
✅ Airflow management & alternative
학습할 내용은 다음과 같다.
1. Production 사용을 위한 Airflow 환경 설정
2. Airflow log file delete
3. Airflow metadata backup
4. Airflow alternative❗ 주의 사항
- airflow.cfg is in /var/lib/airflow/airflow.cfg 에 존재. (webserver, scheduler 작동 시 변화가 반영됌)
-> core 섹션의 dags_folder가 DAG에 있는 DIR이 되어야 함.- Airflow DB upgrade?
-> sqlite -> postgres, MySQL 주기적으로 Backup 必
-> sql_alchemy_conn in Core section of airflow.cfg- enable Authentication & using a strong PW
- large disk volume for logs and local data
- periodic log data cleanup
-> (The above folders need to be cleaned up periodically)
-> you can write a shell operator based DAG for this purpose- From scale up to scale out (Using cloud option)
- Backup Airflow metadata DB
- Add health-check monitoring (API 활성화 후 Health Check Endpoint API 모니터링 툴과 연동)
참고 사항-> cloud composer, AWS MWAA, MS Azure: Data Factory 사용하기
🎈 Airflow log file delete
airflow는 2군데 로그를 기록한다. (폴더명 : 위치한 디렉토리)
1. base_log_folder : /var/lib/airflow/logs
2. child_process_log_directory : /var/lib/airflow/logs/scheduler-> Need to periodically delete
docker-compose 실행된 경우 logs폴더가 host volume형태로 유지 됌.
🎈 Airflow metadata backup
- DB가 외부에 있다면 (AWS-RDS) : 주기적인 백업 셋업.
- Airflow와 같은 서버에 메타 db (postgres) 있다면? DAG이용해 주기 백업 실행.
🎈 Airflow 외에 pipeline
prefect : airflow보다 경량화, 동적 파이프라인 구축 가능, open-source
dagster : 오픈소스지만 무거움, pipeline, data를 동시에 관리 (learning - curve 높은 편)
airbyte : 코딩 툴이라기 보단 low-code (어떻게 transform?, 어느 곳에 데이터 저장?)
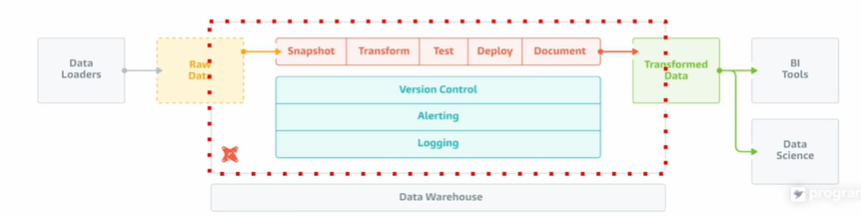
✅ dbt
: ELT를 가볍게 처리하도록 돕는 툴
-> ETL를 하는 이유는 ELT를 하기위함. 즉 데이터 quality 검증이 중요
데이터 품질 방법 ?
-> CI과정에서 code에 unittest 붙이는 것처럼 데이터 이동하는 케이스마다 품질 검증 필수!💯 DB normalization
또한, DB normalization도 데이터 품질을 향상시킬 수 있는 방법 중 하나이다.
: Primary KEY, Composite KEY(PK가 여러개), Foreign KEY 등으로 정규화 가능.
-> 위 KEY들을 통해 데이터 정합성을 쉽게 유지할 수 있고 레코드 수정/적재/삭제를 용이하게 함.
- 1NF : 한 셀에는 하나의 값, PK 존재, 중복된 키, 레코드 X
- 2NF : 1NF 만족, PK 중심으로 의존결과 확인 가능 (스타 스키마 Case - PK 별도 테이블 존재)
- 3NF : 2NF 만족, 전이적 부분 종속성 X
- SCD(Slowly Changing Dimensions) : 모든 테이블의 히스토리 유지, 컬럼 성격에 따라 어떻게 유지할 지 방법이 다름 (보통 2개의 timestamp 필드 갖는게 best - 생성시간, 마지막 수정시간)
- SCD (Production table(OLTP) <-> DW Table(OLAP) 간 일부 속성들은 시간을 두고 변화하는데 이를 DW에 어떻게 반영하는지 중요. (현 데이터만 유지 OR 처음부터 끝까지 히스토리 유지)
SCD Type 1: 데이터가 새로 생기면 덮어쓰기.
SCD Type 2: 특정 entity에 대한 데이터가 새로운 레코드로 추가되는 경우 (멤버쉽 등급 변화), 변경 시간도 추가
SCD Type 3: 특정 entity대안으로 새 컬럼 추가
SCD Type 4: 특정 entity에 대해 새로운 dimension 테이블에 저장 (type2변종, 아예 별도 테이블로 일반화)🎈 dbt
: 다양한 DW를 지원하는 ELT용 오픈소스로 클라우드 버전인 dbt Cloud도 존재.
구성 컴포넌트는 다음과 같다.
- data models (테이블을 몇개의 티어로 관리) - CTAS, Table, View, CTE etc.
- test (품질 검증)
- snapshot
dbt는 다음과 같은 요구조건이 있는 경우에 사용하는 것이 좋다.
1. 데이터 변경 사항 이해 쉽고 필요할 때 롤백 가능을 원하는 경우
2. 데이터 간 lineage(출처, 시간 경과에 따른 이동 위치 등) 확인 가능 - data catalog
3. 품질 테스트 및 에러 보고
4. fact 테이블의 incremental update)
5. dimension table 변경 추적 (history table)
6. 문서 작성 용이✨ local에서 dbt 실행 - dbt core
dbt내 파일들은 yml 또는 SQL 구문이다.
1. local terminal에서 pip3 install dbt-redshift 실행
2. dbt init learn_dbt로 프로젝트 생성 (redshift와 관련된 host, userid 등등 정보 기입)< cd 프로젝트명 이동 후 결과 >
3. models : ELT 만드는데 기본이 되는 빌딩블록으로 table, view, CTE 등의 형태로 존재하며 INPUT, 중간, OUTPUT 테이블을 정의하는 공간.model 구성요소
- input : 입력(raw) - CTE, 중간(staging, src) - View로 데이터 정의
- output : 최종(core) 데이터(table로) 정의
-> 모두 models 폴더 밑에 sql 파일로 존재. (기본적으로 SELECT + jinja template)🎈 Input 방법 - practice
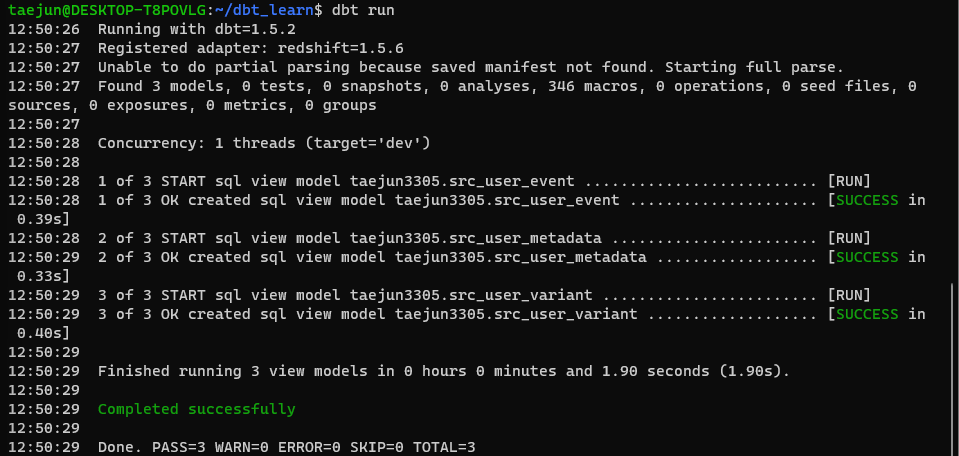
만들어둔 프로젝트로 이동해 models내 저장된 example 제거, yml파일 내 맨 뒤 두줄(example 제거)하고 src만들기
src내 src_user_event, src_user_variant, src_user_metadata sql 생성 후 프로젝트 level에서 dbt run 실행
< redshift 연동 결과 성공 >
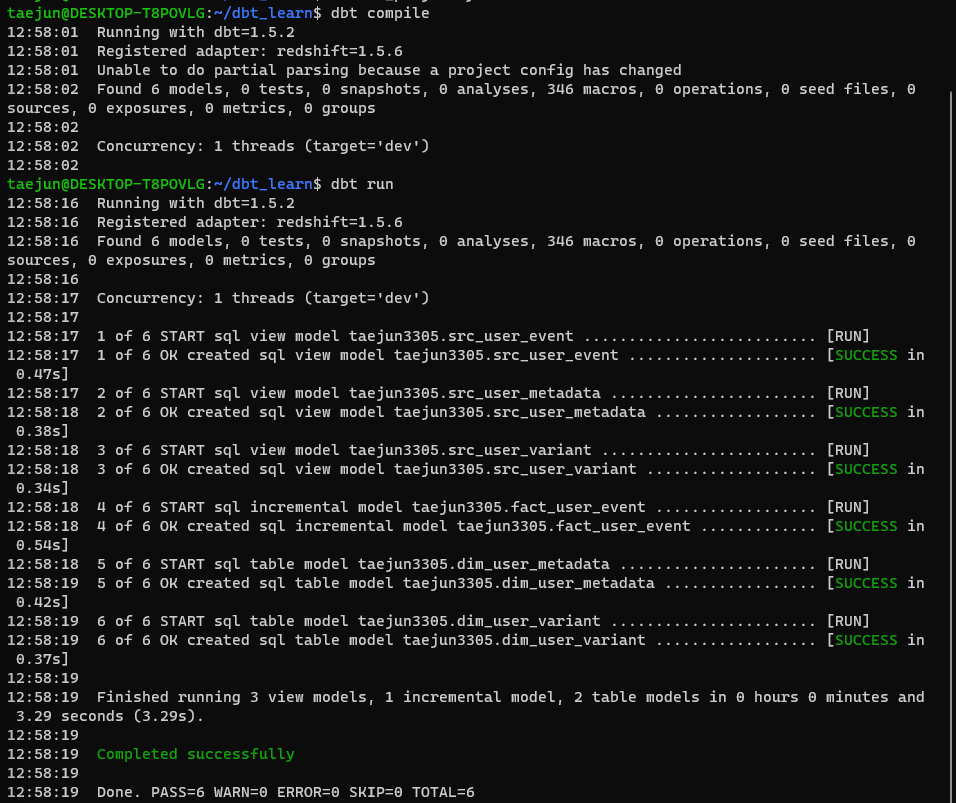
models 폴더내 dim, fact 폴더 생성 후 각 폴더 내 sql 파일 생성.
dbt_project.yml 파일 내 마지막 부분 아래 코드로 수정
models: dbt_learn(프로젝트명): # 프로젝트 내 테이블들은 기본적으로 view로 빌드 +materialized: view dim: # dim 폴더 밑에 테이블들은 모두 table로 빌드 +materialized: table # not embedding, 바로 view나 테이블 없이 CTE 처리 src: +materialized: ephemeral
- 이후 dbt compile(sql 코드만 생성, 실행 X), run(생성된 코드도 실행) 실행
- sql 실행 결과는 프로젝트명/target/compiled or run/프로젝트명/models/에서 확인 가능
- run에서는 fact: insert into 결과, dim: CTAS를, compiled에서는 schema, table 명 확인 가능!

✅ dbt Seeds
많은 dimension 테이블들을 CSV로 만들어 DW로 로드하는 방법. Seeds는 작은 파일 데이터 지칭
-> seeds 폴더 내 적당한 .csv 파일 만들고 자신 스키마 밑에 테이블 생성. (dbt seed로 실행)
✅ dbt sources
중간 단계인 staging 테이블을 만들 때 raw 테이블이 자주 바뀐다면 작업성능이 비효율적으로 떨어진다.
- 기본적으로 처음 입력되는 ETL 테이블을 대상으로 별칭, 최신 레코드 체크 기능 제공
- 테이블 이름에 alias 부여 (ETL 단에서 source table 변경되어도 영향 x)
-> raw_data.user_metadata -> taejun3305, metadata 로 구성
- models로 들어가 sources.yml 파일 생성
version: 2 sources: - name: taejun3305 schema: raw_data tables: - name: metadata identifier: user_metadata - name: event identifier: user_event # 필드 최신성 부여 현 시간보다 1시간 뒤쳐지면 warning, 하루 뒤쳐지면 error나오도록) loaded_at_field: datestamp freshness: warn_after: { count: 1, period: hour } error_after: {count: 24, period: hour } - name: variant identifier: user_variant
- src 들어가서 CTE 구문에서 FROM 이후 {{ source("taejun3305", "metadata") }}로 변경
✅ dbt snapshot
dimension 테이블의 변경이 자주일어나므로 history정보를 기록해 rollback 가능성을 올려야 한다.
앞서 본 SCD Type 2의 일반화인 새로운 dimension 테이블을 만들어 줄 필요가 있다. (히스토리/snapshot 테이블)
처리 방법은 다음과 같다.
1. 먼저 snapshot 폴더에 환경설정
2. snapshot을 위해 data source가 일정 조건을 만족 (PK 존재, timestamp(변경시간) 존재)
3. 변경 감지 기준 - pk 기준 변경시간이 현재 DW에 있는 시간보다 미래인 경우
4. snapshot 테이블에는 4개의 ts존재. (dbt_scd_id, dbt_updated_id, valid_from, valid_to) -> 컬럼 수만큼 ts들 생성
-> snapshots/ 폴더 밑에 scd_user_metadata.sql 편집{% snapshot scd_user_metadata %} {{ config( target_schema='taejun3305', unique_key='user_id', strategy='timestamp', updated_at='updated_at', invalidate_hard_deletes=True ) }} SELECT * FROM {{ source('taejun3305', 'metadata') }} {% endsnapshot %}
✅ dbt tests
데이터 품질 테스트하는 방법으로 2가지가 존재한다.
1. 내장 일반 테스트 ("Generic") : unique, not_null, accepted_values, relationship 등 테스트 지원 (models 폴더)
2. 커스텀 테스트 ("Singular") : 기본적으로 SELECT로 간단하며 결과 리턴 시 실패로 간주 (tests 폴더)Generic tests 구현
-> schema.yml 파일 생성 후 dbt test로 실행Singular tests 구현
-> dim_user_metadata.sql 파일 생성 후 dbt test로 실행🎈 dbt documentation
- 기존 .yml파일에 문서화 추가 (선호), 독립적인 markdown 파일 생성
-> models/schema.yml, models/sources,yml에 description 키를 추가하는 방법도 존재
-> $ 프로젝트명/dbt docs generate로 결과 파일 target/catalog.json파일로 저장- 이를 경량 웹서버로 서빙 (overview.md가 기본 홈페이지, 이미지 등의 asset추가도 가능)
-> dbt docs serve로 웹서버 띄우는 방법 존재 (Lineage graph 체크)
