금일 학습할 내용은 Web Scraping!
그 중 웹의 기초인 HTTP를 정리하고자 한다.
컴퓨터의 탄생 이후 컴퓨터로 기존 업무가 편리해지고 개인화 PC도 탄생하며 PC 간 통신 연결이 이루어진 네트워크가 구축되었고, 여러 네트워크가 묶여 LAN, WAN, Internet이 탄생하게 되었다.
이때 WEB이란 인터넷에서 정보를 교환할 수 있는 하나의 플랫폼.
+) 정보(데이터)를 요청하는 컴퓨터를 클라이언트, 정보를 제공하는 컴퓨터를 서버라고 한다.
아래 링크 참고!!
클라이언트 & 서버 정리
✅ HTTP (Hypertext Transfer Protocol)
-> 웹 상에서 정보를 주고받기 위한 약속 (통신 규율로 생각)
✔️ 클라이언트 -> 서버 : 정보 요청 (HTTP Request)
- Get / HTTP 1.1 (최상단의 정보를 요청)
- Host : 사이트 명
- User - Agent : 사용자를 명시
✔️ 서버 -> 클라이언트 : 정보 응답 (HTTP Response)
- HTTP/1.1 200 OK (Request 잘 전달 됌, 숫자는 Status 코드를 의미)
- html 태그 (body)가 전달됌
- 반드시 요청이 있어야 응답이 존재!
HTTP에는 Host , Resource, Method 등의 정보가 담기고, 요청이든 응답이든 크게 Head와 Body로 구성된다.
✅ Web Page & HTML
웹 페이지 : 웹 속의 문서 하나를 의미 (html 형식)
웹 사이트 : 여러 웹 페이지들의 모음
웹 브라우저 : 사용자가가 HTTP 요청을 보내고, 응답받은 HTML 코드를 렌더링해 준 결과❗ 웹 브라우저의 역할 ?
웹 브라우저는 html request를 보내고 HTTP response 응답에 담긴 html 문서를 우리가 보기 쉬운 형태로 화면을 그려주는 역할을 담당< Python을 이용해 HTTP 통신하는 방법 구현 >
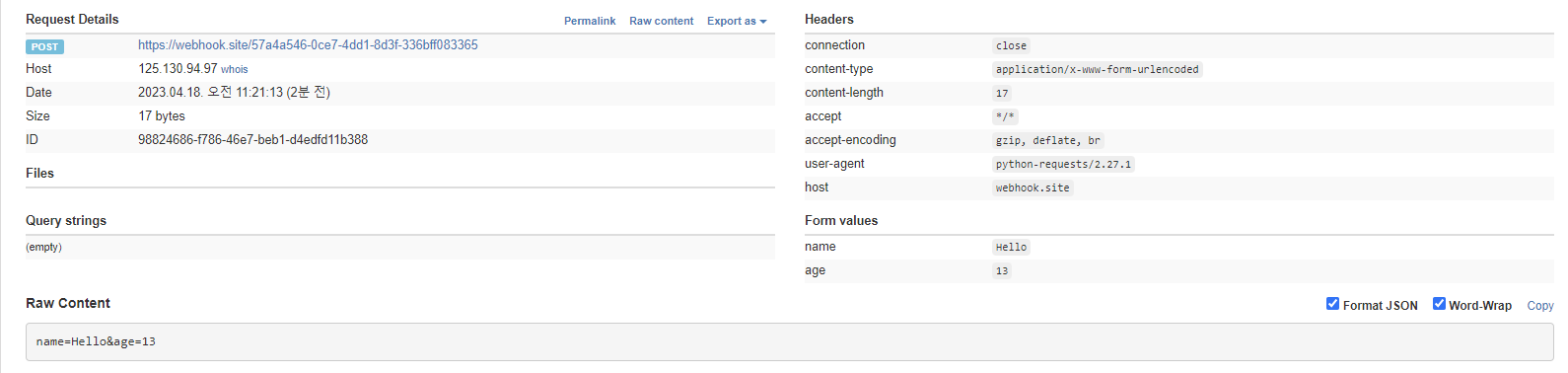
# requests 라이브러리를 불러온 후 Naver의 홈 페이지 요청한 후 응답 받아보기 # 결과로 요청 응답 출력 됌 (200은 success) import requests # HTTP 응답이 담김 res = requests.get("https://www.naver.com") # Header 확인 .headers # attribute를 의미 res.headers # 결과 다음과 같이 나옴 #{'Server': 'NWS', 'Date': 'Tue, 18 Apr 2023 02:09:47 GMT', 'Content-Type': 'text/html; charset=UTF-8', 'Transfer-Encoding': 'chunked', 'Connection': 'keep-alive', 'Set-Cookie': 'PM_CK_loc=65c7698fb8f8f2f2fb913fdf21d3db41f0c9fee8a7617928b40bc8e9ce613952; Expires=Wed, 19 Apr 2023 02:09:47 GMT; Path=/; HttpOnly', 'Cache-Control': 'no-cache, no-store, must-revalidate', 'Pragma': 'no-cache', 'P3P': 'CP="CAO DSP CURa ADMa TAIa PSAa OUR LAW STP PHY ONL UNI PUR FIN COM NAV INT DEM STA PRE"', 'X-Frame-Options': 'DENY', 'X-XSS-Protection': '1; mode=block', 'Content-Encoding': 'gzip', 'Strict-Transport-Security': 'max-age=63072000; includeSubdomains', 'Referrer-Policy': 'unsafe-url'} # Body를 텍스트 형태로 확인 .text : 모든 텍스트를 가져옴 # -> 문제 발생 가능 (일부만 원하는 개발자 입장에서 ) res.text[:1500] # 결과 다음과 같이 나옴 # '\n<!doctype html> <html lang="ko" data-dark="false"> <head> <meta charset="utf-8"> <title>NAVER</title> <meta http-equiv="X-UA-Compatible" content="IE=edge"> <meta name="viewport" content="width=1190"> <meta name="apple-mobile-web-app-title" content="NAVER"/> <meta name="robots" content="index,nofollow"/> <meta name="description" # payload와 함께 post를 보내는 방법 payload = {'name' : 'Hello', 'age' : 13} # 개인마다 unique 한 url resu = requests.post("https://webhook.site/57a4a546-0ce7-4dd1-8d3f-336bff083365", payload) # 응답 상태 확인 200인 경우 요청, 응답 성공 # status code 확인 : .status_code resu.status_code
위와 같이 Form values를 통해 요청한 것에 대해 응답이 잘 이루어졌나 확인 가능!!
✅ Web Crawling
- web page로부터 원하는 정보를 추출하는 것이 목적
- 크롤러를 통해 web page의 정보를 인덱싱
❗ web scraping vs web crawling 차이
- web scraping : 특정 목적으로 특정 웹페이지에서 데이터를 추출
ex) 날짜 데이터 가져오기, 특정 데이터 추출- web crawling : URL을 타고다니며 반복적으로 데이터를 가져오는 것 데이터 색인
ex) 검색 엔진의 web crawler-> 데이터를 가져오는 데 있어 윤리적인 문제가 존재해 분명한 목적이 있어야 하고 서버의 영향이 없어야 한다.
- REP : 로봇 배제 프로토콜
- robots.txt: 웹 사이트, 웹 페이지를 무단으로 수집하는 로봇들의 무단접근 방지를 위해 만들어진 R.E.S이자 국제 권고안
< 크롤링 시 지키는 Rule로 robots.txt 예시 >
# 모든 user-agent에 대해 접근 거부 User-agent: * Disallow: / # 모든 user-agent에 대해 접근 허가 User-agent: * Allow: / # 특정 user-agent에 대해 접근 불허, allow인 경우 허가 User-agent: MussBot Disallow: / # exercise res = requests.get('https://www.programmers.co.kr/robots.txt') print(res.text) # 결과 출력 User-Agent: * Disallow: /users Disallow: /managers Disallow: /cable Disallow: /admin Disallow: /start_trial Disallow: /pr/* Allow: / Sitemap: https://programmers.co.kr/sitemap.xml
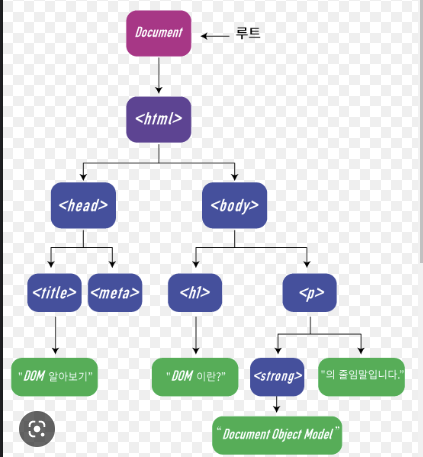
✅ DOM (Document Object Model)
처음 들어보는 생소한 용어..
간략하게 얘기하면, 아래과정을 DOM이라고 한다.
- 브라우저가 문서를 예쁘게 꾸미는 방법 ? : 브라우저의 렌더링 엔진은 웹문서를 로드 후 파싱 진행
- HTML 내 (head 태그, body 태그)를 의미 (실제로는 복잡함)
- 복잡한 구조(여러 노드)를 개별로 객체로 생각하여 문서를 더욱 편리하게 관리 가능
- 브라우저 입장에서는 DOM Tree를 순회하여 특정 원소를 추가, 찾기, 삭제 등 동적 변경 가능
# DOM Tree 순회해 특정원소 추가 var imgElement = documnet.createElement('img'); document.body.appendChild(imgElement); # DOM Tree 순회해 특정원소 찾기 documnet.getElementsByTagName('h2')🎇 정리
브라우저는 html을 파싱한 후 DOM으로 바꾸어 다룸
- 원하는 요소를 동적으로 변경할 수 있다. (추가, 삭제 등등)
- 원하는 요소를 쉽게 찾을 수 있다. (Scraping, Crawling에 유용)
-> 결론적으로 파이썬으로 요청, 응답에 끝나지 않고 특정 원소가 어디에 있는지 알기 위해 html parser가 필요