
Server API에 요청이 들어오게되면 그 요청을 처리하는 여러가지 방식들이 있는데 그 방식 중 하나가 Thread per request model이 있다.
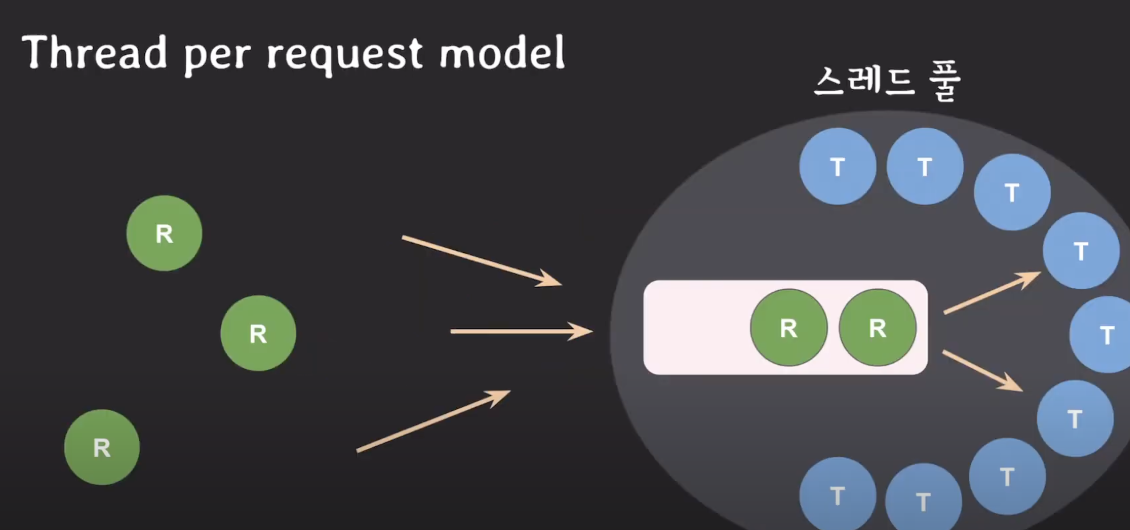
Thread per request model
Request마다 하나의 thread를 할당해서 하나의 request는 하나의 thread가 처리할 수 있도록 하는 것.
즉 request와 thread가 1:1 매핑이 된다.

만약 thread per request 모델의 동작 방식이 서버에 들어오는 요청마다 thread를 새로 만들어서 처리하고 처리가 끝난 thread는 버리는 식으로 동작한다면 어떤 문제점이 있을까?
우선 thread 생성에 소요되는 시간 때문에 요청 처리가 더 오래 걸릴 것이다.
물론 1초, 2초 만큼 긴 시간이 소요되는 것은 아니지만 kernel에서 개입이 되어 kernel level에서 생성되는 것이 thread이기 때문에 일반적으로 단순히 CPU에서 연산작업 하는 것에 비해서 시간을 은근히 잡아먹는 작업이다.
처리 속도보다 더 빠르게 요청이 늘어난다 -> thread가 계속 생성 될 것이다 -> thread 수가 증가 할 것이다. -> context-switching이 더 자주 발생할 것이다. -> CPU 오버헤드 증가로 CPU time 낭비 -> -> 메모리가 점점 고갈 -> 아느 순간 서버 전체가 응답 불가능 상태에 빠질 것이다.
이를 해결하기 위해 thread pool이라는 개념이 등장한다.
Thread pool
Thread pool은 미리 제한된 개수 만큼 thread를 만들어 놓는다.
요청들은 thread pool에서 내부적으로 관리하는 queue로 들어오게 되고 일이 없는 thread에게 request가 할당 되고 thread는 request를 처리하게 된다.
처리가 끝나면 thread는 버려지는 것이 아니라 thread pool에 다시 돌아오게 된다.
즉, 미리 thread를 여러 개 만들어 놓고 재사용하며 thread 생성 시간을 절약한다.
그리고 제한된 개수의 thread를 운용하기 때문에 thread가 무제한으로 생성되는 것을 방지한다.
Thread pool은 언제 사용 해야할까?
여러 작업을 동시에 처리해야할 때 thread pool을 사용해야 한다.
Thread per request 모델에서 사용.
task를 subtask로 나뉘어서 동시에 처리할 때 사용.
순서 상관없이 동시 실행이 가능한 task 처리할 때 사용.
Thread pool 사용 팁
- thread pool에 몇 개의 thread를 만들어 두는 게 적절한가?
- CPU의 코어 개수와 task의 성향에 따라 다름.
만약 CPU-bound task라면 코어 개수 만큼 혹은 그 보다 몇 개 더 많은 정도가 좋다.
만약 I/O-bound task라면 코어 개수보다 1.5? 2배? 3배? 경험적으로 찾아야 함.
- thread pool에서 실행될 task 개수에 재한이 없다면?
- thread pool의 queue size가 제한이 있는지 꼭 확인해야 한다.
만약 요청이 너~무 많아서 할당할 thread가 없다면 queue에 계속해서 쌓이게 될 것이고 이는 메모리 고갈 문제로 이어질 수 있다.
자바의 Executors 클래스
static 메서드로 다양한 형태의 thread pool을 제공
기본 설정으로는 queue size가 20억!(사실상 제한 없음)
size 제한 없는 큐는 상황에 따라서는 메모리를 고갈시키는 잠재적인 위험 요인이 될 수 있다.
ExecutorService threadPool = Executors.newFixedThreadPool(10);
threadPool.submit(task1);
threadPool.submit(task2);spring boot는 hikari cp를 통해서 thread pool을 관리하는데 이것도 공부 해 봐야 겠다.! 바쁘다 바빠..

멋있어용