쿼리튜닝 통해 쿼리 조회 속도 개선하기
1000만 건의 데이터 삽입
대용량의 데이터를 다루는 환경을 구성하기 위해 Python의 Faker 라이브러리를 사용했습니다.
import random
from faker import Faker
import mysql.connector
def insert_data_to_db(data_list, db_config):
conn = mysql.connector.connect(**db_config)
cursor = conn.cursor()
# 데이터 삽입
insert_query = f"INSERT INTO market_order (merchant_uid, order_price, ordered_at, buyer_id) " \
f"VALUES (%s, %s, %s, %s)"
cursor.executemany(insert_query, data_list)
# 변경사항 저장
conn.commit()
# 연결 종료
conn.close()
if __name__ == "__main__":
# Faker 객체 생성
fake = Faker()
# 10만개의 데이터를 저장할 리스트 생성
data_list = []
db_config = {
'host': 'localhost',
'port': 3306,
'user': 'root',
'password': '',
'database': 'market'
}
cnt = 0
for _ in range(11000000):
if len(data_list) % 5000 == 0:
insert_data_to_db(data_list, db_config)
print(data_list)
data_list = []
# merchant_uid, order_price, ordered_at, buyer_id 데이터 생성
merchant_uid = fake.uuid4()
order_price = round(random.uniform(10.0, 500.0), 2)
ordered_at = fake.date_time_this_year()
buyer_id = 1
# 데이터를 리스트에 추가
data_list.append((merchant_uid, order_price, ordered_at, buyer_id))
cnt += 1데이터 생성 부분:
fake.uuid4(): UUID 형식의 가짜 고유 식별자 생성.round(random.uniform(10.0, 500.0), 2): 10.0부터 500.0 사이의 난수를 생성하고 소수점 둘째 자리까지 반올림.
fake.date_time_this_year(): 올해 내에서 랜덤한 날짜와 시간 생성.buyer_id: 요청을 보내는 사용자 PK는 1로 고정.대략 1000만 건의 주문 데이터를 랜덤으로 생성하였습니다.
병목지점
문제상황
- 1000만 건의 데이터에 대한 날짜 검색 로직 수행시 OOM 에러가 발생하는 문제
- 100만건의 데이터에 대한 날짜 검색 로직 수행 시 약 23초의 수행시간이 걸리는 문제
요청을 받았을때 수행되는 비즈니스 로직
getOrderByDate(): 날짜 범위의 검색 결과(contents) -> 10개씩 페이징 처리해서 리턴countOrderByDate(): 날짜 범위 검색 결과의 총 개수(totalElements) -> 페이징 처리를 위해 필요
@GetMapping
public PageResponseDto<OrderGetResponseDto> getOrderDateRange(@RequestParam String startDate, @RequestParam String endDate, @RequestParam int page, @RequestParam int size) {
String email = authorizationHelper.getPrincipalEmail();
List<OrderGetResponseDto> contents = orderService.getOrderByDate(email, startDate, endDate, page, size)
.stream()
.map(Order::toOrderGetResponseDto)
.collect(Collectors.toList());
long totalElements = orderService.countOrderByDate(email, startDate, endDate);
return PageResponseDto.<OrderGetResponseDto>builder()
.size(size)
.page(page)
.content(contents)
.totalElements(totalElements)
.build();
}예상되는 병목지점
컨텐츠를 조회하는
getOrderByDate()10개씩 페이징처리 한 뒤 결과를 반환한다.
따라서countOrderByDate()메서드에서 병목이 발생할 것이다.
페이징 처리를 위해 조건의 결과를 모두 조회하는 countOrderByDate() 메서드의 관심사를 분석해 보았습니다.
각각의 관심사에 로그 남겨 수행시간을 비교해 보았습니다.
@Transactional(readOnly = true)
public long countOrderByDate(String email, String startDate, String endDate) {
log.info("Start countOrderByDate.");
// ---------- 관심사1: String을 LocalDateTime 으로 파싱 ---------- //
long start = System.currentTimeMillis();
LocalDateTime startDateTime = dateUtils.parseDateTime(startDate + "T00:00:00");
LocalDateTime endDateTime = dateUtils.parseDateTime(endDate + "T23:59:59");
log.info("파싱 소요시간: {}", System.currentTimeMillis() - start); // 파싱 소요시간: 0
// ----------- 관심사2: 사용자 검색 --------------//
User foundUser = userService.getUserByEmail(email);
// ------------ 관심사3: 쿼리 수행 --------------//
long startQuery = System.currentTimeMillis();
long result = orderRepository.countOrderBetweenDate(foundUser.getId(), startDateTime, endDateTime);
log.info("쿼리 수행 시간: {}", System.currentTimeMillis() - startQuery); // 쿼리 수행 시간: 22927
return result;
}count쿼리가 수행되는 부분, 즉 SQL 쿼리를 날리는 부분이 병목지점이라는 것을 파악했습니다.
쿼리 튜닝
변경 전
count쿼리를 날리는 로직은 다음과 같습니다.
@Override
public long countOrderBetweenDate(long userId, LocalDateTime startDateTime, LocalDateTime endDateTime) {
return queryFactory
.selectFrom(order)
.where(order.orderedAt.between(startDateTime, endDateTime).and(order.user.id.eq(userId)))
.fetch()
.size();
}fetch() 메서드는 결과를 리스트로 가져오기 때문에 데이터베이스에서 조회한 모든 결과를 리스트에 저장하여 메모리에 로딩합니다. 만약 조회된 데이터가 많다면 메모리 부담이 커질 수 있습니다. 또한 컬렉션에 저장한 뒤 size를 반환하기 때문에 처리 속도 역시 급격하게 늦어진다는 문제가 있었습니다. (100만 건의 데이터 검색 시, 23초 소요)
변경 후
위의 쿼리를 아래와 같이 수정했습니다.
@Override
public long countOrderBetweenDate(long userId, LocalDateTime startDateTime, LocalDateTime endDateTime) {
return queryFactory
.select(order.count())
.from(order)
.where(order.user.id.eq(userId)
.and(order.orderedAt.between(startDateTime, endDateTime)))
.fetchOne();
}집계함수(count())를 사용하여 데이터베이스에서 직접 집계를 fetchOne()을 통해 단일 값을 반환하도록 변경했습니다. 또한 결과를 리스트로 가져오지 않기 때문에 메모리에 부담이 없어집니다. 즉 단일 값만을 반환하기 때문에 메모리를 사용하지 않고 결과를 반환할 수 있습니다. 결과적으로 집계함수를 통해 데이터베이스에서 결과를 바로 계산하므로, 불필요한 계산 및 메모리 로딩이 제거하고 성능을 향상시킬 수 있었습니다. (23초 에서 3초로 개선)
결과 비교
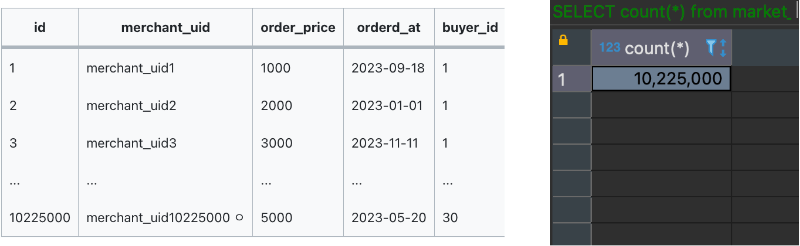
주문 테이블에는 약 1000만 건의 데이터가 있으며, 주문날짜는 2023-01-01 ~ 2023-12-31의 범위입니다.
해당 서비스에 올해 몇 건의 주문이 발생했는지 파악하기 위해 count 쿼리를 실행 시켜보았습니다.
튜닝 전 코드에 요청

1000만 건 이상의 데이터를 모두 리스트에 로드하기 때문에 heap space에 OOM이 발생했습니다. (3분 이상 수행)
튜닝 이후 코드에 요청

튜닝 이후 1000만 건의 데이터를 조회하는데 걸린 시간은 23초입니다.
배운점
Timeout 설정
대용량 데이터를 다루는 상황을 모의하여 임의의 데이터를 삽입하여 테스트를 수행했습니다. 대량의 데이터를 다루다 보니, 초기 개발 단계에서는 고려하지 못한 문제들이 나타났습니다. 이러한 문제들을 해결하고자 노력함으로써 데이터베이스 조회 속도의 중요성을 몸소 체감할 수 있었습니다. 특히 OOM과 같이 개발 단계에서 예상하지 못했던 에러로 인해 생기는 문제를 방지하기 위해서는 Timeout 시간을 적절하게 설정해야 한다는 것을 깨달았습니다.
함수를 사용하면 옵티마이저가 컬럼 정보를 분석하지 못한다.
함수를 사용하는 쿼리
SELECT count(*) FROM market_order
WHERE DATE_FORMAT(ordered_at, '%Y%m%d') > '20231101'
AND DATE_FORMAT(ordered_at, '%Y%m%d') < '20231201'; 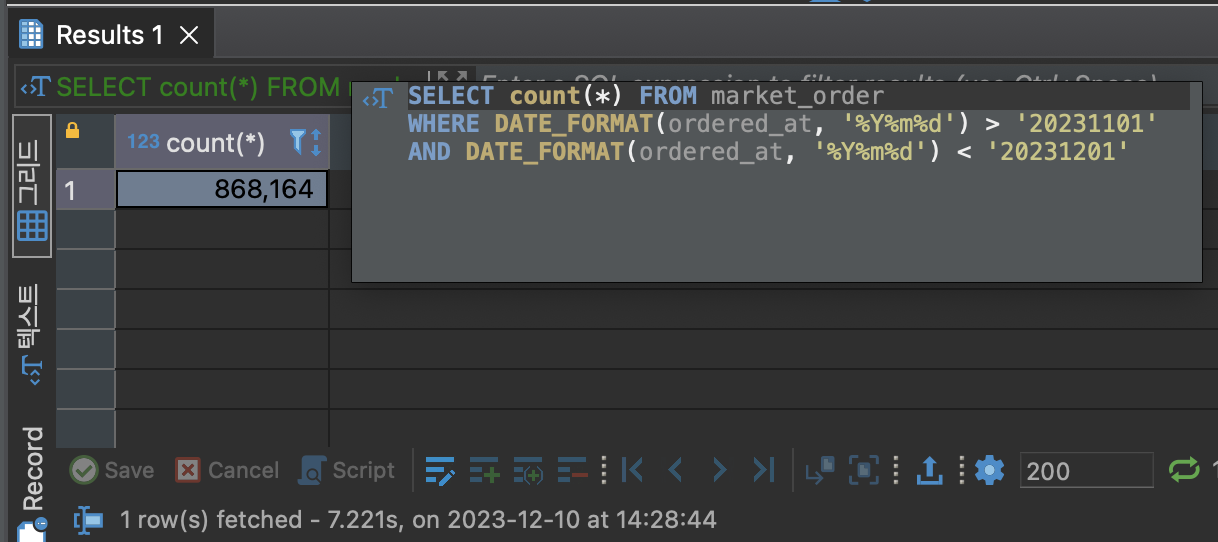
- 함수 사용시 테이블 풀스캔이 발생하여, 수행시간이 7초가 걸린다.
위와 같이 쿼리를 작서하면 어떤 목적의 쿼리인지 쉽게 알아 볼 수 있습니다. 하지만 인덱스가 설정 되어 있더라도 테이블 풀스캔이 수행된다는 문제가 있습니다. 옵티마이저는 컬럼의 분포도를 기준으로 데이터를 추출하는 가장 빠른 방법을 도출합니다. 하지만 위의 쿼리와 같이 market_order DATE_FORMAT 함수를 사용하면 옵티마이저는 market_order와 연관된 데이터 분포도를 알 수 없게 됩니다. 함수로 인해 변경될 결과값을 옵티마이저가 예상하지 못하기 때문입니다. 즉 성능이 크게 떨어지는 문제가 발생합니다.
함수를 사용하지 않도록 쿼리를 변경
SELECT count(*) FROM market_order
WHERE ordered_at BETWEEN '2023-11-01' AND '2023-12-01';- 옵티마이저가 컬럼의 분포도를 분석하여 인덱스를 타고, 수행시간이 400ms로 감소했습니다.
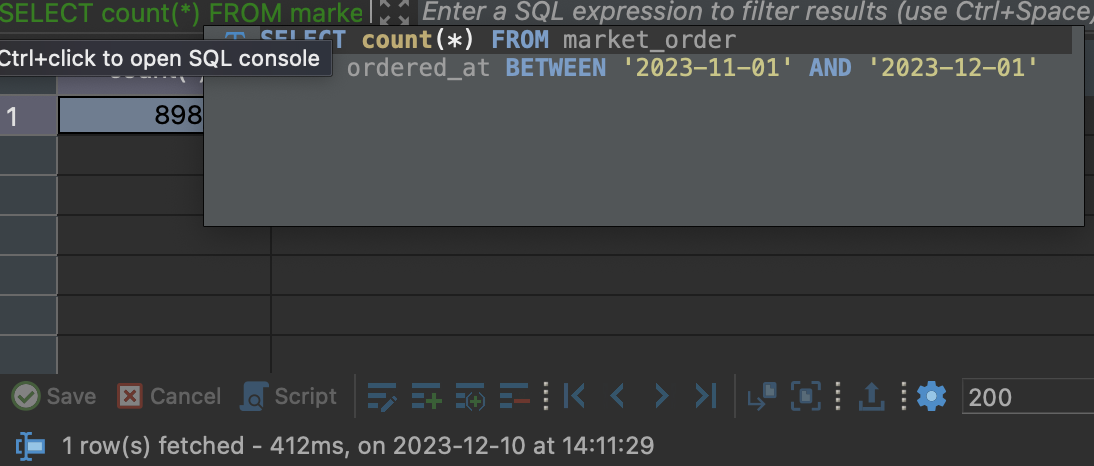
불필요한 함수를 없애고 원하는 시간 사잇값만 검색하도록 쿼리를 튜닝했습니다. market_order에 B-tree 인덱스가 설정 되어 있기 때문에, 옵티마이저가 검색을 효율적으로 할 수 있고 범위 검색에서 데이터를 빠르게 가져옵니다.
함수를 사용하면 이해하기 쉬운 쿼리로 풀어 쓸 수 있지만, 이를 DB가 알아듣기 쉽게 변환한다면 불필요한 시스템 부하를 줄일 수 있습니다.
