아키텍쳐
Test에 무슨 아키텍쳐? 라고 할 수도 있지만 앞에서 보았듯이 테스트가 힘들다는 코드의 구조가 잘못되었다를 의미한다.
테스트하기 쉽다 == 좋은 코드일 확률이 좋다
위 명제를 따르면 매우 쉽게 개발할 수 있다.
강사는 아키텍쳐를 비즈니스 문제를 해결하기 위해 준수해야 하는 제약 이라는 표현을 하였다.
그래서 써야하는 이유가 없다면 없는게 나을 수도 있다고 했다.
따라서 제약을 정하기 전에 팀원들과 공감대를 형성하지 못한다면, 그냥 방해물이 될 뿐이라고도 한다.
아키텍쳐를 사용하는 아키텍트들의 목표는 크게 두가지로 나뉜다.
1. 인력 자원 절감
- 인적 자원 절감은 경계선을 나눠 동시 작업 을 가능하게 해야 한다
- 이를 위해서는 의존성 역전이나 다른 아키텍쳐를 이용해 경계선을 나눈뒤 빠르게 개발을 가능하게 한다
2. 정책을 만들고 세부사항을 미루는 시스템 개발
- 개발시 처음에는 데이터베이스 시스템, 웹서버, 프레임 워크 등등을 적용 할 필요 없이 개발만 가능하게 해야 한다.
- 가장 중요한 것은 도메인 이다.
- 도메인이 핵심인데 이를 어기면 프레임워크, 특정 DB등에 의존하게 된다.
헥사고날 아키텍쳐
의존성 역전
많이 나온 개념이지만 한번 더 간단히 정리하면
관심사를 분리한다.
고립을 시키는데 완전한 고립이 아닌 서로에게 영향이 없을 정도의 고립 이다.
내가 청소를 하는데 삼성 청소기이든, LG이든 독일제든 뭐든 그냥 전원넣게 파워를 켜면 청소가 가능하다.
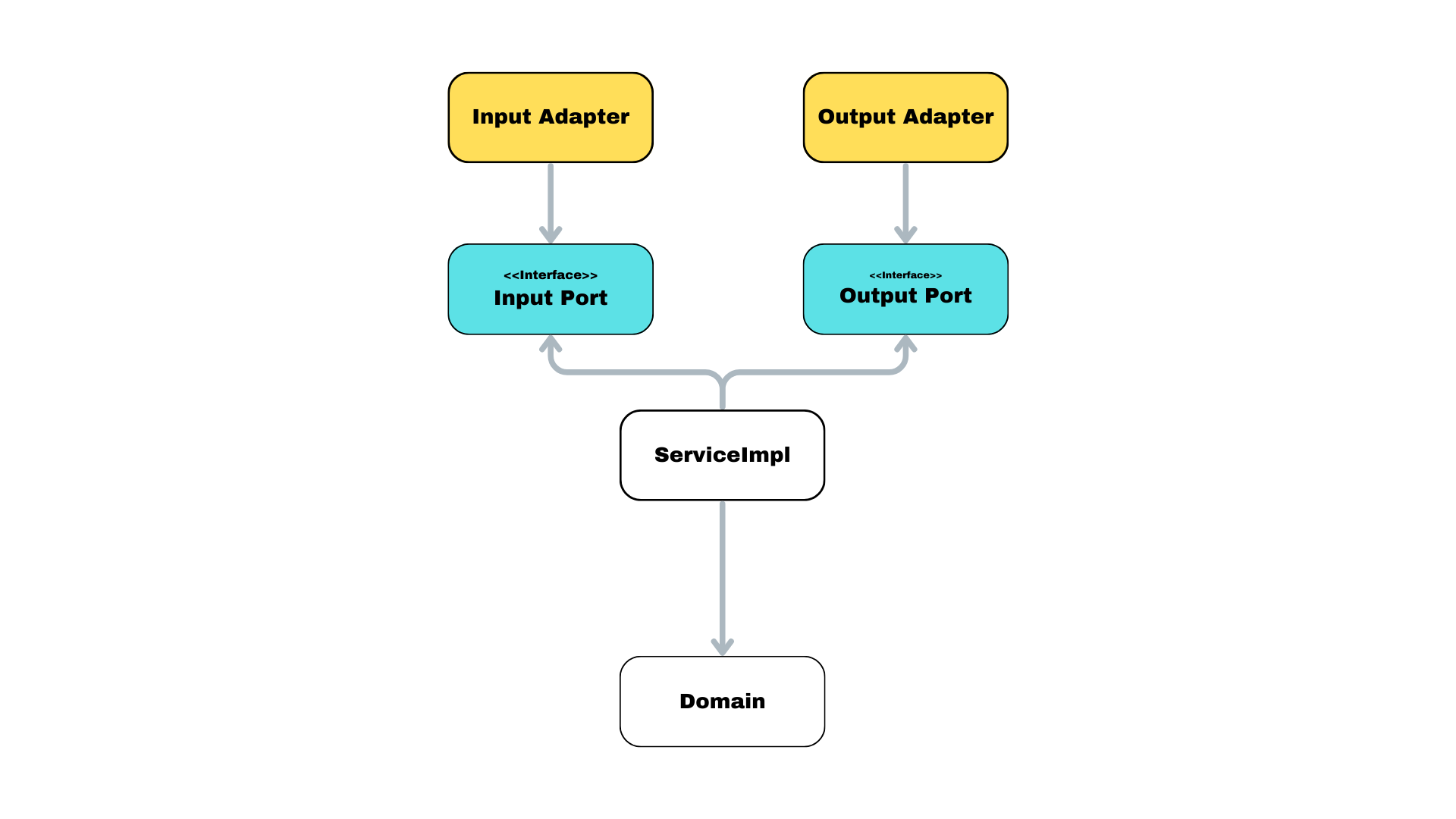
이런 의존성 역전을 패턴으로는 포트 - 어댑터 패턴 이라고 한다.
인터페이스에 필요한 포트를 꽂아주는 느낌이라 그렇다.
A -> interface <- implement
같은 느낌일때 A와 implement 둘다 인터페이스만 알면 된다. 그 뒤에 누가 있는지 몰라도 상관 없다. 여기서 A == inputAdapter(시키는 놈) , implement == outputAdapter(하는 놈), interface == Port 로 불린다.
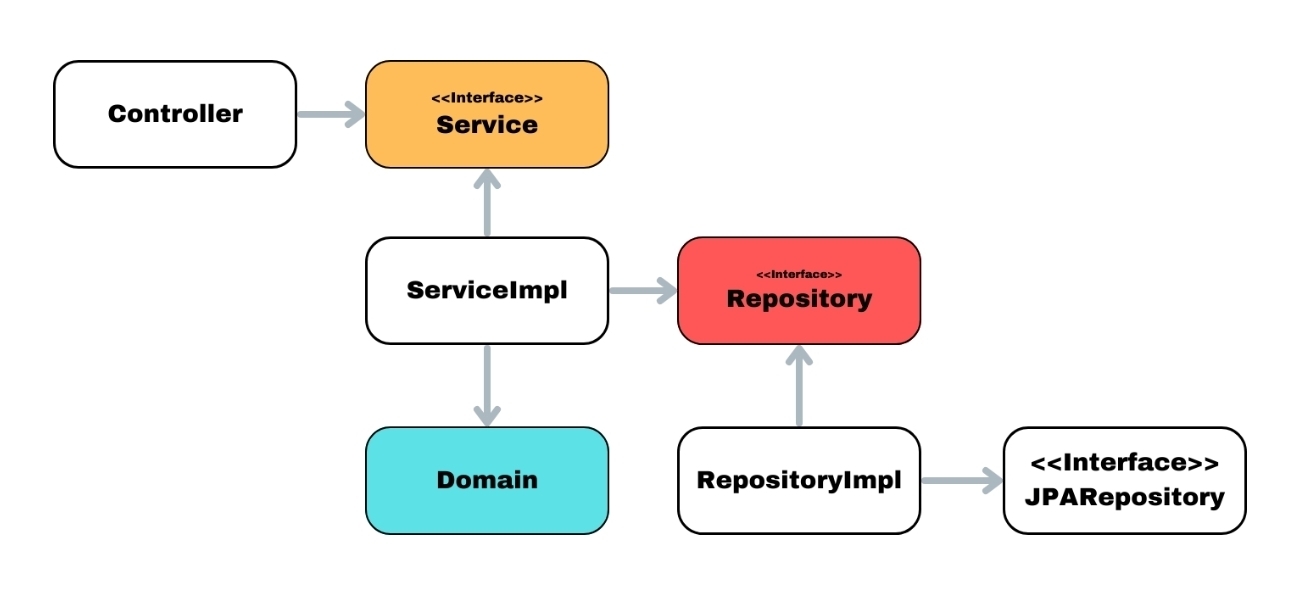
이제 이 그림에 포트 - 어댑터 패턴을 적용하면
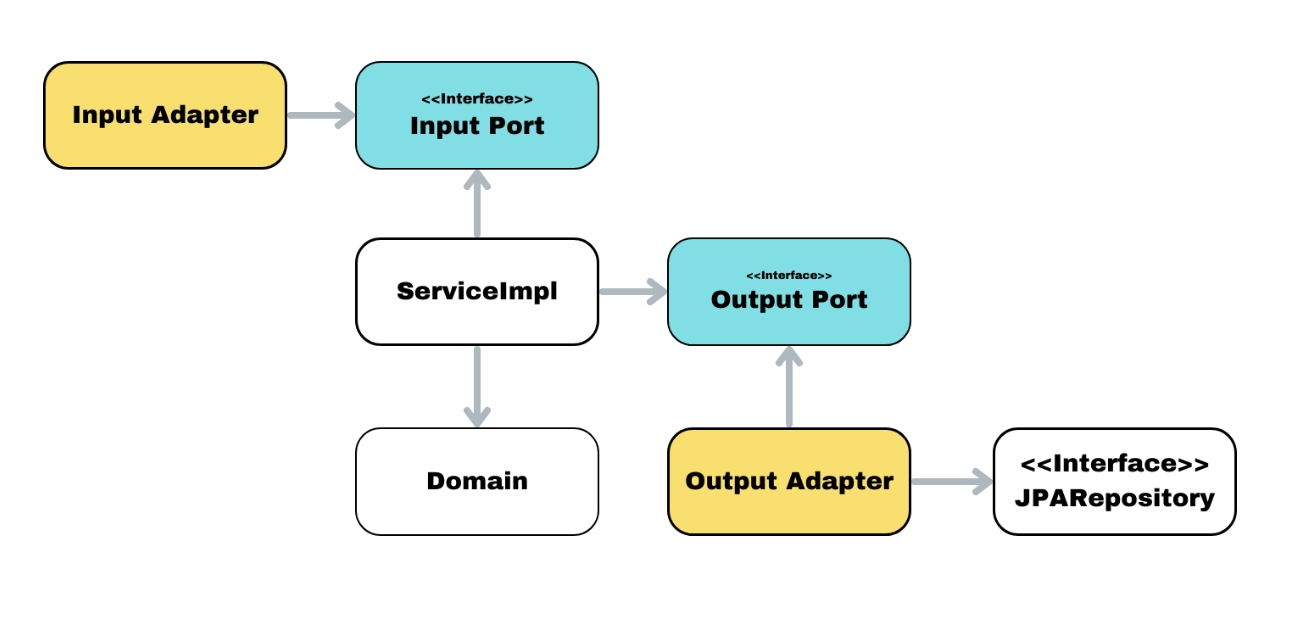
이렇게 바뀌고 이를 배치만 변경하면
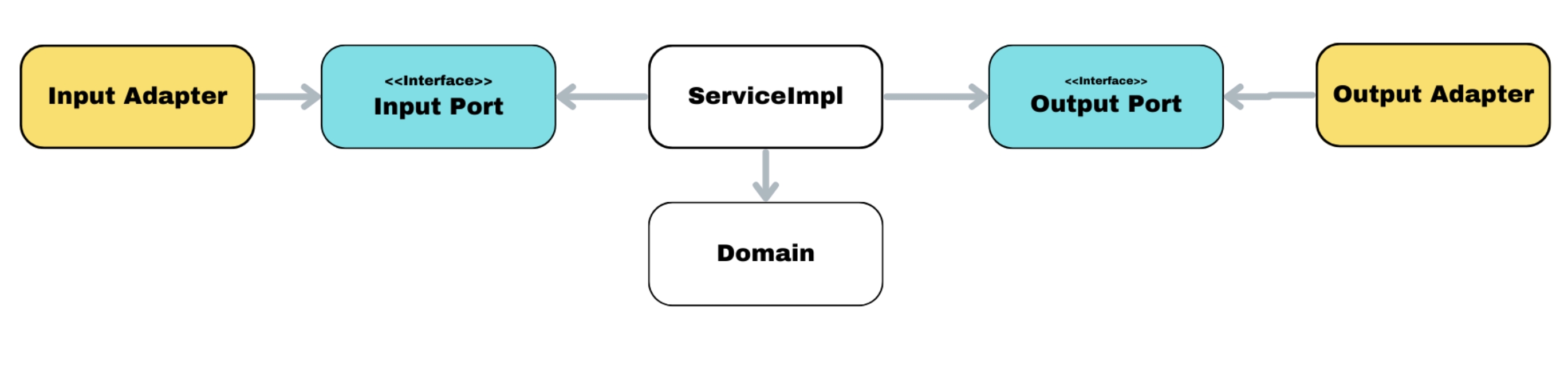
간단하게 바뀌었다.여기서 경계를 Port를 기준으로 하고 거기서 domain에 한번 더 경계를 그으면 끝이다.
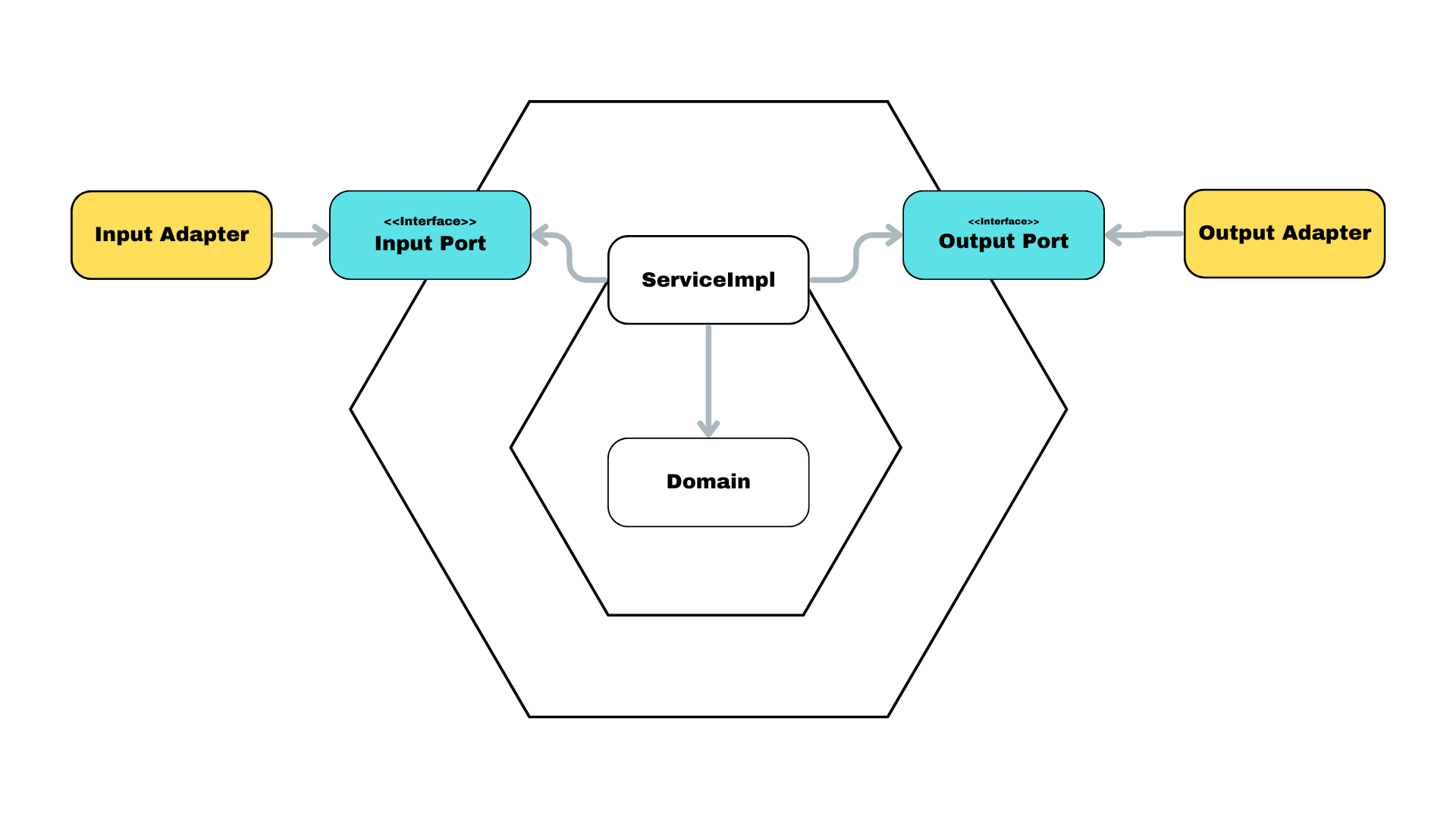
이제 헥사고날 아키텍처에 대해서 다 배웠다. 끝.
장점은
1. 도메인으로 가는 방향이 단방향이기 때문에 Domain은 고립되고 따라서 순수해진다.
2. 외부 세계(프레임 워크 등등) 에는 관심이 사라진다.
3. 그리고 테스트가 편해진다.
헥사고날과 클린 아키텍처
사실 둘을 거의 같은 이야기라고 한다.
InputPort 가 Usecase로, OutputPort가 Gateway로 , 외부세계는 그냥 Humble로 바뀌면 끝이다.
헥사고날 아키텍쳐 특징
위 헥사고날을 변경한 그림이다.
상향식으로 접근하면 자연스러워 진다.
그리고 이렇게 보면 본질과 험블(Adapter)을 구분 가능해진다.
그 말은 내가 Input, Output Adapter가 바뀌더라도, Domain은 그대로 유지가 가능하다는 것이다. 우리는 그냥 구현 방식만 병격하면 된다.
InputAdapter
InputAdapter의 역할은 생각보다 별 거 없다. 스프링의 경우 권한이나 매핑은 알아서 해주고, 들어온 요청을 받아서 계산하고 반납하면 된다.
OutputAdapter
OutputAdapter 도 똑같다. 들어온 요청을 DB, Internet에 전송 가능하게 매핑하고, 전송하고, 결과를 다시 사용가능하게 매핑해서 돌려준다.
Input Port
클린 아키텍쳐에서의 UseCase인데 이것을 중요하게 보았다.
개발자는 개발시 크게 3가지로 인식하는데
1. Usecase 2. Platform 3. Application으로 인식한다고 한다.
그러니까 1. 주문하기 2. Spring 3. Backend, 1. 주문하기 2. React 3. Frontend
이런식이다. 여기서 2, 3은 없어도 크게 무리없이 설명 가능하지만, 1은 없으면 무엇을 할려는지 설명 조차 되지 않는다.
모델은 어디까지 세분화 해야 하는가?
이곳은 아직 어떻게 해야 한다 정해지지 않은 분야라고 한다.
구분을 하지 않으면 강결합이 일어나고, 그렇다고 하면 ORM을 쓸 필요가 없다 이런 입장과 부딪힌다.
단일모델
먼저 단일 모델은 모든것을 Domain에서 가져오는 구조인데. 문제점이 있다.
내가 나의 정보를 조회할 때는 주소랑 모든 정보를 내려줘야 하지만.
다른 사람이 조회할때는 특정 정보는 빼고 줘야하고 특정 정보만 받아야 하기 때문에
입력 출력 모델은 여러개가 있을수 밖에 없다.
2단 분류 + 영속성 모델
이제 단일 모델에서 domain이 직접 DB를 연동하면
웹모델 / 도메인 + 영속성 모델이다. 도메인 엔티티와 Jpa 엔티티가 동일하기 떄문에 강하게 결합되어 있다고 할 수있다.
3단 분류 모델
위와 같은 이유로 domain은 그대로 두고 entity를 구분하였다 앞선 TDD3 참고
이렇게 하면 웹모델/ 도메인모델 /영속성 모델로 3단 분류를 한 모델이다.
InputPort, OutputPort 모델 적용
위 3단 분류 모델에서 서비스가 커지다 보면 매서드에 파라미터가 너무 많아져 가독성이 떨어지는 문제가 생긴다. 이럴 때 inputPort와 Service를 위해 입력을 받아주는 모델을 하다 생성한다. OutputPort도 같은 이유로 모델을 만들어 주면 된다.
이러면 웹 모델 / inPort 모델 / 도메인 모델 / outPort 모델 / 영속성 모델 로 5단 분류를 한다.
한걸음 더
위 분류에서 생긴 모든 모델은 domainModel에서 파생되었긴 때문에 모든 모델은 단일 Interface에서 파생하게 만들 수도 있다. 이걸 단방향 매핑 전략 이라고 한다.
원칙은 원칙이고 편의성은 따로 따져야 한다.
정답은 없다. 프로젝트 사이즈에 따라 구성이 과해지면 구성을 하기 위한 시간이 더 오래 걸릴 수도 있다. 따라서 만들려는 구성에 따라 아키텍트는 분류를 정해서 개발을 이어 나가야 한다.
JPARepository
Repository를 다루는 방법을 생각해 보자
1. as Repository - Service가 바로 의존 방식
2. as RepositoryImpl - Interface 를 두고 거기에 JPA 상속, Service는 Interface에 의존
3. as RepositoryImpl's member - Interface를 두고 Impl이 JpaRepository를 들고있는 방식, 지금까지 해온 방식
가 있다.
1. 방식
레이어드 아키텍처에서 사용한 방식인데 사실 JpaRepository는 이미 인터페이스 이기 떄문에 FakeRepository를 상속하게 할 수 있다.
하지만
Fake 구현시 불필요한 인터페이스도 구현해야 하고
Service가 불필요한 모든 메소드를 알게 되고
DomainEntity가 영속성 객체에 의존하게 딥니다.
마지막으로 JPA에 서비스가 의존하게 됩니다.
2. 방식
interface에 사용해야 하는 인터페이스만 사용하면 된다. 그러면 JpaRepository가 이를 감지하고 구현체를 만들어준다.
이러면 위 단점 중 불필요한 인터페이스 구현과 모든 메소드를 알게 되는 문제를 해결 할 수 있다.
하지만 아직 나머지 문제는 해결 불가능해 JPA에 의존하게 됩니다.
3. 방식
위 1, 2를 모두 해결 가능하다.
서비스 레이어는 추상화 해야 하나?
서비스 레이어는 우리가 위에서 배우 InputPort를 의미 하는데 어댑터의 역할중 대부분은 Spring이 다 해준다. 그래서 사실 호출만 하면 된다. 따라서 굳이 해야하나 라는 입장을 가진 사람들도 있다고 한다.
따라서 서비스 레이어는 굳이? 싶으면 추상화 안해도 되긴 하는데
원칙은 추상화 하는거고, 특히 스프링은 필요 없어 보이기도 한다.
상황과 내 취향에 따라 진행하면 된다.
그리고 어차피 트레이드 오프는 개발자에겐 숙명과 같은일인것 같다.
위 문제에 대한 해답을 찾으려면 결국 추상화는 얼마나 되어야 하는가와 연결되는데
이를 클린 아키텍쳐에서 나온 책에서 나온 말과 연결하면
시스템 안정성과 추상화 정도와 관련된 그래프를 보면 된다.
고통의 구역과, 쓸모없는 구역 사이 어딘가의 내 취향과 상황과 기타 등등등등등등등을 따지면서 하면 된다. 결국 정답이 없다로 귀결된다.
테스트 팁
범위
사람마다 다르다 중요한건 릴리즈때 확신을 줄 수 있어야 한다
자바와 Junit을 활용한 실용주의 테스트에서 Right-BICEP라는게 있는데
Right - 결과가 정확한지
B - 경계조건이 맞는지 확인 (Edgecase 등)
I - 역관계를 검사 가능한지?
C - 내가 구현과 유사한 라이브러리가 있다면 검사하라
E - 오류를 강제로 일어날 수있는지?
P - 성능 조건은 기준에 부합하는지?
팁
- ParameterizedTest - 동일 로직은 여러번 돌리고 싶다면, 가시성이 좋아진다.
- AssertAll - 실패와 상관없이 모든 assert를 돌리기
- 하나의 테스트는 한개만 테스트 해야함, 하지만 가독성이 높다면? 맘대로
- 비동기 처리는 Trhead sleep을 이용하면 결과가 달라질 수 있다. 따라서 thread.join을 사용한다. 사용이 안되면 Awaitility가 좋다.
- FIRST원칙을 지켜라
관련 어록
마틴 파울러가 한 말이 많다
이후 공부법
비즈니스의 집중 - DDD
비즈니스 잘짜고 싶어? - Test
비즈니스와 기술을 분리 - 클린 아키텍처
비즈니스와 기술을 분리하는 여러 구체적인 방법 - 헥사고날 아키텍쳐
이다.
테스트가 중요하다 란걸 알고 있었는데 이제 왜 와 어떻게 라는 핵심을 알게 되었다.
