Web and HTTP
Web page는 objects로 구성되어 있다. objects는 HTML file, JPEG, Java applet, audio file 등등으로 이루어져 있다. web page는 기본 objects가 포함된 기본 HTML file로 구성되어 있다.
각 오브젝트는 URL로 adderssable되어 있다.
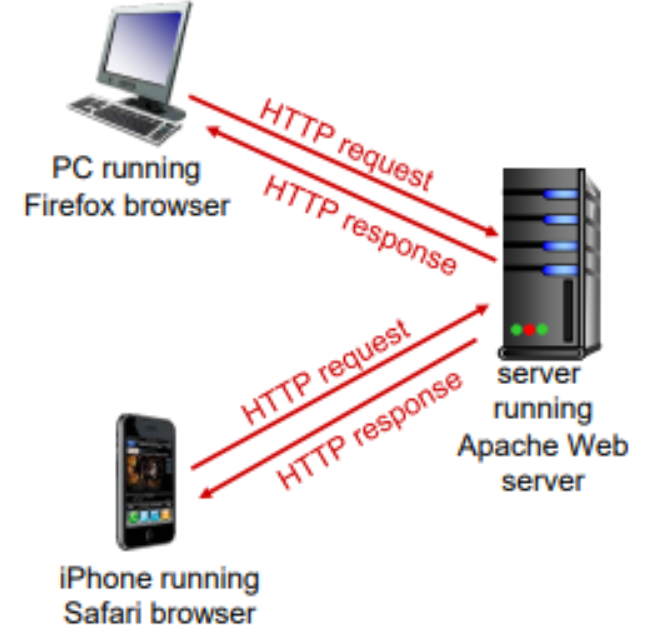
HTTP는 웹에서 사용되는 web application layer protocol이다. web application은 HTTP외에는 protocol 없다고 생각하면 된다. client는 서버로부터 정보를 받아서 display한다. 서버는 URL 정보를 가지고 있고, 해당하는 응답을 보내준다. application layer에 있는 HTTP는 아래 transport layer에서 사용한 TCP를 사용한다. 웹은 신회성이 중요하기 때문에 신뢰성 없는 UDP보다 TCP를 사용하는 것이다.
HTTP는 stateless하다(상태가 없다). (TCP는 stateful하다. TCP는 connection이 열려있는지 state가 있다.) HTTP 입장에서는 이 Client의 request에 대한 정보에 관심있다. 그냥 무언가가 오면, 상응하는 답을 보낼 뿐이다. stateless하기 때문에 가벼워서 서버가 부담없이 돌릴 수 있다.
HTTP
1. 비연결성(Connectionless)
비연결성은 클라이언트와 서버가 한 번 연결을 맻은 후, 클라이언트 요청에 대해 서버가 응답을 마치면 맺었던 연결을 끊어 버리는 성질을 말한다.
<HTTP 프로토콜이 한 번 맺은 연결을 끊어버리는 이유>
HTTP는 인터넷 상에서 불특정 다수의 통신 환경을 기반으로 설계되었다.
만약 서버에서 다수의 클라이언트와 연결을 계속 유지해야 한다면, 이에 따른 많은 리소스가 발생하게 된다.그래서 연결을 유지하기 위한 리소스를 줄이면 더 많은 연결을 할 수 있으므로 비연결적인 특징을 갖는 것이다. 즉, 한 번 맺은 연결을 끊어버리는 이유는 더 많은 호클라이언트와 연결을 하기 위해서이다.
이에 따른 단점도 있는데 서버는 클라이언트를 기억하고 있지 않으므로 동일한 클라이언트의 모든 요청에 대해, 매번 새로운 연결을 시도/해제의 과정을 거쳐야하므로 연결/해제에 대한 오버헤드가 발생한다는 단점이 있다.
오버헤드(overhead): 어떤 처리를 하기 위해 들어가는 간접적인 처리시간, 메모리 등을 말한다.
KeepAlive
오버헤드를 줄이기 위해 HTTP의 keepAlive 속성을 사용할 수 있습니다. KeepAlive는 지정된 시간동안 서버와 클라이언트 사이에서 패킷 교환이 없을 경우, 상대방의 안부를 묻기위해 패킷을 주기적으로 보내는것을 말하며 패킷에 대한 반응이 없으면 접속을 끊게 된다. 이 방법은 주기적으로 클라이언트의 상태를 체크해야 하므로 KeepAlive 역시 완벽한 해결책은 아니다. 왜냐하면 KeepAlive 속성이 On 상태라해도, 서버가 바쁜 환경에서는 프로세스 수가 기하급수적으로 늘어나기 때문에 KeepAlive로 상태를 유지하기 위한 메모리를 많이 사용하게 되기 때문이다.
2. 무상태(Stateless)
Connectionless(비연결성)로 인해 서버는 클라이언트를 식별할 수가 없는데, 이를 Stateless(무상태)라고 한다. 클라이언트의 상태를 모른다는 것을 예시를 통해 봐보자.
- 쇼핑몰에 접속
- 로그인
- 상품 클릭 -> 특정 상품화면으로 이동
- 로그인
- 주문
- 로그인
- .....
매번 새로운 인증을 해야하는 번거로움이 발생하게 된다.
그렇다면 클라이언트의 상태를 기억하는 방법은 없을까? 한번 알아보자.
클라이언트의 상태를 기억하는 방법
클라언트의 상태를 기억하는 이유는 클라이언트의 인증을 유지하기 위해서이다. 서버는 클라이언트가 요청을 하기위해 로그인(인증)을 해도 다음 요청을 할 때 이를 기억하지 못한다. (쇼핑몰에서 페이지를 이동할 때 마다 로그인을 해야 된다....) 이는 사용자의 접근성이 매우 떨어지는 요인이 된다.
쿠키(Cookie)
쿠키란 클라이언트 측(브라우저)에서 관리되는 작은 기록 정보 파일을 의미한다. 쿠키에는 사용자 인증이 유효한 시간을 명시할 수 있고, 한 번 유효 시간이 정해지면 브라우저를 끄더라도 인증이 유지된다는 특징이 있다.
HTTP는 state를 가지고 있지 않아, user의 id나 정보를 읽을 수 없다. 그래서 콘텐츠 제공, 차단 등과 같은 서비스를 제공하지 못한다. 이러한 단점 때문에 HTTP는 state를 가지고 있는 Cookie를 사용한다. Cookie는 state가 있어 사용자 정보를 읽어와 사용자 식별, 콘텐츠 제공 등을 수행할 수 있게 된다.
Cookie의 종류
- HTTP response message의 header line에 Cookie
- HTTP request message의 header line에 Cookie
- user의 host, user의 browser에 의해 관리되는 Cookie
- 웹사이트 백엔드 데이터베이스 상에 있는 Cookie
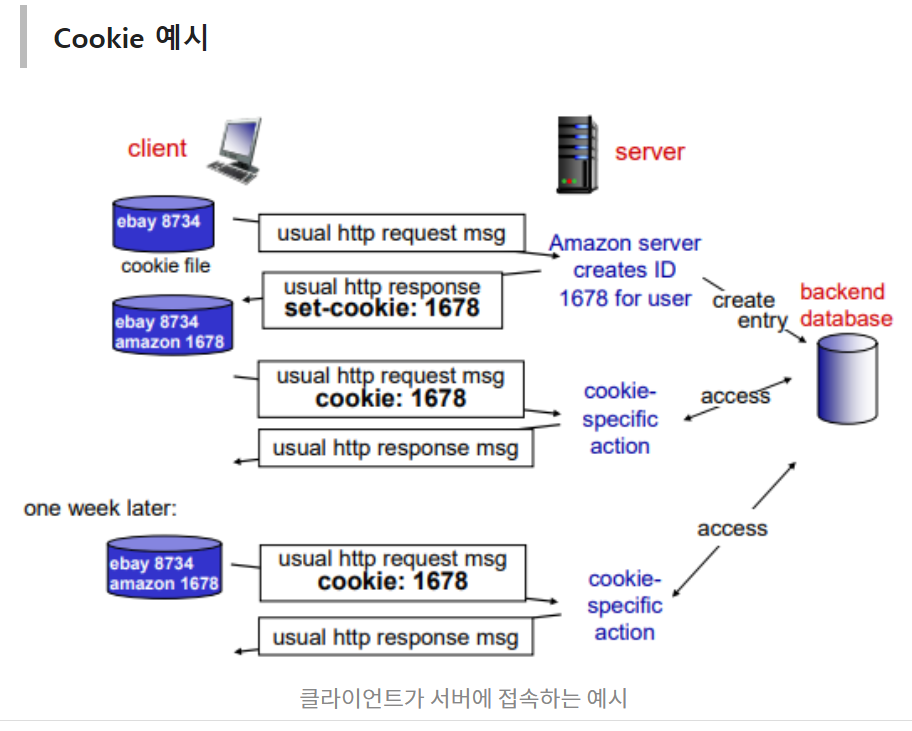
위 그림을 보몀 Cookie의 state가 어떻게 유지되는지에 대해 주목해보자.
- client가 Amazon server로 request msg를 보냄
- Amazon server에서 user ID(1678)를 생성하고, 데이터베이스에 기입하고 response 데이터에 담아서 보냄. (response Cookie(1))
- client는 자체 웹에서 amazon 1678이라는 Cookie 파일 생성 (user brower Cookie(3))
- 다시 접속할때 Cookie가 있으므로 request에 Cookie 파일을 담아서 보냄. (request Cookie(2))
- server는 Cookie가 있다는 신호를 받고, 데이터베이스에서 Client의 정보를 꺼내 보내줌. (back end database Cookie(4))
- client는 지난번에 했던 행동들을 다시 확인 및 수행
요약하자면Client에 Cookie 파일이 없으면 server에서 user ID 만들고 response msg에 Cookie 파일에 담아 보내준다. 그리고 이 user ID는 백엔드 데이터베이스에 기입한다.
Client에 Cookie 파일이 있으면 request msg에 Cookie 파일을 함께 보내고, server의 백엔드 데이터베이스에서 user의 state에 해당하는 response msg를 보내준다.
여기서 알아야 할 것은, HTTP가 Cookie(state)를 전달해준다고 해서 HTTP가 state를 가지고 있는 것은 아니다. state를 가지고 있는 것은 Cookie이고, HTTP는 양쪽의 end points에서 상호보관하고 있는 Cookie(state)를 전달만 해준다는 것을 기억해야 한다.
<쿠키 구성 요소>
- 이름
각각의 쿠키를 구별하는 데 사용되는 이름 - 값
쿠키가 갖고 있는 값 - 유효시간
쿠키의 유지시간 - 도메인
쿠키를 전송할 도메인
(도메인(domain) 주소: 온라인상 위치를 나타내는 인터넷 프로토콜(IP)에 접근하기 위한 주소) - 경로
쿠키를 전송할 요청 경로
<쿠키 동작 방식>
- 클라이언트가 요청을 보냄
- 서버에서 쿠키를 생성
- HTTP 헤더에 쿠키를 포함시켜 응답
- 브라우저가 종료되어도 쿠키 만료 기간이 있다면 클라이언트에서 보관하고 있음
- 쿠키가 존재하면 요청을 할 경우 HTTP 헤더에 쿠키를 함께 보내서 요청한다.
- 서버에서 쿠키를 읽어 이전 상태 정보를 변경할 필요가 있는 경우, 쿠키를 업데이트 하여 변경된 쿠리를 HTTP 헤더에 포함시켜 응답한다.
<쿠키 사용 예시>
- 방문 사이트에서 로그인 시 "아이디와 비밀번호를 저장하시겠습니까?"
- 쇼핑몰의 장바구니 기능
세션
세션은 쿠키를 기반으로 하고 있지만, 사용자 정보 파일을 브라우저에 저장하는 쿠키와 달리 세션은 서버 측에서 관리한다. 서버에서는 클라이언트를 구분하기 위해 세션 ID를 부여하며 웹 브라우저가 서버에 접속해서 브라우저를 종료할 때까지 인증상태를 유지한다. 물론 접속 시간에 제한을 두어 일정 시간 응답이 없다면 세션을 끊도록 설정이 가능 하다. 사용자에 대한 정보를 서버에 저장하기 때문에 쿠키보다 보안에 좋지만, 사용자가 많아질수록 서버 메모리를 많이 차지하게 된다. 즉, 동접자 수가 많은 웹 사이트인 경우 서버에 과부하를 주게 되므로 성능 저하의 요인이 된다.
※ 쿠키와 세션의 차이
쿠키와 세션은 비슷한 역할을 하며, 동작원리도 비슷하다.그 이유는 세션도 결국 쿠키를 사용하기 때문이다. 가장 큰 차이점은 사용자의 기록 정보가 저장되는 위치이다. 쿠키는 서버의 자원을 전혀 사용하지 않으며, 세션은 서버의 자원을 사용을 한다. 보안 면에서는 세션이 더 우수하며, 요청 속도는 쿠키가 세션보다 더 빠른데, 그 이유는 세션의 경우 서버에서의 처리가 필요하기 때문이다.
<세션의 흐름>
1. 클라이언트가 첫번째 최초 요청을 했을 때 서버는 목록에다가 카드를 하나만들어 두고(이는 위조 방지를 위해 만드는 거임) 그 카드를 html을 던져줄 때 header 부분에다가 담아서 웹브라우저(클라이언트)에 보낸다. 웹브라우저는 내부에 받았던 카드를 지니고 있다가(자동으로 저장이 됨, http프로토콜이기 때문에)
2. 두번째로 요청을 할 때 웹브라우저에 저장하고 있던 카드를 들고 간다. 서버는 그 카드가 목록에 있는지를 확인한다.(없으면 새로운 카드를 만든다.) 카으가 있으면 "너 이전에 온 적이 있구나."라고 서버가 인지하게 됨.(이 카드가 세션 id이다.) 이후 3번째, 4번쨰 요청때마다 계속 웹브라우저에 저정된 세션 id를 가져간다.
<세션 id가 사라지는 상황>
- 서버에서 세션의 값을 날렸을 때(제거) -> 목록에서 해당 세션 id를 강제로 제거
- 사용자가 브라우저를 다 종료시켰을 때(브라우저를 다 종료시키면 웹브라우저가 들고 있던 세션 id값이 날라가게 됨)
ㄴ> 그러면 브라우저에서는 세션 id가 날라가서 없어졌지만 서버에는 남아있게 된다. (브라우저를 다 종료하고(닫고) 다시 요청을 보내면 서버는새로운 세션 id값을 만들어준다.)(그래서 서버가 특정 시간(보통 30분)동안 해당 세션 id로 요청이 없으면 알아서 세션 id값을 날려버린다.) - 특정 시간(보통 30분)이 지나면 서버쪽의 세션 id값이 사라지게 된다.
<세션 동작 방식(로그인 할 떄)>
- 클라이언트가 최초로 리퀘스트를 한다.
- 요청을 받은 서버는 세션이라는 저장소에 세션 id를 하나 만든다. 그러면 세션 id를 들고있는 조그만 저장소가 하나 생긴다.(세션의 전체 저장공간은 매우 크다.) - 다른 사용자의 요청도 받아야되기 때문
- 이후 다시 웹브라우저에 응답을 해줄 때 헤더에 세션 id를 넣어서 돌려준다.
- 그러면 클라이언트 쪽 웹브라우저에 세션 id가 저장이 된다.
- (가정)이후 클라이언트 쪽에서 서버로 로그인 요청을 보낸다고 가정(아이디와 비번을 보냄(클라이언트 쪽에서))
- 그러면 서버는 데이터베이스에서 클라이언트에서 보낸 아이디와 비번이 있는지 확인한다.
- (만약 정상적으로 DB에 저장되어 있는 값이 들어왔다면) 세션 쪽에 세션 id 밑에 만들어놓은 조그만 저장소에 지금 클라이언트 쪽에서 로그인 요청을 한 유저의 정보를 저장을 한다.(이 정보는 DB에 있는 로그인 요청을 한 유저의 유저정보이다.) (이후 로그인이 성공을 하면 메인페이지로 리턴을 해준다.(html파일))
- (가정) 이후 클라이언트 쪽에서 유저 정보를 요청을 했다면 서버는 이 사람이 지금 유저 정보에 접근을 하는거니까 세션id가 있는지 확인하고
해당 세션id가 세션에 있는지 확인하고 유저정보 요청을 했으므로 밑의 저장소(7번에서 만들어진 저장소)에 유저의 정보가 있는지도 확인한다. - 만약 유저정보까지 정상적으로 확인했다면 DB에서 사용자가 요청한 데이터를 응답 받는다.
- 응답을 받은 뒤 이를 서버가 다시 웹브라우저로 돌려준다.
(이거 반복)
세선의 단점
서버를 여러개 만들어 놨을 때 클라이언트가 접근 할 때 로드 밸런싱이 일어난다면 서버의 세션의 정보는 각가 다르기 때문에 클라이언트 입장에서는 로그인을 여러번 해야하는 상황이 생길 수가 있다. 그럼 이 단점을 해결할 방법은 없을까?
<이를 해결하는 방법>
1. Sticky 서버를 만들어서 해결 (클라이언트가 최초의 요청을 할 때 동작했던 서버로만 요청을 계속하도록 만드는 방법)
2. 각 서버의 세션을 복제를 시킴(새로운 데이터가 만들어 질 때 마다 복제)
(1,2번 둘 다 귀찮은 짓이고 효율적이지 않다.)
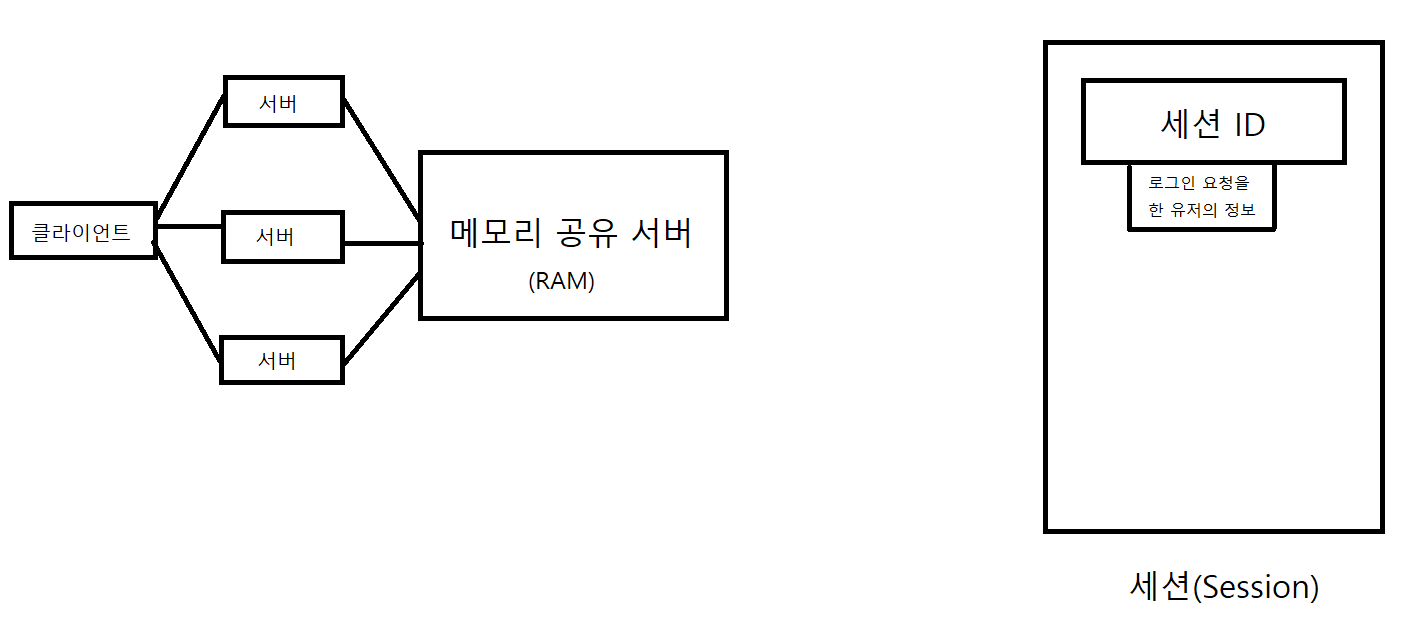
3. 각 서버들이 세션에다가 정보를 저장하는 것이 아니라 이 서버들이 데이터베이스에 세션 값을 넣고 이를 공유해서 쓰는 방법
(단점: 세션이라는 거는 원래 서버가 들고 있는건데 이 방법은 메모리에 접근해서 데이터를 들고 오는 방식이라 엄청나게 빠른데 이 세션 값을
데이터베이스에 넣는다면 IO가 일어나서 데이터를 하드디스크에서 찾아야한다. 그러면 엄청나게 느려진다.)
원래 CPU가 어떤 데이터가 필요할 때 RAM으로 먼저가서(하드디스크에서 찾으면 너무 오래걸리기 때문에) 데이터가 있는지 확인을 하고 없으면 하드디스크로 가서 찾고자 하는 데이터를 찾는다. 만약 RAM에서 못 찾은 데이터를 하드디스크에서 찾았다면 하드디스크에서 찾은 데이터를 RAM에다가 넣고 CPU한테 줘서 데이터를 처리함. 이후 만약 똑같은 데이터를 요청한다면 이때는 하드디스크에서 찾는게 아니라 RAM에서 찾아서 CPU에서 데이터를 줘서 처리를 하게 된다. 이를 캐싱이라고 한다. (그래서 첫번째 요청은 IO가 일어나서 하드디스크까지 데이터를 찾으러 갔다가 와서 시간이 오래걸리지만 두번째 요청은 RAM에서 데이터를 찾아 CPU로 주기 때문에 엄청 빠르다. 그리고 두번째 요청 때는 IO가 일어나지 않는다.) (하드디스크에 접근했다는 건 IO가 일어났다는 것이고 IO가 일어나는 순간 속도가 100만배정도가 느려진다.) (RAM에 접근하면 전기적 신호로 데이터에 접근하는 것이기 때문에 랜덤 Access가 발생하지 않는다. 원하는 위치로 다이렉트하게 접근이 가능하다. 하지만 하드디스크에 접근할 때는 하드디스크에 있는 데이터에는 다이렉트하게 접근이 불가는하다. 왜냐하면 하드디스크에서 데이터를 찾을 떄 하드디스크는 원판모양으로 생겼는데
액츄에이터라는 침과 디스크 원판이 돌면서 데이터를 일일히 찾는(정확한건 찾아보기) 그래서 대부분 하드디스크에 있는 데이터는 풀스캔을 하게
된다. 그래서 IO가 일어나면 굉장히 느려진다.)
3번은 데이터베이스에 데이터를 넣으면 IO가 일어나기 때문에 데이터를 찾는데 굉장히 오랜 시간이 걸리게 된다.
(※ 1,2,3번 모두 해결할 수는 있는 방법들이지만 효율적이지는 않다.)
4. 그래서 보통 메모리 서버를 쓴다. (왜냐면 메모리(공유)서버를 쓰면 IO가 일어나지 않으므로) (메모리 서버는 RAM만 존재, 하드디스크 존재 X) (전기적 신호로 접근하여 다이렉트하게 데이터를 찾아옴) 이 방법으로는 서버들이 메모리 서버에 세션 값을 저장해놓고 같이 공유해서 사용하면 된다. 그러면 위의 문제들이 발생하지 않는다. (대표적인 예: Redis서버)
토큰을 사용하는 OAuth, JWT
쿠키와 세션의 문제점들을 보완하기 위해 토큰(Token)기반의 인증 방식이 도입되었다. 토큰 기반의 인증 방식의 핵심은 보호할 데이터를 토큰으로 치환하여 원본 데이터 대신 토큰을 사용하는 것이다. 그래서 중간에 공격자로부터 토큰이 탈취당하더라도 데이터에 대한 정보를 알 수 없으므로, 보안성을 높은 기술이다. 대표적으로는 OAuth와 JWT이 있습니다. 나중에 더 자세히 다뤄보겠다.
HTTP Method
클라이언트가 서버로 요청을 할 때, 어떠한 목적을 갖는 행위인지 HTTP 메서드에 명시해야한다.(GET, HEAD, PUT, POST, DELETE, TRACE, OPTIONS)
GET
서버에게 리소스를 달라는 요청 (조회)
HEAD
HTTP HEAD 메서드는 특정 리소스를 GET 메서드로 요청했을 때 돌아올 헤더를 요청한다. HEAD 메서드에 대한 응답은 본문을 가져선 안되며, 본문이 존재하더라도 무시해야한다. 그러나, Content-Length처럼 본문 콘텐츠를 설명하는 개체 헤더는 포함할 수 있는데 이 때 개체 헤더는 비어있어야 하는 HEAD의 본문과는 관련이 없고 GET 메서드로 동일한 리소스를 요청했을 때의 본문을 설명한다.
PUT
서버가 요청의 본문을 갖고 요청 URI의 이름대로 새 문서를 만들거나, 이미 URI가 존재한다면 요청 본문을 변경할 때 사용한다.(수정)
POST
서버에 입력데이터를 전송하며 요청 엔티티 본문에 데이터를 넣어 서버에 전송한다.(삽입)
DELETE
서버에서 요청 URI 리소스를 삭제하도록 요청합니다.(삭제) 클라이언트는 항상 삭제된다고 생각하지만, 서버에서는 이 요청을 무시할 수도 있다.
TRACE
클라이언트와 목적지 서버 사이에 있는 모든 HTTP 애플리케이션의 요청/응답 연쇄를 따라가면서 자신이 보낸 메시지의 이상 유무를 파악한다. 서버는 응답 메시지의 본문에 자신이 받은 요청메시지를 넣어 응답하며, 주로 진단을 위해 사용한다.
OPTIONS
서버에게 특정 리소스가 어떤 메소드를 지원하는지 물어볼 수 있다.
HTTP connections
HTTP connection은 두가지가 있다.
1. non-persistent HTTP
TCP connection에 한 오브젝트만 보내고 connection을 닫아버린다. web 브라우저 띄울 때마다 connection을 열고 닫고 하는것이다.
2. persistent HTTP
TCP connection을 하나 열고, 복수개의 objects가 전달하고, 전달이 끝나면 connection을 닫는다.
Non-persistent HTTP

위의 사진 순서를 보면
위와 같은 URL을 들어간다고 가정해보자.
1a. HTTP client가 HTTP server한테(process) TCP connection을 요청한다(www.comeSchool.edu로 port 번호 80으로).
1b. HTTP 서버는 www.someSchool.edu(port 번호 80으로)로 TCP connection을 요청한 HTTP 클라이언트에게 요청을 잘 받았다고 메세지를 통해 알려준다.
-
HTTP 클라이언트는 HTTP request 메시지(URL을 포함하여)를 TCP 연결 소켓으로 보냅니다. 이 요청 메세지는 HTTP 클라이언트가 웹 페이지 클릭에 해당하는 주소(someDepartment/home.index(path name))이라는 object를 원한다는 것을 알려준다.
-
HTTP 서버는 HTTP 클라이언트가 보낸 요청 메세지를 수신하고 요청받은 object(someDepartment/home.index(path name))를 포함하는 response 메세지를 만들어서 소켓으로 보낸다.(해당하는 데이터 or 에러 메시지)
-
하나 주고 받았으니 HTTP server는 TCP connection 닫음
-
HTTP 클라이언트는 response 메세지를 포함하는 html 파일을 받고 클릭에 해당하는 html 웹 페이지가 보여지게 된다. html 파일을 파싱하면서 10개의 referenced된 jpeg object 보게 된다. (HTTP client는 닫았다는 소식 받고, 클릭에 해당하는 것을 display)
-
1~5번 과정 반복
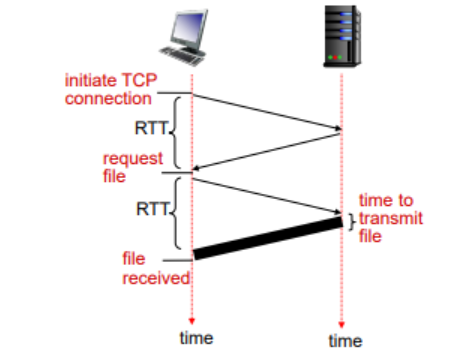
RTT (Round Trip Time) : 메시지가 갔다가 온데까지 시간.
하나의 TCP connection을 만드는데 하나의 RTT를 소요한다. HTTP 보내고 response 받는데 걸리는 시간으로 또 RTT 하나 소요한다. 위의 굵은 선은 transmission time이다.
결론은, 2RTT + transmission time이 걸린다.
Persistent HTTP
Non-persistent HTTP에서는 하나의 데이터를 주고 받으려면 2RTT + transmission delay만큼의 delay가 생긴다. 두배 정도 오래걸리는 것이다. 이 문제를 해결하기 위해 Persistent HTTP가 등장했다. Persistent HTTP는 server가 하나의 response를 보내도, connection을 열어놓는다. 그리고 일정시간동안 데이터가 오지 않으면 connection을 닫는다. 이렇게 처음 데이터에 대해서 connection을 열고, 바로 닫지 않기 때문에 여러 개의 데이터를 받아도 delay time이 Non-persistent HTTP보다 짧아지는 것이다.
예시)
만약 10개의 objects를 주고 받는다하면 delay time은
1RTT(connection) + 10RTT(objects) + 10 transmission time이 될 것이다.
HTTP request, response
requset
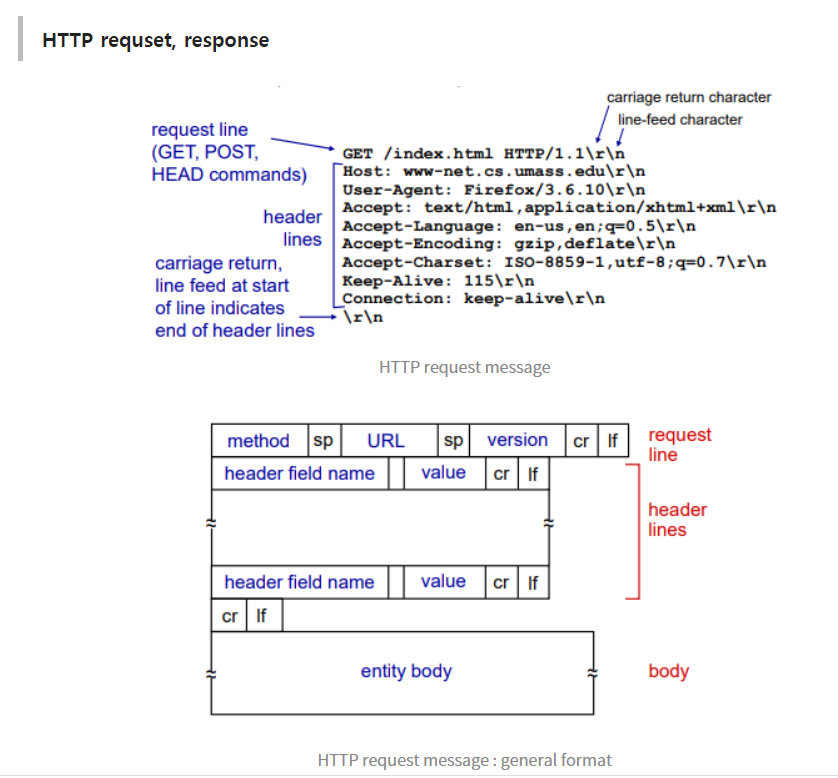
- header : body를 전달하는데 필요한 값. 버전이 뭐고, URL이 뭐고 등등
- body : 진짜 전달하는 내용물
<클라이언트가 request를 보내는 방법>
1. POST 방식
web 페이지 자체가 input을 가지고 있다. input이 body 내에 들어와서 보내진다. 내가 무언가를 request할 때, 구체적인 내용이 body부분으로 들어가는 방식이다.
2. URL 방식
GET Method 사용. input이 request line 안에 URL field에 찍혀있다.
response
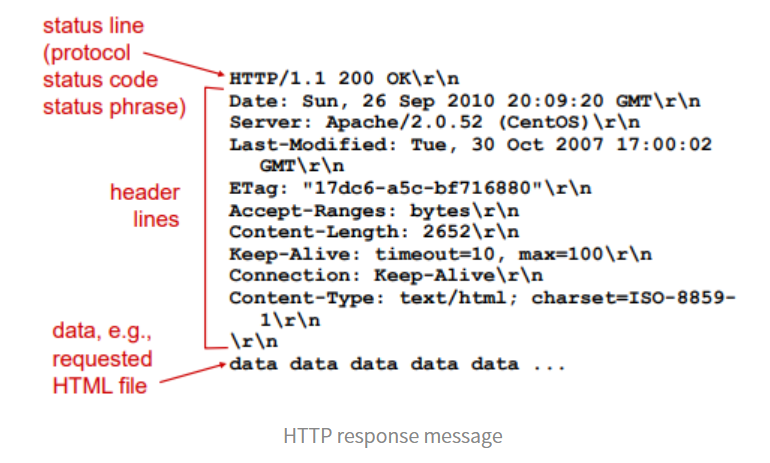
HTTP response status codes
200 OK : 성공했다.
301 Moved Permanently : 요청된 오브젝트가 서버의 로케이션에서 사라졌다(옮겨졌다).
400 Bad Request : 서버가 이해할 수 없는 request가 왔다.
404 Not Found : 서버에 request에 해당하는 것이 없다.
505 HTTP Version Not Supported : HTTP의 버전이 안 맞다. (오래된 프로토콜을 전부 지원해주므로 보기 힘들 것이다.)
