
✅ Bigquery Guide
데브코스 2번째 프로젝트를 진행하면서 사용하게 될 GCP중 하나인 Bigquery에 대해 정리해보고자 한다.
Bigquery는 query engine이 내장된 serverless service로 확장성이 높은 DW다.
- 내장된 query engine은 수 테라바이트의 데이터에 대한 SQL 쿼리를 빠른 시간내에 처리할 뿐만 아니라, OLAP기반 데이터 처리에 적용 시 이점이 있다.
- 두 단계 : 키/값 쌍을 처리해 중간 키/값 쌍을 생성하는 map함수, 동일한 키와 연관된 모든 중간 값을 병합하는 reduce함수다.
- MapReduce라고 알려진 위 단계의 패러다임은 엄청난 영향을 이끌었고, Apache Hadoop의 발전을 이끌었다.
- 단점이라고 하면 HDFS에 데이터를 저장하기 위해선 충분한 크기의 클러스터가 필요하고, MapReduce architecture에서 일반적으로 컴퓨팅 노드가 로컬에 있는 데이터에 접근해야 하는 부분을 간과하게 되는데 HDFS는 반드시 클러스터의 컴퓨팅 노드에 샤딩되어야 한다.
또한, 데이터 크기가 커짐에 따라 당연히 분석 요구사항도 독립적으로 증가하므로 클러스터가 부족하거나 과도한 프로비저닝이 발생할 수 있다.✨ 샤딩 : DB 저장기법 중 하나로 전체 네트워크를 분할한 뒤 트랜잭션을 영역별로 저장하고 이를 병렬처리하여 블록체인에 확장성을 부여하는 On-chain 솔루션으로 데이터를 샤드 단위로 나누어 저장 및 처리한다.
✨ 프로비저닝 : user 요구에 맞게 시스템 자원을 할당, 배치, 배포해 둔 후 필요 시 시스템을 즉시 사용가능한 상태로 미리 준비해 두는 것을 의미
이외에도 아래와 같은 기능 수행이 가능하다.
- 빅쿼리는 다양한 BI Tool과 연동해 사용도 가능
- ML 모델 생성, Batch 단위 데이터 예측도 수행 가능
- 다양한 유형의 데이터(지리 공간, 계층 데이터 등) 저장 가능
- Batch 데이터, 스트리밍 데이터 수집 모두 지원, REST API를 통해 빅쿼리로 직접 데이터 스트리밍 가능
- InfraStructure 직접 구축안해도 되고, 빅쿼리의 데이터는 저장, 전송 시 자동 암호화되므로 보안을 신경써야 하는 번거로움이 없다.
+) 빅쿼리의 경우 파티셔닝을 지원한다는 점에서 AWS Redshift에 비해 장점이 존재한다.
🎈 Bigquery로 작업하기
- 빅쿼리에 데이터셋을 저장하고 IAM을 통해 데이터를 쉽게 공유할 수 있다.
- 빅쿼리에선 컴퓨팅과 스토리지가 분리되어 있어 GCS에 현재 저장된 파일에 빅쿼리 SQL 쿼리를 실행할 수 있고, 이 기능을 통합쿼리(federated query)라고 한다. 통합 쿼리를 사용해 해당 데이터를 변환한 다음 그 결과를 빅쿼리 테이블로 저장까지 할 수 있다.
- ETL, EL 워크플로우 외에도 빅쿼리는 ELT 워크플로우도 수행이 가능하다.
- ELT 워크플로우 : rawdata를 DW에서 추출해 로드한 후 빅쿼리 뷰로 해당 데이터 즉시 변환
✅ SQL 쿼리 요소
SQL문에서 일반적인 문법인 CREATE, READ**, UPDATE, DELETE 등이 있지만, 빅쿼리는 쿼리에서 읽는 컬럼 수에 비례해 요금이 청구되는 ondemand 형식이다.
🎈 SELECT 문 특수 구조
# 특정 컬럼 제외하고 조회
SELECT * EXCEPT(short_name, last_reported)
FROM `bigquery-public-data`.new_york_citibike.citibike_stations
WHERE name LIKE '%Riverside%'
# 특정 컬럼 변환해 모든 컬럼 조회
SELECT * REPLACE(num_bikes_available + 5 AS num_bikes_available)
FROM `bigquery-public-data`.new_york_citibike.citibike_stations
# 서브쿼리 활용 가독성 높이기
WITH all_trips AS (
SELECT gender, tripduration / 60 AS minutes
FROM `bigquery-public-data`.new_york_citibike.citibike_trips
)
SELECT * FROM all_trips
WHERE minutes < 10
LIMIT 5;
# split 함수 적용
SELECT city, SPLIT(city, ' ') AS parts
FROM (SELECT * FROM UNNEST([
'Seattle WA', 'New York', 'Singapore'
)] AS city
)
# 결과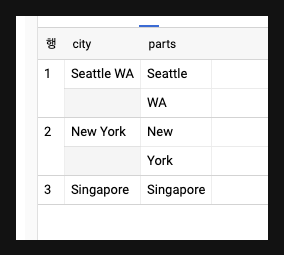
🎈 데이터 타입 관련 함수
# 분모가 0일 가능성있을 때 사용, 분모가 0이고 나누기를 진행하는 경우 NaN 반환 SELECT *, ROUND(IEEE_DIVIDE(oneways, numrides), 2) AS frac_oneway FROM example # SAFE 함수 (수학, 문자열, 시간 함수 등 스칼라 함수에만 사용 가능, 집계, 분석, 사용자 정의 함수에는 사용 X) SELECT SAFE.LOG(10, -3), LOG(10, 3) # Boolean 형 - COALESCE (NULL이 아닌 값 얻을 때 까지 평가 가능) COALESCE(A, B, C, NULL) # CAST함수로 타입 변환 시 오류 대신 NULL 반환 : SAFE_CAST SELECT CAST("true" AS bool), SAFE_CAST("invalid" AS bool) # 문자열 관련 함수 # 1. STRPOS : 문자열 위치 찾아 숫자로 반환 (인덱스가 1부터 시작) # 2. SUBSTR : 부분 문자열 추출 # 3. CONCAT : 입력값 연결 SELECT LPAD('Hello', 10, '*') -- 왼쪽에 지정한 길이만큼 *가 추가된다 , RPAD('Hello', 10, '*') -- 오른쪽에 지정한 길이만큼 *가 추가된다 , LPAD('Hello', 10) -- 왼쪽에 공백이 추가된다 , LTRIM(' Hello ') -- 왼쪽의 공백이 제거된다 , RTRIM(' Hello ') -- 오른쪽의 공백이 제거된다 , TRIM (' Hello ') -- 양쪽의 공백이 제거된다 , TRIM ('***Hello***', '*') -- 양쪽의 *이 제거된다 , REVERSE('Hello') -- 문자열이 뒤바뀐다 # 시간을 나타내는 함수 # 1. DATE : 어떤 일이 발생한 날만 추적, 정밀도 높지 않은 경우 유용 # 2. TIME : 어떤 일이 발생한 시각만 나타내며 수학적 연산에 유용 # 3. DATETIME : 특정 시간대 기준으로 rendering한 TIMESTAMP
✅ Bigquery에 데이터 로딩
프로그래밍 방식을 활용하여 개발이 가능한데, 지난번 학습한 REST API를 활용해 학습을 진행하려 한다.
- Google Cloud Client Library
# 접근 토근을 우선적으로 생성해야한다. json 형태의 파일이며 터미널에서 실행하고 노트북 접근하면 된다.
export GOOGLE_APPLICATION_CREDENTIALS="key 경로"
# 빅쿼리 클라이언트 라이브러리를 설치하는 명령
pip install google-cloud-bigquery
# 라이브러리를 사용하려면 먼저 클라이언트 인스턴스를 생성해야 한다.
from google.cloud import bigquery
bq = bigquery.Client(project=PROJECT)
# project=PROJECT(아래 동일)를 입력하지 않아도 작동한다.
# 클라이언트에 전달하는 프로젝트는 전역적으로 유일한 프로젝트이며,
# bq 객체를 이용해 수행하는 모든 작업에 대한 비용이 청구된다.
# 데이터 정보
dsinfo = bq.get_dataset('bigquery-public-data.london_bicycles')
# 프로젝트 이름을 명시하지 않으면 클라이언트의 인스턴스가 생성될 때 참조했던 프로젝트가 전달된다.
# 프로젝트 이름 없이 데이터셋 정보를 가져오는 파이썬 코드
dsinfo = bq.get_dataset('ch04')
# dsinfo 객체를 얻으면 데이터셋의 여러가지 정보를 얻을 수 있다.
# 데이터셋을 생성하는 코드
dataset_id = "{}.ch05".format(PROJECT)
ds = bq.create_dataset(dataset_id, exists_ok=True)
# 데이터셋을 삭제하는 코드
bq.delete_dataset('ch05', not_found_ok=True)
# 테이블 목록을 출력하는 코드
tables = bq.list_tables('bigquery-public-data.london_bicycles')
for table in tables:
print(table.table_id)
# 테이블을 삭제하는 코드
bq.delete_table('ch05.temp_table', not_found_ok=True)
# 빈 테이블을 생성하는 코드
table_id ='{}.ch05.temp_table'.format(PROJECT)
table = bq.create_table(table_id, exists_ok=True)
# 테이블 스키마를 갱신하는 코드
schema = [
bigquery.SchemaField("chapter", "INTEGER", mode="REQUIRED"),
bigquery.SchemaField("title", "STRING", mode="REQUIRED"),
]
table_id = '{}.ch05.temp_table'.format(PROJECT)
table = bq.get_table(table_id)
print(table.etag)
table.schema = schema
table = bq.update_table(table, ["schema"])
print(table.schema)
print(table.etag)
# 테이블에 새 행을 추가하는 코드
rows = [
(1, u'What is BigQuery?'),
(2, u'Query essentials'),
]
errors = bq.insert_rows(table, rows)여기에 빅쿼리 내 파이썬 클라이언트를 사용해 Pandas or DataFrame으로부터 로드도 가능하다.
import pandas as pd
data =[
(1, u'What is Bigquery?'),
(2, u'Query essentials'),
]
df = pd.DataFrame(data, columns=['chapter', 'title'])
# 데이터를 판다스 데이터프레임으로 로드하는 코드
table_id = 'ch05.temp_table3'
job = bq.load_table_from_dataframe(df, table_id)
job.result() # blocks and waits
print("Loaded {} rows into {}".format(job.output_rows, table_id))
# > Loaded 2 rows into ch05.temp_table3
# url로부터 로드하는 방법
job_config = bigquery.LoadJobConfig()
job_config.autodetect = True
job_config.source_format = bigquery.SourceFormat.CSV
job_config.null_marker = 'NULL'
uri = "gs://bigquery-oreilly-book/college_scorecard.csv"
table_id = 'ch05.college_scorecard_gcs'
job = bq.load_table_from_uri(uri, table_id, job_config=job_config)
# 데이터 로드 결과를 0.1초마다 확인하는 코드
while not job.done():
print('.', end='', flush=True)
time.sleep(0.1)
print('Done')
table = bq.get_table(tblref)
print("Loaded {} rows into {}.".format(table.num_rows, table.table_id))🎇 정리
이외에도 여러 쿼리를 활용하여 빅쿼리(DW)에 저장된 데이터를 처리하는 ELT 과정을 실행할 수 있다.
그러나 중요한 것은 쿼리 역시 코드이므로 가독성을 높여 타인과의 협업을 할 줄 알아야 한다.
오늘 학습을 진행하며 찾아본 SQL Style Guide들은 다음과 같다.위 가이드들을 보면, 그동안 내가 사용했던 쿼리들이 정말 가독성이 없다는 생각이 들었다.
그동안 사실 sql 코딩테스트 문제만을 풀어왔기에 습관을 잘못들인 것 같은데, 이제부터라도 해당 사항들을 참고해 가독성을 높여봐야 겠다는 생각이 들었다.+) Bigquery Guide
