역정규화를 통한 쿼리 효율성 향상
들어가면서
커머스 애플리케이션에서 상품 주문 및 결제는 핵심 비즈니스 로직 중 하나입니다. 특정 사용자가 상품을 주문한 뒤에는 결제 과정이 진행되며, 이를 위해서는 사용자가 주문한 상품들의 총 가격을 파악해야 합니다.
총 주문 금액은 상품의 가격, 주문한 수량 등의 정보를 기반으로 계산됩니다. (상품 가격 * 주문수량)
일반적으로 테이블을 설계할 때, 데이터의 중복을 피하고 데이터 일관성을 유지하기 위해 데이터를 여러 테이블로 나누게 됩니다. 이를 정규화라고 합니다.
저 역시 프로젝트 데이터모델링 과정에서 테이블정규화 작업을 진행하였습니다. 하지만 이 과정에서 비효율적인 쿼리가 발생했고 애플리케이션 성능에 부정적인 영향을 미쳤습니다.
먼저 테이블이 정규화된 상황을 보여드리고, 이런 상황에서 얼마나 비효율적인 쿼리가 생성되는지 설명드리겠습니다.
아래는 역정규화가 적용되지 않은 상태의 데이터베이스 테이블입니다.
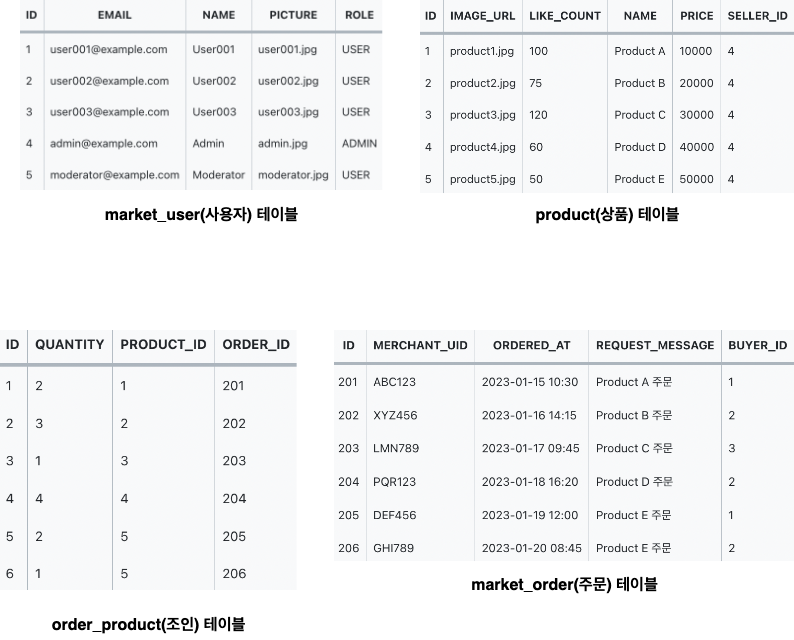
여기서
order_product테이블은 주문테이블과 상품테이블의 N:M 관계를 풀어내기 위한 조인테이블 역할을 수행합니다.
특정 사용자의 총 주문 금액 조회 과정
만약 1번 사용자(user_id = 1)가 상품을 주문하면 다음과 같은 비즈니스 로직이 수행되어야 합니다. 이 과정은 "market_order(주문)" 테이블과 "order_product(조인)" 테이블의 정보를 사용하여 수행됩니다.
-
1번 사용자의 주문 정보를 찾습니다. "order" 테이블에서 BUYER_ID가 1인 모든 주문을 검색합니다.
-
1번 사용자의 주문은 주문 ID 201 (Product A 주문)와 주문 ID 205 (Product E 주문)입니다.
각 주문의 상품 정보를 찾습니다. "order_product" 테이블에서 주문 ID(ORDER_ID)가 201 및 205인 주문된 상품 정보를 검색합니다. -
주문 ID 201에는 "Product A" (상품 ID 1)가 주문되었으며 수량은 2개입니다.
주문 ID 205에는 "Product E" (상품 ID 5)가 주문되었으며 수량은 2개입니다.
각 주문의 총 주문 금액을 계산합니다.
각 주문의 총 주문 금액은 해당 상품의 가격(PRICE)과 수량(QUANTITY)을 곱하여 계산됩니다. -
Product A 주문의 총 금액: (10000원 2개) = 20,000원
Product E 주문의 총 금액: (50000원 2개) = 100,000원
모든 주문의 총 주문 금액을 합산하여 1번 사용자의 총 주문 금액을 계산합니다. -
1번 사용자의 총 주문 금액: 20,000원 (Product A 주문) + 100,000원 (Product E 주문) = 120,000원
따라서, 1번 사용자(user_id = 1)의 총 주문 금액은 120,000원입니다.
쿼리
이 과정은 모두 비즈니스 로직으로 처리되며, 실제로는 JPA의 방언을 이용해 SQL 쿼리가 생성됩니다. 그러나 명확한 설명을 위해 직접 SQL 쿼리를 작성하여 설명드리겠습니다.
SELECT
SUM(p.PRICE * op.QUANTITY) AS TOTAL_PRICE
FROM
market_order mo
INNER JOIN order_product op ON mo.ID = op.ORDER_ID
INNER JOIN product p ON op.PRODUCT_ID = p.ID
WHERE
mo.BUYER_ID = 1;해당 쿼리의 동작은 아래와 같습니다.
-
"market_order" 테이블과 "order_product" 테이블을 조인하여 주문 정보와 주문된 상품 정보를 연결합니다.
-
"order_product" 테이블과 "product" 테이블을 조인하여 상품의 가격을 가져옵니다.
-
1번 사용자의 주문 정보를 필터링하기 위해 BUYER_ID 조건을 사용합니다.
-
주문된 각 상품의 가격(PRICE)과 수량(QUANTITY)을 곱하여 각 주문의 총 주문 금액을 계산합니다.
-
SUM 함수를 사용하여 모든 주문의 총 주문 금액을 합산하여
TOTAL_PRICE로 반환합니다.
해당 쿼리의 결과로 1번 사용자(user_id = 1)의 총 주문 금액이 반환됩니다.
문제점
이 쿼리는 market_order, order_product, product 세 개의 테이블을 조인하는 작업을 수행합니다. 조인 연산은 데이터베이스에서 비용이 많이 드는 작업 중 하나이며, 특히 대량의 데이터를 처리할 때 성능 저하의 원인이 될 수 있습니다. 결제 요청마다 해당 사용자의 total_price를 계산하는 쿼리가 실행된다면 애플리케이션의 성능에 부정적인 영향을 미칠 수 있다고 생각했습니다.
역정규화를 통해 문제해결
주문 데이터 생성 단계에서 총 주문 가격을 사전에 계산하고 이를 주문 테이블의 order_price 컬럼에 별도로 저장했습니다. 이러한 작업을 역정규화라고 합니다.
역정규화는 애플리케이션 성능을 향상시키기 위해 정규화된 데이터를 풀어서 데이터베이스 작업을 최적화하고 응용 프로그램이 데이터를 보다 효과적으로 검색하고 처리할 수 있도록 하는 전략입니다.
정규화된 테이브를을 풀어 역정규화를 진행한 테이블 정보는 아래와 같습니다.
| ID | MERCHANT_UID | ORDERED_AT | REQUEST_MESSAGE | BUYER_ID | TOTAL_PRICE |
|---|---|---|---|---|---|
| 201 | ABC123 | 2023-01-15 10:30:00 | Product A 주문 | 1 | 20000 |
| 202 | XYZ456 | 2023-01-16 14:15:00 | Product B 주문 | 2 | 60000 |
| 203 | LMN789 | 2023-01-17 09:45:00 | Product C 주문 | 3 | 30000 |
| 204 | PQR123 | 2023-01-18 16:20:00 | Product D 주문 | 2 | 160000 |
| 205 | DEF456 | 2023-01-19 12:00:00 | Product E 주문 | 1 | 100000 |
| 206 | GHI789 | 2023-01-20 08:45:00 | Product E 주문 | 2 | 50000 |
주문 데이터를 역정규화하고 TOTAL_PRICE 컬럼을 주문 테이블에 추가하면, 주문 데이터의 총 주문 금액을 계산하기 위한 추가적인 쿼리가 필요하지 않습니다. 이미 주문 테이블의 각 레코드에 총 주문 가격이 포함되어 있으므로 별도의 계산이 필요하지 않습니다.
따라서 1번 사용자(buyer_id = 1)의 총 주문 금액을 검색하기 위해 아래와 같은 SQL 쿼리만 실행하면 됩니다. 결과적으로 조인 연산을 피함으로써 쿼리 성능을 향상시킬 수 있습니다.
SELECT * FROM market_order WHERE seller_id = 1비즈니스 로직
BigDecimal orderPrice = orderProductList.stream()
.map(OrderProduct::getTotalPrice)
.reduce(BigDecimal.ZERO, BigDecimal::add);위와 같이 주문 데이터를 생성하는 과정(비즈니스 로직)에서 totalPrice를 계산하여 주문 가격을 설정하고 데이터베이스에 저장합니다. 이렇게 함으로써 결제가 요청될 때 추가로 데이터베이스 쿼리를 실행하지 않고도 주문 가격을 효율적으로 관리할 수 있게 되었습니다.
전체 코드는 여기에서 확인해주시면 감사하겠습니다.
느낀점
역정규화를 통해 데이터를 효과적으로 구조화하여 성능을 향상시킬 수 있다는 것을 깨달았습니다. 데이터베이스 성능은 응용 프로그램에 직접 영향을 미치므로, 데이터베이스 설계 단계에서 성능 최적화를 고려하는 것이 중요하다고 생각합니다.
하지만 역정규화는 쿼리 성능을 향상시키는 대신 데이터 중복을 허용하기 때문에 데이터 일관성이 손상될 수 있습니다. 따라서 역정규화를 적용하기로 결정할 때는 프로젝트 요구 사항을 종합적으로 고려해야 합니다. 어떤 데이터베이스는 읽기 중심이며 빠른 응답 시간이 필요한 경우에는 역정규화가 유용할 수 있지만, 데이터 일관성을 우선시해야 하는 경우에는 역정규화보다 정규화가 더 적합할 것입니다.
결과적으로 역정규화는 데이터베이스 설계에서 성능 최적화를 위한 강력한 도구로 활용할 수 있지만, 데이터 일관성에 주의해야 합니다. 앞으로도 데이터 모델링과 성능 간의 트레이드오프를 고려하여 애플리케이션을 개발하는 데 노력하겠습니다.
