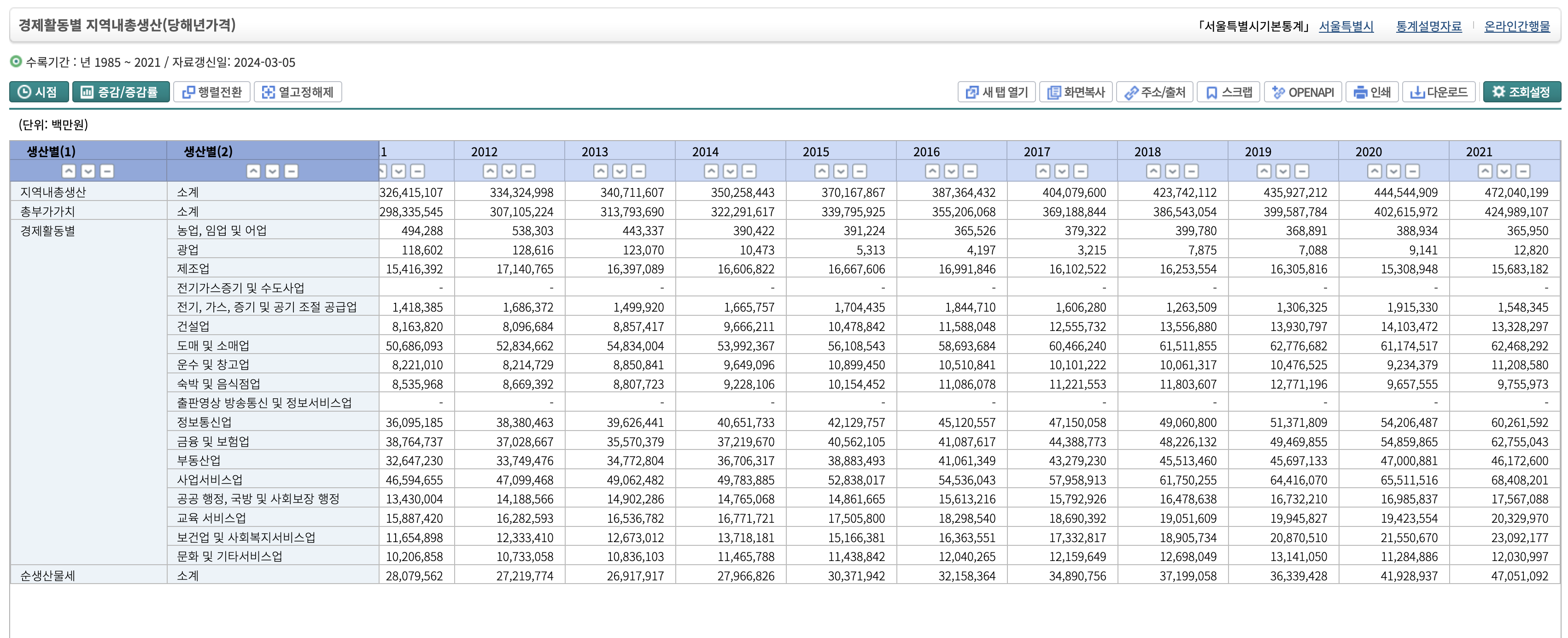
이런 데이터로 쓰는게 국회의사당 이전으로 인한 경제활동별로 어떤 업계가 성장했는지 더 확실하게 구분이 가능할 것 같다.(이런게 영향의 확실한 지표니까.)
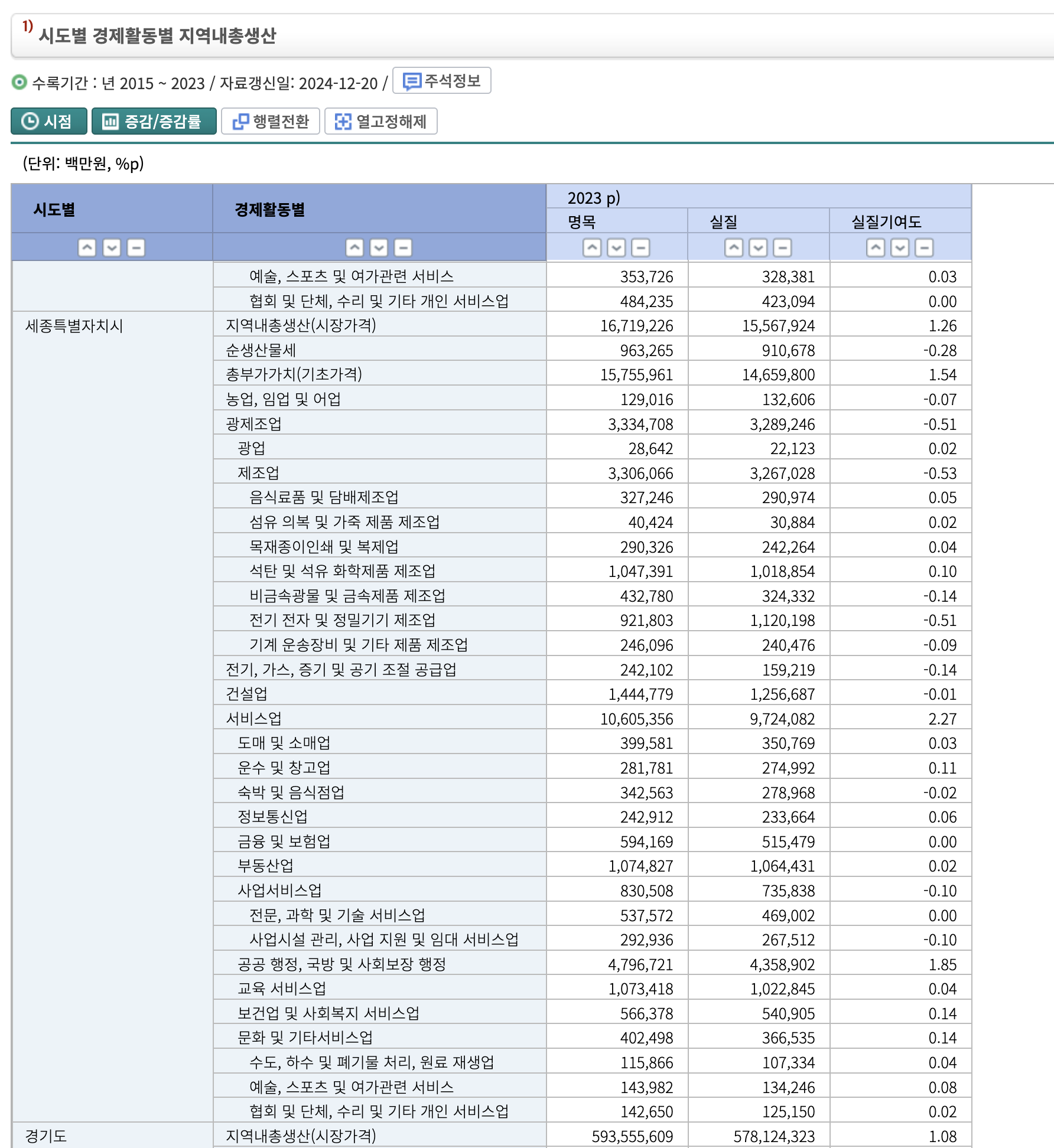
찾았다.
그럼 마지막으로는 소셜미디어 크롤링인데, 역시 제일 핫한 인스타그램을 크롤링하는게 확실하지 않을까? 싶어서 그 방법에 대한 것을 찾아보면 될 것 같다.
... 우선은 가능한 것으로 보이고, Meta for developer로 검색해보니까 인스타그램 뿐 아니라 페이스북이나 스레드까지 크롤링할 수 있을 것으로 보인다.
하지만 이건 어떻게 데이터를 크롤링하느냐 보다, 크롤링한 데이터를 어떻게 정규화하고 긍정/부정 여론을 구분하는 방법이 제일 문제다.
이거야말로 직접 부짗히면서 해보지 않으면 진짜 감을 못잡을 것 같은데, 시나리오를 좀 짜보자.
우선 크롤링 자체는 별로 어렵지 않을 것 같다. api 요청 방식을 까보지는 않았지만 해시태그를 검색하는 기능은 다들 있을거라고 확신하니까.
우선은 수집한 데이터를 DB에 잘라서 저장할 수 있도록 하면 될 것 같음. 글의 내용이랑 공감 수, 날짜, 댓글 수 까지. 가능하면 성별과 연령대까지 할 수 있으면 조금 더 세분화 시킬 수 있을듯?
그러고 난 이후에는 무분별하게 저장한 데이터를 가공해야하는데..
여기서는 NLP로 처리할 수 있게 계획해서 부정과 긍정을 카운터하고 DB에 해당 칼럼을 추가해주면 될 것 같다.
NLP가 나도 지금 처음 알게된 개념이긴한데 인간이 사용하는 언어를 컴퓨터가 이해하고 처리할 수 있게 하는 AI 기술이라고 한다.
여기서 사용할 수 있는게 konlpy나 KoBERT가 있다고 한다. 자동화는 스케줄러로 만든 스크립트가 일정 시간마다 자동으로 실행되게 하면 될듯.
여튼 이렇게 하고 이 내용 바탕으로 PPT 만들었고,
간단 분석을 총 정리 하자면
국회의사당 이전 발표에 따른 영향 분석 요약
1. 부동산 시장의 변화
- 주요 관찰점:
- 세종시 아파트와 일반 주택 모두 2019~2020년 국회의사당 이전 발표 이후 가격이 급격히 상승.
- 2020~2021년 최고점을 기록한 뒤 하락세를 보이며 안정화 국면에 접어듦.
- 수도권과 전국은 세종시만큼 급격한 변화는 없으며, 상대적으로 안정적.
- 해석:
- 국회의사당 이전 발표는 세종시 부동산 시장에 직접적인 영향을 미쳤으며, 단기적 과열 현상을 유발.
- 이후 시장은 안정화되었으나 여전히 다른 지역보다 높은 변동성을 보임.
2. 인구 이동률
- 주요 관찰점:
- 세종시는 다른 지역(서울, 경기도, 전국)보다 전반적으로 높은 인구 이동률을 보임.
- 2019~2020년 국회의사당 이전 발표 시점:
- 세종시로의 인구 유입률이 눈에 띄게 증가.
- 이후 2021년부터 안정적인 수준을 유지.
- 수도권(서울, 경기도)과 전국은 비교적 변화가 크지 않고 안정적.
- 해석:
- 국회의사당 이전 발표는 세종시로의 인구 유입을 단기적으로 촉진했으며, 이는 부동산 시장 과열과 연결.
3. 경제활동별 GRDP 변화
- 주요 관찰점:
- 서비스업과 제조업은 꾸준히 성장하며 세종시 경제를 주도.
- 건설업은 국회 이전 초기 인프라 조성 이후 감소세.
- 농업, 임업 및 어업은 지속적으로 감소, 도시화와 경제 구조 변화 반영.
- 국회의사당 이전 발표가 경제활동별 GRDP에 직접적으로 미친 큰 변화는 관찰되지 않음.
- 해석:
- 세종시 경제는 안정적인 성장을 이어가고 있으며, 국회 이전 발표의 직접적 영향보다는 장기적 발전의 일환으로 보임.
최종 결론
- 국회의사당 이전 발표는 세종시에 강력한 단기적 효과를 미쳤다:
- 부동산 시장의 가격 급등 및 인구 유입률 상승이 이를 입증.
- 이는 세종시가 국회 이전 정책의 중심지로 기능하고 있음을 보여줌.
- 중장기적 변화는 안정화 경향을 보임:
- 부동산 시장과 인구 이동률 모두 시간이 지나면서 안정적 흐름을 유지.
- 경제활동별 GRDP는 발표 이후 큰 변화 없이 안정적으로 성장.
- 실제 이전시 미칠영향:
- 이전 직후에는 급상승세를 보일 것 같음.
- 이후 안정화 과정에서는 급등후 중단기적인 하락이 예상됨.
이 결론이다.
오케이 면접 발표 잘하고 와야겠다. 남은 시간동안은 회사 자체를 좀 알아보고 데이터 분석 자체에 대한 정보를 더 알아봐야할듯.
