
✅ 실시간 데이터 처리 소개
Google 검색엔진으로부터 수많은 논문을 손쉽게 검색할 수 있게 되었고 Hadoop, 텐서플로우, k8s 등등 데이터 분야에서 많은 발전이 이루어지고 있다.
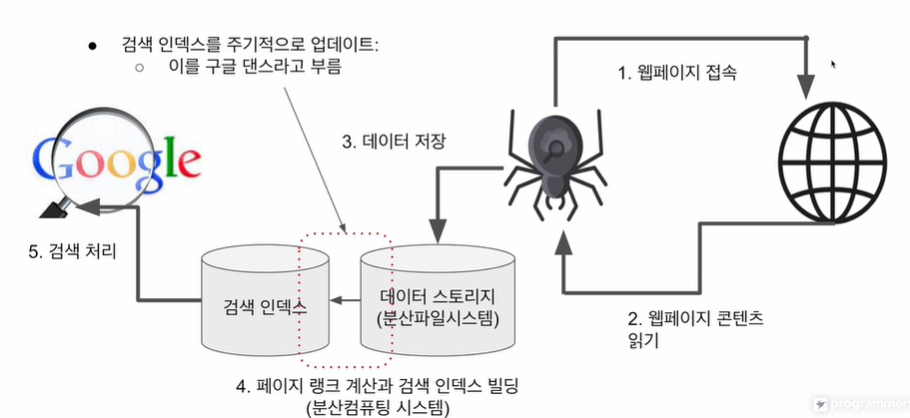
구글은 웹 페이지들간의 링크를 시반으로 중요 페이지를 찾아 검색 순위를 결정 (페이지 랭크)
- 페이지 랭크 논문 발표로 차세대 검새엔진 등장 (러시아의 얀덱스, 중국의 바이두 등)
-> 구글의 경우, 2004년 여름 상장 이후 글로벌 검색엔진이 되었음.
-> 이후 다양한 논문 발표, 오픈소스 활동으로 개발자 커뮤니티에 큰 영향🎈 PageRank
- 더 중요한 페이지는 더 많은 타 사이트로부터 링크를 받는다는 관찰에 기초된 논문.
- 현 구글 검색엔진의 기초.
- 웹 상의 모든 페이지들에 중요도 점수 부여해 계산. (계산의 경우 대용량 컴퓨팅, SW 반드시 必)
✅ 데이터 처리 발전 단계
빅데이터 처리 과정에서 trade-off가 존재하는데 이는 다음과 같다.
Throughput (처리량) VS Latency (지연시간)
- Throughput : 주어진 단위 시간 동안 처리할 수 있는 데이터 양 (DW - OLAP)
- Latency : 데이터를 처리하는데 걸리는 시간 (production DB - OLTP)
- Bandwidth (대역폭) : 처리량 X 지연시간
🎈 SLA (Service Level Agreement)
서비스 제공업체와 고객 간의 계약 또는 합의를 의미하며 통신, 클라우드 컴퓨팅 등 다양한 산업에서 사용된다.
사내 시스템들 간 Latency, Uptime 등을 SLA를 정의하여 현업에서 사용중✍️ Batch 처리
- 주기적으로 데이터 단위를 다른 곳으로 이동하거나 처리하는 것을 의미 (Throughput이 중요!)
-> 얼마나 큰 데이터를 처리할 수 있는가? / 주로 분, 시간, 일 단위- 처리 시스템 구조
○ 분산 파일 시스템(HDFS, S3)
○ 분산 처리 시스템(MapReduce, Hive/Presto, Spark DataFrame, Spark SQL)
○ 처리 작업 스케줄링에 보통 Airflow 사용✍️ 실시간 처리
- 연속적인 데이터 처리 (Latency가 중요!)
- Batch 처리의 고도화 단계. 초 단위의 연속적인 실시간 데이터 처리
- 처리 시스템 구조
○ 이벤트 데이터를 저장하기 위한 메세지 큐들: Kafka, Kinesis, Pub/Sub, …
○ 이벤트 처리를 위한 처리 시스템: Spark Streaming, Samza, Flink, …
○ 이런 형태의 데이터 분석을 위한 애널리틱스/대시보드: Druidstream 데이터 처리 순서는 다음과 같다.
1. Producer(publisher)가 있어 데이터 생성 (일정 주기, 속도로)
2. 생성된 데이터를 메세지 큐와 같은 시스템 (kafka, kinesis, pubsub)에 저장 (data stream마다 별도의 데이터 보유 기한 설정 - kafka : 토픽, 기본 일주일)
3. consumer가 있어 큐로부터 데이터를 읽어서 처리 (적시에 처리되어야 함)
-> backpressure (배압) 이슈 발생 가능. (들어오는 데이터 속도를 따라 잡지 못하는 문제)
-> 이를 해결하고자 중간 단계에 메세지 큐 도입 (작은 메모리 버퍼 추가 -> overflow문제 발생)
-> 궁극적으로 backpressure는 계속 발생. 이를 매번 해결해주는 것이 핵심
ex) 검색엔진에서의 데이터 처리
실시간으로 변동하는 페이지 랭크 계산 처리를 위해 람다 아키텍처를 활용
-> 배치 레이어, 실시간 레이어 2개를 별도로 운영✨ use case
- Real-time Reporting (A/B Test, Marketing, Monitoring)
- Real-time Alerting (Bidding, Fraud Detection)
- Real-time Prediction (Personalized Recommendation)

✅ 실시간 데이터 처리 시 challenge 사항
크게 4가지 단계로 나뉜다.
1. event data model decision
-> 실시간 데이터에서 반드시 포함되어야 하는 중요한 데이터로 timestamp와 PK가 핵심
-> 추가로 사용자 정보, 이벤트 자체에 대한 세부 정보가 필요할 수 있음.
- event data transfer & save
-> point to point / many to many 연결이 필요 - Latency가 중요한 시스템에서 사용하며 많은 API 레이어들의 동작 방식, 다수의 consumer 있는 경우 데이터 중복해서 전송
-> 데이터 저장에 있어 메세지 큐(FIFO)와 같은 시스템 필요
- event data process (처리 방식은 2개 PTP VS Queue)
-> point to point의 경우 consumer 부담이 커짐. (데이터 유실 문제 발생하므로 backpressure 해결 필요)
-> queue의 경우 micro-batch 형태로 데이터 처리 (spark streaming)
- event data management issue monitoring & resolvement
