초간단 구현
간단하게 포스트 디테일 페이지로 유저가 접근할 때마다 포스트의 조회수를 1씩 늘려주는 방법이 있다.
def get(self, request, *args, **kwargs):
team_id = kwargs.get("team_id")
try:
team = Team.objects.get(id=team_id)
team.view += 1
team.save()
teamSerializer = TeamCreateSerializer(team)
response = createSerializerHelper.make_response(teamSerializer.data, request.user.id)
return Response(response, status=status.HTTP_200_OK)
except Team.DoesNotExist:
return Response({"error": "No Content"}, status=status.HTTP_404_NOT_FOUND)- 문제점
API에 접근할 때마다 조회수를 무조건 올려주게 되어 있으므로 유저가 마음만 먹으면 무한정으로 조회수가 올라간다!
어떻게 해결해볼 수 있을까?
이번에 조회수 기능을 개발하면서 목표는 당일 중복 조회 불가이다.
00시시가 되면 다시 조회수를 집계 해주겠다는 뜻
1. 쿠키에 조회 내역 정보를 담아서 보내준다
예를 들어 id가 1인 유저가 10번, 20번 게시글에 접근했다면
쿠키에 view:1=10|20 같은 방식으로 저장해주는 것이다.
쿠키를 보낼 때, 쿠키의 생명주기를 당일 00시까지로 제한해 발급해주면
다음 날부터는 다시 조회수가 집계된다.
response.set_cookie("view", 조회 내역, expires=내일까지의 시간)이제 쿠키의 유무와 내용만 먼저 확인하면 조회수를 집계할 수 있다.
이 방법에는 문제가 없을까?
쿠키는 클라이언트가 관리할 수 있다.
즉, 쿠키를 의도적으로 삭제할 수 있다는 것.
물론, 지금 개발하고 있는 서비스는 유튜브처럼 조회수가 비즈니스적으로 중요하지 않아 유저가 쿠키를 삭제해서 조회수를 올린다고 큰 문제가 되지는 않지만 쉽게 눈치챌 수 있는 기믹이다.
2. 조회 내역 정보를 DB에 담아두고 서버에서 관리한다
조회하는 유저와 게시글 정보 쌍을 DB에 저장해 조회수 중복을 방지할 수 있다.
user_id와 post_id를 저장하는 테이블이 있다면 가능한 얘기.
하지만 이 방법은 조회의 주체가 비회원이라면 관리가 불가능하다.
비회원의 id를 0으로 간주해 저장하는 방법도 있겠으나 다른 사람이 조회했을 때도 집계가 되지 않을 수 있다.
조회하는 유저의 IP정보를 저장하면 어떻게 될까?
서비스의 특성상 이 서비스는 주로 학교의 동아리 회원들이 학교에서 사용할 가능성이 높다. 즉, 같은 IP로 접근할 가능성이 꽤나 있다는 것.
따라서 user_id와 IP를 조합한 정보를 저장해보도록 하자.
게시글을 조회할 때마다 RDBMS에 I/O를 더 가져가기가 싫어서 이 정보를
redis에 저장해보기로 했다.
redis는 집합 자료형을 제공하므로 SADD 명령을 실행했을 때 반환 값을 통해 중복 여부를 체크하기에 용이하다.
또한 Celery-beat로 스케쥴링해주면 특정 키를 정해진 시간에 삭제해 하루가 지나면 다시 조회수를 카운팅해줄 수도 있다.
Celery란 무엇일까? 링크에 Celery의 개요와 장단점이 잘 설명되어 있다.
로직
조회 관련 정보는 views:team_id 집합에 저장된다.
- 유저가 게시글에 접근하면 redis에 유저id_IP 조합의 밸류값이 있는지 확인한다.
- 존재한다면 -> PASS
오늘 첫 방문이라면 -> views:team_id 집합에 유저id_IP조합을 저장후 조회 수를 +1 해준다. - 매일 자정마다 views:로 시작하는 키를 모두 제거한다.
2번 방법을 통해 한 번 구현해보도록 하자.
우선 Celery를 설치하고, Django 프로젝트에 이식하자.
(redis는 로컬에 설치되어 있거나 docker로 실행되어 있다고 가정한다.)
# Celery 관련 라이브러리 설치
pip install celery django-celery-beat django-celery-results#project_name/settings.py
INSTALLED_APPS = [
# 기존 APP들 +
"celery",
"django_celery_beat",
"django_celery_results",
]
CELERY_BROKER_URL = "redis://127.0.0.1:6379/0"
CELERY_RESULT_BACKEND = "django-db"
CELERY_TIMEZONE = "Asia/Seoul"INSTALLED_APPS에 방금 설치한 내용을 업데이트,
Celery 설정을 추가해준다.
아래의 설정 파일을 따라해 Celery가 장고의 설정을 가져오는 경우에
RESULT_BACKEND를 저렇게 설정해 줄 수 있다.
# django_celery_results 관련 DB를 migrate 해준다.
python manage.py migrate#project_name/celery.py NEW
import os
from celery import Celery
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "#project_name.settings")
app = Celery("#project_name")
app.config_from_object("django.conf:settings", namespace="CELERY")
app.autodiscover_tasks()
@app.task(bind=True)
def debug_task(self):
print(f"Request: {self.request!r}")참고: Windows 환경이라면? 링크를 참고해서 설정을 추가해야한다. 필자도 Windows 환경이었는데 도움을 많이 받았다.
프로젝트 폴더 내에 celery.py 스크립트를 새로 생성한 뒤 위 내용을 적어주자.
위 내용은 장고 프로젝트의 세팅에서 celery세팅을 가져오고 이와 관련된 설정은 CELERY_로 시작한다는 뜻이다. namespace는 입맛대로 커스텀하면 된다.
app.autodiscover_tasks() 함수를 사용하면 각각의 앱 폴더에서 tasks.py 내부에 celery 데코레이터가 붙어있는 task를 모두 찾아서 적용할 수 있다.
#project_name/__init__.py
from .celery import app as celery_app
__all__ = ("celery_app",)
위 설정을 추가하면 @shared_task 데코레이터를 사용해도 task를 app에 불러올 수 있다. (tasks.py에서 celery app을 import 안 해도 된다는 뜻)
이번에는 @app.task를 사용해줄 것이므로 해도 되고 안해도 된다.
#project_app/views.py
from django_redis import get_redis_connection
client = get_redis_connection()
def get(self, request, *args, **kwargs):
team_id = kwargs.get("team_id")
if not request.user.id:
user_id = 0
else:
user_id = request.user.id
try:
redis_ans = client.sadd(f"views:{team_id}", f"{user_id}_{request.META.get('REMOTE_ADDR')}")
team = Team.objects.get(id=team_id)
if redis_ans:
team.view += 1
team.save()
teamSerializer = TeamCreateSerializer(team)
response = createSerializerHelper.make_response(teamSerializer.data, request.user.id)
return Response(response, status=status.HTTP_200_OK)
except Team.DoesNotExist:
return Response({"error": "No Content"}, status=status.HTTP_404_NOT_FOUND)비회원의 조회에 대해서 카운트해주기 위해서 비회원의 유저id는 0으로 고정했다.
유저가 API에 접근했을 때 views:team_id에 유저id_IP쌍을 SADD 해준다.
이 때, 집합 추가에 성공한다면 이 명령은 1을 반환하고 실패하면 0을 반환해준다.
따라서 이 값을 분기점으로 조회수를 추가해준다.
#project_app/tasks.py NEW
from django_redis import get_redis_connection
from #project_name.celery import app
client = get_redis_connection()
@app.task
def delete_view_history():
cursor = "0"
print("--- 팀 조회 히스토리 삭제 시작 ---")
while cursor != 0:
cursor, keys = client.scan(cursor=cursor, match="views:*")
if keys:
client.delete(*keys)
print("--- 팀 조회 히스토리 삭제 완료 ---")celery에서 사용할 수 있는 task를 추가해주자. views:로 시작되는 키를 반복적으로 찾아내어 밸류값을 삭제하는 함수이다.
여기서 잠깐!
필자는 장고의 캐시백엔드로 redis를 이미 사용하고 있다.
그런데 왜 django_redis에서 redis_connection을 따로 빼내어서 연결 설정을 해줬을까?
이유는 간단하다. django_redis의 cache.py를 보면 SADD에 관한 내용이 없다..
set, get, delete 등 뿐이고 set이나 sorted_set에 대한 내용을 지원해주지 않는다.
task는 추가해줬으나 어떻게 자정마다 실행하게 할 수 있을까?
이를 가능케하는 것이 Celery-beat이다.
#project_name/celery.py
from celery.schedules import crontab
app.conf.beat_schedule = {
"delete-view-history-per-day": {"task": "project_app.tasks.delete_view_history", "schedule": crontab(minute=0, hour=0)}
}celery.py로 돌아가 위 내용을 추가해주자. crontab을 통해 특정 시간을 지정해 task를 실행시킬 수 있게 해준다.
실행
celery -A project_name worker -l INFO
celery -A project_name beat
python manage.py runserver각각의 터미널에서 명령을 입력해 실행해주자.
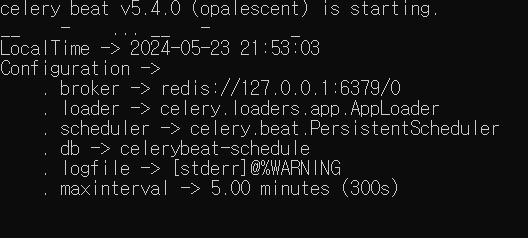
celery worker
user/tasks.send_email은 이메일 보내는 task를 따로 추가한 것이니 출력에 없어도 된다.
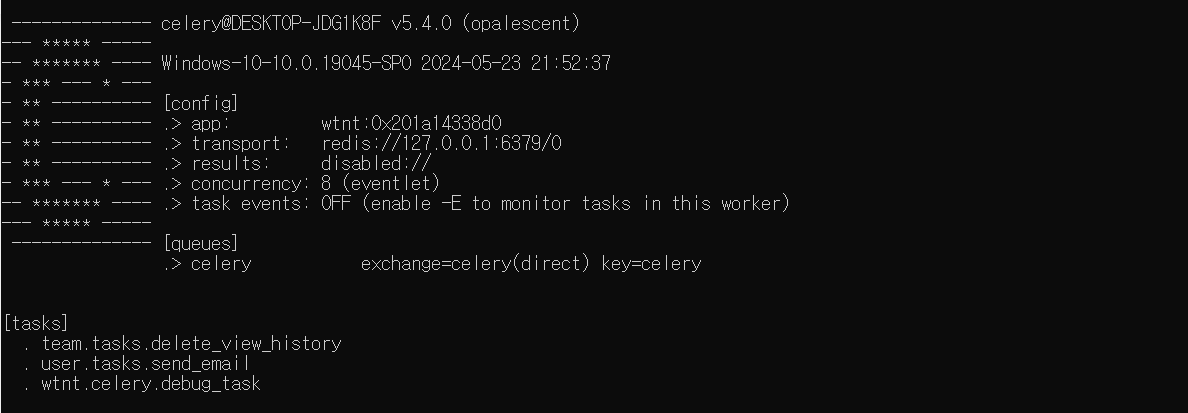
celery beat
잘 실행되었다면 위와 같이 출력되어 있을 것이다.
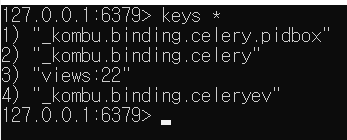
Postman으로 조회를 한 번 해본 뒤에 redis-cli에서 확인해보면
아래와 같이 views:team_id 키가 생성되어있다.
이게 자정에 삭제되는지 안 되는지 확인하기까지 시간이 많이 남았다면
celery.py의 crontab 설정을 바꿔볼 수 있다.
app.conf.beat_schedule = {
"delete-view-history-per-day": {"task": "project_app.tasks.delete_view_history", "schedule": crontab()}
}이렇게 바꿔주면 매 분마다 task가 실행된다.

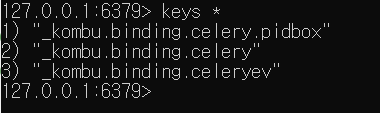
잘 삭제가 된 것을 확인할 수 있다.
위 내용이 실행된 결과를 아까 따로 설치한 django-celery-results를 통해서도 알 수 있는데
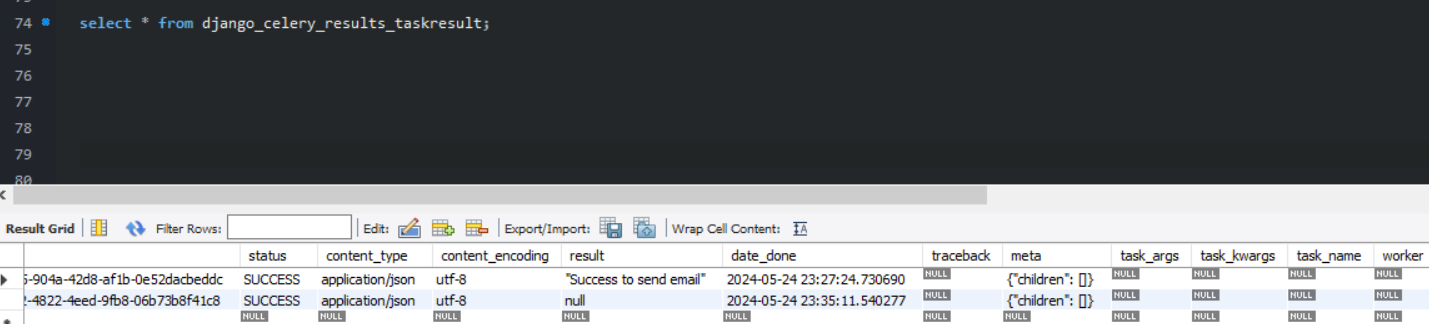
두 번째 열에 해당하는 내용이 방금 우리가 해본 내용이다. celery를 실행한 쉘에서 None값이 반환되었으므로 django_celery_results_taskresult 테이블에는 null이 저장되는 것!
