
✅ RDB
관계형 데이터베이스 학습 내용
- 구조화된 데이터를 저장하고 질의할 수 있도록 해주는 Storage
- 엑셀 스프레드시트 형태의 테이블로 데이터를 정의, 저장 (컬럼, 레코드 형태)
- RDB를 조작하는 프로그래밍 언어가 SQL
- 테이블 정의 (DDL) , 테이블 데이터 조작, 질의 (DML)
🎈 대표적인 RDB
1. production DB : MySQL, PostgreSQL, Oracle
- OLTP (Online Transaction Processing)
- (빠른 속도에 집중, 서비스에 필요한 정보 저장)
- Data Warehouse : Redshift, Snowflake, BigQuery, Hive
- OLAP (Online Analytical Processing) : 처리 데이터 크기에 집중, 데이터 분석
- 처리 데이터 크기에 집중, 데이터 분석 or 모델 빌딩 등을 위해 데이터 저장
- 보통 production DB 복사해 Data Warehouse에 저장
✨ RDB 구조
- 가장 밑단에는 테이블들이 존재 (각 테이블은 레코드로 구성되고, 각 레코드는 하나 이상의 필드로 구성)
- 각 필드는 이름, 타입, 속성(PK)로 구성
- 각 테이블들은 DB (Schema)라는 폴더 밑으로 구성
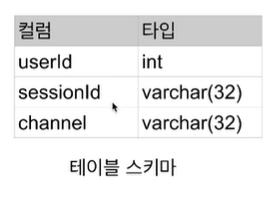
- EX) Schema
빅데이터를 다루기 위해선 SQL은 필수.
그러나 다음과 같은 단점이 존재
💯 구조화된 데이터를 다루는데 최적화
- 정규표현식을 통해 비구조화된 데이터를 어느 정도 다룰 수는 있으나 제약이 심함
- 많은 RDB들이 플랫한 구조만 지원 (no nested like JSON) (BigQuery는 nested structure - 필드내 필드 존재 지원)
- 비구조화된 데이터 다룰 시 Spark, Hadoop 같은 분산 컴퓨팅 환경이 필요 (SQL만으로 처리 X)
- RDB마다 SQL 문법이 상이
🧨 Star Schema
- production DB 용 RDB에서는 보통 스타 스키마 사용해 데이터 저장
- 데이터를 논리적 단위로 나누어 저장, 필요 시 JOIN 처리, Storage 낭비 덜하고 Update 용이
🧨 Denormalized Schema- DW에서 사용하는 방식으로, 단위 테이블로 나누어 저장하지 않기에 별도의 조인이 필요 없음
- Storage 더 사용하지만, JOIN이 없어 계산 속도 빠름
✅ Data Warehouse - OLAP
회사에 필요한 모든 데이터를 저장하는 SQL 기반 RDB
- production DB(OLTP)와는 별도로 존재해야 함, OLAP(데이터크기) VS OLTP(속도)
ex) AWS-Redshift(고정비용), Google Cloud - BigQuery, Snowflake(가변비용)- DW는 고객이 아닌 직원을 위한 DB로, 처리 데이터 크기가 더 중요해짐 (OLAP)
- ETL or Data Pipeline 외부에 존재하는 data를 읽어다가 DW로 저장해주는 자동화 작업
-> ETL을 통해 DW에 적재하는 과정을 데이터 인프라라고 부르며 Spark와 같은 대용량 분산처리 시스템이 일부 추가되며 발전 중에 있다.
✅ Cloud
컴퓨팅자원 (HW, SW)을 네트웍을 통해 서비스 형태로 사용하는 것
- "No Provisioning" "Pay As You Go"
- 자원(ex 서버)을 필요한만큼 실시간으로 할당해 사용한만큼 지불 (탄력적임)
💯 cloud-computing 장점- 초기 투자 비용이 크게 줄어듬 (CAPEX VS OPEX)
- 리소스 준비를 위한 대기시간 대폭 감소 (Shorter Time to Market)
- 노는 리소스 제거로 비용 감소
- 글로벌 확장 용이 및 SW 개발 시간 단축 (SaaS) 이용
✅ AWS
EC2
- AWS의 서버 호스팅 서비스 (가상서버이기에 성능이 전용서버에 비해 떨어짐)
- 다양한 종류의 서버 타입 제공
S3- 아마존이 제공하는 대용량 cloud storage service
- 데이터 저장관리를 위해 계층적 구조 제공
- global namespace 제공하기에 top-level directory(bucket) name 선정에 주의
- 버킷, 파일 별로 access control 가능
✅ Redshift (DW, SQL 기반)
- still OLAP. (응답속도 빠르지 않아 production DB로 사용 불가)
- 2Peta Byte까지 지원
- Columnar storage (컬럼 별 압축 가능, 추가 및 삭제 빠름)
- 벌크 업데이트 지원 (레코드가 들어있는 파일 -> S3 복사 후 COPY 커맨드 사용해 Redshift로 일괄 복사)
- 고정 용량/비용 SQL 엔진
- 타 DW(Snowflake, BigQuery)처럼 PK uniqueness 보장 X, production DB는 PK 보장
-> 개발자가 따로 본인이 지정하여 PK보장이 필수- Postgresql 8.x의 일부 기능과 SQL 호환 (SQL이 메인 언어이므로 테이블 디자인이 상당히 중요)
💯 TABLE 관리
Admin 계정으로 3개의 schema 생성하여
1차로 raw_data 수집, 2차로 denormalized 등 raw_data를 가공해 analytic 테이블 구성. 이후 테스팅 전용으로 데이터를 가공할 수 있도록 adhoc 등의 테이블 생성

To be a DataScientist