
Background
-
CPU가 직접적으로 접근할 수 있는 저장소는
메인메모리와캐시,레지스터뿐 -
레지스터에 대한 접근은 하나의 CPU 클럭 사이클(또는 그 이하) 내에 완료됨 -
메인메모리에 접근하는 데는 레지스터에 접근하는 것보다 훨씬 더 오랜 시간이 소요됨. 이로 인해 "메모리 지연"이라는 현상이 발생할 수 있음 -
이러한 메모리 지연을 최소화하기 위해,
캐시는 CPU 레지스터와 주 기억장치 사이에 위치하여 데이터 접근을 가속화함 -
메모리가 전달받는 스트림은
주소 + 읽기 요청또는주소 + 쓰기 요청 + 데이터2종류임 -
메모리 보호는 시스템의 정확한 작동을 보장하기 위해 필요함
Protection
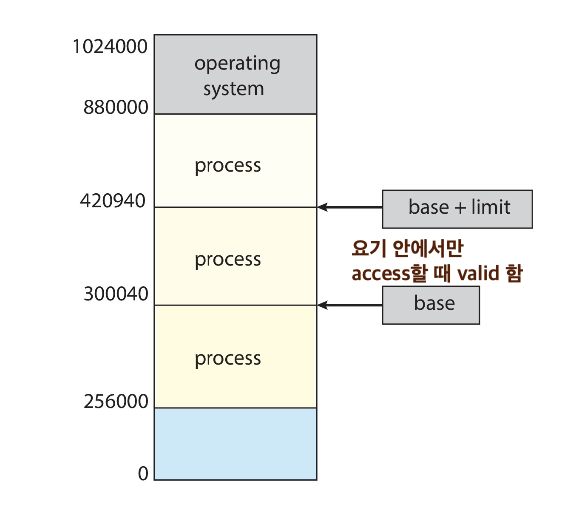
- 각 프로세스는 할당된 주소 공간을 벗어나는 주소에 접근할 수 없다
base register와limit register를 사용하여 프로세스의 논리적 주소 공간을 정의할 수 있음
Hardware address protection
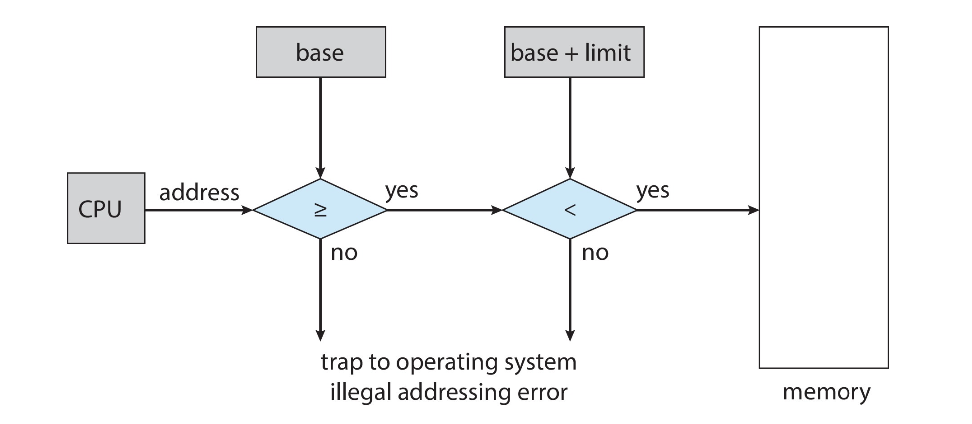
위와 같은 구조로 하드웨어에서 주소를 검사한 뒤 유효한 주소만을 접근 허용함
프로그램 실행 과정
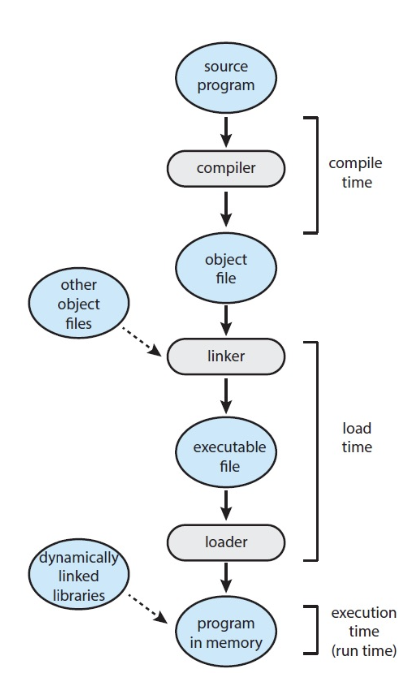
✅ 그냥 내가 궁금해서 찾아본 거 (시험에 안나올듯)
- 소스 코드: 프로그래머가 원하는 기능을 가진 소스 코드를 작성
- 컴파일: 소스 코드는 컴파일러에 의해 컴파일되어 object 파일로 변환됩니다. 컴파일러는 소스 코드를 기계어로 번역하고, 함수 및 변수의 선언을 기록하는 object 파일을 생성합니다. 이 단계에서는 아직 모든 함수 및 변수가 정의되지 않은 상태입니다.
- 링킹: 링커는 여러 개의 object 파일을 하나의 실행 파일로 결합합니다. 링커는 각 object 파일에서 사용된 함수 및 변수의 정의를 찾아서 연결하고, 실행 파일에 필요한 외부 라이브러리와의 연결도 수행합니다. 이러한 과정을 통해 실행 파일이 완성됩니다.
- 로딩: 로더는 실행 파일을 메모리에 로드합니다. 메모리에는 프로그램의 코드, 데이터, 스택 등이 위치하게 됩니다. 로더는 실행 파일을 메모리에 배치하고, 프로그램의 시작 위치를 지정합니다.
- 실행: 로딩이 완료된 후에는 CPU가 프로그램의 시작 위치로 이동하여 프로그램을 실행합니다. 프로그램은 메모리에 로드된 코드와 데이터를 참조하여 작동하게 됩니다. 프로그램은 사용자의 입력이나 시스템의 이벤트에 따라 동작하며, 실행 중에는 CPU와 메모리를 사용하여 계산 및 데이터 처리 작업을 수행합니다.
Address Binding
프로그램에서 사용되는 주소(변수, 레이블 또는 함수)를 해당 주소의 실제 메모리 위치에 연결하는 프로세스
각각의 시간에 바인딩되는 주소 유형은 다음과 같다:
1. 컴파일 타임 (Compile Time):
- 메모리 위치가
미리 알려져 있으면절대 코드를 생성할 수 있습니다.- 시작 위치가 변경되면 코드를 다시 컴파일해야 합니다.
- 메모리 위치가 미리 알려져 있지 않으면,컴파일러가 소스코드를 컴파일에 기계어 코드를 생성
- 이 경우, 심볼릭 주소가 재배치 가능 주소가 됨
2. 로드 타임 (Load Time):
- 메모리 위치가 컴파일 시간에 알려지지 않은 경우, 컴파일 타임에서 재배치 가능한 코드를 생성해야 합니다.
- 위에서 얘기한 메모리 위치가 미리 알려져 있지 않아 컴파일 타임에서 주소 바인딩이 이뤄지지 않으면, 로드 타임에서 바인딩될 수 있다
- 로드 타임(실행하기 직전)에서 주소 바인딩이 일어날 경우, 컴파일 된 재배치 가능 코드의 재배치 가능 주소가 절대 주소로 바인딩 됨
3. 실행 타임 (Execution Time):
- 프로세스가 실행 중에 다른 메모리 세그먼트로 이동될 수 있는 경우, 바인딩은 실행 시간까지 지연됩니다.
- 주소 맵을 위한 하드웨어 지원이 필요합니다. (예: 기본 및 제한 레지스터)
- 프로그램이 실행되는 동안, 실행기는 주소 변환을 수행하여 상징적 주소나 재배치 가능한 주소를 실제 물리적 주소로 변환함
- 이때 주소는 실행 타임에 실제로 사용되는 주소인 절대 주소로 표현됨
- 실행 타임에 주소 변환이 수행되므로, 프로그램이 실행 중일 때만 유효한 주소임
논리 주소 vs 물리 주소
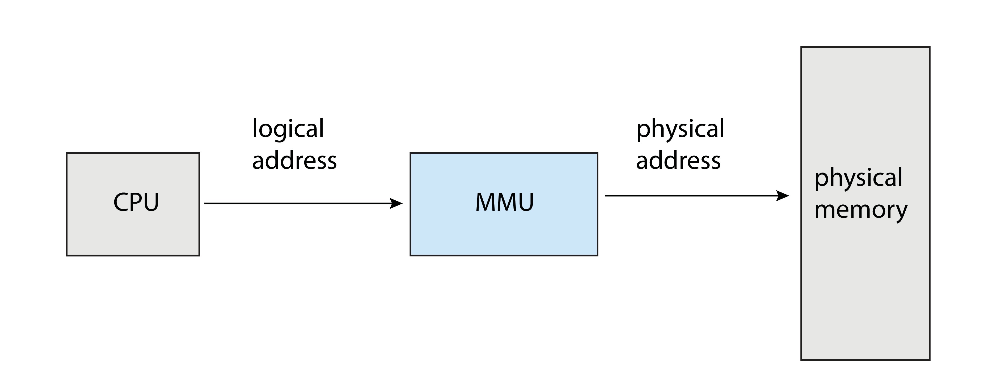
논리 주소 (Logical Address)
- CPU가 생성하는 주소로, 가상 주소라고도 불림
- 프로그램이 생성하는 주소
- 실제 메모리 위치와는 상관 없이 프로그램 내에서 참조되는 주소
물리 주소 (Physical Address)
- 메모리 관리 유닛(MMU)이 볼 수 있는 주소
- 물리적인 메모리 상에서의 실제 주소를 의미
- 런타임에 MMU를 통해 논리 주소에서 물리 주소로 매핑됨
Memory Management Unit
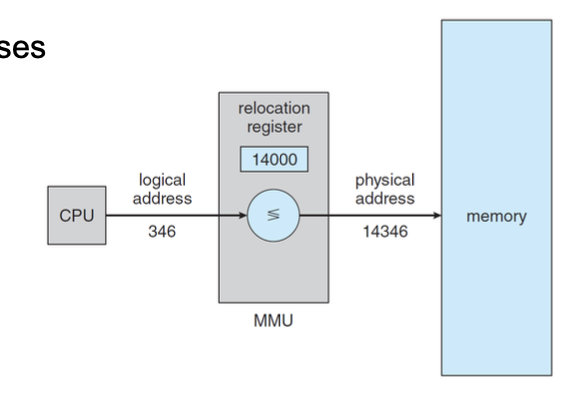
- 재배치 레지스터의 값은 사용자 프로세스가 메모리로 보낼 때 생성하는 모든 주소에 추가됨
- 이로 인해 논리 주소가 물리 주소에 연결(바인딩)됨
- 사용자 프로그램은 논리 주소만을 다루며, 실제 물리 주소는 절대로 볼 수 없음
- 실행 시간 바인딩(execution-time binding)은 메모리 내의 위치에 대한 참조가 이루어질 때 발생함
- 즉, 프로그램이 실행되는 동안에 논리 주소가 실제 물리 주소로 매핑되는 과정을 의미.
Dynamic Loading
프로그램 실행 시 필요한 루틴 또는 함수를 호출하기 전까지
해당 루틴이 메모리에 로드되지 않는기법
-
프로그램의 전체가 메모리에 올라와 있을 필요 없이
필요한 부분만 동적으로로드됨 -
메모리 공간을 더
효율적으로 활용할 수 있으며, 사용되지 않는 루틴은 로드되지 않아자원을 절약할 수 있음 -
특히, 드물게 발생하는 상황을 처리하기 위해 많은 양의 코드가 필요한 경우에 유용함
-
운영 체제로부터 특별한 지원이 필요하지 않으며,
프로그램 설계를 통해 구현됨 -
운영 체제는 동적 로딩을 구현하기 위한
라이브러리를 제공함으로써 도움을 줄 수 있음
Dynamic Linking
실행 시간(execution time)까지 링킹을 연기하는 기법
-
동적 링킹을 하면 모듈들이 실행 가능한 이미지에 포함되지 않음
-
동적으로 링크된 라이브러리(DLLs)는 사용자 프로그램이 실행될 때 해당 프로그램과 링크되는 시스템 라이브러리임 -
정적 링킹은 라이브러리가 로더에 의해 이진 프로그램 이미지에 결합되는 방식과 달리, 동적 링킹은
실행 시에 필요한 라이브러리가 메모리에 로드되고 링크됨 -
동적 링크된 라이브러리는
여러 프로세스 사이에서 공유되며,메인 메모리에는 DLLs의 단일 인스턴스만 존재함 -
운영 체제의 지원을 통해 여러 프로세스가 동일한 주소 공간에 접근할 수 있음
-
동적 링킹은 Windows 및 Linux 시스템에서 널리 사용되며, 특히 표준 C 라이브러리와 같은 시스템 라이브러리에 유용함
-
또한 시스템 라이브러리의 패치에 적용 가능성을 고려할 수 있으며, 버전 관리가 필요할 수 있음
Memory Allocation
Contiguous Allocation (연속 할당)
- 초기 메모리 할당 방법
- 메인 메모리는 일반적으로 두 개의 파티션으로 구성
- 운영 체제가 상주하며 일반적으로 저메모리에 위치한 인터럽트 벡터
- 사용자 프로세스가 상주하는 고메모리
- 각 프로세스는 메모리의 연속된 영역에 할당됩니다.
Variable Partition Scheme (가변 파티션 스키마)
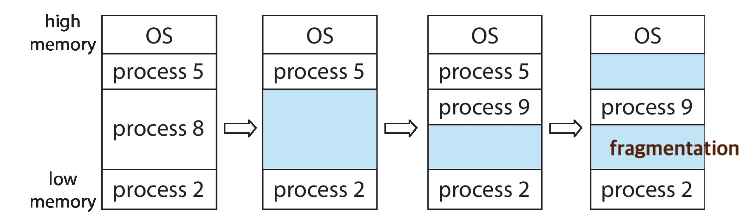
- 메모리에 가변 크기의 파티션을 할당하는 방법
- 각 파티션은 정확히 하나의 프로세스를 수용할 수 있음
- 이를 통해 프로세스의 개별적인 요구에 따라 파티션의 크기를 조정하여 보다 효율적인 메모리 활용이 가능
연속 할당은 간단하고 직관적인 메모리 관리를 제공하지만, 외부 단편화와 제한된 유연성의 문제점이 있습니다. 가변 파티션 스키마는 이러한 제한 사항을 해결하기 위해 더 효율적인 메모리 할당과 활용을 가능하게 합니다.
Fragmentation
External Fragmentation
- 프로세스가 메모리에 로드되고 제거됨에 따라 빈 메모리 공간이 작은 조각들로 나누어짐
- 이러한 조각들은
External Fragmentation (외부 단편화)를 일으키는데, 이는 충분한 전체 메모리 공간이 요청을 충족시키지만 연속적이지 않은 상태를 의미함 - 이러한 외부 단편화로 인해 메모리의 일부가 사용 불가능해질 수 있음
50-percent rule
50-percent rule (50% 규칙)은 N개의 블록이 할당된 경우, 0.5N개의 블록이 단편화로 인해 손실되는 것을 의미함- 메모리의 1/3이 사용할 수 없게 될 수 있음
단편화 해결법 - 압축(compaction)
- 모든 빈 메모리를 한 곳에 모아 큰 블록으로 만드는 작업
- 동적 재배치가 가능하고 실행 시간에 수행될 때만 가능
- 모든 프로세스를 메모리의 한쪽 끝으로 이동시키는 가장 간단한 압축 알고리즘은 비용이 많이 들 수 있음
Paging
프로세스의 물리적 주소 공간이 비연속적일 수 있도록 허용하는 메모리 관리 방식
- 외부 단편화를 방지
- 단편화로 인한 메모리 복구(compaction) 필요성을 없앨 수 있음
- 페이징은 운영체제와 컴퓨터 하드웨어간의 협력을 통해 구현됨
물리적 및 논리적 메모리 분할
- 피지컬 메모리를
Frame이라는 고정 크기의 블록으로 분할 - 로지컬 메모리도
Page라는 같은 크기의 블록으로 분할 - 블록의 크기는 2의 거듭제곱이며, 512바이트에서 16메가바이트 사이
페이지 테이블
- N 페이지 크기의 프로그램을 실행하려면, 물리 메모리에서 N개의 빈 프레임을 찾아야 함
- 로지컬 주소를 피지컬 주소로 변환하기 위해 페이지 테이블이 설정됨
- 이렇게 하면 프로그램이 메모리에서 연속적인 공간을 차지할 필요가 없어, 외부 단편화 문제를 효과적으로 해결할 수 있음
주소 변환 방식
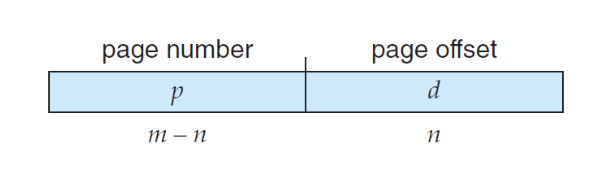
CPU가 생성하는 주소는 다음과 같이 나뉩니다:
- Page number(
p) : 페이지 테이블에 대한 인덱스로 사용되며, 페이지 테이블에는 물리 메모리의 각 페이지의 기본 주소가 포함됩니다. - Page offset(
d) : 기본 주소와 결합되어 메모리 단위로 전송되는 물리 메모리 주소를 정의합니다. - 주어진 논리 주소 공간 2^m과 페이지 크기 2^n에 대해 위와 같이 주소를 분할하고 변환합니다.
Paging Hardware
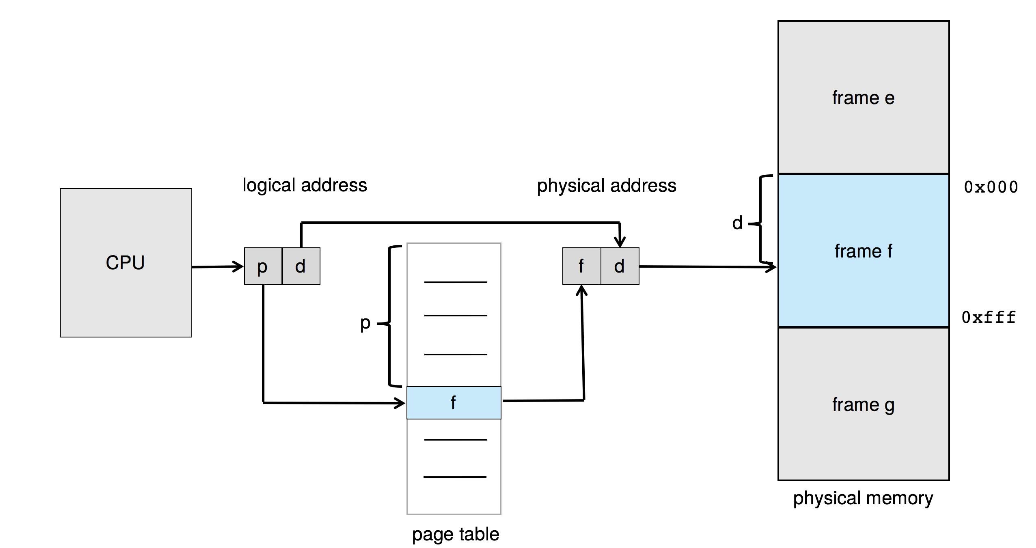
페이징 예시
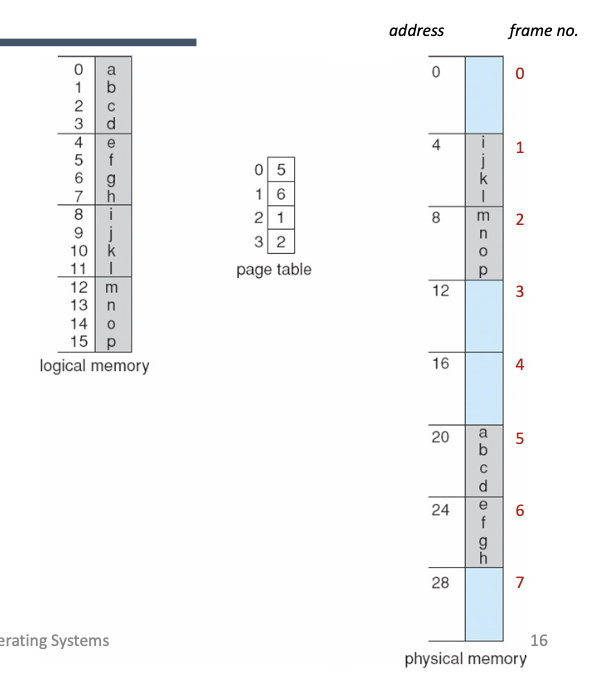
다음과 같은 주소 관련 조건이 주어졌을 때의 페이징에 대해 설명합니다:
- 논리적 주소: m=4, n=2
- 주소 공간: 16 바이트 (2^m)
- 페이지 크기: 4 바이트 (2^n)
- 물리적 메모리: 32 바이트 (8페이지)
- 프레임 크기는 페이지 크기와 동일
- 5비트 주소 공간 (2^5)
이 예제에서는 16바이트의 논리적 주소 공간이 4바이트 크기의 페이지로 나누어지고, 물리적 메모리는 32바이트로, 총 8개의 페이지(프레임)로 나누어집니다.

Page table의 구현
페이지 테이블은 프로세스당 데이터 구조로, 각 프로세스의 프로세스 제어 블록(PCB)에 페이지 테이블에 대한 포인터가 저장됩니다.
- 페이지 테이블은 메인 메모리에 저장됨
페이지 테이블 기본 레지스터(Page-table base register, PTBR)는 페이지 테이블을 가리킴페이지 테이블 길이 레지스터(Page-table length register, PTLR)는 페이지 테이블의 크기를 나타냄
- 컨텍스트 전환(Context-switching)은 PTBR의 변경만을 요구하지만, 모든 데이터/명령어 접근은 두 번의 메모리 접근을 필요로 함
- 하나는 페이지 테이블을 위한 것이고, 다른 하나는 데이터/명령어를 위한 것임
- 두 번의 메모리 접근 문제는 Translation Look-aside Buffers(TLBs)라는 특별한 빠른 조회 하드웨어 캐시를 사용함으로써 해결할 수 있음
Translation Look-aside Buffer (TLB)
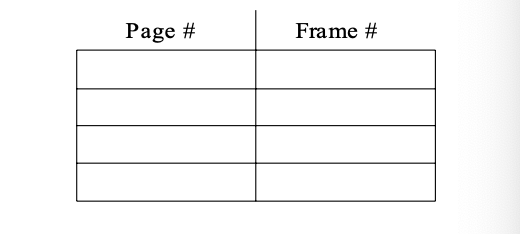
TLB는 연관 메모리(Associative memory)를 이용한 고속 메모리 캐시입니다.
- 일반적으로 작은 크기: 32에서 1,024개의 항목(entries)
- TLB의 각 항목은 두 부분으로 구성:
key(or tag),value - 모든 키에 대해 동시에 검색
- 주소 변환 (p, d)
- 만약
p가 연관 레지스터에 있다면, 프레임 번호를 추출 - 그렇지 않다면, 메모리에 있는 페이지 테이블에서 프레임 번호를 얻음
- 만약
- 일부 TLBs는 각 TLB 항목에
주소 공간 식별자(Address-Space IDentifiers, ASIDs)를 저장- 각 프로세스를 고유하게 식별하여
주소 공간 보호를 제공
- 각 프로세스를 고유하게 식별하여
TLB 미스가 발생하면, 그 값은 차후 참조를 위해 TLB에 로드됨대체 정책(Replacement policies)을 고려해야 하며, 예를 들어 최근에 가장 적게 사용된 것(Least Recently Used, LRU)을 대체- 일부 항목(핵심 커널 코드를 위한 것)은 항상 빠른 접근을 위해
고정(wired down)될 수 있음
**
Paging Hardware
효과적인 접근 시간 (Effective Access Time, EAT)
TLB 내에서 페이지 번호가 발견되는 횟수의 비율을 '히트 비율(Hit Ratio)'이라 합니다.
- 메모리 접근에 10 나노초가 소요되며, 히트 비율이 80%라고 가정해보겠습니다.
- EAT = 0.80 x 10 + 0.20 x 20 = 12 나노초
- 이는 접근 시간이 20% 느려진 것을 의미
- 보다 현실적인 히트 비율인 99%를 고려해봅시다.
- EAT = 0.99 x 10 + 0.01 x 20 = 10.1 나노초
- 이는 접근 시간이 단지 1% 느려진 것을 의미
EAT는 히트 비율에 따라 결정되며, 이는 페이지 번호가 TLB에서 발견되는 빈도를 나타냅니다. 히트 비율이 높을수록 EAT는 감소하며, 이는 시스템 성능 향상을 의미합니다.
Memory Protection
각 프레임에 연관된
Protection bits (보호 비트)를 사용하여 읽기 전용인지 읽기-쓰기 모두 가능한지를 나타냅니다.
- 각 페이지 테이블 항목에
유효-무효 비트(valid-invalid bit)가 첨부됨:Valid(유효)- 연관된 페이지가 프로세스의 논리적 주소 공간 내에 있음; 합법적인 페이지Invalid(무효)- 페이지가 프로세스의 논리적 주소 공간 내에 없음- 또는 페이지 테이블 길이 레지스터(Page-Table Length Register, PTLR) 사용
- 모든 위반은 커널로의 트랩(trap)을 발생시킴
이러한 메커니즘을 통해, 운영 체제는 각 프로세스의 메모리 접근을 제어하고, 불법적인 메모리 접근이 시스템을 손상시키는 것을 방지합니다.
메모리 보호 예시
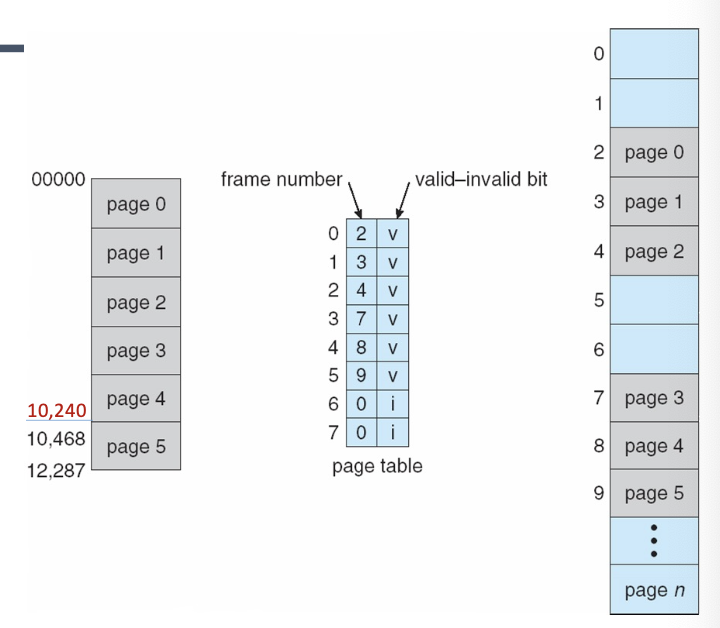
14비트 주소 공간(0 ~ 16383)을 가진 시스템을 가정해봅시다.
- 페이지 크기: 2 KB (11-bit)
- 페이지 수: 8개 (3-bit)
- 프로그램은 0에서 10468까지만 사용
이 예시에서, 각 페이지의 크기는 2KB이며, 전체 주소 공간을 8개의 페이지로 나눌 수 있습니다. 프로그램이 0에서 10468까지만 사용하기 때문에, 나머지 주소 공간은 보호됩니다. 이는 메모리 보호 메커니즘이 어떻게 프로세스의 불법적인 메모리 접근을 방지하는지를 보여주는 예시입니다.
공유 페이지 (Shared Pages)
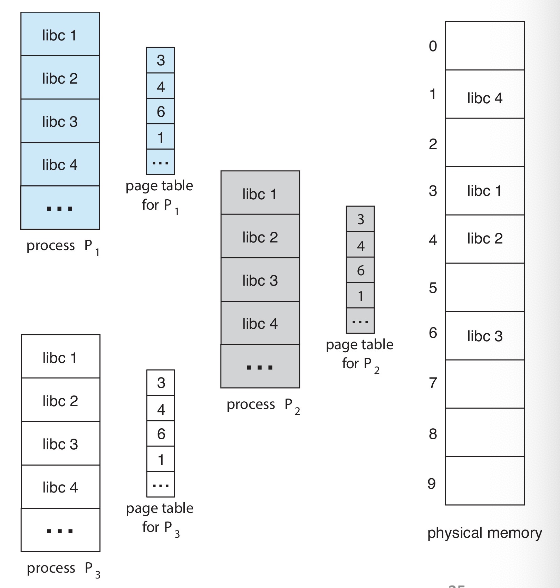
여러 프로세스 간에 공유될 수 있는 페이지
Shared Code (공유 코드)
- 읽기 전용(재진입 가능) 코드의 한 복사본이 여러 프로세스간에 공유됨 (예: 텍스트 에디터, 컴파일러, 윈도우 시스템)
- 같은 프로세스 공간을 공유하는 여러 스레드와 유사함
- 읽기-쓰기 페이지의 공유가 허용되면 프로세스 간 통신에도 유용함
Private code and data (개인 코드와 데이터)
- 각 프로세스는 코드와 데이터의 별도의 복사본을 유지함
- 개인 코드와 데이터를 위한 페이지는 논리적 주소 공간의 어디에서나 나타날 수 있음
이 메커니즘을 통해, 여러 프로세스는 필요한 공유 자원에 대한 접근을 최적화할 수 있으며, 동시에 개인 데이터와 코드는 안전하게 보호됩니다.
페이지 테이블 구조
직접적인 방법을 사용하면 페이징에 대한 메모리 구조가 거대해질 수 있습니다.
- 현대 컴퓨터에서 볼 수 있는 32비트 논리 주소 공간을 생각해보면,
- 페이지 크기는 4KB(2^12), 페이지 테이블 항목 수는 1백만개 이상 (2^32 / 2^12 = 2^20)
- 각 항목이 4바이트라면, 각 프로세스는 페이지 테이블만으로 4MB의 메모리를 필요로 함
- 페이지 테이블은 연속적인 메모리에 할당될 수 없음
해결책은 페이지 테이블을 더 작은 단위로 나누는 것입니다:
- 계층적 페이징(Hierarchical Paging)
- 해시된 페이지 테이블(Hashed Page Tables)
- 반전 페이지 테이블(Inverted Page Tables)
이러한 방법들은 페이지 테이블의 메모리 사용량을 효과적으로 줄이고, 메모리 관리를 효율적으로 수행할 수 있게 돕습니다.
계층적 페이지 테이블 (Hierarchical Page Tables)
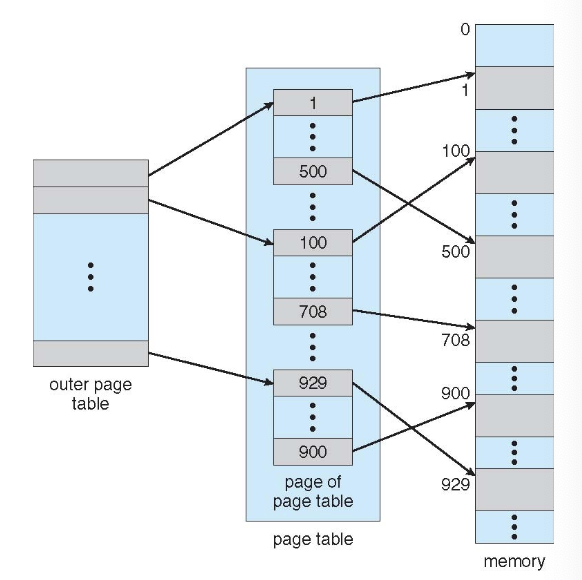
논리적 주소 공간을 여러 페이지 테이블로 나눕니다.
- 단순한 기술 중 하나는 2단계 페이지 테이블입니다.
- 이 방식은 페이지 테이블 자체를 페이지화(paging)합니다.
이러한 계층적 페이지 테이블 구조는 메모리 사용량을 줄이고, 더 큰 주소 공간을 처리할 수 있게 합니다. 또한, 페이지 테이블을 페이지화하면 필요한 페이지 테이블만 메모리에 유지하고, 나머지는 디스크에 저장하여 메모리를 효율적으로 관리할 수 있습니다.
Two-Level paging example
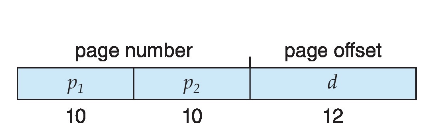
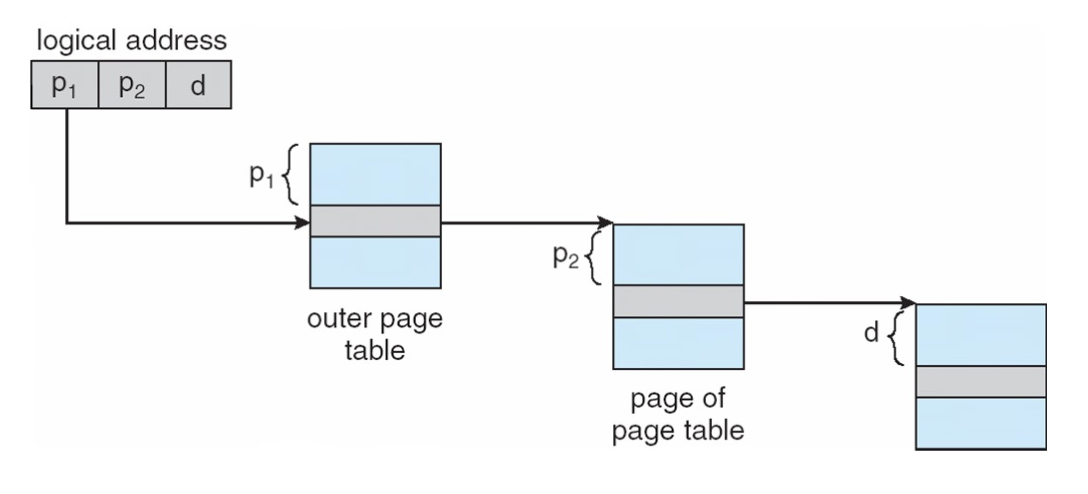
4KB 페이지 크기를 가진 32비트 머신에서 논리 주소는 다음과 같이 나눠집니다.
-
페이지 번호: 20비트
-
페이지 오프셋: 12비트
-
페이지 테이블이 페이지화되어 있으므로, 페이지 번호는 다시 10비트 페이지 번호와 10비트 페이지 오프셋으로 나눠집니다.
-
논리 주소는 다음과 같습니다:
- p1은 외부 페이지 테이블을 인덱싱하는 데 사용됩니다.
- p2는 내부 페이지 테이블의 페이지 내 이동을 나타냅니다.
-
외부/내부 페이지 테이블 크기:
- 각각 2^10 페이지 테이블 항목과 각 항목당 4바이트: 4KB (= 페이지 크기)
- 이제 각각의 페이지 테이블을 페이지(연속적인 메모리)에 배치할 수 있습니다.
-
이를
전방 매핑 페이지 테이블(Forward-mapped page table)이라고 부릅니다.
해시 페이지 테이블 (Hashed Page Tables)
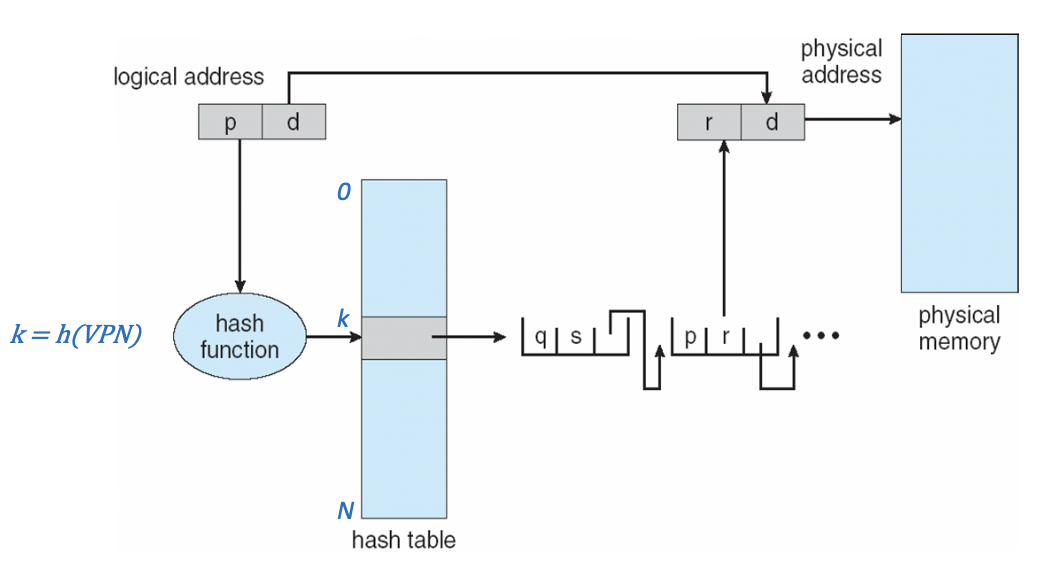
Hashed page table은 가상 페이지 번호를 해시 테이블에 해싱하고, 해당 위치에 체인의 요소들이 저장되며, 이 체인에서 매치되는 가상 페이지 번호를 찾아 해당 물리 프레임을 추출하는 방식으로 작동합니다.
- 주소 공간이 32비트 이상인 경우에 흔히 사용됩니다.
- 가상 페이지 번호는 페이지 테이블로 해시되며, 페이지 테이블은 동일한 위치로 해시되는 요소들의 체인을 포함합니다. 이는 충돌을 저장하기 위한 별도 체이닝입니다.
- 각 요소는 다음을 포함합니다:
- 가상 페이지 번호 (VPN)
- 매핑된 페이지 프레임의 값
- 다음 요소를 가리키는 포인터
- 체인에서 가상 페이지 번호가 비교되어 일치하는 요소를 찾습니다.
- 일치하는 요소가 발견되면, 해당 물리 프레임이 추출됩니다.
이 해시 페이지 테이블 방식은 주소 공간이 매우 큰 시스템에서 페이지 테이블의 크기를 줄이는 데 효과적입니다.
클러스터 페이지 테이블 (Clustered Page Tables)
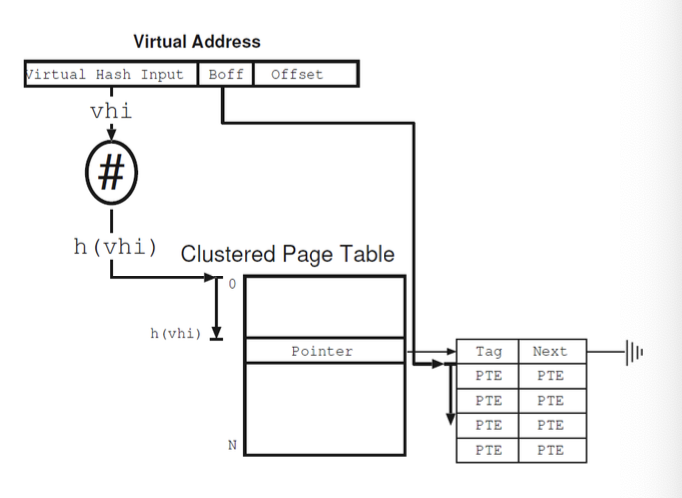
프로세서 아키텍처가 64비트 가상 주소 공간으로 이동함에 따라, 우리는 페이지 테이블의 확장을 지원해야 합니다.
- 클러스터 페이지 테이블은 해시 페이지 테이블의 수정 버전으로, 각 항목은 가상 주소 공간에서 연속적인 페이지 세트를 포함합니다.
- 하나의 PTE(페이지 테이블 항목)가 여러 물리 페이지 프레임의 매핑을 저장할 수 있습니다.
- 페이지 블록 내의 페이지 수를 서브블로킹 팩터라고 합니다.
클러스터 페이지 테이블은 매우 크지만 희소하게 채워진 주소 공간을 효율적으로 관리할 수 있게 해줍니다.
역페이지 테이블 (Inverted Page Table)
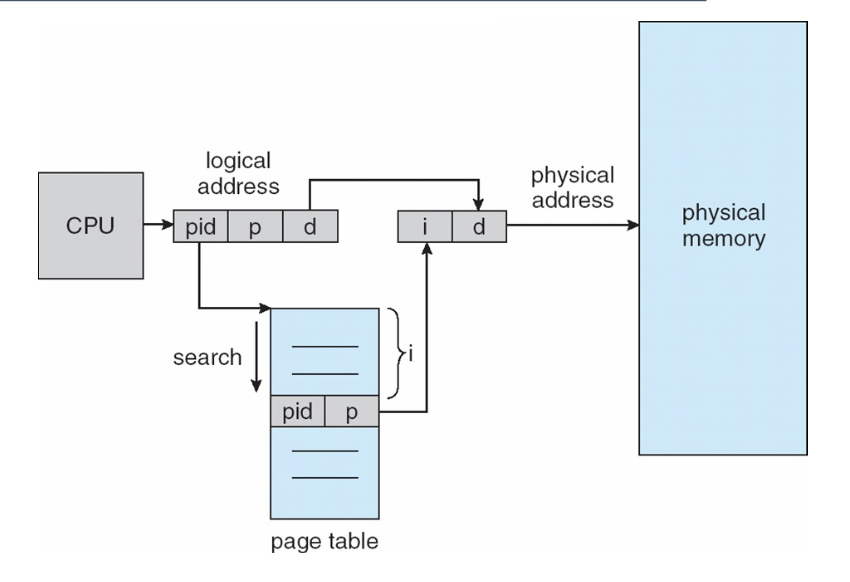
Inverted Page Table은 가상 페이지를 물리적 프레임에 매핑하는 기존 방식 대신 물리적 메모리 프레임을 가상 페이지에 매핑하는 데이터 구조입니다
Inverted page table은 모든 물리 페이지 프레임을 추적하며, 각 엔트리는 실제 메모리 위치에 저장된 페이지의 가상 주소와 해당 페이지를 소유한 프로세스 정보를 포함하며, 페이지 참조 발생 시 테이블을 검색하여 주소를 찾습니다.
- 모든 가능한 논리 페이지에 대해 페이지 테이블을 가지는 각 프로세스보다는, 모든 물리 페이지 프레임을 추적합니다.
- 공간 효율성이 뛰어납니다.
- 물리 메모리의 각 프레임에 대해 하나의 항목이 있습니다.
- 항목은 실제 메모리 위치에 저장된 페이지의 가상 주소와, 해당 페이지를 소유한 프로세스에 대한 정보 (즉, ASID 또는 PID)를 포함합니다.
- 이 방식은 페이지 참조가 발생할 때 테이블의 전체 검색에 필요한 시간을 늘립니다.
- 해시 테이블을 사용하면 검색을 하나 또는 최대 몇 개의 페이지 테이블 항목으로 제한할 수 있습니다.
- 접근을 가속화하기 위해 해시 테이블을 조회하기 전에 먼저 TLB가 검색됩니다.
- 그런데 공유 메모리는 어떻게 구현하나요?
- 가상 주소를 공유 물리 주소로 매핑하는 것은 한 번만 있습니다.
스왑핑 (Swapping)
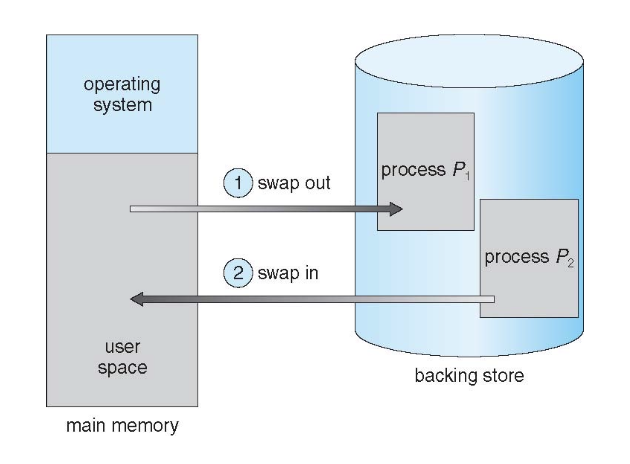
프로세스는 일시적으로 메모리에서 백업 스토어로 스왑될 수 있으며, 이후 계속 실행을 위해 메모리로 다시 가져올 수 있습니다.
- 프로세스의 총 논리 메모리 공간은 물리 메모리를 초과할 수 있습니다.
- 백업 스토어 - 모든 사용자의 모든 메모리 이미지 복사본을 수용할 수 있는 충분히 크고 빠른 디스크입니다.
Swapping with Paging
대부분의 시스템에서, Linux 및 Windows를 포함하여, 프로세스 전체가 아닌 프로세스의 페이지를 스왑할 수 있습니다.
- 일반적으로 스왑핑이라고하면 표준 스왑핑을 의미하고, 페이징과 함께하는 스왑핑을 의미합니다.
- 페이지 아웃 작업은 메모리에서 페이지를 백업 스토어로 이동시키고, 그 반대 과정은 페이지 인이라고 합니다.
