
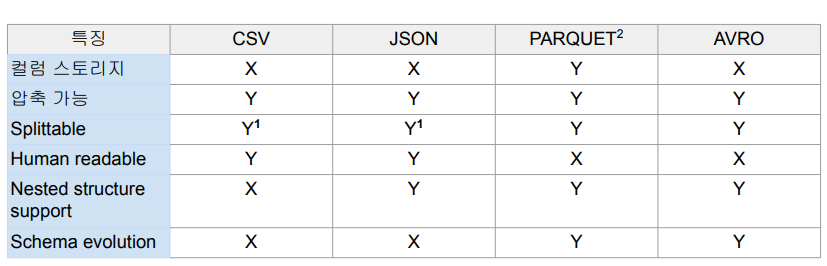
✅ spark file format
spark에서 데이터는 디스크에 파일로 저장되며 구조는 다음과 같다.
- Unstructured : Text
- Semi-structured : JSON, XML, CSV
- Structured : PARQUET, AVRO, ORC, SequenceFile
주요 파일들의 타입은 다음과 같다.
- PARQUET : spark의 기본 파일 포맷으로 하나의 데이터 블록은 하나의 row group으로 구성된다.
session 생성 시 .config("spark.jars.packages", "org.apahce.spark:spark-avro_2.12:3.3.1") 추가해 사용할 파일 불러와야 함.
이후 write \ .format("avro or parquet or json" \ .mode("overwrite") \ .option 등으로 파일 save() 해주기.
✅ Execution plan
spark은 결국 개발자가 만든 코드를 변환하여 실행된다.
각 task 별로 변환의 경우 다음과정을 거친다.
- narrow dependencies : 독립적인 partition level 작업 (select, filter, map 등)
- wide dependencies : shuffling 필요한 작업 (groupby, reduceby, partition by, repartition 등)
실행의 경우는 다음과 같다.
- actions : read, write, show, collect -> Job(하나의 job은 하나 이상의 transformation으로 구성되고, 하나 이상의 operator로 구성) 실행 (코드 실행)
-> lazy execution : 더 많은 operation을 볼 수 있기에 최적화 더 잘 가능. (SQL 선호 이유)즉 Action -> Job -> 1 + stages -> 1 + tasks
- Action : Job을 하나 만들고 코드가 실제로 실행
- Job : 하나 이상의 stage로 구성되며 stage는 shuffling 발생하는 경우 새로 생김
- stage : dag 형태로 구성된 task들이 존재하며 파티션 수 만큼 병렬 실행도 가능!
- task : 가장 작은 실행 유닛으로 executor에 의해 실행
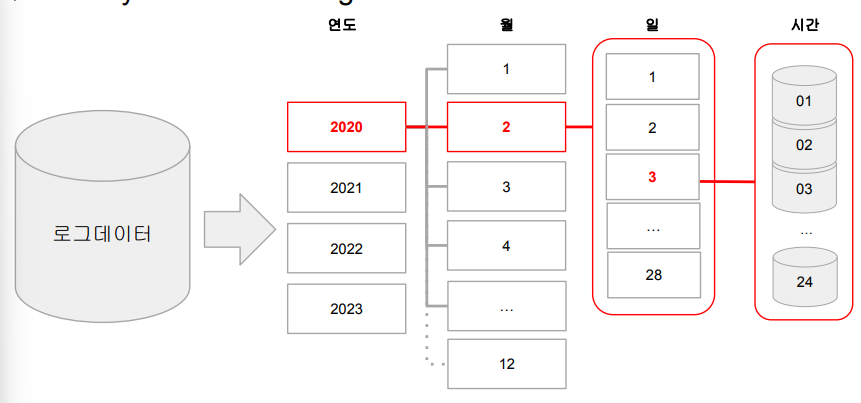
✅ Bucketing & File System Partitioning
- 둘다 Hive metastore 사용이 필요 : saveAsTable
- 데이터 저장을 이후 반복처리에 최적화된 방법으로 하는 것
- Bucketing : DF를 특정 ID를 기준으로 나누어 테이블로 저장하는 방식으로 과정은 다음과 같다.
-> 먼저 agg, window, join에서 많이 사용되는 키가 있는지 확인하고, 있다면 데이터를 해당 컬럼 기준으로 테이블로 저장.- FSP : 원래 Hive에서 많이 사용하며 데이터의 특정 컬럼을 기준으로 폴더 구조를 만들어 데이터 저장을 최적화! ex) 데이터를 연도, 월, 일 기준으로 폴더 구조로 저장!

To be a DataScientist