
✅ Project3
기존 프로젝트에서 작업해놓은 GCP 내 기능들을 docker기반 Airflow 서버에 올려 자동화 작업 및 앞단의 데이터 변경 과정에서의 확장성 확보를 하고자 한다.
🎈 To do list
- Airflow 서버 연결
- GCP - Airflow 연동 (test 작업 필요)
- 스키마 확장성 고려한 Dag 작성
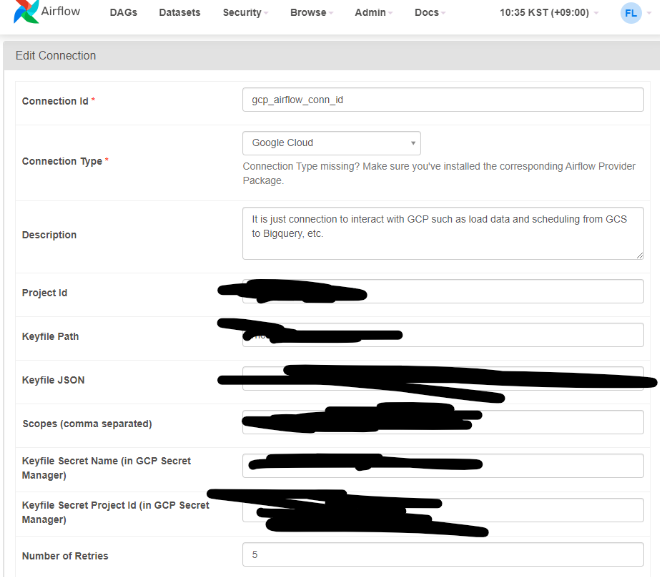
우선 GCP - Airflow간 connections 작업을 진행해준다.
다른 분이 생성해주신 Airflow 웹 서버에서 해당 작업 진행
잘 connection 됐는지 여부는 dag를 하나 올려 확인할 것.
🎈 Airflow 서버 연결
프로젝트 진행을 위해 다른 사람이 생성한 airflow 서버를 자신의 local 환경과 연결하는 방법은 다음과 같다.
음.. 우선 방법을 살펴보면 다음과 같다.
1. docker hub에서 airflow 이미지 불러오기
docker pull apache/airflow
2. airflow 컨테이너 생성docker run -d -p 8080:8080 \ -v <LOCAL_DIRECTORY>:/opt/airflow \ -e AIRFLOW__CORE__REMOTE_LOGGING=True \ -e AIRFLOW__CORE__REMOTE_BASE_LOG_FOLDER=/opt/airflow/logs \ -e AIRFLOW__CORE__REMOTE_LOG_CONN_ID=my_airflow_server \ -e AIRFLOW__CORE__REMOTE_LOGGING_END_POINT=<AIRFLOW_SERVER_URL> \ apache/airflow
- airflow 실행 확인 (docker ps)로 컨테이너 체크
아니면, GCP내 VM 인스턴스를 SSH로 연결하여 터미널을 실행할 수도 있다.
위 방법으로는 해결 X
추가로 알아본 다음 방법 사용해 연결 진행
- local에서 SSH 인증용 rsa private-public key 생성해 vm인스턴스에 올려서 진행
-> $ ssh-keygen taejun3305- $ cat ~/ .ssh/id_rsa.pub으로 나오는 키 저장해 GCP Console에 키 저장
- google api console에서 vm에서 ssh rsa public key 추가
그러나.... 마찬가지로 error 발생...
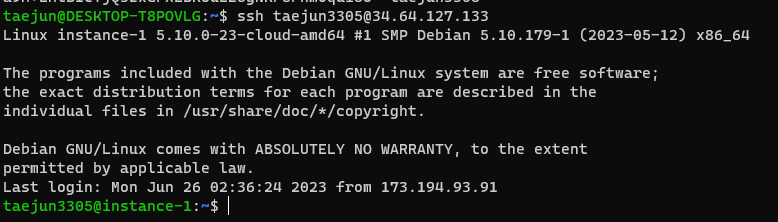
재부팅 후 키 재설정하니 airflow 서버 연동 (ssh 연결) 성공!!
🎈 Dag 작성 (GCS -> Bigquery)
dag 작성에 앞서 파이프라인을 다음과 같이 가져가려 한다.
기존 : GCS -> Bigquery (external 테이블)로 바로 적재
-> 그러나, 위 데이터 파이프라인은 확장성, 기존 데이터 변경을 전혀 고려하지 않았다.따라서 GCS -> Bigquery로 데이터를 적재하되, external 테이블이 아닌 중간 점검의 느낌으로 staging 테이블을 추가해주었다. 이렇게 함으로써 얻을 수 있는 결과는 다음과 같다.
- Dag로 task를 다음과정으로 세분화하여 데이터 정합성 확인 가능
-> staging으로 (load, check), external로 (create, check) 진행하여 클라우드 스토리지 -> 데이터 웨어하우스로의 데이터 이동과정에서 에러 사항 확인
- error 사항에 대해 전체 dag를 재실행하는 risk 감소.
-> 에러사항이 존재하는 테이블에 한해 staging에 갇히게 되므로 해당 테이블 관련 쿼리만 수정해주면 되는 효율성 존재. 전체 쿼리를 손 볼 필요 X
- alert 기능 구현하여 error 철저히 확인
-> slack alert, email alert 기능 구현하여 철저하게 체크
예시 코드는 다음과 같다.
from airflow import DAG
from airflow.contrib.operators.bigquery_operator import BigQueryOperator
from airflow.contrib.operators.gcs_to_bq import GoogleCloudStorageToBigQueryOperator
from airflow.contrib.operators.bigquery_check_operator import BigqueryCheckOperator
from airflow.operators.dummy_operator import DummyOperator
from datetime import datetime, timedelta
import pandas as pd
import logging
from plugins import slack
default_args = {
'owner': 'airflow',
'depends_on_past' : False,
'email': ['taejun3305@gmail.com'],
'email_on_failure': True,
'email_on_retry': False,
'retries': 3,
'retry_delay': timedelta(minutes=3),
'on_failure_callback':slack.on_failure_callback
}
## GCP information
project_id = "job-posting-api-388303"
staging_dataset = 'Staging'
dwh_dataset = 'external'
# bucket detail information
gs_bucket_recruit = 'hale-posting-bucket/recruit'
gs_bucket_google_trend = 'hale-posting-bucket/google_trend'
gs_bucket_certification = 'hale-posting-bucket/certification'
# define DAG
with DAG(
dag_id='GCS_to_Bigquery',
start_date=datetime(2023,5,31),
catchup=False,
default_args=default_args,
schedule='0 0 * 6,7 *'
) as dag:
start_pipeline = DummyOperator(
task_id = 'start_pipeline'
)
# Loading data from GCS to Bigquery
load_recruit = GoogleCloudStorageToBigQueryOperator(
task_id = 'load_recruit',
bucket = gs_bucket_recruit,
source_objects = ['recruit_info20*.csv'],
destination_project_dataset_table = f'{project_id}:{staging_dataset}.recruit',
schema_object = 'recruit_info20*.json',
write_disposition = 'WRITE_APPEND',
source_format = 'json',
field_delimiter = ',',
encoding = 'UTF-8',
)
load_google_trend = GoogleCloudStorageToBigQueryOperator(
task_id = 'load_google_trend',
bucket = gs_bucket_google_trend,
source_objects = ['result_20*.csv'],
destination_project_dataset_table = f'{project_id}:{staging_dataset}.google_trend',
schema_object = 'result_20*.csv'
write_disposition = 'WRITE_APPEND',
source_format = 'csv',
encoding = 'UTF-8',
)
# Check load data not null and data schema
check_recruit = BigqueryCheckOperator(
task_id = 'check_recruit',
# schema detect
use_legacy_sql = True,
# checking rows_count in staging
sql = f"SELECT COUNT(*) FROM {project_id}.{staging_dataset}.recruit"
)
check_google_trend = BigqueryCheckOperator(
task_id = 'check_google_trend',
use_legacy_sql = True,
# checking rows_count in staging
sql = f"SELECT COUNT(*) FROM {project_id}.{staging_dataset}.google_trend"
)
loaded_data_to_staging = DummyOperator(
task_id = 'loaded_data_to_staging'
)
# load dimensions data from filed directly DW table
load_certification = GoogleCloudStorageToBigQueryOperator(
task_id = 'load_certification',
bucket = gs_bucket_certification,
source_objects = ['certificate_info.csv'],
destination_project_dataset_table = f'{project_id}:{staging_dataset}.certification',
source_format = 'csv',
write_disposition = 'WRITE_TRUNCATE',
autodetect = True,
encoding = 'UTF-8',
schema_fields = [
{'name': '시험구분', 'type': 'STRING', 'mode': 'REQUIRED'},
{'name': '검정연도', 'type': 'INT', 'mode': 'REQUIRED'},
{'name': '자격등급', 'type': 'STRING', 'mode': 'REQUIRED'},
{'name': '응시자수', 'type': 'INT', 'mode': 'REQUIRED'},
{'name': '취득자수', 'type': 'INT', 'mode': 'REQUIRED'}
]
)
# create & check fact data
create_recruit = BigQueryOperator(
task_id = 'create_recruit',
use_legacy_sql = True,
params = {
'project_id': project_id,
'staging_dataset': staging_dataset,
'dwh_dataset': dwh_dataset
},
sql = 'taejun3305/instance-1/ELT_GCP/sql/Dimension_recruite.sql'
)
check_dim_recruit = BigQueryOperator(
task_id = 'check_dim_recruite',
use_legacy_sql = True,
params = {
'project_id': project_id,
'staging_dataset': staging_dataset,
'dwh_dataset': dwh_dataset
},
sql = f'SELECT COUNT(*) FROM `{project_id}.{dwh_dataset}.external_recruit.sql`'
)
create_google_trend = BigQueryOperator(
task_id = 'create_google_trend',
use_legacy_sql = True,
params = {
'project_id': project_id,
'staging_dataset': staging_dataset,
'dwh_dataset': dwh_dataset
},
sql = 'taejun3305/instance-1/ELT_GCP/sql/Dimension_google_trend.sql'
)물론 아직 완성은 아니지만, 그동안 예시로만 해왔던 dag를 직접 구현을 위해 처음 작성해보면서 code 구현을 해보는 중.
🎇 추가로 해야 할 사항들
- Dag 작성 마무리 및 테스팅 필요.
- 각 check 기준 sql 쿼리 작성 필요 (data validation)
- CI & alert Check
airflow: Airflow의 핵심 라이브러리로, 작업 스케줄링, 모니터링, 실행 등을 관리하는 기능을 제공합니다.
DAG: Airflow에서 작업 흐름을 정의하는 객체입니다. DAG(Directed Acyclic Graph)는 Airflow에서 작업들 간의 종속성과 실행 스케줄을 정의하는 데 사용됩니다.
BigQueryOperator: Airflow에서 BigQuery와 상호작용하기 위한 연산자입니다. BigQueryOperator를 사용하면 SQL 쿼리를 실행하고, 테이블을 생성하거나 삭제하는 등의 작업을 수행할 수 있습니다.
GoogleCloudStorageToBigQueryOperator: Airflow에서 Google Cloud Storage(GCS)에서 BigQuery로 데이터를 로드하기 위한 연산자입니다. GCS에 저장된 파일을 BigQuery 테이블로 로드할 수 있습니다.
BigQueryCheckOperator: Airflow에서 BigQuery 작업의 결과를 확인하기 위한 연산자입니다. 특정 쿼리의 결과를 확인하거나 특정 조건을 검사하여 작업의 성공 여부를 판단하는 데 사용됩니다.
DummyOperator: Airflow에서 아무 작업도 수행하지 않고 그저 DAG에서 단순한 흐름을 만들기 위해 사용되는 연산자입니다. 주로 DAG 내에서 테스트 또는 조건 분기를 위해 사용됩니다.
