Computer Architecture
- 컴퓨터 구조 기초
- 컴퓨터의 구성
- CPU 작동원리
- 캐시 메모리
Computer Architecture
컴퓨터 구조 기초
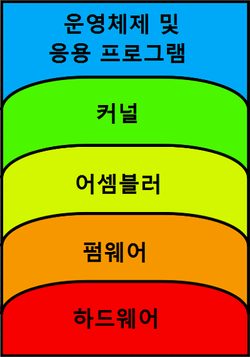
컴퓨터는 입력, 연산, 제어, 기억, 출력 5가지 기능을 구현하기 위해 여러부품으로 구성되어 있다. 위의 사진은 컴퓨터의 추상 계층을 나타내는 사진이다.
하드웨어
컴퓨터 하드웨어는 케이스 중앙 처리 장치(CPU), 모니터, 자판, 컴퓨터 기억 장치, 그래픽 카드, 사운드 카드, 메인보드와 같은 컴퓨터의 물리적 부품을 의미한다.
중앙 처리 장치(CPU(Central Processing Unit))
CPU는 컴퓨터 시스템을 통제하고 프로그램의 연산을 실행 및 처리하는 가장 핵심적인 컴퓨터의 제어 장치를 말하거나 그 기능을 하는 칩을 말한다. CPU는 외부에서 정보를 입력받고 그 정보를 기억하고 컴퓨터 프로그램의 명령어를 해석하여 연산하고, 외부로 출력하는 역할을 한다. 즉 CPU는 컴퓨터 부품과 정보를 교환하면서 컴퓨터 시스템 전체를 제어한다. 모든 컴퓨터의 작동과정이 CPU의 제어를 받아서 컴퓨터의 두뇌라고 부른다.
기억 장치
기억 장치는 전자회로에서 데이터나 상태 명령어 등을 기록하는 장치를 말하며, 흔히 메모리라고 한다. 컴퓨터에서 널리 사용되며, CPU가 계산을 담당하고 메모리가 기억을 담당한다. 쉽게 설명하면 CPU는 일꾼이고 메모리는 작업장이며 보조기억장치는 창고라고 할 수 있다.

CPU에 가까운 순서대로 레지스터(CPU) -캐시 메모리 - 주기억 장치 - 캐시 메모리 - 보조 기억장치로 나눌 수 있다. 일반적으로 용량이 작을수록 동작속도가 빠르며, 용량이 클수록 동작속도가 느리다.
펌웨어(firnware)
펌웨어는 툭정 하드웨어 장치에 포함된 소프트웨어로 소프트웨어를 읽어 실행하거나, 수정하는 것도 가능한 장치를 뜻한다. 하드웨어의 제어(low-level control)와 구동을 담당하는 일종의 운영체제이다. 펌웨어는 ROM이나 PROM에 저장되며, 하드웨어보다는 교환하기가 쉽지만, 소프트웨어보다는 어렵다.
소프트웨어(software)
소프트웨어는 컴퓨터에게 동작 방법을 지시하는 명령어 집합의 모임이다. 프로그램 소프트웨어는 컴퓨터 하드웨어에 직접 명령어를 주거나 다른 소프트웨어에 입력을 제공함으로써, 명령어의 기능을 수행한다.
컴퓨터의 구성
하드웨어
- 중앙처리장치(CPU)
- 기억장치: RAM, HDD
- 입출력 장치: 마우스, 프린터
소프트웨어
- 시스템 소프트웨어: 운영체제, 컴파일러
- 응용 소프트웨어: 워드프로세서, 스프레드시트
시스템 버스
하드웨어 구성 요소를 물리적으로 연결하는 선
각 구성요소가 다른 구성요소로 데이터를 보낼 수 있도록 통로가 되어줌
용도에 따라 데이터 버스, 주소 버스, 제어 버스로 나누어짐
데이터 버스
중앙처리장치와 기타 장치 사이에서 데이터를 전달하는 통로
기억장치와 입출력장치의 명령어와 데이터를 중앙처리장치로 보내거나, 중앙처리장치의 연산 결과를 기억장치와 입출력장치로 보내는 '양방향' 버스임
주소 버스
데이터를 정확히 실어나르기 위해서는 기억장치 '주소'를 정해주어야 함.
주소버스는 중앙처리장치가 주기억장치나 입출력장치로 기억장치 주소를 전달하는 통로이기 때문에 '단방향' 버스임
제어 버스
주소 버스와 데이터 버스는 모든 장치에 공유되기 때문에 이를 제어할 수단이 필요함
제어 버스는 중앙처리장치가 기억장치나 입출력장치에 제어 신호를 전달하는 통로임
제어 신호 종류 : 기억장치 읽기 및 쓰기, 버스 요청 및 승인, 인터럽트 요청 및 승인, 클락, 리셋 등
제어 버스는 읽기 동작과 쓰기 동작을 모두 수행하기 때문에 '양방향' 버스임
컴퓨터는 기본적으로 읽고 처리한 뒤 저장하는 과정으로 이루어짐
(READ → PROCESS → WRITE)
이 과정을 진행하면서 끊임없이 주기억장치(RAM)과 소통한다. 이때 운영체제가 64bit라면, CPU는 RAM으로부터 데이터를 한번에 64비트씩 읽어온다.
CPU 작동원리
CPU는 컴퓨터에서 가장 핵심적인 역할을 수행하는 부분. '인간의 두뇌'에 해당
크게 연산장치, 제어장치, 레지스터 3가지로 구성됨
연산 장치
산술연산과 논리연산 수행 (따라서 산술논리연산장치라고도 불림)
연산에 필요한 데이터를 레지스터에서 가져오고, 연산 결과를 다시 레지스터로 보냄
제어 장치
명령어를 순서대로 실행할 수 있도록 제어하는 장치
주기억장치에서 프로그램 명령어를 꺼내 해독하고, 그 결과에 따라 명령어 실행에 필요한 제어 신호를 기억장치, 연산장치, 입출력장치로 보냄
또한 이들 장치가 보낸 신호를 받아, 다음에 수행할 동작을 결정함
레지스터
고속 기억장치임
명령어 주소, 코드, 연산에 필요한 데이터, 연산 결과 등을 임시로 저장
용도에 따라 범용 레지스터와 특수목적 레지스터로 구분됨
중앙처리장치 종류에 따라 사용할 수 있는 레지스터 개수와 크기가 다름
범용 레지스터 : 연산에 필요한 데이터나 연산 결과를 임시로 저장
특수목적 레지스터 : 특별한 용도로 사용하는 레지스터
CPU의 동작 과정
- 주기억장치는 입력장치에서 입력받은 데이터 또는 보조기억장치에 저장된 프로그램 읽어옴
- CPU는 프로그램을 실행하기 위해 주기억장치에 저장된 프로그램 명령어와 데이터를 읽어와 처리하고 결과를 다시 주기억장치에 저장
- 주기억장치는 처리 결과를 보조기억장치에 저장하거나 출력장치로 보냄
- 제어장치는 1~3 과정에서 명령어가 순서대로 실행되도록 각 장치를 제어
캐시 메모리
속도가 빠른 장치와 느린 장치에서 속도 차이에 따른 병목 현상을 줄이기 위한 메모리를 말한다.
CPU가 주기억장치에서 저장된 데이터를 읽어올 때, 자주 사용하는 데이터를 캐시 메모리에 저장한 뒤, 다음에 이용할 때 주기억장치가 아닌 캐시 메모리에서 먼저 가져오면서 속도를 향상시킨다.
속도라는 장점을 얻지만, 용량이 적기도 하고 비용이 비싼 점이 있다.
CPU에는 이러한 캐시 메모리가 2~3개 정도 사용된다. (L1, L2, L3 캐시 메모리라고 부른다)
속도와 크기에 따라 분류한 것으로, 일반적으로 L1 캐시부터 먼저 사용된다. (CPU에서 가장 빠르게 접근하고, 여기서 데이터를 찾지 못하면 L2로 감)
듀얼 코어 프로세서의 캐시 메모리 : 각 코어마다 독립된 L1 캐시 메모리를 가지고, 두 코어가 공유하는 L2 캐시 메모리가 내장됨
만약 L1 캐시가 128kb면, 64/64로 나누어 64kb에 명령어를 처리하기 직전의 명령어를 임시 저장하고, 나머지 64kb에는 실행 후 명령어를 임시저장한다. (명령어 세트로 구성, I-Cache - D-Cache)
L1 : CPU 내부에 존재
L2 : CPU와 RAM 사이에 존재
L3 : 보통 메인보드에 존재한다고 함
캐시 메모리 작동 원리
시간 지역성
for나 while 같은 반복문에 사용하는 조건 변수처럼 한번 참조된 데이터는 잠시후 또 참조될 가능성이 높음
공간 지역성
A[0], A[1]과 같은 연속 접근 시, 참조된 데이터 근처에 있는 데이터가 잠시후 또 사용될 가능성이 높음
이처럼 참조 지역성의 원리가 존재한다.
캐시에 데이터를 저장할 때는, 이러한 참조 지역성(공간)을 최대한 활용하기 위해 해당 데이터뿐만 아니라, 옆 주소의 데이터도 같이 가져와 미래에 쓰일 것을 대비한다.
CPU가 요청한 데이터가 캐시에 있으면 'Cache Hit', 없어서 DRAM에서 가져오면 'Cache Miss'
캐시 미스 경우 3가지
Cold miss
해당 메모리 주소를 처음 불러서 나는 미스
Conflict miss
캐시 메모리에 A와 B 데이터를 저장해야 하는데, A와 B가 같은 캐시 메모리 주소에 할당되어 있어서 나는 미스 (direct mapped cache에서 많이 발생)
항상 핸드폰과 열쇠를 오른쪽 주머니에 넣고 다니는데, 잠깐 친구가 준 물건을 받느라 손에 들고 있던 핸드폰을 가방에 넣었음. 그 이후 핸드폰을 찾으려 오른쪽 주머니에서 찾는데 없는 상황
Capacity miss
캐시 메모리의 공간이 부족해서 나는 미스 (Conflict는 주소 할당 문제, Capacity는 공간 문제)
캐시 크기를 키워서 문제를 해결하려하면, 캐시 접근속도가 느려지고 파워를 많이 먹는 단점이 생김
Java
- 컴파일 과정
- Java Virtual Machine
- Call By Value / Call By Reference
- Thread
- Casting
- Auto Boxing / Auto Unboxing
JAVA
컴파일 과정
컴파일
인간이 이해하기 쉬운 언어를 기계어로 변역하는 과정
컴파일러
컴파일을 하는 프로그램
바이트 코드
컴퓨터가 이해할 수 있는 0과 1로 이루어진 코드
프로그래밍 언어 ---------- (컴파일러) ---------- 바이트 코드
이 바이트 코드는 운영체제마다 다르기 때문에 컴파일러를 통해 만들어진 바이트 코드를 윈도우, 맥, 리눅스에서 실행시켰을 때 다른 결과가 나올 수 있게 된다.
예를 들어 C언어는 윈도우 C언어 컴파일러, 맥 C언어 컴파일러, 리눅스 C언어 컴파일러가 각각 있어서 이 컴파일러마다 다른 0과 1을 만들어내게 되고 해당 운영체제에 서로 다르게 만들어진 바이트 코드를 전달해 주면 C언어 프로그래밍 언어로 만든 같은 내용이 출력이 되는 식이다.
하지만 자바는 자바 컴파일러 하나가 있고 자바 컴파일러 하나로부터 생성된 0과 1의 바이트 코드가 하나있으며 이 바이트 코드가 윈도우, 맥, 리눅스에 바로 가는 것이 아니라 윈도우의 JVM, 맥의 JVM, 리눅스의 JVM에 가는 것이다.
JVM은 바이트코드와 운영체제 사이에서 둘을 호환시켜주는 역할을 한다.
JVM은 운영체제마다 각각있으며 JAVA를 설치하면 한 번에 같이 설치가 되는 식이다.
정리하면 C언어는 컴파일러가 여러 개 있고 컴파일 된 결과물(바이트코드)이 여러개지만 자바는 컴파일러가 하나고 컴파일된 결과물(버이트코드)이 동일하며 이 결과물을 JVM이 각각의 운영체제에게 번역을 해주는 것이다.
그래서 자바는 한 번만 결과물을 만들어 놓으면 어떤 운영체제에서든지 똑같은 결과가 나온다는 장점이있다.
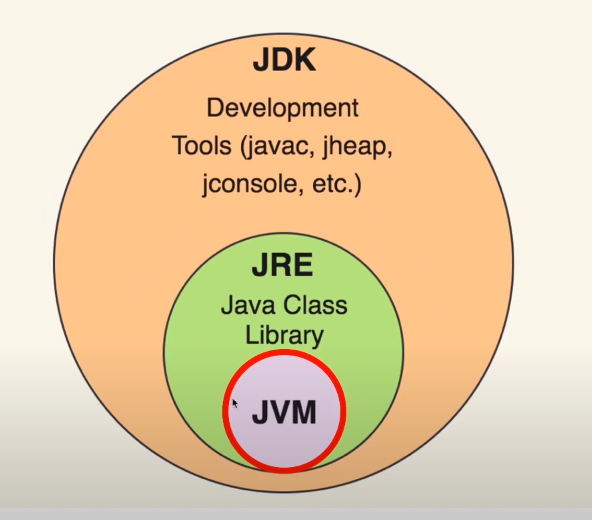
JDK > JRE > JVM
JDK에는 JRE가 포함되어 있고 JRE에는 JVM이 포함되어 있는 관계이다. 즉, JDK를 설치하면 JRE도 설치되고, JVM도 설치가 되는 것이다.
Java Virtual Machine
JVM
JVM (Java Virtual Machine)
OS 별로 존재한다.
바이너리 코드를 읽고 검증하고 실행한다.
컴파일 한 결과물을 실행시켜주는 역할
JRE
JRE (Java Runtime Environment, 자바 실행 환경)
JRE = JVM + 자바 프로그램 실행에 필요한 라이브러리 파일들
JVM의 실행환경을 구현
JDK
JDK (Java Develrpment Kit, 자바 개발 도구)
JDK = JRE + 개발을 위한 도구
컴파일러, 디버그 도구 등이 포함
자바의 버전 = JDK의 버전
(JDK는 여러 종류가 있으며 기능 자체는 모두 동일하나 성능과 비용에 약간의 차이가 있을 수 있다.)
자바의 버전 중에는 LTS(Long Time Support)라는 버전이 있는데 이 버전은 오래 지원하는 버전을 뜻한다.
Call By Value / Call By Reference
Call By Value(값에 의한 호출)
함수가 호출될 때, 메모리 공간 안에서는 함수를 위한 별도의 임시 공간이 생성된다. (c++의 경우 stack frame) 함수가 종료되면 해당 공간은 사라진다.
스택 프레임(Stack Frame) : 함수 호출시 할당되는 메모리 블록(지역변수의 선언으로 인해 할당되는 메모리 블록)
call-by-value 값에 의한 호출방식은 함수 호출시 전달되는 변수의 값을 복사하여 함수의 인자로 전달한다.
복사된 인자는 함수 안에서 지역적으로 사용되는 local value의 특성을 가진다.
따라서 함수 안에서 인자의 값이 변경되어도, 외부의 변수의 값은 변경되지 않는다.
Java의 경우 함수에 전달되는 인자의 데이터 타입에 따라서 (원시자료형 / 참조자료형) 함수 호출 방식이 달라진다.
원시 자료형 (primitive type) : call-by-value 로 동작 (int, short, long, float, double, char, boolean )
참조 자료형 (reference type): call-by-reference 로 동작 (Array, Class Instance)
Call By Reference(참조에 의한 호출)
함수가 호출될 때, 메모리 공간 안에서는 함수를 위한 별도의 임시 공간이 생성된다. (예: stack frame) 함수가 종료되면 해당 공간은 사라진다.
call-by-reference 참조에 의한 호출방식은 함수 호출시 인자로 전달되는 변수의 레퍼런스를 전달한다. (해당 변수를 가르킨다.)
따라서 함수 안에서 인자의 값이 변경되면, 아규먼트로 전달된 객체의 값도 함께 변경된다.
Thread
- 프로세스 내에서 실제 작업을 수행하는 것을 쓰레드라고 한다.
- 모든 프로세스는 최소한 하나의 쓰레드를 가지고 있다.
프로세스
실행 중인 프로그램, 자원(메모리, CPU 등)과 쓰레드로 구성됨
프로세스 : 쓰레드 = 공장 : 일꾼
싱글 쓰레드 프로세스(일꾼이 한명) = 자원 + 쓰레드
멀티 쓰레드 프로세스(일꾼이 여러명) = 자원 + 쓰레드 + 쓰레드 + 쓰레드 + ..... + 쓰레드
<멀티 쓰레드로 프로그램을 작성하면 좋은 점>
- 한 프로세스안에서 일꾼이 여러명이기 때문에 여러 작업을 나누어서 처리할 수 있어 작업을 보다 효율적으로 처리할 수 있다.
(자바는 멀티 쓰레드를 지원한다.) - 사용자에 대한 응답성이 향상된다.(파일을 보내면서 채팅을 칠 수가 있다.)
- 작업이 분리되어 코드가 간결해진다.
<멀티 쓰레드로 프로그램을 작성하면 안 좋은 점>
- 동기화(synchronization)에 주의해야 한다.
- 교착상태(dead-lock)가 발생하지 않도록 주의해야 한다.
(교착상태: 두 개 이상의 작업이 서로 상대방의 작업이 끝나기 만을 기다리고 있기 때문에 결과적으로 완료되지 못하는 상태를 말함) - 각 쓰레드가 효율적으로 고르게 실행될 수 있게 해야한다.
(쓰레드가 여러개가 있어서 어떤 쓰레드는 실행할 기회를 갖지 못해서 작업이 진행이 안될 수가 있다. 이를 기아라고 하며 프로그램을 잘못 짜면 특정 쓰레드는 작업을 실행할 기회를 얻지 못할 수 있어 각 쓰레드가 효율적으로 고르게 실행될 수 있게 작성해야 한다.)하나의 새로운 프로세스를 생성하는 것보다 하나의 새로운 쓰레드를 생성하는 것이 더 적은 비용이 든다.
2개의 싱글 쓰레드 프로세스의 비용 > 멀티 쓰레드 프로세스(쓰레드 2개) 1개의 비용
Casting(형변환)
다형성- 하나의 객체가 여러가지 타입을 가질 수 있는 것을 의미한다.
캐스팅은 OOP(객체지향프로그래밍) 에서 매우 중요하다. 왜냐하면 캐스팅은 OOP의 다형성과 관련이 있기 때문이다. 캐스팅의 목적은 데이터를 바꾸는 것이 주목적이 아닌, 코드를 적는 프로그래머가 이미 데이터 정보에 대해 이해한 가정하에, OOP의 다형성 측면에서 사용한다.기본 데이터형에서의 캐스팅은 원칙적으로 데이터손실을 막고자 한다.
자료형이 정해진 변수에 값을 넣을때는 변수가 원하는 정보를 하나도 빠짐 없이 다 넣어줘야 성립한다. (즉 변수의 데이터 타입 >= 실제 데이터의 타입)
예시를 통해 알아보자.
int a = 1.0 // 불가능 (변수의 데이터 타입은 int지만 1.0은 double이므로)
int a = (int) 1.0 // 가능 (실제 데이터 앞에 (데이터 자료형)을 붙여줘 캐스팅이 되어 1.0대신 1이 들어가서 int a = 1과 동일한 코드가 된다.)
double b = 1 // 가능 (변수의 데이터 타입이 더 크므로)
<업캐스팅>
Parent와 Child 클래스가 있으며 Child클래스가 Parent 클래스를 상속 받는다고 가정해보자.
Parent parent = new Parent(); // 문제 없음
Child child = new Child(); // 문제 없음
Parent parent = new Child(); // Child클래스는 부모 클래스를 상속 받기 때문에 Parent 자료형 데이터를 모두 가지고 있다. (Parent <= Child) 이를 업캐스팅이라고 한다.
<다운캐스팅>
다운캐스팅을 알아보기 전에 다음 코드가 에러인 이유를 살펴보고 가자.
Child child = (Child) new Parent();
위의 코드는 컴파일에러가 아닌 런타임에러이다. 컴파일러에게 프로그래머가 현변환을 함으로써, 일단 데이터를 맞게 넣어준 것처럼 보여줘서 컴파일러가 문법이 맞다고 생각하게 만들어 컴파일에러가 나지 않는 것이다. 하지만 프로그램이 실제로 작동할 때 Parent의 데이터 타입을 Child로 바꾸지 못한다는 것을 깨닫고 런타임에러가 나며 프로그램이 종료된다. 데이터 타입을 바꾸지 못하는 이유는 Child는 참조형 데이터 타입으로 프로그래머가 작성하는 부분이다. 이 말은 프로그래머마다 다른 Child클래스가 만들어 질 것이다. 이를 JVM은 추리하지 못함로 런타임에러가 나오는 것이다.
int a = (int) 1.0;
위의 코드는 기본형 데이터 타입이므로 기본형 데이터 타입끼리는 추리가 가능하기 때문에 알아서 알맞은 데이터 크개로 변환하여 넣어줄 수 있다. 하지만 참조형 데이터 타입은 그렇지 못해 위의(Child child = (Child) new Parent();)는 런타임에러가 발생하게 된다.
다운 캐스팅은 일반적으로 성립하지 않지만 성립되는 경우가 존재한다. 예시를 통해 알아보자.
Parent parent = new Child(); // 업캐스팅 (Child 데이터 타입이 Parent 데이터 타입보다 크다.)
Child child = (Child) parent; // 가능
위의 Child child = (Child) parent가 가능한 이유는 parent는 Parent클래스 형태의 변수지만 Child 객체를 생성하여 그 주소값을 가지고 있는 변수이다. 그래서 다음과 같은 코드가 가능한 것이다.
Auto Boxing / Auto Unboxing
기본 타입 : boolean, char, byte, short, int, long, flaot, double
Wrapper 클래스 : Integer, Long, Float, Double, Boolean...
Wrapper클래스를 사용하는 이유는?
-
기본 데이터 타입을 Object로 변환할 수 있다.
-
java.util패키지의 클래스는 객체만 처리하므로 Wrapper class는 이경우에도 도움이 된다.
-
ArrayList등과 같은 Collection Framework의 데이터 구조는 기본 타입이 아닌 객체만 저장하게 되고,
Wrpper class를 사용하여 오토 방식/ 언박싱이 일어난다. -
멀티스레딩에서 동기화를 지원하려면 객체가 필요하다.
박싱이란?
기본 타입 데이터를 대응하는 Wrapper클래스로 만드는 동작(int -> Integer)
언박싱이란?
Wrapper 클래스에서 기본 타입으로 변환(Integer -> int)
<주위할 점>
편의성을 위해 오토 박싱과 언박싱이 제공되지만, 내부적으로 추가 연산 작업이 발생하여, 성능이 떨어지게 된다.
따라서 오토 박싱과 언박싱이 일어나지 않도록 동일한 타입 연산이 이루어지도록 구현해야 한다.
//박싱
int a = 10;
Integer b = new Integer(a);
//오토 박싱
int i =10;
Integer num = i;
//언박싱
Integer b = new Integer(10);
int a = b.intValue();
//오토 언박싱
Integer num = new Integer(10);
int i = num;