
이전에 친구들과 진행한 DB 스터디를 통해 아래 해당 JOIN 부분을 학습했지만 복습하는 느낌으로 다시 정리!
✅ JOIN
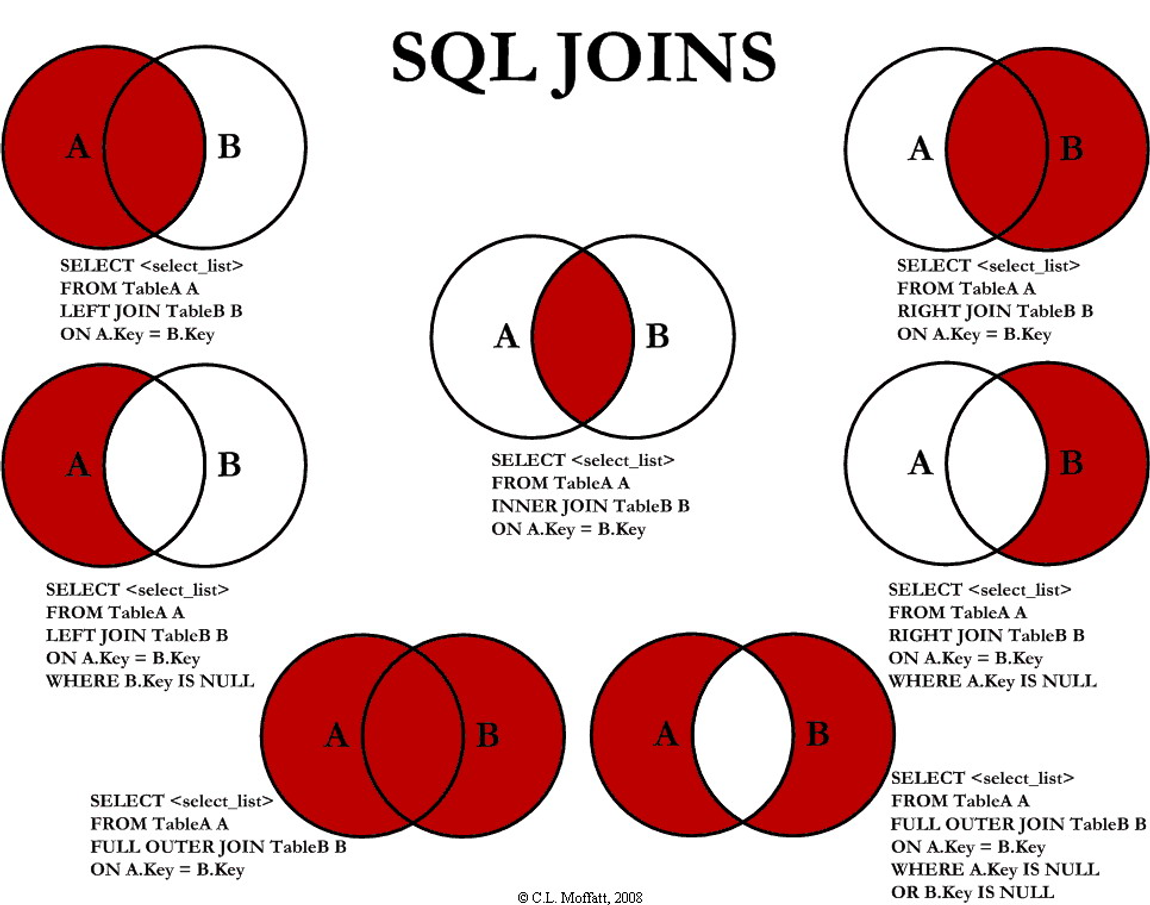
- 🎈 조인이란
조인이란 2개 이상의 테이블을 옵션에 따라 하나의 테이블 혹은 결과물로 합치는 것을 의미한다. 조인은 옵션에 따라 다양한 방식으로 이루어지며, 그 종류에는 inner join, left outer join, right outer join 등이 있다.
- 🎈 INNER JOIN
이너 조인이란 특정 테이블에 어떤 테이블을 조인시킬 경우 양 테이블의 데이터 중 조건에 부합하는 데이터만을 남기는 방식이다. 일종의 교집합으로 보면 되고, 해당 방식은 두 테이블 중 어떤 테이블을 기준으로 잡더라도 결과물이 동일하다는 특징이 있다.
- 🎈 LEFT (OUTER) JOIN
엄밀히 말하면 left outer join이지만 보통은 left join으로 이야기한다. 해당 방식은 JOIN문을 기준으로 왼쪽의 테이블을 기준으로 삼고, 기준 테이블의 데이터는 모두 남기고 조인할 테이블의 데이터를 이에 갖다 붙이는 방식이다. 기준 테이블의 데이터는 모두 남겼기 때문에 조인이 되지 않는 행이 발생하며, 이런 행에는 데이터 구조를 유지하기 위한 더미 데이터(null)가 붙게 된다. 이를 이용하면 차집합을 구현할 수 있는데, 바로 더미 데이터가 붙은 행만을 추출하는 방법이다.
- 🎈 RIGHT (OUTER) JOIN
이는 위에서 기술한 LEFT JOIN에서 기준 테이블만 바뀐 형태이므로 따로 설명은 하지 않겠다.
- 🎈 FULL OUTER JOIN
해당 방식은 대부분의 DBMS에서 직접적으로 지원하지는 않지만 간접적으로 이를 구현할 방법은 존재한다. (가끔 유용)
- 🎈 CROSS JOIN
두 테이블 상호 간 가능한 모든 조합을 출력
- 🎈 SELF JOIN
자기 자신과 alias를 다르게 하여 JOIN 진행
조인 시 one : one은 PK unique여부에 따라 완전하거나 한쪽이 부분집합이 된다.
반면, one : many의 경우 중복 문제가 발생하고, many : many의 경우 one : one 또는 one : many로 변경하는 것이 낫다.💯 최종적으로 SQL이 SELECT * FROM TABLE_A LEFT JOIN B ON A.ID = B.ID 라면,
A테이블은 그대로, B테이블의 경우 ID가 A와 일치하는 조건에 한해서만 합쳐지게 된다.
✅ 추가 SQL 함수
- COALESCE : NULL값을 다른 값으로 바꾸어주는 함수
COALESCE(exp1, exp2, exp3, ... ) : exp1부터 인자를 하나씩 살펴 NULL이 아니면 해당 인자 리턴.
ex) COALESCE(value, 0) : VALUE가 NULL이면 0, 아니면 VALUE 그대로 사용
+) GROUP같이 예약어를 필드명으로 사용하고자 할 때 double quotation 사용해 지정
단, 이후 필드명을 사용할 때 모두 double quotation을 적용해야 함.
✅ homework
ROW_NUMBER VS FIRST_VALUE/LAST_VALUE
- 사용자 251번의 시간순으로 볼 때 첫번째 채널과 마지막 채널이 무엇인가?
ROW_NUMBER를 활용해 해결해보기
🎈 < 사용자별로 처음 채널과 마지막 채널 알아내기 >
-- GROUP BY 방식
SELECT userid,
-- 아래 인덱싱 처리한 first_value, last_value의 MAX지정해 각각 채널 1개씩 추출
MAX(CASE WHEN first_value = 1 THEN channel END) as first_channel,
MAX(CASE WHEN last_value = 1 THEN channel END) as last_channel
FROM
-- 서브쿼리 사용해, ROW_NUMBER()로 userid 기준 timestamp 오름차순 및 내림차순 하여 번호 인덱싱 처리
(SELECT userid, channel,
(ROW_NUMBER() OVER (PARTITION BY USC.userid ORDER BY ST.ts asc)) as first_value,
(ROW_NUMBER() OVER (PARTITION BY USC.userid ORDER BY ST.ts desc)) as last_value
FROM raw_data.user_session_channel USC
JOIN raw_data.session_timestamp ST ON USC.sessionid = ST.sessionid
)
GROUP BY userid;
-- JOIN 방식
SELECT first.userid as userid, first.channel as first_channel, last.channel as last_channel
FROM
(SELECT userid, ts, channel, ROW_NUMBER() OVER(PARTITION BY userid ORDER BY ts) as seq
FROM raw_data.user_session_channel USC
JOIN raw_data.session_timestamp ST ON USC.sessionid = ST.sessionid
) as first
JOIN (
SELECT userid, ts, channel, ROW_NUMBER() OVER(PARTITION BY userid ORDER BY ts DESC) as seq
FROM raw_data.user_session_channel USC
JOIN raw_data.session_timestamp ST ON USC.sessionid = ST.sessionid
) as last ON first.userid = last.userid and first.seq = 1
WHERE last.seq = 1;
-- CTE 사용
WITH first as (
SELECT userid, ts, channel, ROW_NUMBER() OVER(PARTITION BY userid ORDER BY ts) as seq
FROM raw_data.user_session_channel USC
JOIN raw_data.session_timestamp ST ON USC.sessionid = ST.sessionid
), last as (
SELECT userid, ts, channel, ROW_NUMBER() OVER(PARTITION BY userid ORDER BY ts DESC) as seq
FROM raw_data.user_session_channel USC
JOIN raw_data.session_timestamp ST ON USC.sessionid = ST.sessionid
)
SELECT first.userid as userid, first.channel as first_channel, last.channel as last_channel
FROM first
JOIN last ON first.userid = last.userid and first.seq = 1
WHERE last.seq = 1;확실히 CTE를 사용한 방식이 코드 가독성이 높은 듯 하다.
🎈 < Gross Revenue가 가장 큰 userid 10개 찾기 >
SELECT userid, SUM(amount) as grossRevenue
FROM raw_data.session_transaction ST
-- session_transaction과 일치하는 sessionid 가진 userid만 가져와서 amount 계산
LEFT JOIN raw_data.user_session_channel USC ON USC.sessionid = ST.sessionid
GROUP BY userid
ORDER BY grossRevenue DESC
LIMIT 10;🎈 < 월별 nps 계산 >
- 고객들이 0(의향 없음) ~ 10 (의향 아주높음)
- detractor : 비추천자 (0 ~ 6)
- passive : 소극자 (7, 8)
- promoter : 홍보자 (9, 10)
- NPS : promoter (%) - detractor (%)
SELECT LEFT(created_at, 7) AS MONTH,
# 9이상인 promoter는 1처리, 6이하인 detractor는 -1 처리하여 1만 카운팅
ROUND(SUM(CASE WHEN score >= 9 THEN 1
WHEN score <= 6 THEN -1 END)*100.0 / COUNT(1), 2) AS NPS
FROM raw_data.nps
GROUP BY MONTH
ORDER BY MONTH