BOJ Platinum Challenge
1.[BOJ] 13537 수열과 쿼리 1 - P3

머지 소트 트리를 구현하여 k보다 큰 원소의 개수를 빠르게 구한다.
2.[BOJ] 1395 스위치 - P3
세그먼트 트리의 lazy propagation를 이용한다. lazy propagation를 하지 않으면 시간 초과.
3.[BOJ] 14939 불 끄기 - P4
(0, 0) ~ (8, 8)를 순회하며 불이 켜져있으면 바로 밑에 칸의 스위치를 누른다. 마지막 줄 (9, 0) ~ (9, 9)에서 불이 켜져있으면 불가능한 경우이다. 첫번째 줄의 스위치를 누를 경우도 고려해야 하므로 부분 집합을 활용한다. 최소값을 출력한다.
4.[BOJ] 2618 경찰차 - P4
경찰차의 현재 있는 위치 (마지막으로 방문한 위치)를 기준으로 dp. 어떤 경찰이 방문했는지 기록하기 위해 BooleanArray 추가
5.[BOJ] 1708 볼록 껍질 - P5
볼록 껍질 (Convex Hull) 기본 문제
6.[BOJ] 10254 고속도로 - P2
Convex Hull & Rotating Callipers를 이용하여 최대 거리 구하기. 스택에서 첫번째와 두번째값을 꺼내와야 하므로 Stack class를 구현하였다.
7.[BOJ] 7420 맹독 방벽 - P4
Convex Hull을 활용하여 가장 바깥쪽 건물들을 구한다. 가장 바깥쪽 건물들의 둘레의 길이 + 2 x PI x L을 구한다.
8.[BOJ] 13016 내 왼손에는 흑염룡이 잠들어 있다 - P5
임의의 지점에서의 최대 길이는, 각 지점에서 트리의 지름에 해당하는 양 꼭짓점까지의 거리의 최대 길이와 같다. (임의의 지점을 pi, 트리의 지름에 해당하는 양 꼭짓점을 pa, pb라 하면 max(len(pi, pa), len(pi, pb)))
9.[BOJ] 1006 습격자 초라기 - P3
2차원 dp 테이블 정의 : dp[N번째 열][방문 형태] (방문 형태: 0 = 모두 방문, 1 = 첫번째 행만 방문, 2 = 두번째 행만 방문). 원의 형태이므로 4가지의 경우를 고려해야 한다.
10.[BOJ] 3197 백조의 호수 - P5
bfs를 이용하여 각 좌표에서 빙판이 녹는 시간을 기록한다. bfs를 이용하여 백조가 만날 수 있는 가장 빠른 시간을 구한다.
11.[BOJ] 13275 가장 긴 팰린드롬 부분 문자열 - P5
manacher 알고리즘 사용
12.[BOJ] 16163 #15164번_제보 - P5
manacher 알고리즘을 사용하여 각 위치에서의 가장 긴 팰린드롬 문자열의 길이 구하기. sum((팰린드롬 문자열의 길이 + 1) / 2)가 팰린드롬 부분 문자열의 개수이다.
13.[BOJ] 11046 팰린드롬?? - P5
manacher 알고리즘을 활용하여 각 인덱스에서의 가장 긴 팰린드롬의 길이를 저장한다. 입력되는 자연수가 2자리 이상일 수 있으므로 String이 아닌 IntArray를 사용하여 팰린드롬인지 판단한다.
14.[BOJ] 2150 Strongly Connected Component - P5
타잔 알고리즘을 사용하여 SCC구하기
15.[BOJ] 1506 경찰서 - P5
타잔 알고리즘을 사용하여 SCC 구하기. 각각의 SCC에서 최소 비용을 구해서 더하기
16.[BOJ] 4196 도미노 - P4
주어진 입력값에 따라 정방향 리스트와 역방향 리스트를 둘 다 만든다. 타잔 알고리즘을 사용하여 SCC를 구한다. 각각의 SCC의 inDegree를 구하여 0이면 카운팅 한다.
17.[BOJ] 3596 크로스와 크로스 - P2
0 ~ n까지 Grundy Number를 구해서 승리 여부를 판단한다. 어떤 지점에 x마크를 하면 양 옆으로 2칸은 더이상 마크 할 수 없는 지점과 다름 없다.
18.[BOJ] 11868 님 게임 2 - P4
스프라그–그런디 정리 기본 문제
19.[BOJ] 11694 님 게임 - P2
각 돌 더미의 그런디 값을 xor한다. 돌 더미가 1인 것의 개수가 0이거나 홀수이면, 1번 값이 0이 아니면 선공 승, 0이면 후공 승이다. 돌 더미가 1인 것의 개수가 0이 아닌 짝수이면, 돌 더미 중에서 1이 아닌 것을 하나만 1로 바꾸고 계산한다.
20.[BOJ] 16895 님 게임 3 - P4
각각의 돌 더미들의 그런디 값을 xor한 값을 G라 했을때, G가 0이면 답은 0이다. G가 0이 아닐 때, 각각의 돌 더미의 개수를 낮춰가며 새로운 그런디 값 G'를 만들고, 이 값이 0인 경우의 수를 카운팅 한다.
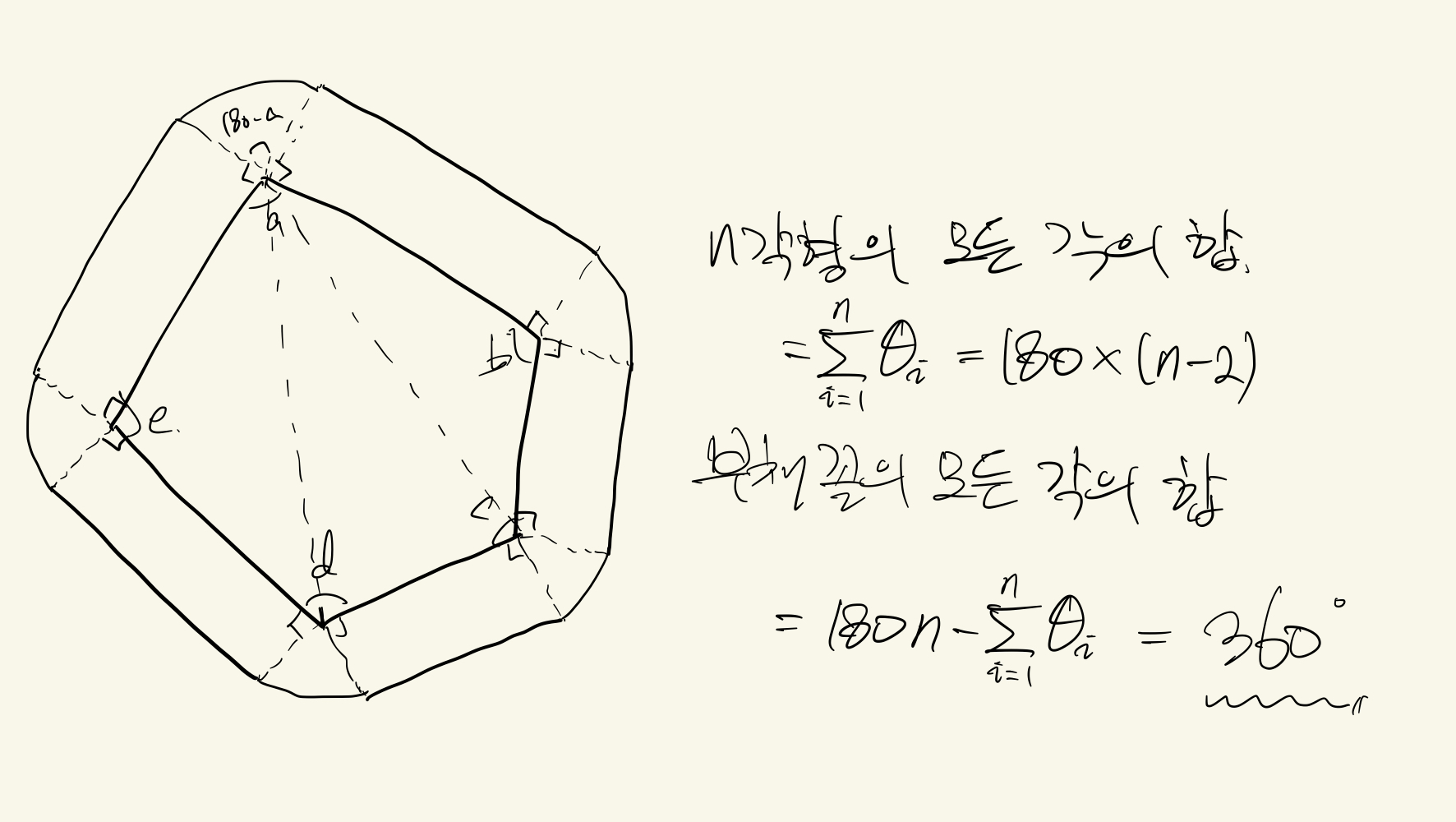
21.[BOJ] 13034 다각형 게임 - P3
다각형에 직선을 그어 양쪽으로 나눠지는 그런디 값을 이용한다. n을 증가시켜가며 n각형의 그런디 값을 구한다.
22.[BOJ] 16877 핌버 - P3
3000000까지의 피보나치 수열을 구한다. 3000000번째 까지의 Grundy값을 전처리 한다. mex값을 구할 때 사용하는 Boolean배열의 크기는 최대 Grundy값의 크기로 설정하면 된다.
23.[BOJ] 3977 축구 전술 - P4
타잔 알고리즘을 사용하여 모든 scc를 구하고 각각의 원소에 sccId를 설정한다.각각의 scc의 inDegree를 구하고 0인 scc가 1개면 가능한 경우이고, 2개 이상이면 불가능한 경우이다.inDegree가 0인 sccId에 해당하는 원소를 오름차순으로 출력한다.
24.[BOJ] 10803 정사각형 만들기 - P3
가로, 세로로 쪼갰을 때 나오는 두 부분의 최소값을 구하는 dp테이블을 만든다. 한쪽의 길이가 다른쪽의 길이보다 많이 클 때 (n >> m), 작은 쪽의 길이를 한 변의 길이로 하는 정사각형(m x m)을 만드는 것이 가장 최소가 된다.
25.[BOJ] 4250 EKG Sequence - P5
2 ~ 1000000까지의 소수를 구한다. (prime, count) 쌍으로 map을 만든다. 이전 값의 인수 중에서 소수인 것을 찾고, 현재까지 나오지 않은 수 중에서 조건에 맞는 가장 큰 숫자를 구한다. 300000개의 배열이 모두 채워질 때까지 반복한다.
26.[BOJ] 4013 ATM - P2
타잔 알고리즘을 사용하여 SCC 구하기. 각 SCC들을 하나의 정점처럼 생각하며 레스토랑 까지의 최대 액수 구하기. 타잔 알고리즘으로 구한 SCC들의 리스트를 역순으로 탐색하며 최대 액수 갱신
27.[BOJ] 9240 로버트 후드 - P3
볼록 껍질을 구하고 회전하는 캘리퍼스로 최대 길이를 구한다.
28.[BOJ] 11280 2-SAT - 3 - P4
2-sat 기본 문제. scc를 구해서 모순이 발생하는지 확인한다.
29.[BOJ] 11281 2-SAT - 4 - P3
타잔 알고리즘을 사용하여 각 원소들의 sccId를 구한다. 위상 정렬 순으로 xi 와 !xi중에서 먼저 나오는 값을 false로 설정한다.예제 1의 출력 값이 주어진 값과 다를 수 있다. (경우의 수가 여러가지)
30.[BOJ] 3648 아이돌 - P3
-1 -> 1간선 추가하기. 2-sat 풀기동작하는 테스트 케이스의 개수가 안 나와있다. try, catch로 에러를 잡아서 종료시켰다.
31.[BOJ] 2207 가위바위보 - P4
2-sat 기본 문제
32.[BOJ] 16367 TV Show Game - P2
(a, b, c) 중에 2개 이상 맞아야 하므로 3개중에 2개를 묶었을 때, 적어도 둘 중 하나는 조건을 만족해야 한다. (a or b) and (b or c) and (c or a)
33.[BOJ] 15675 괴도 강산 - P1
보석 칸에서는 가로 or 세로, 위치 추적기 칸에서는 가로 and 세로
34.[BOJ] 13941 Kronican - P5
(N - K)번의 물의 이동을 하면 된다.N이 최대 20이므로 비트 마스킹을 이용하여 이동 여부를 체크한다.dp\[2^N]의 dp테이블을 채운다.
35.[BOJ] 3015 오아시스 재결합 - P5
스택에 (키, 사람 수)를 저장하고 나보다 작거나 같은 사람이 있으면 제거한다.같은 키의 사람을 처리할 때 주의해야 한다.
36.[BOJ] 9376 탈옥 - P4
감옥 밖, 죄수1, 죄수2를 중심으로 다익스트라를 사용하여 최단 거리를 구한다.각 지점에서 감옥 밖, 죄수1, 죄수2까지의 거리의 합이 가장 작은 값이 정답이다.
37.[BOJ] 17071 숨바꼭질 5 - P5
t1시간에 동생이 도달할 지점을 t2시간에 도착했다 했을 때, (t1 - t2)가 짝수이면 동생과 만날 수 있다. 도착 시간이 홀수, 짝수일 경우를 나눠서 각각의 최단 시간을 구한다. 동생이 도착할 지점을 하나씩 순회하며 조건을 만족하는 값이 있는지 판단한다.
38.[BOJ] 25517 머리 아픈 암산은 이제 그만! - P4
10^8, 2x10^8, ..., 10^9의 10개 정도를 미리 계산해서 입력해둔다.나누기 연산은 숫자^(MOD - 2)를 곱하는 것으로 대신한다.10^9의 팩토리얼 계산의 시간 복잡도를 줄이지 않으면 시간 초과를 피할 수 없다.
39.[BOJ] 18250 철도 여행 - P5
연결되어 있는 지점들에서 inDegree가 홀수인 개수를 구하고 그것을 2로 나눈 값이 모든 경로를 지나는데 필요한 횟수이다. (inDegree가 홀수인 개수가 0이고, inDegree > 0 이면 필요한 횟수는 1이다.)
40.[BOJ] 10217 KCM Travel - P4
1번 지점에서 1~N까지의 M의 비용으로 가는 최단 시간을 기록하는 dp테이블을 만든다. dp[N][M]다익스트라를 구현하여 각 지점에서의 비용과 최단 시간을 갱신한다.간선의 입력 데이터를 정렬해주지 않으면 시간 초과를 맞이할 수 있다.
41.[BOJ] 1086 박성원 - P5
10의 거듭 제곱을 K로 나눈 나머지와, 주어진 수를 K로 나눈 나머지를 전처리 한다. (dp[순열의 flag][K로 나눈 나머지] = 경우의 수)로 설정하고 0 ~ (1 shl N) 까지 순회하며 dp 테이블을 채운다.
42.[BOJ] 1637 날카로운 눈 - P4
문제풀이 1 ~ 임의의 수에서 정수의 숫자를 구하고 그것이 홀수인지 짝수인지 판별한다. 매개 변수 탐색을 통해 위의 1번 과정을 반복하며 정수의 숫자가 홀수인 수를 구한다. 주의사항 정수의 숫자가 홀수인 수가 없을 수도 있다. 소요시간 24분 문제링크 회고 아이디어를 생각해내기 어려운 문제였다. 매개 변수 탐색이라는 것을 깨닫고 나면 그렇게 어려운 ...
43.[BOJ] 18937 왕들의 외나무다리 돌게임 - P3
각각의 그런디 값을 xor한 값이 0이 아니면 먼저 시작한 사람이 이긴다. G[i] = i - 2
44.[BOJ] 11871 님 게임 홀짝 - P3
각각의 그런디 값을 xor한다. G\[2k + 1] = k + 1, G\[2k] = k - 1
45.[BOJ] 16887 루트 님 게임 - P1
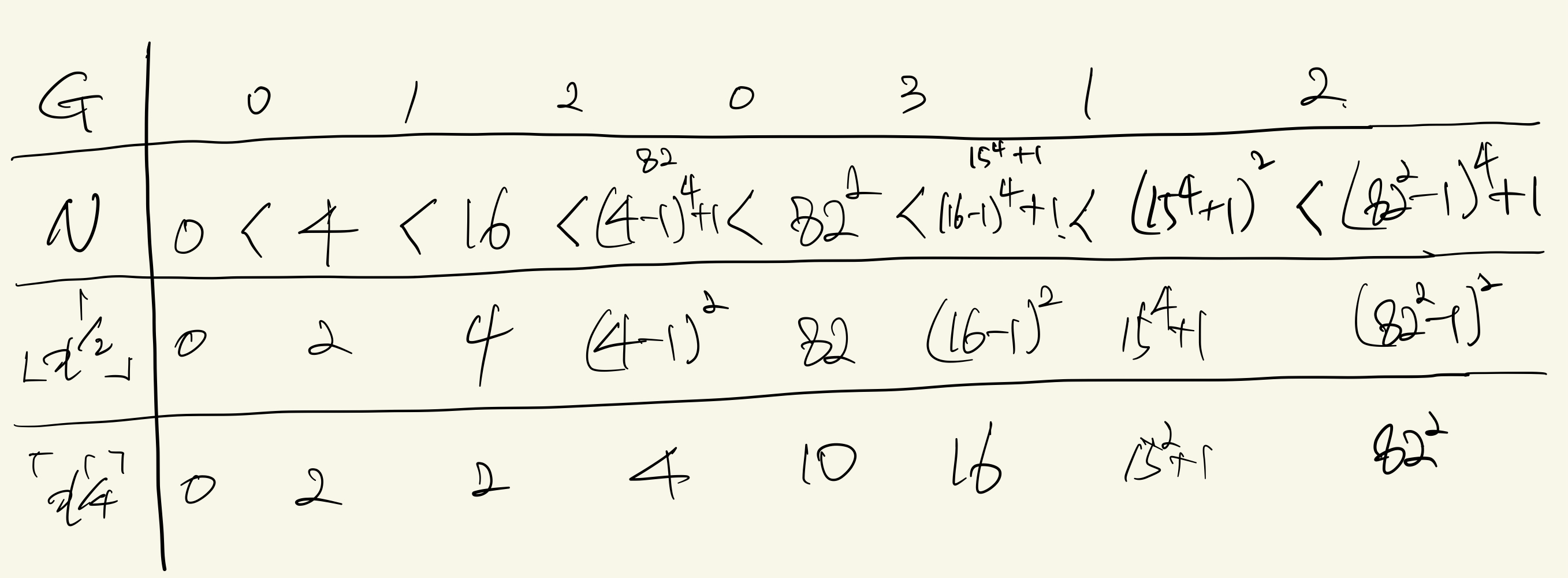
x^(1/4)이나 x^(1/2)가 이전 그런디 값의 경계조건을 넘어가는 부분에 주의하며 그런디 값을 채워나간다.
46.[BOJ] 18940 숫자 카드 제거 게임 - P1
완전 탐색으로 아래와 같이 그런디의 배열을 출력해보고 규칙을 찾는다. 0 ~ 42까지의 숫자 중에서는 0, 4, 8, 14, 20, 24, 28, 34, 38, 42가 그런디가 0이고, 그 이후에는 직전 숫자에 (+12, +4, +4, +10, +4)를 한 숫자이다.
47.[BOJ] 11717 Wall Making Game - P2
빈 칸을 선택한 후 선택한 좌표의 가로, 세로를 제외한 4부분으로 쪼개진 부분 격자판의 그런디 값을 xor한 값을 구한다.모든 경우에 해당하는 그런디 값의 mex값을 구한다.
48.[BOJ] 16725 다항 계수 - P5
문제의 노트에 주어진 다항식을 푸는 방식의 누적합을 이용한 풀이. 나머지 계산할 때 음수값이 나오는 것을 조심하자.
49.[BOJ] 16566 카드 게임 - P5
카드 배열에서 특정 숫자보다 큰 숫자중에 가장 작은 숫자를 빠르게 구하기 위해 이분 탐색을 사용한다. 이미 사용한 숫자인지 아닌지 판단하기 위해 인덱스 배열을 추가하였다. (배열에 바로 접근하는 것이 아니라 인덱스 배열을 거쳐서 배열에 접근한다.)
50.[BOJ] 30239 트리와 XOR - P4
가장 작은 값을 만들려면 모두 루트와 같은 숫자로 바꿔줘야 한다. (자신 xor (자신 xor 부모) = 부모)a xor (a xor b) = b인 xor의 성질을 이용한다. (자신 xor (자신 xor 부모) = 부모)
51.[BOJ] 5942 Big Macs Around the World - P5
최소 비용을 구하는 문제이지만, 비용이 초기 상태보다 줄어들 수 있으므로 벨만-포드 알고리즘을 사용한다.
52.[BOJ] 1219 오민식의 고민 - P5
벨만-포드 알고리즘을 사용한다. 사이클을 조심하자.
53.[BOJ] 3860 할로윈 묘지 - P4
벨만-포드 알고리즘을 사용하여 최단 시간을 구한다. 음의 사이클이 존재하면 무조건 Never 출력
54.[BOJ] 5670 휴대폰 자판 - P4
trie 자료 구조를 사용하여 버튼을 눌러야 하는 횟수의 평균을 구한다.
55.[BOJ] 9202 Boggle - P5
문자열의 해싱을 통해 prefixSet과 wordMap을 만든다. (prefixSet은 접두어가 존재하지 않는 불필요한 문자를 탐색하는 것을 방지하기 위해 사용하고, wordMap은 주어진 문자를 판별하기 위해 사용한다.)완전 탐색으로 발견할 수 있는 모든 문자에 대해
56.[BOJ] 13505 두 수 XOR - P3
trie 자료 구조를 사용하여 각 숫자를 2진수로 표현한 문자를 저장한다.N개의 2진수를 순회하며 각각의 xor값이 가장 커질 수 있는 경우를 구한다. (trie 자료 구조를 탐색하며 자기 자신의 비트와 다른 값을 우선해서 탐색해 나간다.)
57.[BOJ] 16903 수열과 쿼리 20 - P3
주어진 숫자를 2진수의 String으로 바꾸고 trie에 저장한다. trie의 삽입, 삭제, 최대 xor값을 구하는 연산을 구현한다.
58.[BOJ] 1605 반복 부분문자열 - P3
이분 탐색을 통해 길이를 정하고, 조건을 만족하는 여부는 문자열의 해시값을 구하여 판단한다.
59.[BOJ] 17228 아름다운 만영로 - P2
트리를 순회하며 문자열의 해시값을 비교한다. (라빈-카프)해시 테이블을 만들면 시간 초과가 날 수 있다.
60.[BOJ] 5446 용량 부족 - P3
trie 자료 구조를 구현하고, 하위 항목에 삭제할 파일이 있는지, 하위 항목에 삭제하면 안되는 파일이 있는지, 현재 파일이 삭제해야 되는 파일인지 여부를 체크한다.trie를 순회하며 삭제 횟수를 구한다.
61.[BOJ] 13504 XOR 합 - P3
trie 자료 구조를 구현한다. 현재까지의 누적합과 trie 자료 구조 내부의 값을 xor한 것 중에 가장 큰 값을 구한다.현재까지의 누적합을 trie 자료 구조에 add한다.N개의 수에 대하여 2, 3번을 반복한다.
62.[BOJ] 17365 별다줄 - P3
trie 자료 구조와 dp를 활용하는 문제
63.[BOJ] 13445 부분 수열 XOR - P2
trie 자료 구조를 만들고 0을 넣는다.현재까지의 xor누적 값을 trie 내부의 숫자와 비교하여 K보다 작은 숫자의 개수를 구한다.현재까지의 xor누적 값을 trie에 넣는다.N개의 배열을 순회하며 2, 3번을 반복한다.
64.[BOJ] 17844 복붙하기 - P2
이분 탐색을 통해 문자열의 길이를 정한다. 해당 문자열의 길이에 해당하는 해시값을 라빈-카프 알고리즘을 사용하여 효율적으로 구한다. 해시 충돌을 방지하기 위해 서로 다른 모듈러 연산을 통해 해시값을 4개정도 사용한다. 해시 충돌이 발생할 수 있다는 것을 고려해야 한다.
65.[BOJ] 19608 Searching for Strings - P3
N의 각각의 알파벳이 등장하는 횟수를 카운팅한다.H를 순회하며, N개의 문자열마다 알파벳이 등장하는 횟수가 1번 값과 같으면 해시값을 비교한다.해시 충돌을 방지하기 위해 해시값을 여러개 사용한다.
66.[BOJ] 21218 Unique Activities - P2
이분 탐색을 통해 단어의 길이를 정한다.해싱을 통해 단어의 동등성을 확인한다.단어의 등장 횟수를 카운팅한다.단어의 등장 횟수가 1인 것 찾는다.
67.[BOJ] 16886 나누기 게임 - P3
3 + 2k, 6 + 3k, 10 + 4k ... 와 같이 ((N - i번째 까지의 구간합) % i == 0) 이면 돌 더미를 i개로 분리할 수 있다. 이때의 그런디 값은 xor값의 구간합으로 구할 수 있다. N까지의 그런디값을 전처리 한다.
68.[BOJ] 11375 열혈강호 - P4
이분 매칭을 이용하여 최대 매칭 횟수 구하기
69.[BOJ] 11376 열혈강호 2 - P4
한 사람이 최대 2개의 일을 담당할 수 있으므로, 이분 매칭을 진행할 때 2번씩 수행한다.
70.[BOJ] 11377 열혈강호 3 - P3
N명과 M개의 직업을 이분 매칭한 결과를 기록하고, 다시 한번 이분 매칭을 해서 최대 K번을 더 추가한다.
71.[BOJ] 11378 열혈강호 4 - P3
이분 매칭을 한번 수행한 다음에, 최대 K번의 매칭을 더 수행한다.시간 절약을 위해 매칭이 성공한 경우에만 다시 매칭을 시도한다.
72.[BOJ] 1017 소수 쌍 - P3
2000까지의 소수 목록을 만든다.N개의 숫자들을 순회하며 더하면 소수가 되는 쌍을 기록한다.첫번째 숫자와 더하면 소수가 될 수 있는 쌍 하나를 고정하고 이분 매칭을 한다.모든 숫자가 매칭되었을 경우만 카운팅한다.
73.[BOJ] 1671 상어의 저녁식사 - P3
상어가 다른 상어를 먹을 수 있으면 간선을 추가하고, 이분 매칭을 2번 수행한다. 상태가 완전히 동일한 상어는 서로 먹고 먹히지 않게 인덱스를 기준으로 우선 순위를 부여한다.
74.[BOJ] 3683 고양이와 개 - P2
고양이를 선호하는 그룹과 개를 선호하는 그룹으로 나눈다.고양이 그룹과 개 그룹 사이에 절대 양립할 수 없는 사람들을 간선으로 연결한다.이분 매칭 후 전체 인원 수에서 빼준다.
75.[BOJ] 13166 범죄 파티 - P1
이분 탐색을 통해 파티 비용을 결정한다. 이분 매칭을 통해 모든 사람이 매칭될 수 있으면 현재 파티 비용을 출력한다. 이분 매칭에 사용되는 visited 배열을 Boolean으로 만들면, 초기화할 때 O(N^2)의 시간 복잡도를 가질 수 있으므로 주의해야 한다.
76.[BOJ] 11406 책 구매하기 2 - P4
source -> 사람 -> 서점 -> sink에 해당하는 간선을 연결하고 최대 유량을 구한다.
77.[BOJ] 2316 도시 왕복하기 2 - P3
도시를 최대 1번씩만 방문하며 최대 유량 구하기도시를 1번만 방문하기 위해 하나의 도시 사이에 1의 용량을 갖는 간선을 추가한다.
78.[BOJ] 11405 책 구매하기 - P3
최소 비용 최대 유량을 구한다.
79.[BOJ] 11408 열혈강호 5 - P3
최소 비용 최대 유량을 구한다.최대 유량과 최소 비용을 출력한다.
80.[BOJ] 13511 트리와 쿼리 2 - P3
lca(u, v) = 최소 공통 조상price\[i] = i부터 root까지의 비용쿼리 1 : price\[u] + price\[v] - 2 x price\[lca(u, v)]쿼리 2 : depth차이를 이용하여 k번째를 구한다.
81.[BOJ] 3176 도로 네트워크 - P4
parent[i][N] = N 노드에서 2^i 번째 부모를 저장한다.max[i][N] = N 노드에서 2^i 번째 부모까지의 간선 중에 최대값을 저장한다.min[i][N] = N 노드에서 2^i 번째 부모까지의 간선 중에 최소값을 저장한다.
82.[BOJ] 14278 블록 쌓기 - P5
dp\[높이]\[블록에 대한 비트 마스킹]으로 둔다.count[111] = count[011] + count[001] + count[000]인 것을 이용한다.단, 한 칸 아래 높이에 있는 블록의 유무에 따라 가능 여부를 판단해야 한다.
83.[BOJ] 14601 샤워실 바닥 깔기 (Large) - P5
2^k x 2^k의 정사각형을 4등분 하며 샤워실 바닥을 깔아준다.정사각형의 네 귀퉁이 중에 한 부분이 빠져있는 도형을 채우는 것을 반복한다.
84.[BOJ] 1294 문자열 장식 - P3
문자열을 사전순으로 정렬하고 하나씩 채워나간다.두 문자열을 비교할 때, minOf(o1.length, o2.length)까지의 문자가 모두 같은 경우에는 문자열의 길이가 큰 것을 우선한다.
85.[BOJ] 3043 장난감 탱크 - P4
행이 작은 순서로 정렬한 값들을 1 ~ N행에 배정하고, 열이 작은 순서로 정렬한 값들을 1 ~ N열에 배정하면 된다.경로를 구할 때는 위로 올라가는 탱크는 행이 작은 탱크가 우선이고, 아래로 내려가는 탱크는 행이 큰 탱크가 우선이다. 왼쪽으로 이동하는 탱크는 열이 작
86.[BOJ] 1467 수 지우기 - P2
세준이가 가지고 있는 문자열의 길이를 N이라 하고, 삭제할 문자열의 길이를 M이라 했을 때, (N - M)길이의 문자열을 만들면 된다.현재 단계에서 가능한 가장 큰 수를 배치한다. -> 해당 숫자 앞에 있는 모든 숫자가 삭제 가능하고, 해당 숫자를 선택할 수 있어야 한
87.[BOJ] 1328 고층 빌딩 - P5
dp[빌딩을 세운 개수][왼쪽에서 보이는 빌딩의 개수][오른쪽에서 보이는 빌딩의 개수]로 둔다.높이가 N인 빌딩을 먼저 세우고 dp[1][1][1] = 0로 둔다.(N - 1) ~ 1 순으로 빌딩을 세워나가면서 dp테이블을 채운다.
88.[BOJ] 1315 RPG - P3
dp[STR][INT] = 사용하고 남은 PNT로 두고 현재 STR, INT값이 가능한지 판단하여 깰 수 있는 퀘스트 개수의 최대값을 구한다.
89.[BOJ] 10165 버스 노선 - P5
버스 노선의 길이를 기준으로 내림차순 정렬한다.현재 노선보다 출발점이 앞에 있는 노선의 도착점이, 현재 노선의 도착점보다 더 뒤에 있다면 포함관계이다.
90.[BOJ] 13547 수열과 쿼리 5 - P2
쿼리를 (l / sqrt(N))에 대하여 오름차순, r에 대하여 오름차순 정렬한다.이전 쿼리의 l, r과 현재 쿼리의 l, r에서 변동량을 기록한다.
91.[BOJ] 13548 수열과 쿼리 6 - P1
쿼리를 (l / sqrt(N))으로 오름차순 정렬, r로 오름차순 정렬한다.count[A] = A가 등장하는 횟수, countCount[등장 횟수 K] = 등장 횟수가 K인 것의 개수로 둔다.카운팅 할 때, 음수가 발생할 수 있으므로 더하기 연산을 먼저 해준다.
92.[BOJ] 8462 배열의 힘 - P2
Mo's 알고리즘 기본 문제
93.[BOJ] 14413 Poklon - P1
값의 범위가 값의 개수보다 매우 크므로 hashMap을 활용하여 좌표를 치환한다.쿼리를 정렬한다.mo's 알고리즘을 활용하여 구간에 2번 등장하는 숫자의 개수를 구한다.
94.[BOJ] Sum and Product - P4
각 지점에서 1이 나오는 개수의 누적합을 구한다.1이 아닌 지점의 인덱스 리스트를 만든다.1이 아닌 지점들의 구간을 순회하며 구간의 왼쪽 바깥의 연속하는 1의 개수, 구간의 오른쪽 바깥의 연속하는 1의 개수를 고려하여 mul == sum이 되는 개수를 카운팅한다.
95.[BOJ] 16297 Eating Everything Efficiently - P5
dp\[시작 인덱스] = 시작 인덱스에서 시작하여 얻을 수 있는 최대 만족도로 정의한다.현재 지점을 방문할지 안할지를 구분하며 최대값을 기록한다. maxOf(현재 인덱스 만족도 + (현재 이후에서 얻을 수 있는 최대 만족도 / 2), 현재 이후에서 얻을 수 있는 최대
96.[BOJ] 1146 지그재그 서기 - P5
dp\[현재 상태에서 나보다 키가 작은 학생 수]\[현재 상태에서 나보다 키가 큰 학생 수]\[다음에 키가 큰 학생이 나와야하는지 작은 학생이 나와야 하는지 여부]로 두고 dp테이블을 채워나간다.N = 1일때를 고려해야 한다.
97.[BOJ] 2184 김치 배달 - P3
도시들과 김치 공장을 하나의 배열에 넣고 오름차순 정렬한다.dp[방문한 가장 왼쪽 인덱스][방문한 가장 오른쪽 인덱스][현재 위치(0: 왼쪽 인덱스, 1: 오른쪽 인덱스)] = 최소값으로 두고 dp테이블을 채워나간다.
98.[BOJ] 1023 괄호 문자열 - P3
dp[문자열의 길이][열린 괄호의 개수 - 닫힌 괄호의 개수] = 경우의 수로 두고 dp테이블을 채워나간다.단, 열린 괄호의 개수 - 닫힌 괄호의 개수가 음수가 되는 경우는 고려하지 않는다.N개의 문자를 결정하는데, 앞에서 부터 차례대로 열린 괄호를 넣었을때 경우의
99.[BOJ] 17428 K번째 괄호 문자열 - P5
dp[문자열의 길이][열린 괄호의 개수 - 닫힌 괄호의 개수] = 경우의 수로 두고 dp테이블을 채워나간다. 이때, 항상 (열린 괄호의 개수 >= 닫힌 괄호의 개수)를 만족해야 한다.K번째 문자열을 구한다.
100.[BOJ] 2315 가로등 끄기 - P3
dp[방문한 최소 인덱스][방문한 최대 인덱스][현재 위치(0 : 최소 인덱스, 1: 최대 인덱스)] = 최소값으로 두고 dp테이블을 채워나간다.
101.[BOJ] 1413 박스 안의 열쇠 - P5
dp[박스의 개수][열쇠의 개수] = 경우의 수로 두고 dp테이블을 채워나간다.
102.[BOJ] 2419 사수아탕 - P1
dp[방문한 최소 인덱스][방문한 최대 인덱스][현재 위치(0: 왼쪽, 1: 오른쪽)]방문할 사탕 바구니 개수를 (1 ~ N)으로 정하고, N번 반복하며 최대값을 구한다.사탕 바구니에 무한대가 아닌 m개의 사탕이 있으므로 방문하는 도중에 0개가 될 수 있다. 즉,
103.[BOJ] 10670 Moovie Mooving - P3
dp[방문 여부] = 최대 시간으로 두고 dp테이블을 채워나간다.dp의 값이 L이상인 것들 중에서 방문 횟수가 최소인 것을 구한다.
104.[BOJ] 25582 pqbd - P3
manacher 알고리즘을 사용하여 팰린드롬의 최대 길이를 구한다.manacher 알고리즘을 사용할때, 중심이 팰린드롬인지 아닌지 확인해야 한다.
105.[BOJ] 20424 퀼린드롬 (Hard) - P2
알파벳의 대소문자중에 대칭이 있는 문자로 변환한다.대칭이 없는 문자가 하나라도 있으면 -1을 출력한다.manacher 알고리즘을 사용하여 각 지점에서의 팰린드롬의 길이를 구한다.팰린드롬이 왼쪽 끝이나 오른쪽 끝에 도달하는 지점을 찾고 최소값을 갱신한다.
106.[BOJ] 1517 버블 소트 - P5
현재 인덱스보다 큰 인덱스, 현재 값보다 작은 값의 개수만큼 카운팅해주면 된다.세그먼트 트리를 이용하여 값이 작은 순으로 넣어주고, 현재 인덱스보다 큰 인덱스의 개수를 구하면 된다.
107.[BOJ] 2243 사탕상자 - P5
세그먼트 트리에 각 사탕의 맛에 따른 개수를 표시한다.꺼낼 사탕의 순위는 세그먼트 트리의 각 사탕의 개수의 합을 비교하여 구할 수 있다.
108.[BOJ] 7493 Collisions - P5
공을 x에 대하여 오름차순 정렬했을 때, 세그먼트 트리에서 내 속도보다 큰 공의 개수를 구하면 된다.충돌 후 속도가 변하는 것은 공이 서로를 통과하는 것과 같은 효과이다.입력 데이터에 오류가 있다.
109.[BOJ] 2517 달리기 - P4
세그먼트 트리를 사용하여 현재 등수 순으로 순회하며, 나보다 실력이 낮은 사람의 숫자를 카운팅한다.
110.[BOJ] 3653 영화 수집 - P4
초기 상태로 N ~ 1의 번호를 순서대로 세그먼트 트리의 (0 ~ N-1)인덱스에 넣느다.선택한 영화의 세그먼트 트리의 인덱스를 구하고, 그 보다 큰 인덱스의 개수를 구한다.선택한 영화를 세그먼트 트리의 다음 인덱스에 넣고 이를 반복한다.
111.[BOJ] 5419 북서풍 - P3
배열을 정렬할 때 시간 초과를 만날 수 있다. 컬렉션으로 정렬하자.
112.[BOJ] 12844 XOR - P3
구간 업데이트, 구간 쿼리를 구하기 위해 세그먼트 트리의 lazy propagation을 활용한다.
113.[BOJ] 13925 수열과 쿼리 13 - P1
세그먼트 트리를 만들고, lazy propagation을 하기 위해 쿼리 1, 2, 3에 해당하는 size == 3의 IntArray의 배열을 만든다.각각의 쿼리를 처리해준다. 1번 쿼리는 0번 인덱스에 더해주고, 2번 쿼리는 0번 인덱스와 1번 인덱스에 각각 곱해준다
114.[BOJ] 17353 하늘에서 떨어지는 1, 2, ..., R-L+1개의 별 - P2
세그먼트 트리에 인접한 배열의 차이의 합을 저장한다. (Bn = An - An-1, B1 + ... + Bn = An - A0)lazy propagation을 이용한다.