

Reactive Mongo를 Spring Data의 Pageable을 활용해서 익숙한 방법처럼 어떻게 사용할 수 있을까??
먼저 아래와 같은 Job Collection이 있다
@Document
class Job(
@Id
val id: String? = null,
val name: String
) {
}우리가 구현해야 할 기능은 Job의 name이 들어왔을 때 이 문자열을 포함하는 Job들을 name의 길이 가 짧은 순, name 오름차순 으로 Slice 조회를 하는 것이다.
1. Repository
Aggregation을 작성 할 CustomRepository를 만들어주자
interface CustomJobRepository {
fun findByNameSearchSlice(name: String?, pageable: Pageable): Flux<Job>
}
인터페이스를 구현하는 Impl Repository를 만들어주자
- name을 포함하는 Criteria를 작성하고, match 메서드를 통해 MatchOperation을 생성
val criteria = if (name != null) {
Criteria.where("name").regex(".*${name}.*")
} else {
Criteria()
}
val match = Aggregation.match(criteria)- name의 길이를 Sorting에 사용하기 위해 "nameLength" ProjectionOperation을 생성
val addFields = Aggregation.project("name")
.andExpression("strLenCP(name)").`as`("nameLength")- 필요한 커스텀 소팅을 위해 Sort 객체들을 생성해 sort()메서드에 넣어 SortOperation을 생성
val sort = Aggregation.sort(
Sort.by(
Sort.Order(Sort.Direction.ASC, "nameLength")
).and(
Sort.by(Sort.Direction.ASC, "name")
)
)
-
이제 pagination을 위해 Skip과 limit Operation을 생성
- Skip은 시작 위치를 건너뛰는 것으로 Page의 번호이다.
- Limit는 몇 개를 가져올지 정하는 것인데 Page의 Size이다.여기서 중요한 것은 Slice 조회를 위해 limit에서 pageSize에 +1을 하는 것이다.
그 이유는 Slice는 Page와 다르게 총 개수를 구하기 위해 Count 쿼리를 하지 않는다. 대신 다음 원소를 하나 더 조회해서 다음 번호의 페이지가 존재하는지 확인한다. -
마지막으로 집계 함수를 생성하고 쿼리를 날려주자
val aggregation = Aggregation.newAggregation(match, addFields, sort, skip, limit)
return mongoTemplate.aggregate(aggregation, "job", Job::class.java)전체 Impl Repo 코드
class CustomJobRepositoryImpl(
@Autowired private val mongoTemplate: ReactiveMongoTemplate
) : CustomJobRepository {
override fun findByNameSearchSlice(name: String?, pageable: Pageable): Flux<Job> {
val criteria = if (name != null) {
Criteria.where("name").regex(".*${name}.*")
} else {
Criteria()
}
val match = Aggregation.match(criteria)
val addFields = Aggregation.project("name")
.andExpression("strLenCP(name)").`as`("nameLength")
val sort = Aggregation.sort(
Sort.by(
Sort.Order(Sort.Direction.ASC, "nameLength")
).and(
Sort.by(Sort.Direction.ASC, "name")
)
)
val limit = Aggregation.limit(pageable.pageSize.toLong() + 1)
val skip = Aggregation.skip((pageable.pageNumber * pageable.pageSize).toLong())
val aggregation = Aggregation.newAggregation(match, addFields, sort, skip, limit)
return mongoTemplate.aggregate(aggregation, "job", Job::class.java)
}
}
- ReactiveMongoTemplate을 활용해서 query를 날려야하기 때문에 주입받도록 하자
CustomRepository interface도 기존의 JobRepository에 추가해주자
interface JobRepository : ReactiveMongoRepository<Job, String>, CustomJobRepository {
fun findByName(name: String): Mono<Job>
}2. Service
이제 Service를 만들어야 하는데 그 전에 Slice 인터페이스의 구현체인 SliceImpl을 생성 할 Utli 클래스를 만들자
class SliceResponse {
companion object {
fun <T> of(
content: MutableList<T>,
pageable: Pageable
): Slice<T> {
val hasNext = content.size > pageable.pageSize
if (hasNext) {
content.removeLast()
}
return SliceImpl(content, pageable, hasNext)
}
}
}로직은 간단하게 다음 페이지 번호에서 Collection을 하나 가져왔으면 hasNext가 True이고, 가져온 것을 삭제한다
이제 서비스에 메서드를 추가하자
@Transactional(readOnly = true)
suspend fun searchByJobName(name: String?, pageable: Pageable): Slice<Job> {
return SliceResponse.of(
jobRepository.findByNameSearchSlice(name, pageable).collectList().awaitSingle(),
pageable
)
}여기서 왜 Repository에서 Mono<
Slice<Job>>를 반환하지 않고 번거롭게 Flux를 반환하는 거지?? 라는 의문이 들 수도 있다.
그 이유는 Mono로 하게 되면 아래와 같은 예외를 마주치게 된다.
org.springframework.data.repository.query.QueryCreationException:
Could not create query for public abstract reactor.core.publisher.Mono pmeet.pmeetserver.user.repository.job.CustomJobRepository.findByNameSearchSlice(java.lang.String,org.springframework.data.domain.Pageable);
Reason: 'CustomJobRepository.findByNameSearchSlice' must not use sliced or paged execution; Please use Flux.buffer(size, skip).Mono Slice를 사용하면 문제가 발생하는 이유는 Reactive 프로그래밍에 부합하지 않다. 왜냐하면 Page와 Slice 모두 Content 필드의 타입이 List 컬렉션이기 때문에 결과를 모두 수집해야해서 Reactive하지 않기 때문이다.
자세한 내용은 https://github.com/spring-projects/spring-data-r2dbc/issues/565 를 참고하자
마지막으로 파사드 서비스에 메서드를 추가하자
@Transactional(readOnly = true)
suspend fun searchJobByName(name: String?, pageable: Pageable): Slice<JobResponseDto> {
return jobService.searchByJobName(name, pageable).map { JobResponseDto.from(it) }
}3. Controller
이제 마지막으로 컨트롤러에 메서드를 추가하자
@GetMapping("/search")
@ResponseStatus(HttpStatus.OK)
suspend fun searchJobByName(
@RequestParam(required = false) name: String?,
@RequestParam(defaultValue = "0") page: Int,
@RequestParam(defaultValue = "10") size: Int
): Slice<JobResponseDto> {
return jobFacadeService.searchJobByName(name, PageRequest.of(page, size))
}4. Swagger 테스트
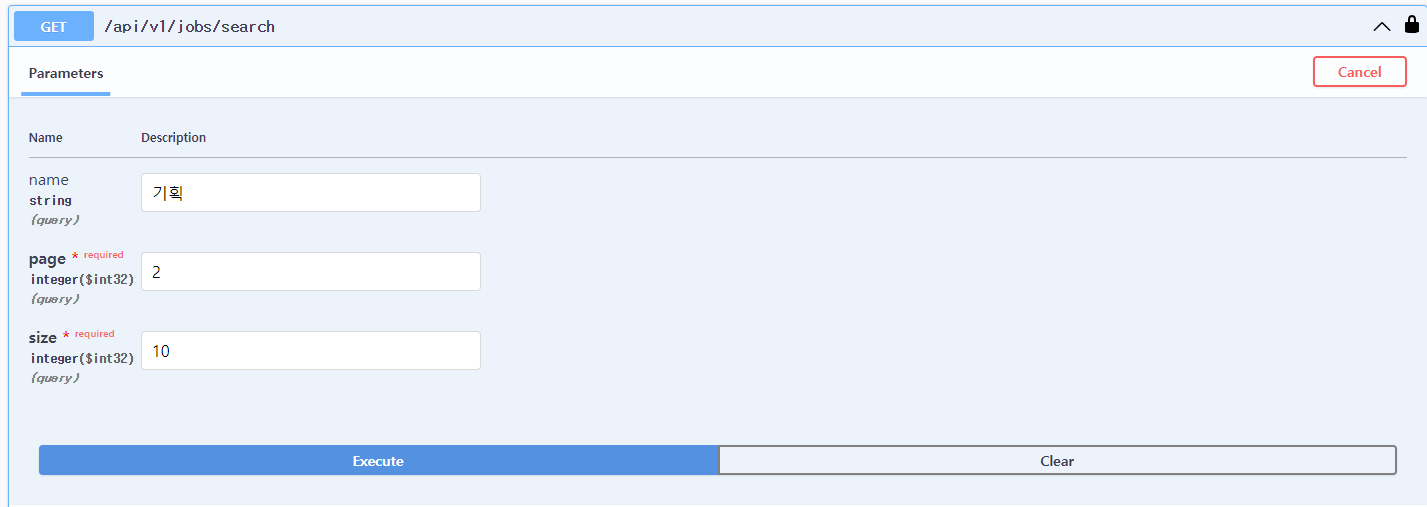
{
"content": [
{
"id": "66643de0e3f8e3dd71db8427",
"name": "서비스기획"
},
{
"id": "66643de0e3f8e3dd71db8422",
"name": "신사업기획"
},
{
"id": "66643de0e3f8e3dd71db845c",
"name": "이벤트기획"
},
{
"id": "66643de0e3f8e3dd71db842b",
"name": "콘텐츠기획"
},
{
"id": "6665262cdb1e432726cb1b45",
"name": "경영기획10"
},
{
"id": "66652628db1e432726cb1b44",
"name": "경영기획11"
},
{
"id": "66643de0e3f8e3dd71db847f",
"name": "금융상품기획"
},
{
"id": "66643de0e3f8e3dd71db842c",
"name": "UIUX 기획"
},
{
"id": "6665262edb1e432726cb1b46",
"name": "경영기획100"
}
],
"pageable": {
"pageNumber": 2,
"pageSize": 10,
"sort": {
"empty": true,
"sorted": false,
"unsorted": true
},
"offset": 20,
"unpaged": false,
"paged": true
},
"size": 10,
"number": 2,
"sort": {
"empty": true,
"sorted": false,
"unsorted": true
},
"first": false,
"last": true,
"numberOfElements": 9,
"empty": false
}의도한대로 소팅과 Slice form의 응답이 제대로 나온 것을 확인할 수 있다.
5. TestCode 트러블 슈팅
위 기능의 테스트 코드를 작성하면서 Repository 단위테스트와 통합테스트에서 이슈가 있었다.
첫 번째로 Repository 단위 테스트에서 테스트 컨테이너를 사용한다.
@ExperimentalCoroutinesApi
@ContextConfiguration(classes = [MongoTestConfig::class])
internal class JobRepositoryUnitTest(
@Autowired @Qualifier("testMongoTemplate") private val template: ReactiveMongoTemplate
) : DescribeSpec({
val factory = ReactiveMongoRepositoryFactory(template)
val jobRepository = factory.getRepository(JobRepository::class.java)위 처럼 기존의 factory를 통해 JobRepository를 가져오는 과정에서 CustomRepository 때문에 문제가 발생하게 된다.
public <T> T getRepository(Class<T> repositoryInterface) {
return this.getRepository(repositoryInterface, RepositoryFragments.empty());
}
public <T> T getRepository(Class<T> repositoryInterface, Object customImplementation) {
return this.getRepository(repositoryInterface, RepositoryFragments.just(new Object[]{customImplementation}));
}이유는 factory의 getRepository의 메서드에 CustomRepoImpl을 추가하지 않았기 때문이다.
해결은 간단하게 아래와 같이 CustomRepoImpl을 생성해서 아규먼트에 추가해주면 된다.
val factory = ReactiveMongoRepositoryFactory(template)
val customJobRepository = CustomJobRepositoryImpl(template)
val jobRepository = factory.getRepository(JobRepository::class.java, customJobRepository)두 번째로 통합테스트에서 Slice Json 응답을 다시 객체로 변환하고 있다.
describe("GET /api/v1/search") {
val jobName = "TestJob"
val userId = "1234"
val pageNumber = 0
val pageSize = 10
withContext(Dispatchers.IO) {
for (i in 1..pageSize * 2) {
jobRepository.save(Job(name = jobName + i)).block()
}
}
context("인증된 유저가 직무 이름과 페이지 정보가 주어지면") {
val mockAuthentication = UsernamePasswordAuthenticationToken(userId, null, null)
val performRequest = webTestClient
.mutateWith(mockAuthentication(mockAuthentication))
.get()
.uri {
it.path("/api/v1/jobs/search")
.queryParam("name", jobName)
.queryParam("page", pageNumber)
.queryParam("size", pageSize)
.build()
}
.accept(MediaType.APPLICATION_JSON)
.exchange()
it("요청은 성공한다") {
performRequest.expectStatus().isOk
}
it("이름을 포함하는 직무들을 Slice로 반환한다") {
performRequest.expectBody<Slice<JobResponseDto>>().consumeWith {
it.responseBody?.content?.size shouldBe pageSize
it.responseBody?.isFirst shouldBe true
it.responseBody?.isLast shouldBe false
it.responseBody?.size shouldBe pageSize
it.responseBody?.number shouldBe pageNumber
it.responseBody?.numberOfElements shouldBe pageSize
it.responseBody?.content?.forEachIndexed { index, jobResponseDto ->
jobResponseDto.name shouldBe jobName + (index + 1)
}
it.responseBody?.hasNext() shouldBe true
}
}
}
}
}위 테스트를 실행해보면 아래와 같은 예외를 마주치게 된다
Caused by: com.fasterxml.jackson.databind.exc.InvalidDefinitionException:
Cannot construct instance of `org.springframework.data.domain.Slice` (no Creators, like default constructor, exist): abstract types either need to be mapped to concrete types,
have custom deserializer, or contain additional type information응답 Json을 Slice로 역직렬화를 하지 못하는 것이다. (SliceImpl을 사용해도 동일한 예외 발생)
해결법은 역직렬화를 가능하도록 생성자를 가진 클래스를 만들어서 직접 Slice를 만들고 테스트 응답에 적용하면 된다.
@JsonIgnoreProperties(ignoreUnknown = true)
class RestSliceImpl<T> @JsonCreator(mode = JsonCreator.Mode.PROPERTIES)
constructor(
@JsonProperty("content") content: List<T>,
@JsonProperty("number") number: Int,
@JsonProperty("size") size: Int,
@JsonProperty("pageable") pageable: JsonNode,
@JsonProperty("last") last: Boolean, // last는 SliceImpl의 hasNext의 반대로 생성된다.
@JsonProperty("first") first: Boolean,
@JsonProperty("sort") sort: JsonNode,
@JsonProperty("numberOfElements") numberOfElements: Int,
@JsonProperty("empty") empty: Boolean
) : SliceImpl<T>(content, PageRequest.of(number, size), !last) performRequest.expectBody<RestSliceImpl<JobResponseDto>>().consumeWith {
it.responseBody?.content?.size shouldBe pageSize
it.responseBody?.isFirst shouldBe true
it.responseBody?.isLast shouldBe false
it.responseBody?.size shouldBe pageSize
it.responseBody?.number shouldBe pageNumber
it.responseBody?.numberOfElements shouldBe pageSize
it.responseBody?.content?.forEachIndexed { index, jobResponseDto ->
jobResponseDto.name shouldBe jobName + (index + 1)
}
it.responseBody?.hasNext() shouldBe true