https://school.programmers.co.kr/learn/courses/30/lessons/181871
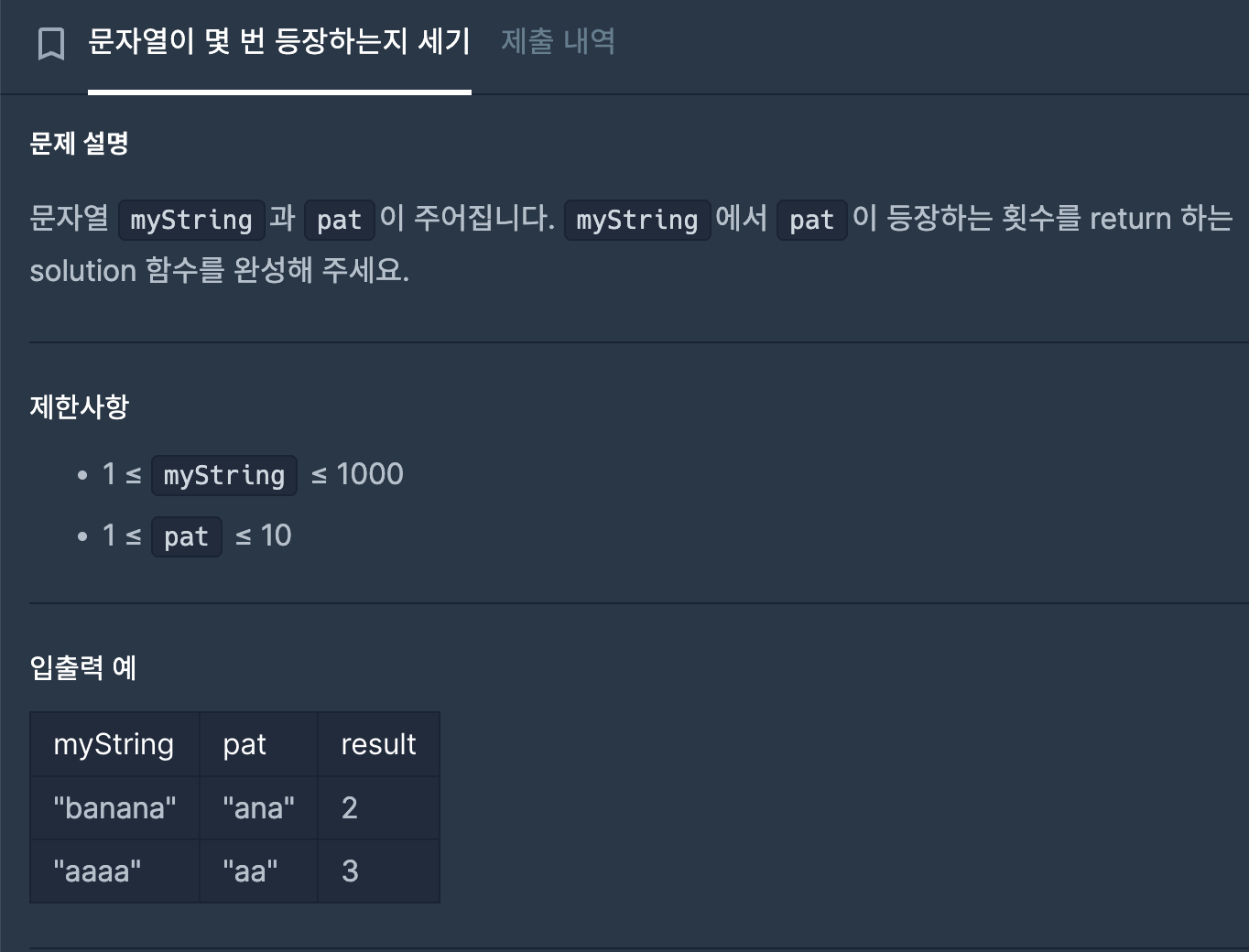
문자열에서 특정 부분 문자열의 개수를 세려고 할 때, 많은 사람들이 count()를 사용한다.
하지만 아래와 같은 경우에는 기대한 결과가 나오지 않는다.
문제 상황
"banana".count("ana") # 결과: 1
"aaaa".count("aa") # 결과: 2직접 보면 다음과 같이 더 많이 나와야 한다고 생각할 수 있다.
예시 1: "banana"에서 "ana"

총 2번 등장한다.
예시 2: "aaaa"에서 "aa"

총 3번 등장한다.
그런데 count()는 각각 1, 2를 반환한다.
원인: count()는 겹치는 경우를 세지 않는다
count()는 부분 문자열을 찾으면, 그 문자열의 길이만큼 건너뛴 후 다음 탐색을 진행한다.
즉, 겹치는(overlapping) 경우를 고려하지 않는다.
예를 들어 "aaaa"에서 "aa"를 찾는 과정은 다음과 같다.
index 0에서 "aa" 발견 → 카운트 +1
index 2로 이동 → "aa" 발견 → 카운트 +1
종료
이 과정에서 index 1, 2에서 시작하는 "aa"는 무시된다.
해결 방법: Sliding Window Algoritm
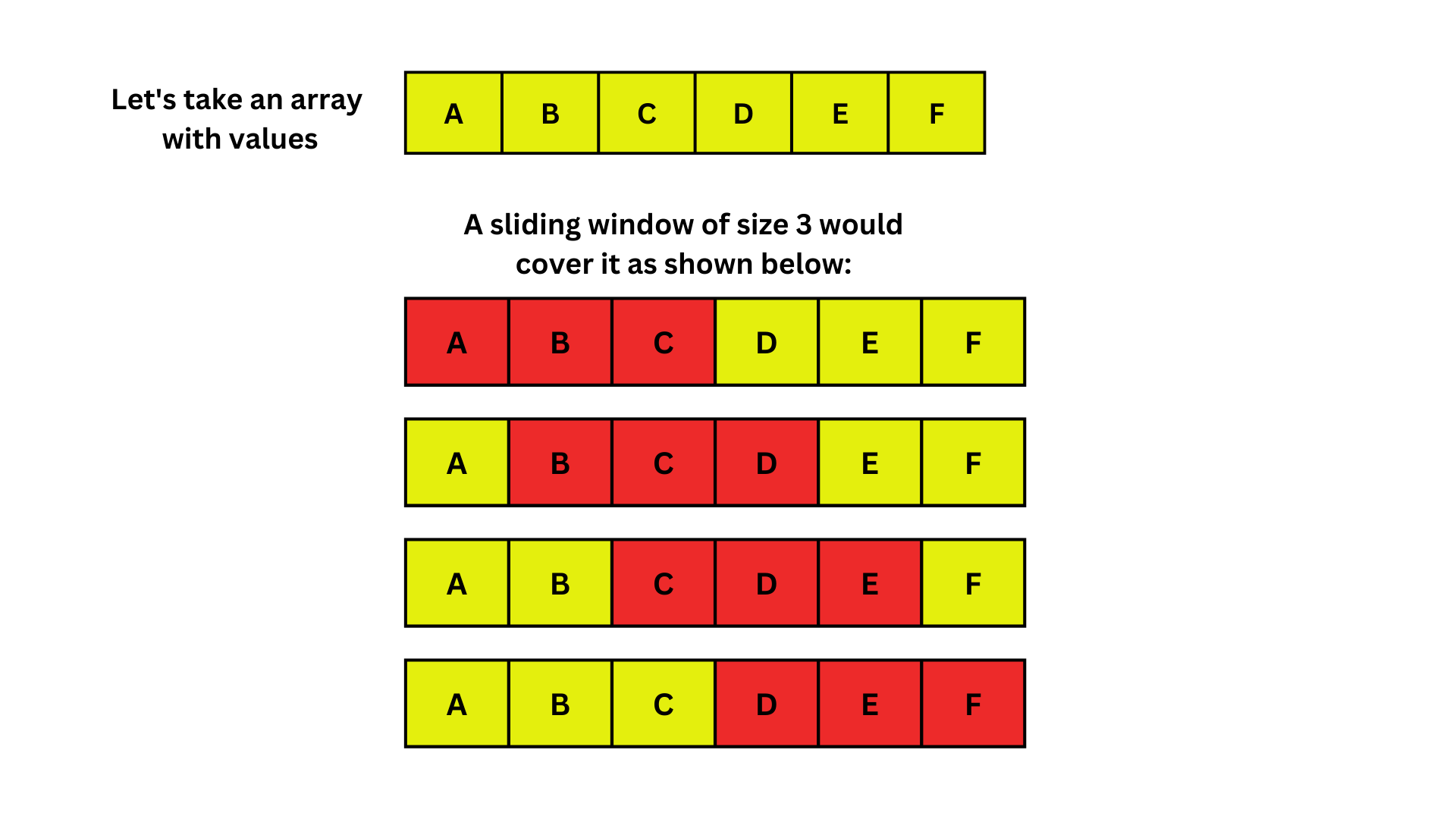
[이미지 출처 https://logicmojo.com/sliding-window-algorithm]
겹치는 경우까지 모두 세고 싶다면, 문자열을 한 칸씩 이동하면서 직접 비교해야 한다.
기본 구현
def count_overlap(s, sub):
count = 0
for i in range(len(s) - len(sub) + 1):
if s[i:i+len(sub)] == sub:
count += 1
return count사용 예시
count_overlap("banana", "ana") # 2
count_overlap("aaaa", "aa") # 3한 줄로 표현하기
리스트 컴프리헨션을 사용하면 다음과 같이 간단하게 표현할 수 있다.
def count_overlap(s, sub):
return sum(1 for i in range(len(s) - len(sub) + 1)
if s[i:i+len(sub)] == sub)정리
- count()는 겹치지 않는 경우만 센다.
- 겹치는 부분 문자열까지 포함하려면 직접 탐색해야 한다.
- 문자열 문제에서 자주 나오는 함정이므로 반드시 이해하고 넘어가는 것이 중요하다.
